带你玩转 3D 检测和分割 (二):核心组件分析之坐标系和 Box
我们在前文 玩转 MMDetection3D (一)中介绍了整个框架的大致流程,从这篇文章开始我们将会带来 MMDetection3D 中各种核心组件的解析,而在 3D 检测中最重要的核心组件之一就是坐标系和 Box 。
1.坐标系的来龙去脉
目前,在 MMDetection3D 支持的算法中,有三大坐标系,他们是——
- 深度坐标系(Depth),此坐标系主要被用于通过深度相机采集的数据集, 大多是室内场景点云检测。
- 激光雷达坐标系(LiDAR),顾名思义,是适用于室外场景点云检测普遍采用的激光雷达设备的坐标系。
- 相机坐标系(Camera),该坐标系在室内室外场景的点云检测均有使用,代表彩色相机的常用坐标系,一般用于数据格式的转换。在多模态或者单目 3D 的检测器中,相机坐标系是三维点云与二维图像之间的桥梁。
请注意,其实此语境下的坐标系并不只是坐标系本身,它还包括如何定义 包围框的长宽高和旋转角。
在 3D 物体检测任务兴起的初期,群雄争霸,研究者还在探索如何使用现有的数据集进行 3D 检测器的训练,在一些数据预处理的流程上并未达到统一。加之数据集本身的格式也往往不同,因此包围框的格式比较混乱。MMDetection3D 在经历了一些坐标系相关的挫折之后,痛定思痛,决定使用统一的范式一统坐标系江湖,让使用者尽可能少在包围框坐标系上伤脑筋,我们在最新版本的 v1.0.0.rc0 版本中,重构了我们的坐标系。
1.1 基础定义
在 3D 目标检测中,框 Box 通常表示为:(x, y, z, x_size, y_size, z_size, yaw)。
其中 (x, y, z) 表示框的位置 ,(x_size, y_size, z_size) 表示框的尺寸,yaw 表示框的朝向角。
我们重温一下高中物理——右手系。右手系的其中一个定义是,把大拇指指向 x 轴的正方向,食指指向 y 轴的正方向时,中指微屈所指的方向就是 z 轴的正方向。见下图:

图 1:左手系和右手系
在右手系中,按惯例我们定义:选择一个轴作为重力轴(在上图中重力轴为 y 轴),在垂直于重力轴的平面上选择一个参考方向,则参考方向的朝向角 yaw 为 0,其他方向的朝向角 yaw 不为 0,取决于其与参考方向的角度,而且从重力轴的负方向(重力轴指向人的眼睛)看,朝向角沿着逆时针方向增大。在 MMDetection3D 中,我们将 x 轴设定为参考方向,此外在 MMDetection3D 支持的算法和数据集实现中,包围框的旋转角度只考虑朝向角 yaw,不考虑俯仰角 pitch 和翻滚角 roll。
而针对 3D 框的尺寸 (x_size, y_size, z_size),按惯例我们定义为物体 3D 框在朝向角 yaw 角度为 0 时沿着 x, y, z 轴三个方向的长度。
1.2 坐标系重构的前后
我们对 MMDetection3D 坐标系进行了大的重构,从而满足上述的所有定义。
我们先来观察一下重构之前的深度坐标系,如左下图所示:
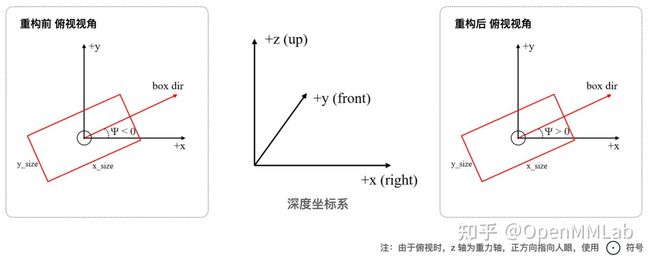
图 2: 深度坐标系重构前后
从轴的关系来看,它是一个右手系,但是并不标准——按图中所示它的朝向角的增加方向是与上文标准右手系相反的!因此,此番重构对深度坐标系的影响就是将朝向角取相反数,与标准右手系一致(右上图所示)。
我们再来看一下重构之前的激光雷达坐标系:

图 3: 激光雷达坐标系重构前后
同样,如左上图所示,它不是一个标准右手系,朝向角反过来了。此外,包围框的 (x_size, y_size) 对应的竟是朝向角为 0 时分别与 y, x 轴平行的两组边的长度!这点常常会使人迷惑,因此重构后,不仅朝向角定义与标准右手系一致,而且原来的 (x_size, y_size) 得到了交换,更符合人们的直觉(右上图所示)。读者或许会奇怪,为什么最初会这样定义 (x_size, y_size)?原因是沿用了 SECOND 的惯例,有兴趣的读者可以参考 SECOND 的代码仓库。
而相机坐标系则是此次重构中唯一没有变化的坐标系了:
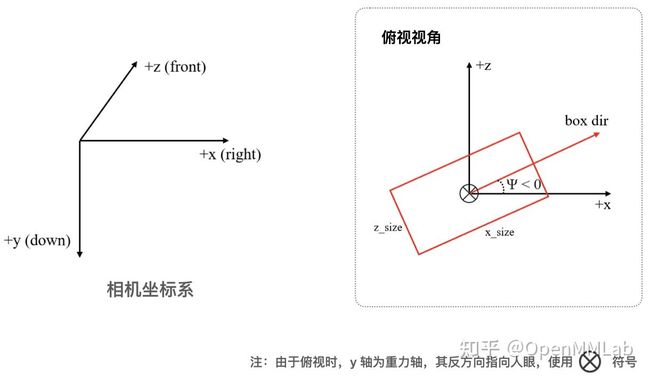
图 4: 相机坐标系
最后,用一张图概括新的三大坐标系:

图 5: 全新的三大坐标系
实际在数据集的采集过程中,往往存在着多个相机或者激光雷达,比如在 KITTI 数据集采集过程中,就存在 4 个相机(2个彩色相机 + 2个灰度相机),和 1 个激光雷达。事实上每个传感器都有自己的坐标系,数据集会提供一些标定文件,里面包含各个传感器对应坐标系之间的变换矩阵。考虑到实际使用情况,MMDetection3D 没有选择将这些坐标系合并为一种坐标系,而是考虑到各个传感器的标定习惯,根据数据传感器的类别分别设定坐标系,我们只是统一规范定义了每个类别的传感器对应的坐标系。


图 6: KITTI 传感器设定
2.Box 代码级解析
2.1 构建 Box
在实际代码中,我们将某个场景所有的物体 3D 框 Boxes 封装成一个类,提供 BaseInstance3DBoxes这个基类,再分别基于此为三种坐标系构建 LiDARInstance3DBoxes、CameraInstance3DBoxes、DepthInstance3DBoxes 三种 Boxes 类,相关的代码位于/mmdet3d/core/bbox/structures目录下。
为了让大家更好地理解该定义,我们可以举一个简单的例子:
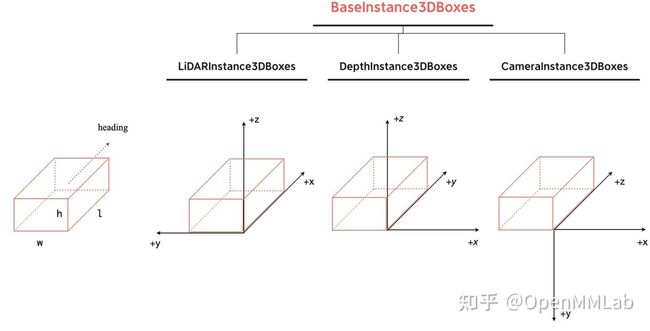
图 7: 示例图
如上图所示,假设物体的长宽高分别为 l, w, h, 其朝向为如图所示,我们可以根据上述的定义表示该物体 3D 框在各个坐标系下的值,这里我们默认三个坐标系原点是重合的:
- 激光雷达坐标系:该物体底部中心点坐标为
(l/2, w/2, 0),朝向和 x 轴的夹角为 0,即 yaw 角为 0,此时沿着x-y-z三个轴方向的长度即为x_size, y_size, z_size的值,分别为l、w、h,所以该坐标系下 Box 的值为(l/2, w/2, 0, l, w, h, 0)。 - 深度坐标系:该物体底部中心点坐标为
(-w/2, l/2, 0),此时朝向和 x 轴的夹角为 90 度,即 yaw 角为pi/2,需要注意的是,为了获得x_size, y_size, z_size, 我们需要将物体旋转到和 x 轴平行,此时沿着x-y-z三个轴方向的长度分别为l、w、h,所以该坐标系下的 Box 的值为(-w/2, l/2, 0, l, w, h, pi/2)。 - 相机坐标系:该物体底部中心点坐标为
(-w/2, 0, l/2), 此时朝向和 x 轴的夹角为 90 度,需要注意的是,根据前面的定义 yaw 角为-pi/2,同样的为了获得x_size, y_size, z_size, 我们需要将物体旋转到和 x 轴平行,此时沿着x-y-z三个轴方向的长度分别为l、h、w,所以该坐标系下的 Box 的值为(-w/2, 0, l/2, l, h, w, -pi/2)。
可以看到,一个物体 3D 框中的 (x_size, y_size, z_size) 在激光雷达坐标系和深度坐标系中为 (l, w, h),而在相机坐标系中为 (l, h, w)。
我们再来看一下这些值是怎么被封装成各种 Boxes 类的,这里我们可以来看一下简化后的代码:
# DepthInstance3DBoxes 和 LiDARInstance3DBoxes 直接继承了 BaseInstance3DBoxes 的
# 初始化函数
class BaseInstance3DBoxes(object):
def __init__(self, tensor, origin=(0.5, 0.5, 0)):
# 注意传入的 tensor 形状为 N X 7,表示场景中 N 个物体 3D 框
assert tensor.dim() == 2
self.tensor = tensor.clone()
# 如果传入的tensor中的 x,y,z 不是底部中心点,会转换为底部中心
if origin != (0.5, 0.5, 0):
dst = self.tensor.new_tensor((0.5, 0.5, 0))
src = self.tensor.new_tensor(origin)
self.tensor[:, :3] += self.tensor[:, 3:6] * (dst - src)
# CameraInstance3DBoxes 重写了初始化,主要是由于默认 origin 不同的原因
class CameraInstance3DBoxes(BaseInstance3DBoxes):
def __init__(self, tensor, origin=(0.5, 1.0, 0.5)):
# 注意传入的 tensor 形状为 N X 7,表示场景中 N 个物体 3D 框
assert tensor.dim() == 2
self.tensor = tensor.clone()
if origin != (0.5, 1.0, 0.5):
dst = self.tensor.new_tensor((0.5, 1.0, 0.5))
src = self.tensor.new_tensor(origin)
self.tensor[:, :3] += self.tensor[:, 3:6] * (dst - src) 上述具体的 Box 的值其实储存在 self.tensor 里面,注意其存储的 Box 位置是底部中心的位置,而非几何中心位置。在构建 BaseInstance3DBoxes 基类的时候,需要注意到 origin 这个变量,其表示的是传入 Box 类的变量 tensor 中的 x,y,z 相对于整个物体 3D 框的相对坐标。
评论里有同学谈到 origin 的理解问题,我们可以在各个不同的坐标系下将任意一个 3D 框通过放缩和平移变换为一个坐标值在 0-1 之间的正方体,而此时各个坐标系下 3D 框底部中心点的坐标值就是原 3D 框底部中心点对应的 origin:

这样我们没有改变 3D 框内点之间的相对位置关系(没有旋转变换),通过给定 3D 框内某个点的实际坐标以及对应的 origin ,我们可以通过结合 3D 框的尺寸 (h, l, w) 计算出框中任意的一点(包括几何中心点和底部中心点等),而在实际构建 Box 的时候,默认采用的 origin 对应的是底部中心点。我们再来回顾一下上面的代码:
# 假设我们传入的 tensor 中的位置(点)实际是几何中心点,
# 即此时传入的 origin = (0.5, 0.5, 0.5)
if origin != (0.5, 1.0, 0.5):
dst = self.tensor.new_tensor((0.5, 1.0, 0.5))
# (0.5, 0.5, 0.5)
src = self.tensor.new_tensor(origin)
# 此时 tensor[3:6] 表示的是(l, h, w), 而目标 origin 和传入 origin
# 的差值为 (0.0, 0.5, 0.0), 两者结合可以算出底部中心点坐标
self.tensor[:, :3] += self.tensor[:, 3:6] * (dst - src) 在 DepthInstance3DBoxes 和 LiDARInstance3DBoxes 中,底部中心点对应的相对坐标 origin为 (0.5, 0.5, 0),在 CameraInstance3DBoxes 中,底部中心点对应的相对坐标 origin 为(0.5, 1.0, 0.5),其作用就是将 tensor 中的坐标 (x,y,z) 转换为 Box 底部中心点。
比如上图 7 所示的 3D 物体框 Box 有多种构建方式:
# 传入 tensor 变量的形状为 1 x 7
# 用底部中心点,在激光雷达坐标系下构建,使用默认 origin 相对位置
LiDARInstance3DBoxes(tensor=[[l/2, w/2, 0, l, w, h, 0]])
# 用 3D Box 几何中心点,在激光雷达坐标系下构建
LiDARInstance3DBoxes(tensor=[[l/2, w/2, h/2, l, w, h, 0]],
origin=(0.5, 0.5, 0.5)))
# 用底部中心点,在深度坐标系下构建,使用默认 origin 相对位置
DepthInstance3DBoxes(tensor=[[-w/2, l/2, 0, l, w, h, pi/2]])
# 用 3D Box 几何中心点,在深度坐标系下构建
DepthInstance3DBoxes(tensor=[[-w/2, l/2, h/2, l, w, h, pi/2]],
origin=(0.5, 0.5, 0.5))
# 用底部中心点,在相机坐标系下构建,使用默认 origin 相对位置
CameraInstance3DBoxes(tensor=[[-w/2, 0, l/2, l, h, w, -pi/2]])
# 用 3D Box 几何中心点,在相机坐标系下构建
CameraInstance3DBoxes(tensor=[[-w/2, -h/2, l/2, l, h, w, -pi/2]],
origin=(0.5, 0.5, 0.5)) 2.2 不同坐标系 Box 的转换

图 8: 不同坐标系 Box 转换图
在 MMDetection3D 中,我们提供了Box3DMode 类用来实现不同坐标系下的 Box 之间的自由转换,Box3DMode 提供类方法 convert ,我们截取部分代码并进行一些简化,来分析不同坐标系下包围框转换的代码(详见这里):
#=================== mmdet3d/core/structures/box_3d_mode.py ==================
@staticmethod
def convert(box, src, dst, rt_mat=None, with_yaw=True):
"""Convert boxes from `src` mode to `dst` mode."""
is_Instance3DBoxes = isinstance(box, BaseInstance3DBoxes)
# 如果是 Boxes 类, 需要使用 tensor 方法取出值
if is_Instance3DBoxes:
arr = box.tensor.clone()
else:
arr = box.clone()
# 从激光雷达坐标系转换到相机坐标系
if src == Box3DMode.LIDAR and dst == Box3DMode.CAM:
# 如果没有提供旋转平移转换矩阵(rotation and translation matrix),
# 那么我们默认变换前后的坐标系的原点是重合的
if rt_mat is None:
rt_mat = arr.new_tensor([[0, -1, 0], [0, 0, -1], [1, 0, 0]])
xyz_size = torch.cat([x_size, z_size, y_size], dim=-1)
if with_yaw:
yaw = -yaw - np.pi / 2
yaw = limit_period(yaw, period=np.pi * 2)
# 从相机坐标系转换到激光雷达坐标系
elif src == Box3DMode.CAM and dst == Box3DMode.LIDAR:
if rt_mat is None:
# rt_mat 为变换矩阵,用于变换 x,y,z
rt_mat = arr.new_tensor([[0, 0, 1], [-1, 0, 0], [0, -1, 0]])
xyz_size = torch.cat([x_size, z_size, y_size], dim=-1)
if with_yaw:
yaw = -yaw - np.pi / 2
yaw = limit_period(yaw, period=np.pi * 2)
# 利用旋转矩阵变换位置
xyz = arr[..., :3] @ rt_mat.t()
arr = torch.cat([xyz[..., :3], xyz_size, yaw], dim=-1)
# ---------------- 其他坐标系间的转换类似,这里省略 -----------------
if is_Instance3DBoxes:
if dst == Box3DMode.CAM:
target_type = CameraInstance3DBoxes
elif dst == Box3DMode.LIDAR:
target_type = LiDARInstance3DBoxes
elif dst == Box3DMode.DEPTH:
target_type = DepthInstance3DBoxes
# 封装进 Boxes 类
return target_type(arr, box_dim=arr.size(-1), with_yaw=with_yaw)
else:
return arr 我们可以看到,从 LiDAR 坐标系到相机坐标系,x_size 不变,y_size 和 z_size 交换,而 yaw 先取相反数,再减去了 90 度。角度的变换是由于两个坐标系中,yaw = 0 的基准轴 x 轴并不是同一个(相差 90 度),且由于相机坐标系重力轴正方向向下,故 yaw 增长方向从上向下看是顺时针,与 LiDAR 坐标系中相反。因为 x_size 为 yaw = 0 时与 x 轴平行的边的长度,而三大坐标系 yaw = 0 的基准轴都是 x 轴,所以 x_size 始终保持不变;而相机坐标系中的 y 轴对应于 LiDAR 坐标系中的 z 轴,因此 y_size 和 z_size 互换。
而在可视化结果的时候,比如采用 Open3D 或者 MeshLab 进行可视化,需要将检测得到的结果框转换到深度坐标系:
#================ mmdet3d/datasets/kitti_dataset.py ===============#
def show():
# ......
# ground truth
gt_bboxes = self.get_ann_info(i)['gt_bboxes_3d'].tensor.numpy()
show_gt_bboxes = Box3DMode.convert(gt_bboxes, Box3DMode.LIDAR,
Box3DMode.DEPTH)
# 预测结果
pred_bboxes = result['boxes_3d'].tensor.numpy()
show_pred_bboxes = Box3DMode.convert(pred_bboxes, Box3DMode.LIDAR,
Box3DMode.DEPTH)
# 调用 open3d 或 meshlab 进行可视化
show_result(points, show_gt_bboxes, show_pred_bboxes, out_dir,
file_name, show) 在实际使用过程中另一种情况就是该方法是被各个 Boxes 类调用,各个 Boxes 类都提供了 convert_to 方法,比如对于CameraInstance3DBoxes 来说:
#================ mmdet3d/core/bbox/structures/cam_box3d.py ===============#
# 该方法可以将 camera boxes 转换为其他坐标系的 boxes
def convert_to(self, dst, rt_mat=None):
from .box_3d_mode import Box3DMode
return Box3DMode.convert(
box=self, src=Box3DMode.CAM, dst=dst, rt_mat=rt_mat) 需要注意的是,如果不提供旋转平移转换矩阵 rt_mat,我们默认变换前后的坐标系的原点重合,不过通常在实际情况下,相机和激光雷达并不在同一个位置,所以官方会提供转换矩阵,其中会包含一些坐标系间的位置平移变换信息。比如在 KITTI 数据集中,pkl 标注文件中的框是在相机坐标系下标注的,但是在真正的训练过程中,需要将框转换到激光雷达坐标系:
#================ mmdet3d/datasets/kitti_dataset.py ===============#
def get_ann_info(self, index):
# 从 pkl 标注文件中载入 3D Box ground truth
loc = annos['location']
dims = annos['dimensions']
rots = annos['rotation_y']
gt_bboxes_3d = np.concatenate([loc, dims, rots[..., np.newaxis]],
axis=1).astype(np.float32)
# 将 gt_bboxes_3d 首先封装为 Camera Boxes 类,再转换为 LiDAR Boxes 类
# 这里 np.linalg.inv(rect @ Trv2c) 就是通过 KITTI 数据计算得到旋转平移变换矩阵
# 我们在后面对 KITTI 数据集做分析的时候会具体介绍
gt_bboxes_3d = CameraInstance3DBoxes(gt_bboxes_3d).convert_to(
Box3DMode.LIDAR, np.linalg.inv(rect @ Trv2c)) 注意:从上述例子中我们可以看出,我们统一了各个数据集的坐标系,是保证了各个数据集的坐标系(相机、激光雷达、深度坐标系)都满足我们在第一节中的定义,但是各个数据集内部的坐标系之间的相对位置关系会被保留,这种相对位置关系是在各数据集采集的时候,由各个传感器的设置(sensor setup) 决定的。
2.3 Box 的属性

图 9:Box 类属性图
在图中我们列出了部分属性和操作方法,这里有些需要注意的点:
1.默认的 center 属性其实是 bottom_center ,gravity_center 才是物体 3D 框的几何中心点。
2.bev 将 Box 投影到 BEV 视角下,获取带有方向(朝向角)的 2D BEV Box。
3.nearest_bev 则是将 Box 投影到 BEV 视角下后,去掉朝向角,将 Box 和坐标轴对齐后的 2D BEV Box。

图 10:bev 及其对应的 nearest_bev
4.overlaps 类方法主要是用来计算两个 Boxes 类之间的 3D IOU。
将 Boxes 封装为类的一个好处自然就是我们可以为其添加很多属性和操作方法(成员函数),同时可以让不同坐标系下的 Boxes 拥有统一的接口,使得用户在使用他们的时候无需操心他们属于哪个坐标系。举一个很简单的例子:对于 bev 来说,在相机坐标系和激光雷达坐标系下具体的获取方式会有些区别。
#================ mmdet3d/core/structures/cam_box3d.py ===============#
@property
def bev(self):
"""torch.Tensor: 2D BEV box of each box with rotation
in XYWHR format, in shape (N, 5)."""
# 投影到 xz 平面
bev = self.tensor[:, [0, 2, 3, 5, 6]].clone()
# 重力轴 y 轴正方向在相机坐标系中指向下方,所以需要反转 bev 转向角
bev[:, -1] = -bev[:, -1]
return bev
#================ mmdet3d/core/structures/lidar_box3d.py ===============#
@property
def bev(self):
"""torch.Tensor: 2D BEV box of each box with rotation
in XYWHR format, in shape (N, 5)."""
# 投影到 xy 平面
return self.tensor[:, [0, 1, 3, 4, 6]] 而封装后不论 Boxes 在哪个坐标系下,都可以直接使用 bev 属性获取 Boxes 在当前坐标系下的俯视鸟瞰框。
2.4 Box 训练组件
2.4.1 Box Assigner
正负样本属性分配模块的作用是进行正负样本定义或者正负样本分配(可能也包括忽略样本定义),正样本就是常说的前景样本(可以是任何类别),负样本就是背景样本。因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。该模块至关重要,不同的正负样本分配策略会带来显著的性能差异,对应的代码在mmdet3d/core/bbox/assigners中,主要借用的是 MMDetection 的模块:
from mmdet.core.bbox import AssignResult, BaseAssigner, MaxIoUAssigner
__all__ = ['BaseAssigner', 'MaxIoUAssigner', 'AssignResult'] 2.4.2 Box Sampler
在确定每个样本的正负属性后,可能还需要进行样本平衡操作。本模块作用是对前面定义的正负样本不平衡进行采样,力争克服该问题。一般在 3D 目标检测中 3D gt bbox 都是非常少的,所以正负样本比是远远小于 1 的。而基于机器学习观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的,MMDetection3D 提供了一些典型的采样策略如下所示:
from mmdet.core.bbox.samplers import (BaseSampler, CombinedSampler,
InstanceBalancedPosSampler,
IoUBalancedNegSampler, OHEMSampler,
PseudoSampler, RandomSampler,
SamplingResult)
from .iou_neg_piecewise_sampler import IoUNegPiecewiseSampler
__all__ = [
'BaseSampler', 'PseudoSampler', 'RandomSampler',
'InstanceBalancedPosSampler', 'IoUBalancedNegSampler', 'CombinedSampler',
'OHEMSampler', 'SamplingResult', 'IoUNegPiecewiseSampler'
] 2.5 Box 测试组件
2.5.1 Box post-process
在检测任务中非常常见的一个现象就是模型最后输出的 bboxes 数目比较多,而且存在一些重叠的 bboxes 现象,在这一部分,不同任务的后处理对象其实是不太一样的,对应的代码在mmdet3d/core/post_processing 中:
from mmdet.core.post_processing import (merge_aug_bboxes, merge_aug_masks,
merge_aug_proposals, merge_aug_scores,
multiclass_nms)
from .box3d_nms import aligned_3d_nms, box3d_multiclass_nms, circle_nms
from .merge_augs import merge_aug_bboxes_3d
__all__ = [
'multiclass_nms', 'merge_aug_proposals', 'merge_aug_bboxes',
'merge_aug_scores', 'merge_aug_masks', 'box3d_multiclass_nms',
'aligned_3d_nms', 'merge_aug_bboxes_3d', 'circle_nms'
] - 对于点云 3D 检测任务,模型直接输出 3D 空间中的检测得到的 bboxes 的位置、长宽高和朝向等信息,所以通常是在 3D 空间中进行 3D NMS,将检测结果投影到 BEV 视角下进行后处理。相关的代码在
mmdet3d/core/post_processing/box3d_nms.py下。 - 而对于单目 3D 检测任务,不同的方法采用了不同的 post-process 后处理,比如在 FCOS3D / PGD 方法中,后处理同样直接作用于 3D 框,而对于 SMOKE/ MonoFlex 这类方法,后处理则是作用于 2D 图像上,和 2D 检测类似。
其实和 Box 挂钩的东西太多了,很多的 Box 相关的东西还是得配合着模型训练过程来说会有更好的效果。下一篇我们将带大家看看 3D 场景中的可视化组件 Visualizer,如何在多个模态数据上轻松可视化并且自由切换。为什么在可视化的时候经常出现一些莫名其妙的问题(比如 github 上各种和可视化相关的 issue) ,且听下回分解~
最后,我们欢迎大家去体验坐标系重构后的算法库,伴随着坐标系的重构我们也对部分模型进行了精度的升级(比如 PointPillars 在 KITTI 数据集上的 performance) ,希望给大家带来更好的使用体验~~
https://github.com/open-mmlab/mmdetection3dgithub.com/open-mmlab/mmdetection3d