python爬虫--Scrapy框架--Scrapy+selenium实现动态爬取
python爬虫–Scrapy框架–Scrapy+selenium实现动态爬取
前言
本文基于数据分析竞赛爬虫阶段,对使用scrapy + selenium进行政策文本爬虫进行记录。用于个人爬虫学习记录,可供参考,由于近期较忙,记录得较粗糙,望见谅。
框架结构
start启动scrapy -> 爬虫提交链接request(可以有多条链接)给Scheduler -> Scheduler决定链接的调度(调度器应该是个优先队列,起到分配线程的作用,用分布式爬虫来加快爬取速度)-> Scheduler把请求的链接发送给下载器(下载器可以配置middlewares) -> 下载器发送request给网页服务器 -> 网络服务器将response对象返回给下载器 -> 下载器将response下载发送给爬虫 -> 爬虫解析response返回的对象并进行后续操作(给Item Pipeline发送存储请求or再次发起链接请求)
Scrapy Engine进行整个爬虫流程的把控,相当于一个main函数。Scrapy流程示意图如下图所示:
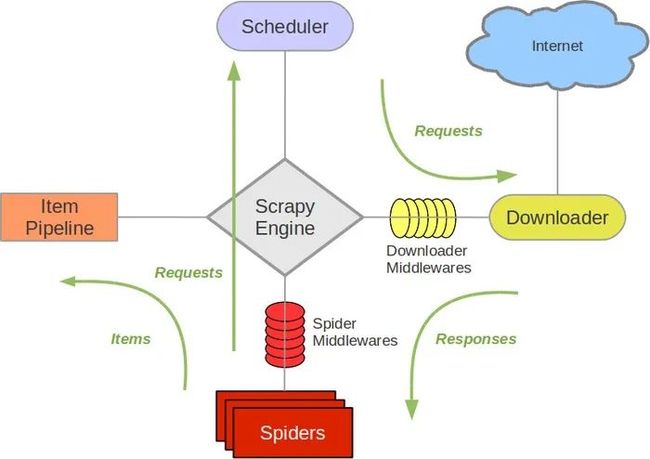
创建爬虫
cd <项目文件夹>
scrapy startproject SpiderProjectName
... ...
cd SpiderProjectName
# 创建普通爬虫
scrapy genspider spider_name xxx.com
# 创建crawlspider(可定义抓取规则,自动抓取链接)
scrapy genspider -t crawl spider_name xxx.com
配置settings
- 不遵循爬虫协议(建议改成False)
ROBOTSTXT_OBEY = False
当要用到下面的构件时,在settings.py中找到下面代码,去掉#号即可
- 开启中间件
# 开启下载器中间件
DOWNLOADER_MIDDLEWARES = {
'testSpider.middlewares.TestspiderDownloaderMiddleware': 543,
}
# 开启爬虫中间件
SPIDER_MIDDLEWARES = {
'testSpider.middlewares.TestspiderSpiderMiddleware': 543,
}
- 设置header
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36' # 填写自己的请求头,自己的是这个
}
- 开启pipelines
ITEM_PIPELINES = {
'testSpider.pipelines.TestspiderPipeline': 300,
}
- 设置下载时延,防止爬虫被识别
DOWNLOAD_DELAY = 3 # 默认是3
RANDOMIZE_DOWNLOAD_DELAY=True # 这行要自己加,在settings中没有定义
- 关闭COOKIES,防止服务器追踪爬虫轨迹
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
重写方法
- 定义开始爬取的链接一般写在spider.py的start_urls中。如果需要写一个方法来生成链接,可以在你的spider.py文件里重写start_requests(self)方法。
自定义中间件
在middlewares中重写中间件方法,可以实现自己的功能(例如利用selenium进行模拟点击)。
Downloader和Spider中间件都需要先在settings.py中先开启。如果自己在middlewares中定义了新的中间件class,则应在settings中自行添加类名和权重值。权重值越小,越优先执行。
DOWNLOADER_MIDDLEWARES = {
'testSpider.middlewares.TestspiderDownloaderMiddleware': 543,
'testSpider.middlewares.CustomDownloaderMiddleware': 542, # 先执行权值小的
'testSpider.middlewares.RandomUserAgentMiddleware': 541, # 开启假请求头的下载器中间件
}
- 设置多请求头(假请求头)
为了防止scrapy被识别,可以使用多(假)请求头来发送请求
如上,在DOWNLOADER_MIDDLEWARES中
from fake_useragent import UserAgent
import random
class RandomUserAgentMiddleware(object):
def __init__(self):
self.agent = UserAgent()
@classmethod
def from_crawler(cls, crawler):
return cls()
def process_request(self, request, spider):
user_agent = self.agent.random
request.headers.setdefault('User-Agent', user_agent)
print(user_agent)
item类–自定义meta字段
预定义元数据,告诉爬虫item中有的字段。
- items.py
class TestspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
date = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
- spider.py
from TestspiderSpider.items import TestspiderItem
def parse_item(self, response):
url = response.url
date = response.xpath('/html/head/meta[@name="PubDate"]/@content').get()[:-6]
title = response.xpath('/html/head/meta[@name="ArticleTitle"]/@content').get()
content = response.xpath('//*[@class="content-text"]').get()
yield TestspiderItem(url=url, date=date, title=title, content=content)
配合selenium实现动态爬取
- scrapy可以高效实现页面抓取,scrapy的crawlspider类可以自动抓取链接并前往链接解析内容。
- selenium可以实现动态点击,能够获得加载完整的page_source,与scrapy互补。
selenium的安置方法
selenium能够负责解析动态页面,返回动态生成的网络源码。但是selenium应该放在能够实现动态点击,且能够返回动态生成的源码的地方。因此,selenium的安放有讲究,目前我只发现这一种方法,后续如果有更好的方法再补充。
放在middlewares的process_request()
爬虫将url传入到middlewares,因此可以在middlewares的process_request()方法中向服务器发送操作请求,再用driver.page_source解析网页源码,此时服务器response的源码加载了动态生成的内容。
- 爬虫每发送一次url请求,process_request()调用一次。如果要加载动态内容,selenium可以安放在这里。
注意
spider.py的start_requests()方法yield Request(url)的只是一个链接请求,并不是动态生成的内容,默认还是加载起始字段;
crawlspider
crawlspider只能抓取response返回的源码中符合Rule的链接,再访问链接里的内容。
- crawlspider继承了scrapy.spider的CrawlSpider类,该类中多了一个名为rules的成员变量,定义了抓取规则
- 对于满足rules的链接,crawlspider会再次将这些链接向middlewares发送request,因此middlewares中的process_request, process_response方法也会再次调用
- Rule()里定义LinkExtractor规则,LinkExtractor()方法参数常用的有:allow:只有正则匹配成功的链接才捕获;restrict_xpath:规定xpath格式的链接才捕获
问题
如何才能在start_url中动态点击按钮获得下一个链接的同时,解析数据返回给爬虫,同时selenium能够在当前页面继续爬取(比如要爬取新闻文本,点击下一页按钮(按钮是js加载,因此没有链接),生成了新的页面,抓取新页面的新闻链接后,再在该页面基础上点击下一页面获得新页面源码)?
补充:process_request不能采用yield方法,因为yield方法返回的是一个包装了链接的生成器(generator)对象,而不是普通的链接,scrapy是处理不了这种对象的。
解决方案
目前我还没有在scrapy中能一次性解决上面的问题的方法,我最终决定selenium和scrapy分开来处理。这个方法比较笨,但也是无奈之举= =。毕竟爬取这个网站确实是比较麻烦。如果有更好的方法,后续会继续补充。
思路:将爬虫分成两步:
一、先用selenium爬取所有项目对应的所有链接,并存储到数据库中。数据库设计如下
| post_url | category |
|---|
二、在start_requests方法中,按page yield成新界面的url对爬虫发送请求。对于发送的页面链接,在process_request用selenium进行driver.get(request.url)方法处理,并return HtmlResponse(url, body = self.driver.page_source, request = request, encoding = 'utf-8')。此时返回的页面是动态加载生成的页面,用crawlspider自动捕获新闻链接,并重新向爬虫发送请求,获得的新闻链接在parse方法中进行处理。
此时爬虫的工作就已经完成,后续只需将parse中将新闻链接中要提取的数据打包成item,记住要保留他的post_url,将打包好的item返回给pipeline,保存到数据库中。该步数据库设计如下:
| post_url | date | title | content |
|---|
将第一和第二步存储的数据库按照post_url进行连接,就可以得到所需要的文本信息了。此时爬虫工作成功完成。