Scrapy框架+Gerapy分布式爬取海外网文章
Scrapy框架+Gerapy分布式爬取海外网文章
- 前言
- 一、Scrapy和Gerapy是什么?
-
- 1.Scrapy概述
- 2.Scrapy五大基本构成:
- 3.建立爬虫项目整体架构图
- 4.Gerapy概述
- 5.Gerapy用途
- 二、搭建Scrapy框架
-
- 1.下载安装Scrapy环境
- 2.建立爬虫项目
- 3.配置Scrapy框架
-
- (1)items.py的配置
- (2)middlewares.py的配置
- (3)pipelines.py的配置
- (4)items.py的配置
- 4.创建爬虫python文件
- 三.编辑爬虫代码
-
- 1.编辑爬虫代码
- 2.执行爬虫代码
- 四.搭建分布式爬虫管理框架
-
- 1.搭建Gerapy
- 2.编辑项目
- 总结
前言
本文主要以海外网(http://www.haiwainet.cn/)为爬取对象,一来是为了完成老师布置的作业,二来是为了留存下自己的学习记录,以便以后遗忘时重新回顾。随着人工智能的不断发展,爬虫这门技术也越来越重要,很多人都开启了学习爬虫,本文就介绍了爬虫学习的基础内容。
一、Scrapy和Gerapy是什么?
1.Scrapy概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 后台也应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持.
2.Scrapy五大基本构成:
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
3.建立爬虫项目整体架构图
本图按顺序说明整个程序执行时候发生的顺序。
注意在调用下载器时,往往有一个下载器中间件,使下载速度提速。
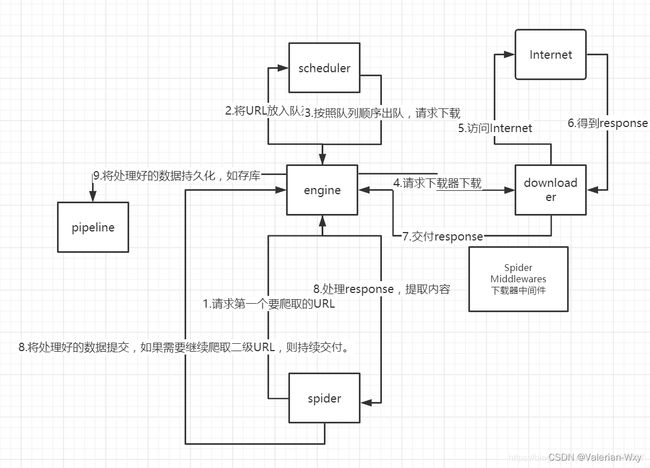
官网架构图

4.Gerapy概述
Gerapy就是将我们爬虫工程师通过Scrapy爬虫框架写好的项目整合到Django的Web环境进行统一管理的后台。简单理为一个Admin后台进行控制我们写好的爬虫脚本,进行有针对性的网络数据采集(比如固定时间、固定间隔、或者一次性采集)方便管理,并且对项目进行简单的项目管理,对于了解Django的Web开发的小伙伴来说后期如果需要报表功能可以基于这个框架自己增加Admin中的模块功能,比较容易。该框架对于初学者非常友好,并且使用简单、高效。
5.Gerapy用途
Gerapy 是一款 分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
1.更方便地控制爬虫运行
2.更直观地查看爬虫状态
3.更实时地查看爬取结果
4.更简单地实现项目部署
5.更统一地实现主机管理
二、搭建Scrapy框架
1.下载安装Scrapy环境
代码如下(示例):
pip install scrapy==2.6.1
本文作者使用Windows系统,使用组合键Win+R并输入cmd打开终端,并在终端中输入图示代码
结果如图:
2.建立爬虫项目
首先进入我们创建爬虫项目的文件夹,点击右键进入Power Shell终端,使用如下代码创建新项目
代码如下(示例):
scrapy startproject NewsHaiwai

结果如图
3.配置Scrapy框架
首先进入我们创建的文件夹,作者使用的软件是VScode
可以看到,打开我们的NewsHaiwai文件夹,其中配置文件有四个:items.py、middleware.py、pipelines.py、settings.py。
(1)items.py的配置
代码如下(示例):
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NewshaiwaiItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()#标题
url = scrapy.Field()#网址
date = scrapy.Field()#日期
content = scrapy.Field()#文章正文
site = scrapy.Field()#站点
item = scrapy.Field()#栏目
本文作者使用Windows系统,使用组合键Win+R并输入cmd打开终端,并在终端中输入图示代码
结果如图:
(2)middlewares.py的配置
首先第一行添加
# -*- coding: utf-8 -*-
然后在最下边添加Header和IP类:
# 添加Header和IP类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware#从scrapy.down...导入中心键
from scrapy.utils.project import get_project_settings
import random
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')#创建一个UA列表,每次访问随机抽取一个
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")
本文作者使用Windows系统,使用组合键Win+R并输入cmd打开终端,并在终端中输入图示代码
结果如图:
(3)pipelines.py的配置
代码如下(示例):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymongo
# useful for handling different item types with a single interface
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class NewshaiwaiPipeline:
# class中全部替换
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
sheetname = settings["MONGODB_TABLE"]
username = settings["MONGODB_USER"]#monggodb没有密码的情况下就把这两行注释掉即可
password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
#client = pymongo.MongoClient(host=host, port=port)#没有密码的时候
# 指定数据库
mydb = client[dbname]
# 存放数据的数据库表名
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert_one(data)#insert()/insert_one()适用于高版本python
return item
(4)items.py的配置
首先在最上边添加:
# -*- coding: utf-8 -*-
然后将机器人协议选为不遵守(20行):
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
然后将中间件组件从注释中释放(54行),并按照如图修改:
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'NewsHaiwai.middlewares.RotateUserAgentMiddleware': 543,
}
然后将写入MONGODB组件从注释中释放(67行):
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'NewsData.pipelines.NewsdataPipeline': 300,
}
最后在下边添加如图所示代码,添加UA和MONGODB数仓设置:
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 添加MONGODB数仓设置
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "NewsHaiwai" # 数仓数据库
MONGODB_TABLE = "News_Haiwai_A" # 数仓数据表单
4.创建爬虫python文件
在终端中使用如下代码,其中” “所代表的含义是目标引用的作用域是全域:
scrapy genspider haiwainet " "
结果如图:

三.编辑爬虫代码
1.编辑爬虫代码
在VScode中打开我们创建的爬虫python文件
使用如下代码编辑:
# -*- coding: utf-8 -*-
import scrapy#导入scrapy库
from NewsHaiwai.items import NewshaiwaiItem#和最初创建的文件夹名字相同,即NewshaiwaiItem的item.py文件中
from bs4 import BeautifulSoup#导入BeautifulSoup
class HaiwainetSpider(scrapy.Spider):
“这个类用于爬虫”
name = 'haiwainet'#命名爬虫名称,在终端中执行
allowed_domains = []#作用域
start_urls = [
['http://opinion.haiwainet.cn/456317/', '海外网', '评论-侠客岛1','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/2.html', '海外网', '评论-侠客岛2','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/3.html', '海外网', '评论-侠客岛3','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/4.html', '海外网', '评论-侠客岛4','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/5.html', '海外网', '评论-侠客岛5','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/6.html', '海外网', '评论-侠客岛6','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/7.html', '海外网', '评论-侠客岛7','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/8.html', '海外网', '评论-侠客岛8','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/9.html', '海外网', '评论-侠客岛9','20201935王新宇'],
['http://opinion.haiwainet.cn/456317/10.html', '海外网', '评论-侠客岛10','20201935王新宇'],
['http://opinion.haiwainet.cn/456465/', '海外网', '评论-港台腔','20201935王新宇'],
['http://opinion.haiwainet.cn/345415/', '海外网', '评论-海外舆论','20201935王新宇'],
['http://news.haiwainet.cn/yuanchuang/', '海外网', '咨讯-原创','20201935王新宇'],
['http://www.haiwainet.cn/roll/', '海外网', '咨讯-滚动','20201935王新宇'],
['http://opinion.haiwainet.cn/456318/', '海外网', '理论-学习小组','20201935王新宇'],
['http://huamei.haiwainet.cn/bagua/ ', '海外网', '华媒-秀八卦','20201935王新宇'],
['http://huamei.haiwainet.cn/news/', '海外网', '华媒-新闻','20201935王新宇'],
['http://huamei.haiwainet.cn/hanwainet/CentralKitchenPlatform/World/ ', '海外网', '华媒-国际资讯','20201935王新宇'],
['http://singapore.haiwainet.cn/', '海外网', '新加坡-滚动资讯','20201935王新宇'],
['http://us.haiwainet.cn/News1/', '海外网', '美国-时事新闻','20201935王新宇'],
#爬取网站列表+站点+栏目+学号姓名
def start_requests(self):
for url in self.start_urls:
item = NewshaiwaiItem()#生成字典
item["site"] = url[1]#设置站点
item["item"] = url[2]#设置栏目
item["student_id"] = url[3]#设置学号姓名
# ['http://opinion.haiwainet.cn/456317/', '海外网', '评论-侠客岛','20201935王新宇']传进来的url
yield scrapy.Request(url=url[0],meta={"item": item},callback=self.parse)#利用生成器进行迭代返回
def parse(self, response):
item = response.meta["item"]#承接之前参数
site_ = item["site"]#利用site_充当中间传递变量
item_ = item["item"]#利用item_ 充当中间传递变量
student_id_ = item["student_id"]#利用student_id_充当中间传递变量
title_list = response.xpath(
'//*[@id="list"]/li/h4/a/text()').extract()#爬取title
url_list = response.xpath(
'//*[@id="list"]/li/h4/a/@href').extract()#爬取二级网址
date_list = response.xpath(
'//*[@id="list"]/li/div/span/text()').extract()#爬取日期
#//*用于匹配所有符合要求的节点 //匹配子孙节点 /用于获取直接子节点
for each in range(len(title_list)):
item=NewshaiwaiItem()#定义字典,此时item是一个空字典
item['title']=title_list[each]#通过for循环的下标访问每一个item的标题、url、date
item['url']=url_list[each]#设置二级链接
item['date']=date_list[each]#设置日期
item["site"] = site_#设置站点
item["item"] = item_#设置栏目
item["student_id"] = student_id_#设置学号姓名
#print(item)#检查是否出错
yield scrapy.Request(url=item["url"], meta={"item": item}, callback=self.parse_detail)
#meta表示携带response里边的参数,固定写法meta={"item": item}
def parse_detail(self,response):
item=response.meta["item"]
strs=response.xpath('/html/body/div[3]/div/div[2]/div/p/text()').extract()#此时得到的是一个列表,有多个p标签
#如果想要文章原结构就不使用text()
#此步不能使用//*
#最后还可以通过extract()[0]的方式解决列表赋值给字符串的问题
#其中item["content"]是一个字符串,但是后边匹配的结果是一个列表,所以通过取出列表第一个元素的方法或者使用从列表取出字符串的方式
#本文选择使用匿名函数从列表取出字符串的方式解决
#item["content"]=BeautifulSoup(strs,'lxml').text
item["content"] = " ".join('%s' %id for id in strs)
return item#把数据写入mongodb
2.执行爬虫代码
在终端中执行如下代码:
scrapy crawl haiwainet
在Navicat查看,结果如图:

四.搭建分布式爬虫管理框架
1.搭建Gerapy
首先打开命令行,输入如下代码下载所需包:
pip install gerapy==0.9.11
pip install scrapyd
然后在目标文件夹下打开终端,在终端中执行如下代码:
gerapy init
gerapy migrate
结果如图:

然后在终端中执行如下代码:
gerapy initadmin
结果如图,其中结果表明用户创建成功,用户名是admin,密码是admin:
![]()
然后在终端中执行如下代码(关闭防火墙):
gerapy runserver 0.0.0.0:8000
然后就可以在网站上登录到网页进行分布式爬虫了:

然后再全局搜索中打开scrapyd文件所在位置,再终端中运行scrapyd.exe,保留命令窗口:
然后在浏览器中登录到127.0.0.1:8000
2.编辑项目
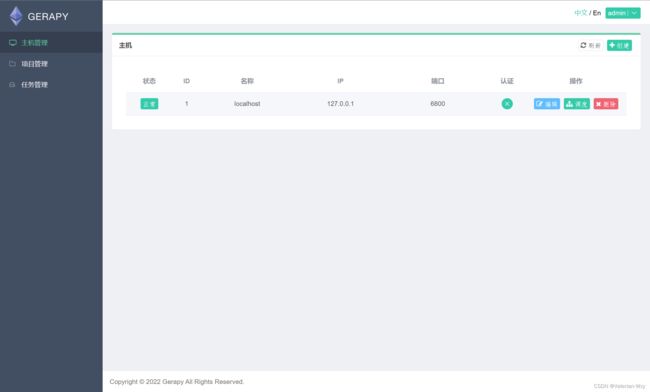
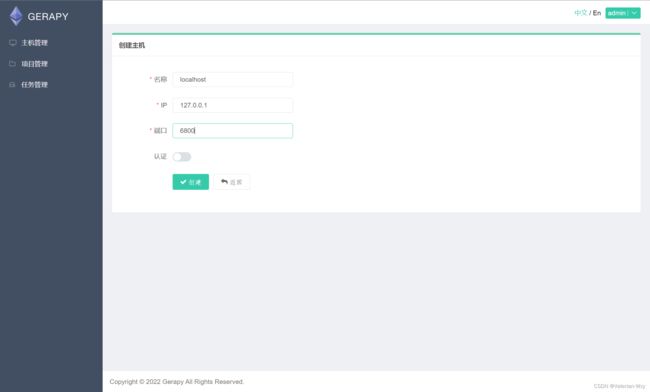
(1)主机管理
结果如图:
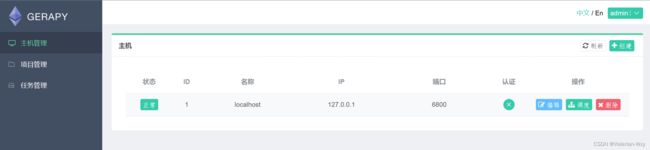
成功如图:
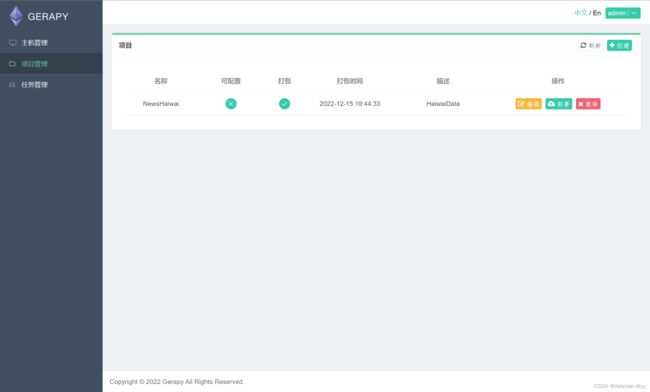
(2)项目管理
将含有cfg文件后缀的爬虫项目的上级文件目录复制到gerapy文件下的projects文件中,在浏览器中刷新,即结果如图:
添加对应描述(英文),打包,点击部署:

(3)任务管理
根据自己的需要设置时间,或者时间间隔,小编这里设置的时间间隔为1天为例,开始实践为1分钟后(为了快速看运行情况)。
ps:目前版本还没有北京时间,推荐使用Hong_Kong时间
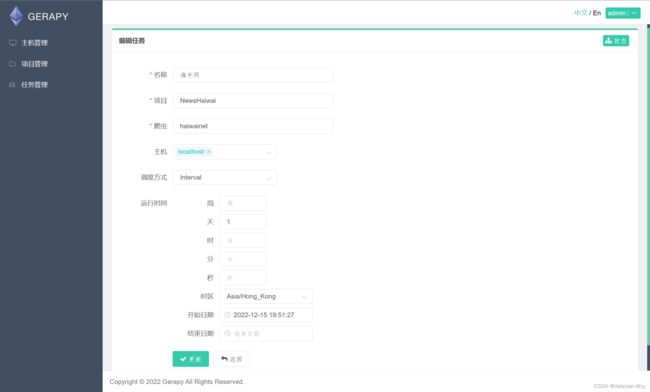
查看任务状态:


总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
学习来源:
https://blog.csdn.net/ck784101777/article/details/104468780
https://blog.csdn.net/bookssea/article/details/107309591
https://blog.csdn.net/weixin_44088790/article/details/115017625
https://blog.csdn.net/zhao1299002788/article/details/108808112
https://feishujun.blog.csdn.net/article/details/117200531
https://blog.csdn.net/weixin_65350557/article/details/128319447