Python中的多线程(史上最简单易懂版)
简介:
多线程简单理解就是:一个CPU,也就是单核,将时间切成一片一片的,CPU轮转着去处理一件一件的事情,到了规定的时间片就处理下一件事情。
主要内容:
1.python中显示当前线程信息的属性和方法
# coding:utf-8
# 导入threading包
import threading
if __name__ == "__main__":
print("当前活跃线程的数量", threading.active_count())
print("将当前所有线程的具体信息展示出来", threading.enumerate())
print("当前的线程的信息展示", threading.current_thread())
效果图:

2.添加一个线程
# coding:utf-8
import threading
import time
def job1():
# 让这个线程多执行几秒
time.sleep(5)
print("the number of T1 is %s" % threading.current_thread())
if __name__ == "__main__":
# 创建一个新的线程
new_thread = threading.Thread(target=job1, name="T1")
# 启动新线程
new_thread.start()
print("当前线程数量为", threading.active_count())
print("所有线程的具体信息", threading.enumerate())
print("当前线程具体信息", threading.current_thread())
效果图:

3.线程中的join函数
(1)预想的是,执行完线程1,然后输出All done…
“理想很丰满,现实却不是这样的”
# coding:utf-8
import threading
import time
def job1():
print("T1 start")
for i in range(5):
time.sleep(1)
print(i)
print("T1 finish")
def main():
# 新创建一个线程
new_thread = threading.Thread(target=job1, name="T1")
# 启动新线程
new_thread.start()
print("All done...")
if __name__ == "__main__":
main()
效果图:

(2)为了达到我们的预期,我们使用join函数,将T1线程进行阻塞。join函数进行阻塞是什么意思?就是哪个线程使用了join函数,当这个线程正在执行时,在他之后的线程程序不能执行,得等这个被阻塞的线程全部执行完毕之后,方可执行!
# coding:utf-8
import threading
import time
def job1():
print("T1 start")
for i in range(5):
time.sleep(1)
print(i)
print("T1 finish")
def main():
# 新创建一个线程
new_thread = threading.Thread(target=job1, name="T1")
# 启动新线程
new_thread.start()
# 阻塞这个T1线程
new_thread.join()
print("All done...")
if __name__ == "__main__":
main()
效果图:

4.使用Queue存储线程的结果
线程的执行结果,无法通过return进行返回,使用Queue存储。
# coding:utf-8
import threading
from queue import Queue
"""
Queue的使用
"""
def job(l, q):
for i in range(len(l)):
l[i] = l[i] ** 2
q.put(l)
def multithreading():
# 创建队列
q = Queue()
# 线程列表
threads = []
# 二维列表
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [6, 6, 6]]
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q))
t.start()
threads.append(t)
# 对所有线程进行阻塞
for thread in threads:
thread.join()
results = []
# 将新队列中的每个元素挨个放到结果列表中
for _ in range(4):
results.append(q.get())
print(results)
if __name__ == "__main__":
multithreading()
效果图:

5.线程锁lock
当同时启动多个线程时,各个线程之间会互相抢占计算资源,会造成程序混乱。
举个栗子:
当我们在选课系统选课时,当前篮球课还有2个名额,我们三个人去选课。
选课顺序为stu1 stu2 stu3,应该依次打印他们三个的选课过程,但是现实情况却是:
# coding:utf-8
import threading
import time
def stu1():
print("stu1开始选课")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu1选课成功,现在篮球课所剩名额为%d" % course)
else:
time.sleep(2)
print("stu1选课失败,篮球课名额为0,请选择其他课程")
def stu2():
print("stu2开始选课")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu2选课成功,现在篮球课所剩名额为%d" % course)
else:
time.sleep(2)
print("stu2选课失败,篮球课名额为0,请选择其他课程")
def stu3():
print("stu3开始选课")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu3选课成功")
print("篮球课所剩名额为%d" %course)
else:
time.sleep(2)
print("stu3选课失败,篮球课名额为0,请选择其他课程")
if __name__ == "__main__":
# 篮球课名额
course = 2
T1 = threading.Thread(target=stu1, name="T1")
T2 = threading.Thread(target=stu2, name="T2")
T3 = threading.Thread(target=stu3, name="T3")
T1.start()
T2.start()
T3.start()
效果图:

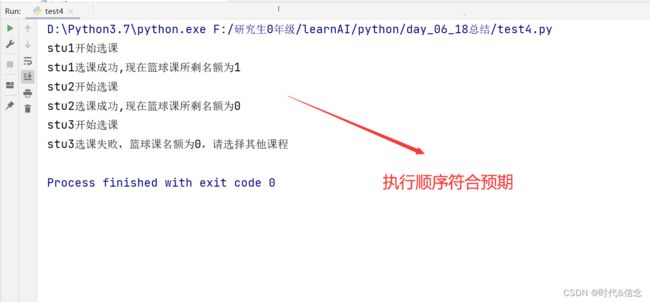
为了解决这种情况,我们使用lock线程同步锁,在线程并发执行时,保证每个线程执行的原子性。有效防止了共享统一数据时,线程并发执行的混乱。改进的代码如下:
# coding:utf-8
import threading
import time
def stu1():
global lock
lock.acquire()
print("stu1开始选课")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu1选课成功,现在篮球课所剩名额为%d" % course)
else:
time.sleep(2)
print("stu1选课失败,篮球课名额为0,请选择其他课程")
lock.release()
def stu2():
global lock
lock.acquire()
print("stu2开始选课")
global course
if course > 0:
course -= 1
print("stu2选课成功,现在篮球课所剩名额为%d" % course)
else:
time.sleep(1)
print("stu2选课失败,篮球课名额为0,请选择其他课程")
lock.release()
def stu3():
global lock
lock.acquire()
print("stu3开始选课")
global course
if course > 0:
course -= 1
time.sleep(1)
print("stu3选课成功,现在篮球课所剩名额为%d" % course)
else:
time.sleep(1)
print("stu3选课失败,篮球课名额为0,请选择其他课程")
lock.release()
if __name__ == "__main__":
# 篮球课名额
course = 2
# 创建同步锁
lock = threading.Lock()
T1 = threading.Thread(target=stu1, name="T1")
T2 = threading.Thread(target=stu2, name="T2")
T3 = threading.Thread(target=stu3, name="T3")
T1.start()
T2.start()
T3.start()
效果图: