机器学习-Sklearn(第三版)Day1 决策树
1 概述
决策树( Decision Tree )是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规 则
并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各 种问题时都有良好表现
尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
1.1 sklearn中的决策树
在sklearn模块中决策树是 sklearn.tree
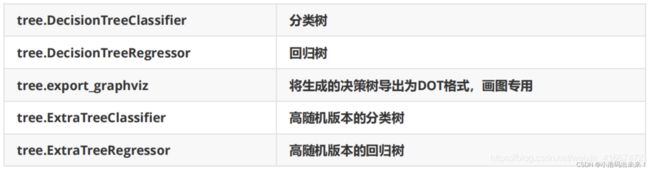
sklearn 中决策树的类都在 ”tree“ 这个模块之下。这个模块总共包含五个类:
在开始敲代码之前,我们先看看sklearn建模的基本流程:
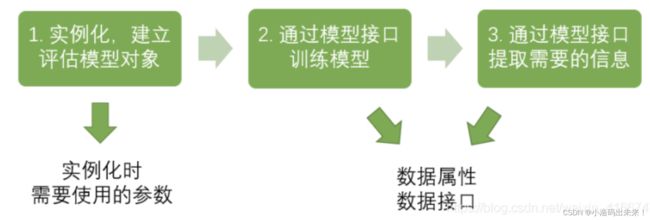
如果按照上图的流程,分类树的建模流程就是:
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息是不是只用了三行呢?!
下面我们用一个具体的例子来讲解分类树
2 DecisionTreeClassififier与红酒数据集
我们先看看分类树的参数:

是不是傻眼了?这么多,看到都脑阔疼。
没关系,接下来我们挑选其中重要的参数配合实际的例子来讲清楚。
2.1 重要参数
2.1.1 criterion
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个 “ 最佳 ” 的指标 叫做“ 不纯度 ” 。
通常来说,不纯度越低,决策树对训练集的拟合越好。现在使用的决策树算法在分枝方法上的核心 大多是围绕在对某个不纯度相关指标的最优化上。
不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是 说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
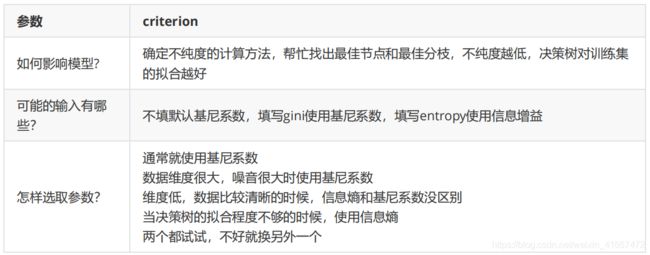
Criterion 这个参数正是用来决定不纯度的计算方法的。 sklearn 提供了两种选择:
1 )输入 ”entropy“ ,使用 信息熵 ( Entropy )
2 )输入 ”gini“ ,使用 基尼系数 ( Gini Impurity )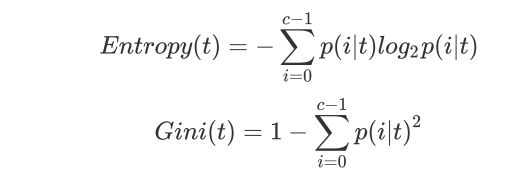
其中 t 代表给定的节点, i 代表标签的任意分类, 代表标签分类i 在节点 t 上所占的比例。
注意,当使用信息熵 时,sklearn 实际计算的是基于信息熵的信息增益 (Information Gain) ,即父节点的信息熵和子节点的信息熵之差。
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。
但是 在实际使用中,信息熵和基尼系数的效果基 本相同。
信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。
另外,因为信息熵对不纯度更加敏感,所以信息熵作为指标时,决策树的生长会更加“ 精细 ”
因此对于高维数据或者噪音很多的数据,信息熵很容易 过拟合,基尼系数在这种情况下效果往往比较好。
当模型拟合程度不足的时候,即当模型在训练集和测试集上都表 现不太好的时候,使用信息熵。当然,这些不是绝对的。
到这里,决策树的基本流程其实可以简单概括如下:

下面我们真的要开始上代码了,一般大多数讲决策树的教程都会用鸢尾花(iris)数据集
但是用这个数据集不太好,原因是有一个参数不能够用这个数据集很清楚的介绍,下面我们会讲到
所以本文用的是红酒数据集:
(使用sklearn的决策树算法对葡萄酒数据集进行分类)
问题如下:
使用sklearn的决策树算法对葡萄酒数据集进行分类,要求:
①划分训练集和测试集(测试集占20%)
②对测试集的预测类别标签和真实标签进行对比
③输出分类的准确率
④调整参数比较不同算法(ID3,C4.5,CART)的分类效果。
首先,要确保你的计算机上有机器学习的环境,如果没有,请看作者文章《机器学习-环境配置(windows版)》
然后我们打开cmd,输入指令:
jupyter lab代码实现:
1.导入依赖包
#导入相关库
import sklearn
from sklearn.model_selection import train_test_split
from sklearn import tree #导入tree模块
from sklearn.datasets import load_wine
from math import log2
import pandas as pd
import graphviz
import treePlotter
2.导入数据集
#导入数据集
wine = load_wine()
X = wine.data #X
Y = wine.target #Y
features_name = wine.feature_names
print(features_name)
pd.concat([pd.DataFrame(X),pd.DataFrame(Y)],axis=1)
#打印数据

3.划分数据集,数据集划分为测试集占20%
#划分数据集,数据集划分为测试集占20%;
x_train, x_test, y_train, y_test = train_test_split(
X, Y,test_size=0.2)
# print(x_train.shape) #(142, 13)
# print(x_test.shape) #(36, 13)
4.导入模型,进行训练
#采用C4.5算法进行计算
#获取模型
model = tree.DecisionTreeClassifier(criterion="entropy",splitter="best",max_depth=None,min_samples_split=2,
min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features=None,
random_state=None,max_leaf_nodes=None,class_weight=None);
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
y_predict = model.predict(x_test)
print('准确率为:',score)
#准确率为: 0.9444444444444444
5.对测试集的预测类别标签和真实标签进行对比
pd.concat([pd.DataFrame(x_test),pd.DataFrame(y_test),pd.DataFrame(y_predict)],axis=1)
#打印数据,对测试集的预测类别标签和真实标签进行对比
最后两列为真实标签和预测类别标签
6.调整参数比较不同算法(ID3,C4.5,CART)的分类效果
#采用CART算法进行计算
#获取模型
model = tree.DecisionTreeClassifier(criterion="gini",splitter="best",max_depth=None,min_samples_split=2,
min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features=None,
random_state=None,max_leaf_nodes=None,class_weight=None);
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
y_predict = model.predict(x_test)
print('准确率为:',score)
#准确率为: 1.0
7.画出最后预测的树

泰坦尼克号幸存者的预测
泰坦尼克号的沉没是世界上最严重的海难事故之一,今天我们通过分类树模型来预测一下哪些人可能成为幸存者。数据集来着https://www.kaggle.com/c/titanic,数据集会随着代码一起提供给大家,大家可以在下载页面拿到,或者到群中询问。数据集包含两个csv格式文件,data为我们接下来要使用的数据,test为kaggle提供的测试集。
接下来我们就来执行我们的代码。
1. 导入所需要的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt2. 导入数据集,探索数据
data = pd.read_csv(r"C:worklearnbettermicro-classweek 1 DTdatadata.csv",index_col
= 0)
data.head()
data.info()3. 对数据集进行预处理
#删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1) #处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data["Age"] = data["Age"].fillna(data["Age"].mean())
data = data.dropna()
#将分类变量转换为数值型变量
#将二分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这
个方式可以很便捷地将二分类特征转换为0~1
data["Sex"] = (data["Sex"]== "male").astype("int") #将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
#查看处理后的数据集
data.head()4. 提取标签和特征矩阵,分测试集和训练集
X = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3) #修正测试集和训练集的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
#查看分好的训练集和测试集
Xtrain.head()5. 导入模型,粗略跑一下查看结果
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score_ = clf.score(Xtest, Ytest)
score_
score = cross_val_score(clf,X,y,cv=10).mean()
score6. 在不同max_depth下观察模型的拟合状况
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion="entropy"
)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()#这里为什么使用“entropy”?因为我们注意到,在最大深度=3的时候,模型拟合不足,在训练集和测试集上的表现接近,但却都不是非常理想,只能够达到83%左右,所以我们要使用entropy。
7. 用网格搜索调整参数
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
GS.best_params_
GS.best_score_