【视频异常检测综述-论文阅读】Deep Video Anomaly Detection: Opportunities and Challenges
来源:
Ren, Jing, et al. “Deep Video Anomaly Detection: Opportunities and Challenges.” 2021 International Conference on Data Mining Workshops (ICDMW), Dec. 2021. Crossref, https://doi.org/10.1109/icdmw53433.2021.00125.
文章连接:https://arxiv.org/abs/2110.05086
1.摘要
异常检测在各种研究环境中是一项热门而重要的任务,已经研究了几十年。为了确保人们的生命和财产安全,视频监控已广泛部署在各种公共场所,如十字路口、电梯、医院、银行,甚至在私人住宅中。深度学习在声学、图像和自然语言处理等多个领域都显示了其能力。然而,设计智能视频异常检测系统并非易事,因为在不同的应用场景中,异常之间存在显著差异。如果这种智能系统能够在我们的日常生活中实现,那么它将具有许多优势,例如在很大程度上节省人力资源,减轻政府的财政负担,以及及时准确地识别异常行为。
最近,出现了许多关于扩展深度学习模型以解决异常检测问题的研究,从而在深度视频异常检测技术方面取得了有益的进展。
本文从一个新的角度全面回顾了基于深度学习的视频异常检测方法。具体来说,我们分别总结了深度学习模型在视频异常检测任务中的机遇和挑战。我们提出了智能视频异常检测系统在各个应用领域的几个潜在的未来研究方向。此外,我们总结了当前视频异常检测深度学习方法的特点和技术问题。
2.INTRODUCTION
随着监控摄像机部署成本的降低,视频监控的应用被广泛扩展到不同场景。在过去几十年中,深度学习取得了巨大的成功,并在许多以前被认为在计算上无法实现的任务中表现出了优异的性能,例如人脸匹配[2]、推荐系统[3]和异常检测[4]。相应地,越来越多的人致力于基于深度学习模型的视频异常检测。
智能视频异常检测系统能够检测明显偏离正常的异常行为或实体,例如在视频监控的先验知识有限的情况下识别多个移动物体,或检测特定事件,例如打架、踩踏、交通事故和流浪。视频异常通常是上下文的,并根据真实场景定义。例如,在超市或演唱会中观察人群聚集是正常的,而当需要社会距离来阻止病毒传播时,观察人群聚集是异常的。在大多数视频异常检测算法中,大多数算法可以在时间和空间上定位异常。具体来说,检测过程集中于识别所有视频中包含异常的视频片段,而定位致力于确定哪一帧是异常的,并解释该帧的哪一部分是异常的。最近的相关研究可以通过提供端到端解决方案的基于深度学习的模型来处理这两个问题。
视频监控中的异常检测仍然面临一系列挑战:
- 模糊性:异常检测被广泛认为是检测在特定情况下预期不会出现的事件的过程。然而,在现实世界中,正常和异常之间的边界没有明确划分。例如,一些正常样本也会表现出异常事件所具有的奇怪特征,这阻碍了模型的检测精度。
- 依赖性:到目前为止,尽管在许多文献中都引入了对异常的统一定义。另一方面,所有这些差异都不能直接应用于特定的异常检测任务中。即使是同一事件也可能具有不同的特征,并且在不同的背景下也有很大差异。异常的上下文依赖性使检测模型无法适应。
- 稀疏性和多样性:与一般分类任务不同,在实际异常检测数据集中,正样本(即异常)远小于负样本。这种数据不平衡的特性使得监督模型难以训练。此外,现实世界中的异常行为多种多样,无法完全说明,有时甚至可能尚未发生。因此,在一个模型中考虑所有可能的异常类型是不切实际的。
- 隐私问题:在检测非视频数据集中的异常时,用户的私人信息(例如姓名)可以被随机泛化码所取代,这对最终的实验结果没有影响。而在视频监控数据中,尤其是包括面部和行为信息,如果数据是开源的,则会侵犯个人隐私。这种隐私特性导致缺少开源数据集。
- 噪音:随着视频监控的广泛覆盖,为了提高安全性,人们部署了摄像机。摄像机经常出现在电梯、十字路口、商场、餐馆甚至一些私人住宅中。虽然现有成像设备很容易支持获取视频监控数据,但手动注释这些数据是一个耗时的过程,并且容易出错。数据的噪声最终无疑会影响模型的准确性。
A. Relevant Surveys
为了应对上述挑战,人们设计了各种算法,并取得了显著的实验结果。已有相关调查介绍了视频异常检测模型。
- Kiran等人[10]回顾了无监督和半监督视频异常检测模型。
- Mabrouk和Zagrouba[11]详细介绍了智能视频异常检测系统内的过程,包括特征提取和描述。
- Pawar和Attar[12]分析了基于视频的异常活动检测的深度学习技术。姚和胡[13]介绍了基于传统和深度学习的视频暴力检测方法。
- [14]和[15]对基于深度学习的视频异常检测模型进行了全面调查,分类差异较小,而[14]还有一部分评估了模型的性能。
- 苏等人[16]总结了现有视频序列中暴力检测的最新方法。
- Roshan等人[17]回顾了暴力检测的最新趋势,并对不同的最先进的浅层和深层模型进行了比较研究。
- Ramzan等人[18]回顾了各种最先进的暴力检测技术,这些技术不仅限于深度学习模型。
- 在[19]中,作者对基于深度学习的图像和视频数据异常检测方法进行了深入分析。此外,还讨论了当前面临的挑战和未来的研究方向。
我们的工作在两个方面与之前的研究不同。一方面,本调查研究了视频异常检测系统可以应用的各种应用,这些应用不限于固定领域。另一方面,我们系统地总结了不同应用中的潜在机会,以及目前算法中仍然存在的挑战,而不是像其他调查那样比较算法背后的机制。
B. Contributions
- 对深度学习方法在视频异常检测方面的机遇和挑战进行了前瞻性总结
- 提出了智能视频异常检测系统在各个应用领域的一系列潜在研究和发展方向
- 对视频异常检测深度学习方法中的主要技术挑战进行了全面分析,从而为进一步改进模型提供了见解
3. OPPORTUNITIES
大多数现有研究致力于检测交通视频监控中的异常,而视频异常检测任务广泛存在于各种现实场景中。在本节中,我们不仅介绍了智能交通中的深度视频异常检测,还概述了其他领域的一些潜在机会,即数字教育、智能家居、公共卫生和数字孪生。
A. Intelligent Transportation
交通运输是人类社会生产、生活和经济发展的重要组成部分。当前的交通系统为人们提供了快速、舒适和安全的交通服务。然而,快速增长的人口对交通的日益增长的需求直接导致了机动车数量的爆炸性增长。因此,交通拥堵、交通事故频发等问题随之而来。为此,智能交通系统(ITS)应运而生,实践证明,智能交通系统是解决当前经济发展引起的交通问题的理想方案。
众所周知,ITS是其他视频异常检测应用中最热门的研究方向,在检测结果方面也取得了显著的改进。道路交通场景中的异常检测任务通常很广泛,重点是车辆、行人、环境等实体及其相互作用。考虑到交通监控系统的检测精度受天气和交通状况等多种因素的影响,人们致力于研究智能交通系统中检测结果的鲁棒性。
随着深度学习和无线通信技术的最近发展,开发了许多创新的交通监控系统。Li等人[30]旨在以无监督的方式检测车辆异常情况(如交通事故)。检测框架是使用Faster R-CNN[31]构建的,其采用了SENet[32]作为主干特征提取器。Aboah[33]提出了一种基于视觉的交通异常检测系统。异常检测过程由三个主要部分组成:用于提取背景特征的背景估计器、用于过滤虚假异常候选的道路掩码提取器以及用于确认和最终检测结果的决策树。尽管不断开发新的基于深度学习的模型来提高不同环境下的视频异常检测精度,但在未来的工作中仍有许多有待研究的开放机会。例如,学习算法和系统的实际部署之间仍然存在巨大差距。此外,应提高自动驾驶模拟环境的真实性,以确保模型在不稳定交通情况下的鲁棒性。
B. Online Education
由于过去十年信息和通信技术的发展,传统的离线教学和学习过程正逐渐转向在线平台。2019冠状病毒疾病的爆发加速了这一过程。由于这种流行病,在未来一段时间内,在线教育将成为知识传递的主要方式。同时,在线考试也随着时间的需要而普及。有效检测作弊行为和远程在线考试是确保考生公平的重要前提。然而,传统的作弊检测方法可能不再能够完全成功地防止考试期间的作弊。有必要设计一个人工智能系统来自动检测考试中的作弊行为。
实际上,已经开发了一系列技术并将其应用于智能监护系统,例如视线跟踪、语音检测和识别检查期间不允许存在的任何实体。这些技术在节省人力的同时,带来了公平、客观的检查监督。Atoum等人[35]提出了一种OEP系统,通过使用wearcam和网络摄像头,自动、连续地检测在线考试期间的作弊行为。尽管wearcam可以提供更广阔的视野,但在家为每个学生配备wearcam仍然不现实。Bawarith等人[36]在电子考试管理系统中提出了一种在线保护器,实现了指纹认证和眼动跟踪。此外,还可以检测到离开屏幕的学生。张和李[37]提出了一种深度学习系统,即DenseLSTM,作为行为检测代理。该方法可以提取更好的特征表示并增强网络的特征激活,这对于预测潜在的电子欺骗行为是有效的。智能监考系统的流程图如下图所示
本质上,教育视频监控系统是学生学习行为的完整记录。这种视频数据比传统形式的教育数据存储保留了更多细节。例如,对于大多数教育利益相关者,包括研究人员,课程分数或学生的平均成绩(GPA)通常用于评估该学生的知识掌握情况。这种方法带来了便利,同时丢失了太多信息。随着计算能力的提高,我们能够快速处理大量数据。通过视频记录学习过程无疑为分析教学提供了很大帮助。学习过程的视频记录无疑保留了学生的整个学习过程以及考试过程。除了作弊检测之外,这还为所有与教育相关的异常分析提供了数据安全,包括课程失败分析、心理问题等
C. Smart Home
为了确保家里的安全,许多人在家里安装了视频监控系统。视频监控是家庭自动化系统的一小部分,被认为是全面的安全保障[38]。人们可以使用手机和电脑观看视频,随时随地掌握实时的家庭情况。由于一直盯着屏幕看会浪费时间和精力,因此自动识别异常行为并立即发送报警信号无疑是必要的。
Yhaya等人[40]提出了一种用于人类活动中异常恶意检测的自适应系统。这种数据驱动的系统适应人类行为常规的变化,并有能力通过嵌入遗忘机制抛弃旧的行为模式。Withange等人[41]研究了应用计算机视觉通过RGB-D成像识别坠落位置,以便于在老年人独立生活中基于机器人的坠落事故现场辅助。Markovitz等人[42]直接研究了可以从视频序列构建的人体姿势图,该图不会受到视点或照明等有害参数的影响。这种无监督的深度学习模型可以通过学习正常行为来识别异常的人类行为。类似地,Morais等人[43]还通过对其模型中耦合特征的动力学和相互作用进行建模,了解了骨骼轨迹的规律性。该模型的一个优点是,它可以解释其内部推理和相应因素的可视化。这是基于深度学习的异常检测模型的重要组成部分
现有的研究大多集中在视频监控技术上,当有人出现在网络摄像机中时,可以记录视频片段,而自动异常检测很少研究。老年抚养比的增加是全世界面临的一个常见问题,这增加了政府为养老金和医疗保健提供资金的额外负担[44]。然而,对于负担不起照顾者或喜欢独居的人,如果在家中安装了智能视频异常检测系统,老年人可以独立生活,并且可以及时检测和处理紧急情况(例如,老年人摔倒)。因此,开发智能家居中的视频异常检测系统对提高人类生活的质量和便利性具有重要意义。事实上,这种智能系统也可以安装在医院和疗养院,以减少未知事故带来的风险
D. Public Health
公共卫生是一个跨学科领域,涉及流行病学、生物统计学、社会科学等多个领域。此外,环境卫生、社区卫生、行为卫生、心理卫生和其他重要子领域也包括在公共卫生范围内。公共卫生的主要目的是通过预防和治疗疾病来提高人类生活质量。通过监测病例和健康指标,视频异常检测可以从多个角度造福于公众健康。以名为2019年冠状病毒病(COVID-19)的流行病为例,为了避免传染病的进一步传播,可以应用智能视频监控系统来检测异常行为[47]、[48]。Bhambani等人[49]提出了一种实时面罩和社交距离违规检测系统,该系统使用视频片段和图像上的YOLO对象检测。左等人[50]开发了一种基于深度学习的行人社会距离检测系统,该系统可用于分析大流行期间城市流动性的新规范。Saponara等人[51]为2019冠状病毒疾病实现了一个基于人工智能的实时系统,该系统由深度学习对象检测模型和社交距离计算算法组成。智能监控系统利用实时视频信息检测异常模式并执行预测分析。然后识别异常类型,然后启动预定义信号以执行补救措施。通过可穿戴传感器、用户特定行为模式和室内环境参数,可以监测和进一步分析居民的健康状况[52]。基于视觉的环境辅助生活,也称为AAL,旨在改善老年人和弱势群体的日常生活。与环境传感器或佩戴式传感器相比,视频异常检测技术更便宜、更有效、更易于实施。例如,基于RGB摄像机、多摄像机和深度摄像机开发了坠落检测方法[53]。患者监控系统也是视频异常检测在公共卫生领域的另一个重要应用。在医院,这种系统用于更好地定期观察患者,可以检测病房中的异常活动,包括不规则姿势、不平衡行走、爬床等[54]。Cattani等人[55]提出了一种通过从视频中提取和处理运动信号来评估病理运动周期性可能性的方法。鉴于摄像机的低成本和计算机视觉技术的成熟,公共健康中的异常检测必将得到进一步发展。基于视觉的方法可以与其他传感器数据相结合,以提高其鲁棒性和准确性。
智能监控系统利用实时视频信息检测异常模式并执行预测分析。然后识别异常类型,然后启动预定义信号以执行补救措施。通过可穿戴传感器、用户特定行为模式和室内环境参数,可以监测和进一步分析居民的健康状况[52]。基于视觉的环境辅助生活,也称为AAL,旨在改善老年人和弱势群体的日常生活。与环境传感器或佩戴式传感器相比,视频异常检测技术更便宜、更有效、更易于实施。例如,基于RGB摄像机、多摄像机和深度摄像机开发了坠落检测方法[53]。患者监控系统也是视频异常检测在公共卫生领域的另一个重要应用。在医院,这种系统用于更好地定期观察患者,可以检测病房中的异常活动,包括不规则姿势、不平衡行走、爬床等[54]。Cattani等人[55]提出了一种通过从视频中提取和处理运动信号来评估病理运动周期性可能性的方法。鉴于摄像机的低成本和计算机视觉技术的成熟,公共健康中的异常检测必将得到进一步发展。基于视觉的方法可以与其他传感器数据相结合,以提高其鲁棒性和准确性。
E. Digital Twins
在工业环境中,准确的异常检测有助于早期检测潜在故障和主动维护计划管理。为了实现高性能异常检测,近年来,在动态工业边缘/云网络中实现数字孪生技术的研究兴趣不断增长。通常,数字孪生技术用于构建虚拟环境,作为物理对象或过程的实时数字对应物。此外,数字孪生技术的进步可以帮助实现复杂机械的真实模拟,从而加快实现智能制造和工业4.0的进程。
如今,在异常检测任务中,学术界和工业界越来越认识到将数字孪生与深度学习相结合的重要性[58]。在[59]中,作者使用DT生成了涵盖一整年运行的正常运行数据的大型数据集。然后,以弱监督的方式将暹罗Au-toencoder(SAE)架构应用于异常检测。由于电网的临界性质,检测电网异常的能力至关重要[60]。在本文中,作者使用卷积神经网络(CNN)在电气系统自动网络保护(ANGEL)数字孪生环境中检测电力系统中的物理故障。该方法不仅可以检测电力系统中的故障,而且具有识别哪些母线包含异常的能力。Gao等人[61]使用DT收集实时数据并实现实时缺陷识别。随着新型异常的出现,传统模型被重新构建耗时且成本高昂。为了解决这个问题,他们提出了一种用于新类别识别的深度终身学习方法。
应该注意的是,上述所有DT驱动的异常检测系统不能直接应用于视频监控数据。在现代工业中,摄像机以高密度部署,以无缝监控机器的状态和工人的活动[58]。DT技术可以采用现代数据可视化方案,如虚拟现实(VR)和增强现实,以提供更具插图和用户友好的视图。因此,可以进一步利用深度学习模型和数字孪生技术的集成来解决视频异常检测任务。此外,DT技术能够生成包含不同上下文中异常的合成数据集,从而解决了缺少具有足够正样本且无噪声的数据集的问题。图2显示了结合数字孪生技术和深度学习模型的异常检测/预测系统的架构图。

III. CHALLENGES
针对各种应用中遇到的不同类型的异常和技术困难,提出了许多基于深度学习的模型和智能系统。显然,这些模型和系统可以在很大程度上帮助减少人力资源消耗,并使人们的生活更加方便。然而,视频异常检测仍然存在许多问题和挑战。
在本节中,我们根据模型结构(即基于重建的模型、预测模型、生成模型、一类分类模型和混合模型)讨论了模型中存在的技术问题和挑战。不同类别的模型之间有一些联系。例如,预测模型可以使用生成器来预测视频的下一帧,使用鉴别器来判别预测是真是假。下表总结了这些模型之间的比较。
| 类型 | Assumption | Drawback |
|---|---|---|
| 基于重建的模型 | 正常数据的重建误差值较低。相反,异常数据会获得更高的值 | 模型泛化良好时无效;难以解释 |
| 预测模型 | 正常数据可以很好地预测,即预测帧和实际帧之间的差异比异常数据更接近 | 更高的计算复杂度 |
| 生成模型 | 生成器生成鉴别器网络的不规则性,并将鉴别器训练为二进制分类器 | 训练昂贵;不稳定;再生产困难;模式崩溃 |
| 一类分类模型 | 正常数据被压缩到超平面或超球体中,任何显著偏离正常行为的行为都被称为异常 | 训练时间更长 |
| 混合模型 | 深度学习模型用作特征提取器来生成特征表示,并将特征表示输入分类算法中 | 表示学习和分类模型分离导致检测性能不理想 |
A. Reconstruction-based Models
与正常实例相比,异常实例通常很少。为了解决这个问题,基于重建的异常检测方法通常以无监督的方式学习正常行为的特征。重建模型的基本思想是在测试阶段以较低的重建误差值重建正常数据,并使其分布更接近训练数据。相应地,异常数据的重建误差预计会更高。深度自动编码器[74]是重建模型中最常用的模型,它由一个编码器Encoder和一个解码器Decoder组成,前者将输入向量压缩到低维向量中,后者将该密集向量重建回输入向量。DeepAD[75]的目标是最小化输入向量 和重构向量之间的重构误差
和重构向量之间的重构误差 :
:
![]()
其中N是正常的训练数据,D(E(·))是DeepAD框架。在这里,编码器可以是任何类型的神经网络,例如卷积神经网络(CNN)和长短时记忆(LSTM)。尽管DeepAD及其变体很受欢迎,但龚等人[76]指出,如果自动编码器无法概括异常数据,则无法满足重建误差值较高的异常假设。换句话说,异常是使用广义模型重建的,编码器生成的表示不能保证其有效性。因此,该模型无法解释检测到的异常帧异常的原因。
B. Predictive Models
视频由一系列帧组成,这些帧可以被视为空间和时间信号的顺序。预测模型的任务是通过给出过去的p帧来预测t帧,其可以表示为:
![]()
基于真实目标帧及其预测帧构建预测模型的损失函数:
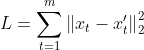
其中, 是时间戳t中的真实目标帧,
是时间戳t中的真实目标帧,![]() 是预测帧。预测模型假设可以很好地预测正常事件。因此,预测帧
是预测帧。预测模型假设可以很好地预测正常事件。因此,预测帧![]() 与其基本真值之间的差异可用于检测异常事件。虽然预测模型在视频异常检测任务中表现良好,但其计算复杂度较高。因此,预测模型更适合离线应用。
与其基本真值之间的差异可用于检测异常事件。虽然预测模型在视频异常检测任务中表现良好,但其计算复杂度较高。因此,预测模型更适合离线应用。
C. Generative Models
生成模型通常包含基于高斯分布生成帧的架构,例如生成对抗网络(GAN)[77]。GAN由发生器和鉴别器组成。生成器的作用是根据真实数据的实际分布拟合新的数据分布,而鉴别器是判别向量是从真实数据中提取还是从生成的数据中提取。GAN的损耗函数表示如下:
![L = \frac{1}{m} \sum_{i=1}^{m}\left [ logD(x_i) - log(1 - D(G(z_i)))\right ]](http://img.e-com-net.com/image/info8/93002a25e8e741bf8eb7125b5d5985bb.gif)
该函数的前半部分旨在最大限度地提高识别真实数据的概率,后一部分旨在识别生成的数据。在这里,生成器和鉴别器可以是任何类型的神经网络结构,如CNN。与其他模型不同,通过同时训练生成器和鉴别器,GAN可以作为端到端模型。此外,生成器可以同时生成异常样本。因此,GAN是视频异常检测中应用最广泛的模型之一。尽管甘有其优点,但它也不可避免地存在一些缺陷,包括训练费用高、不稳定、复制困难和模式崩溃。
D. One-Class Classification Models
考虑到异常的模糊性和多样性,迫切需要开发用于检测视频异常的多类分类。在检测视频异常时,研究人员通常将任何明显偏离正常行为的行为视为异常。因此,没有异常标签的异常检测任务可以被视为一类分类(OCC)问题。这种模型在视频异常检测中的核心思想是找到一个超球,该超球包围正常数据的网络表示[78]。此超球体中未包含的任何数据点都将被视为异常。深度学习和OCC模型的组合可以训练为联合学习具有一类分类目标的密集特征表示。然而,这种模型需要花费更多训练时间。
E. Hybrid Models
在解决异常检测任务时,每种模型都有自己的目标函数和特定的优势。因此,研究人员可以考虑在一个模型中建立多个服务于不同块的模型,这可以利用不同的模型并提高检测精度。在混合模型中,从深度学习方法中学习到的代表性特征可以转移到传统算法,如支持向量机(SVM)分类器[79]。低维特征向量使混合模型更具可扩展性和计算效率,适用于解决视频异常检测任务。与其他具有自定义损失函数的模型不同,混合模型的损失函数是通用的,这意味着特征提取器对特征表示没有影响。因此,混合模型的性能次优。尽管混合模型在任务中具有出色的性能,但它们大多依赖于任务,无法在不同任务之间切换。
IV. CONCLUSION
本文介绍了深度视频异常检测模型在几种新兴的实际应用场景中的潜在机会,并讨论了文献中的技术问题。本研究在深度视频异常检测方面的新视角为对此领域感兴趣的研究人员提供了明确的指导。