学习笔记——Python跨文件夹调用函数的方法以及相对路径变更的问题
目录
-
- 学习笔记——Python跨文件夹调用函数的方法以及相对路径的问题
-
- 跨文件夹调用函数
- 跨文件夹调用函数时相对路径的问题
学习笔记——Python跨文件夹调用函数的方法以及相对路径的问题
跨文件夹调用函数
因为本人最近在做编译原理的实验,由于编译原理是需要将多个模块进行整合在一起的,所以我在进行函数调用的时候遇到了问题。
这里我有两个.py文件,test2.py在文件夹1中。
test1.py和文件夹1 在同一个文件夹中
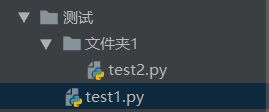
test1.py的代码如下:
from test2 import run
if __name__ == '__main__':
run()
test2.py的代码如下:
def run():
print('test.2py调用')
由于test1.py和test2.py是不在同一目录下的,所以test1.py直接进行import是会报错的,没有找到test2。
原因是python程序中使用 import XXX 时,python解析器会在当前目录、已安装和第三方模块中搜索 xxx,如果都搜索不到就会报错。
解决方法:
使用sys.path.append()或sys.path.insert()方法可以临时添加搜索路径,并且导入的路径会在python程序退出后失效。
import sys
sys.path.insert(0, './文件夹1')
from test2 import run
if __name__ == '__main__':
run()
import sys
sys.path.append('./文件夹1')
from test2 import run
if __name__ == '__main__':
run()
此时相当于把文件夹1的路径也加入到该程序的临时搜索路径,此时程序可以正常导入test2.py的run函数。
insert 与 append的区别在于 insert(0,’./文件夹1’)是将该目录的优先级定为0级(最高等级)。
跨文件夹调用函数时相对路径的问题
在单独进行test2.py运行的时候,输出的文件路径采用的是相对路径,也就是当前目录输出一个文件。所以程序输出在了文件夹1的目录下。
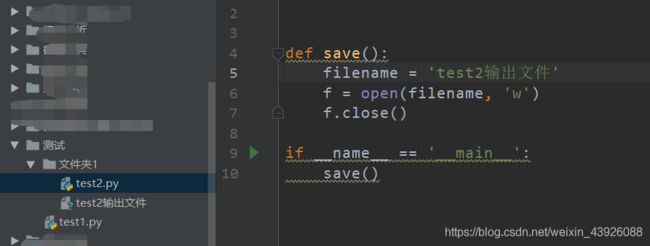
但是当test1.py进行调用test2.py时,也就跨文件夹进行调度的时候,此时是经过test1.py调用的test2.py,所以当前相对路径是test1.py的目录下。
通过运行test1.py,运行结果如下图:
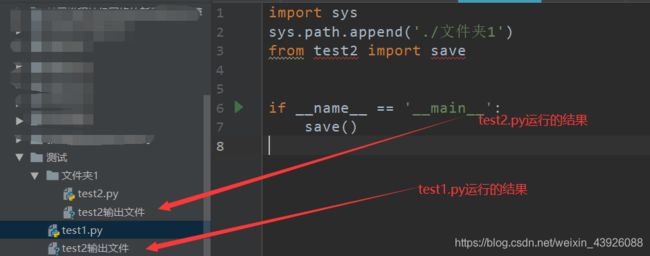
所以,尤其是当test2.py进行读取文件的时候,如果想要test1.py可以完美调用test2.py时,推荐test2.py读取文件时使用绝对路径。