python文件的读写read_csv常用参数
文章目录
- pandas.read_csv参数理解
-
- filepath_or_buffer
- header
- sep
- delimiter
- delim_whitespace
- names
- index_col
- usecols
- squeeze
- prefix
- dtype
- engine
- converters
- skiprows
- skipfooter
- nrows
- parse_dates
- keep_date_col
- iterator
- chunksize
- compression
- comment
- encoding
pandas.read_csv参数理解
filepath_or_buffer
filepath_or_buffer是pandas.read_csv的默认第一个参数,用于指定读取的文件的路径,一般直接给值
pd.read_csv('data/ex1.csv')
# 等价于pd.read_csv(filepath_or_buffer='data/ex1.csv')
header
指定作为标题的行,默认为0,如果不需要可以指定为None
header 的值可以是一个行数(数字),也可以是一个列表,如[0,1,3],将有多个标题行
但是要注意的是,当header指定某一行时,如果这一行不是第一行,那么该行前面的数据会被忽略。如果指定的是一个如[1,3]的列表时,那么不仅前面的行会被忽略,之间的行也会被忽略
举两个例子:
数据:
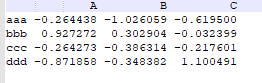
1、读取第2行作为标题行,第一行将会被忽略掉
result = pd.read_csv('data/ex3.txt', header=1,delim_whitespace=True)
result
获得结果:
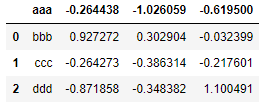
2、读取多行作为标题行,不仅仅上面的行被忽略的,之间的行也被忽略了
result = pd.read_csv('data/ex3.txt', header=[1,3],delim_whitespace=True)
result
获得结果:

sep
指定的分隔符,默认为 ‘,’ 逗号
如果文件是用tab和多个空格分隔的,那么可以设置参数为sep=’\s+’
sep=’\s+'作用是: s+可以将tab和多个空格都当成一样的分隔符!!!!!!
举个例子:现在有一个文本文件它的分隔符是tab或者是空格
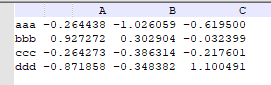
这个时候使用默认的sep读取出来的结果会有错误,所以需要另外设置sep的值,这里只要设置sep=’\s+'就能正常的读取该文件
result = pd.read_csv('data/ex3.txt', sep='\s+')
result
获得结果:
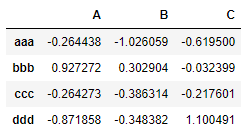
delimiter
备选分隔符,功能与sep相同,如果指定该参数那么sep将失效,使用上面sep的例子,在原本的基础上再指定delimiter参数,获得的结果无法正常读取我们想要的内容,说明sep失去了效果
result = pd.read_csv('data/ex3.txt', sep='\s+', delimiter=',')
result
获得结果:

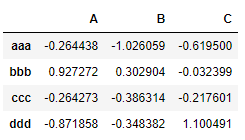
delim_whitespace
指定空格是否作为分隔符使用,等价于sep=’\s+’,如果delim_whitespace =True,那么sep和delimiter都将失效,还是用上面的例子,获得的结果可以发现sep和delimiter并没有对结果造成影响,说明它们失效了
result = pd.read_csv('data/ex3.txt', sep=',', delimiter=',',delim_whitespace=True)
result
获得结果
names
用于设置标题行,如果读取的文件中没有标题行,这时可以设置自定义的列名
举个栗子
数据:

result = pd.read_csv('data/ex2.csv', header=0,names=['a', 'b', 'c', 'd', 'message'])
result
获得结果:

index_col
指定某一列或多列作为行索引,如果给定的值是一个列编号或者一个列名,那么该列将作为行索引,如果指定的是一个序列,那么该序列中的多列将作为行索引
继续使用上面names的例子,从结果上可以看到message列已经作为行索引使用了
result = pd.read_csv('data/ex2.csv', header=0,names=['a', 'b', 'c', 'd', 'message'], index_col=4)
result
获得结果

usecols
指定需要加载的列,如果我们只是要加载一个文件中的某些列而不是全部的时候,可以使用usecols参数,可以加快加载速度以及降低内存的消耗
usecols接收一个序列,然后将加载序列中指定的列,序列可以是列编号也可以是列名
还是使用上面names的例子:
result = pd.read_csv('data/ex2.csv', header=0,names=['a', 'b', 'c', 'd', 'message'], usecols=['b','c','message'])
result
获得结果

squeeze
当squeeze=True时,如果文件只包含一列的话,那么就返回一个Series
举个栗子:
数据:

result = pd.read_csv('data/ex8.txt',squeeze=True)
result
获得结果

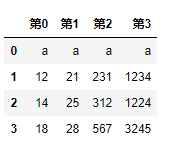
prefix
如果设置了header=None没有标题行时,那么默认的标题行将会是0,1,2…等,设置perfix参数可以给这些默认的标题行添加一个前缀
举个例子
result = pd.read_csv('data/ex9.csv',header=None,prefix='第')
result
获得结果
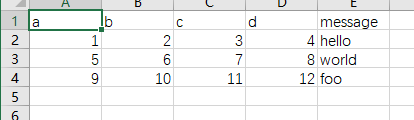
dtype
指定每一列的数据类型,比如{‘a’: np.float64, ‘b’: np.int32}等
举个例子
数据:
result = pd.read_csv('data/ex1.csv',dtype={'a':float}) # 或者dtype={0:float}
result
获得结果

engine
可以通过engine参数指定使用的分析引擎,可以选择C或者是python,C引擎快但是Python引擎功能更加完备。
使用方法:
engine=‘c’ 或者 engine=‘python’
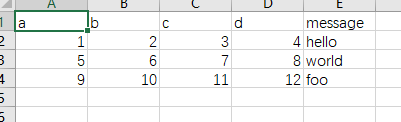
converters
该参数可以给指定的列进行定制,产生我们需要的效果
举个例子
数据:
def change(n):
return str(n)+'个'
result = pd.read_csv('data/ex1.csv',converters={0:change})
#用lambda表达式可以直接写成{0:lambda n:str(n)+'个'}
result
获得结果

skiprows
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
举个例子,可以看到本来将作为标题行的第一行被忽略了,而第二行成为了标题行
数据:
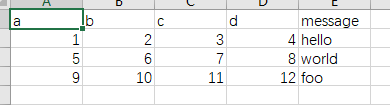
result = pd.read_csv('data/ex1.csv', skiprows=1)
result
获得结果
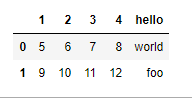
skipfooter
与skiprows一样,也是忽略一些行,但是skiprows是从头开始的,而skipfooter是从尾开始的
注意: 如果engine参数设置了’c’引擎,那么该参数不能使用,如果使用会报the ‘c’ engine does not support skipfooter的错误
举个例子,还是用上面skiprows的数据,可以从结果中看到,数据的最后一行被忽略了
result = pd.read_csv('data/ex1.csv', skipfooter=1)
result
获得结果

nrows
可以指定要读取的行数,从头开始算
parse_dates
如果值为 [[1, 3]] —> 合并1,3列作为一个日期列使用
如果值为 [1, 2, 3] —> 解析1,2,3列的值作为独立的日期列;
如果值为 {‘foo’ : [1, 3]} —> 将1,3列合并,并给合并后的列起名为"foo"
接下来使用案例一一介绍上面的各种传值
从结果看,该参数可以解析日期的格式最多可以格式化到时分秒
数据:
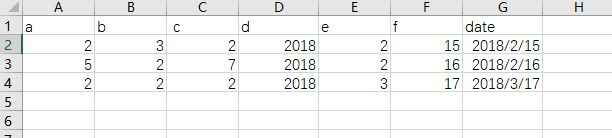
1.
result = pd.read_csv('data/ex10.csv', parse_dates=[['d','e','f']]) # 或者[[3,4,5]]
result
获得结果
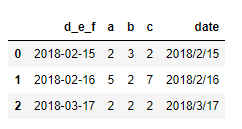
2.
result = pd.read_csv('data/ex10.csv', parse_dates=['date',3])
result
获得结果
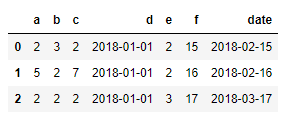
3.
result = pd.read_csv('data/ex10.csv', parse_dates={'日期':['date',3]})
result

keep_date_col
针对上面parse_dates参数使用,如果parse_dates将多个列连接为日期列,那么将keep_date_col设置为True将保留被连接的列
举个例子
result = pd.read_csv('data/ex10.csv', parse_dates=[[3,4,5]],keep_date_col =True)
result
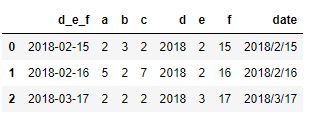
iterator
返回一个TextFileReader 对象,以便逐块处理文件。
举个例子,可以看到result已经不能直接输出一个表格,而是变成了一个可迭代的对象
result = pd.read_csv('data/ex10.csv', iterator=True)
print(result)
for i in result:
print(i)
获得结果

chunksize
与上面的iterator类似,将文件分成指定大小的块,然后返回一个可迭代的对象
直接举个例子看看
可以看到该对象的迭代每一次都会带有标题行,如果行数不够,则只输出剩余的行
result = pd.read_csv('data/ex10.csv', chunksize=2)
print(result)
for i in result:
print(i)
获得结果
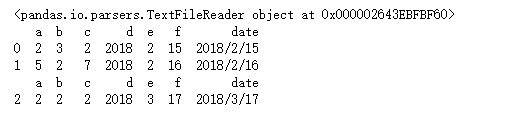
compression
直接使用磁盘上的压缩文件。如果使用infer参数,则使用 gzip, bz2, zip或者解压文件名中以‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。
默认为infer
下面我将ex10文件压缩,如下图
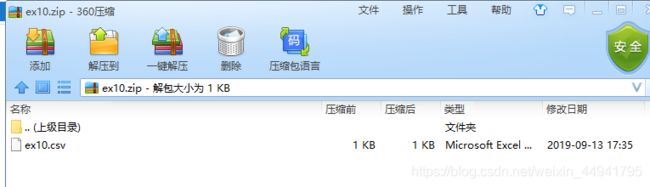
然后进行读取
result = pd.read_csv('data/ex10.zip', compression='infer')
result
获得结果

comment
识别行是否需要忽略,该参数的值只能是一个字符,比如’#’,那么凡是以# 开头的行都将被忽略
举个例子
数据:
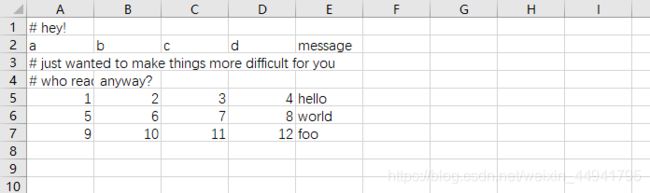
result = pd.read_csv('data/ex4.csv',comment='#')
result
获得结果

encoding
指定字符集类型,通常指定为’utf-8’