Java项目:博客系统西瓜社区(springboot+mybatis-plus+thymeleaf)
西瓜社区文档
项目全部源码百度网盘地址在文档中,仔细阅读就可发现
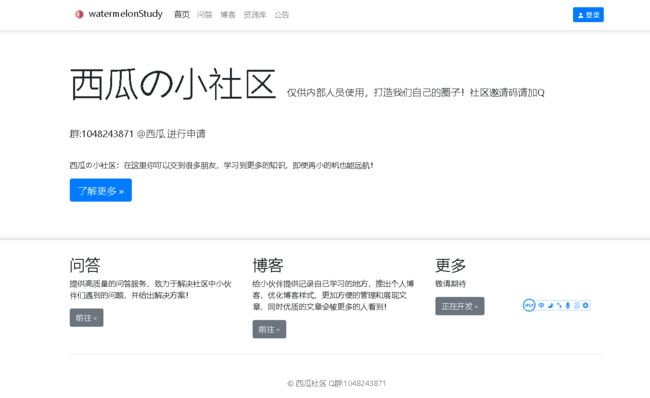
- 前端:社区目前基于开源的markdown框架editorme进行开发的问答和博客的两个功能
- 后端:springboot,mybatis-plus,swagger2,thymeleaf
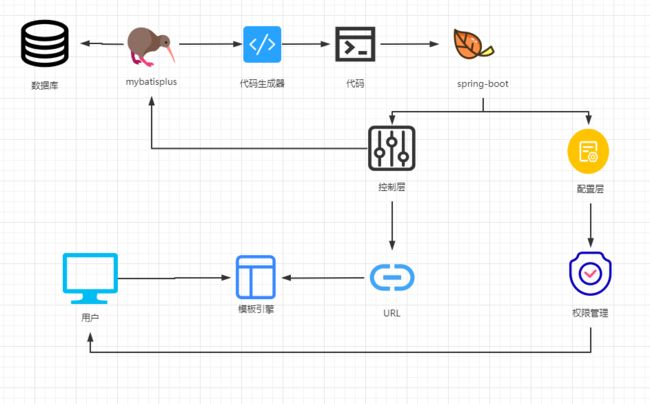
西瓜社区代码解析
数据库代码解析
== 以下代码中Table structure for xxx为数据结构 ==
== Records of xxx 为测试数据 ===
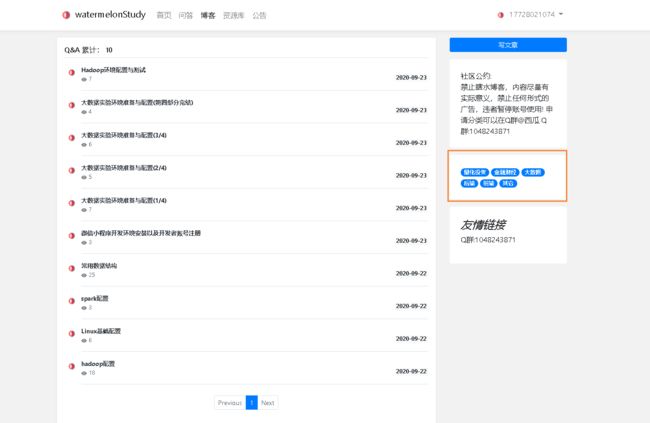
1.zxy_blog(博客信息)
zxy_blog这个table主要用于存储博客!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_blog
-- ----------------------------
DROP TABLE IF EXISTS `zxy_blog`;
CREATE TABLE `zxy_blog` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`bid` varchar(200) NOT NULL COMMENT '博客id',
`title` varchar(200) NOT NULL COMMENT '博客标题',
`content` longtext NOT NULL COMMENT '博客内容',
`sort` int(1) NOT NULL DEFAULT '0' COMMENT '排序 0 普通 1 置顶',
`views` int(10) NOT NULL DEFAULT '0' COMMENT '浏览量',
`author_id` varchar(200) NOT NULL COMMENT '作者id',
`author_name` varchar(200) NOT NULL COMMENT '作者名',
`author_avatar` varchar(500) NOT NULL COMMENT '作者头像',
`category_id` int(10) NOT NULL COMMENT '问题分类id',
`category_name` varchar(50) NOT NULL COMMENT '问题分类名称',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=42 DEFAULT CHARSET=utf8;
2.zxy_blog_category(博客分类信息)
zxy_blog_category这个table主要用于存储博客分类信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_blog_category
-- ----------------------------
DROP TABLE IF EXISTS `zxy_blog_category`;
CREATE TABLE `zxy_blog_category` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`category` varchar(50) NOT NULL COMMENT '博客分类',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_blog_category
-- ----------------------------
INSERT INTO `zxy_blog_category` VALUES ('1', '量化投资');
INSERT INTO `zxy_blog_category` VALUES ('2', '金融财经');
INSERT INTO `zxy_blog_category` VALUES ('3', '大数据');
INSERT INTO `zxy_blog_category` VALUES ('4', '后端');
INSERT INTO `zxy_blog_category` VALUES ('5', '前端');
INSERT INTO `zxy_blog_category` VALUES ('6', '其它');
3.zxy_comment(博客和问答的评论信息)
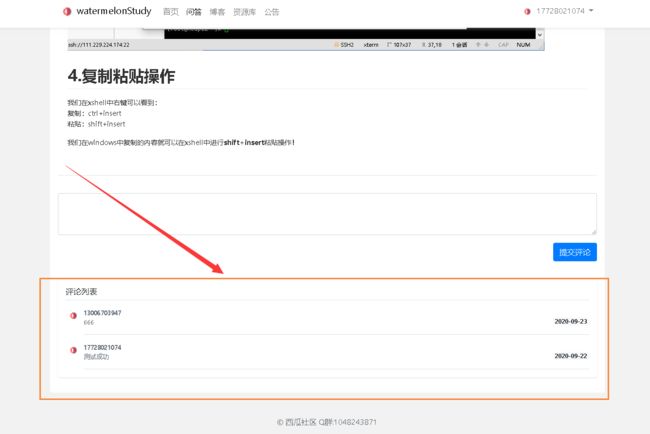
zxy_comment这个table主要用于存储博客和问答的评论信息,其中topic_category为1的是博客评论信息,topic_category为2则是问答评论信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_comment
-- ----------------------------
DROP TABLE IF EXISTS `zxy_comment`;
CREATE TABLE `zxy_comment` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`comment_id` varchar(200) NOT NULL COMMENT '评论唯一id',
`topic_category` int(1) NOT NULL COMMENT '1博客 2问答',
`topic_id` varchar(200) NOT NULL COMMENT '评论主题id',
`user_id` varchar(200) NOT NULL COMMENT '评论者id',
`user_name` varchar(200) NOT NULL COMMENT '评论者昵称',
`user_avatar` varchar(500) NOT NULL COMMENT '评论者头像',
`content` longtext NOT NULL COMMENT '评论内容',
`gmt_create` datetime NOT NULL COMMENT '评论创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=144 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_comment
-- ----------------------------
INSERT INTO `zxy_comment` VALUES ('137', '13a7c0777b774bb0b907117ad5a27dde', '2', 'b0c4c0e64d0644678e7ef6dcb245311f', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '沙雕', '2020-09-22 16:08:53');
INSERT INTO `zxy_comment` VALUES ('138', '14c60b2b67674c4ca636f4c22d167ac1', '1', '92f0434c4b3043dfa4f03b3cda5b97de', 'f4941f85aae24d2dbb4e3cea3c5db323', '小小12138', '/images/avatar/avatar-1.jpg', '大神666', '2020-09-22 23:10:14');
INSERT INTO `zxy_comment` VALUES ('139', 'd7496bb4a00d44b986e66d66bd7ec0e8', '2', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '测试成功\r\n', '2020-09-22 23:57:47');
INSERT INTO `zxy_comment` VALUES ('140', '417866117d15495d94ed1a4a4ab39a07', '1', '92f0434c4b3043dfa4f03b3cda5b97de', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '66666666666666666666666666666666666666666666666', '2020-09-23 13:27:28');
INSERT INTO `zxy_comment` VALUES ('141', 'd989c4b67cc64522abc8959d925d17ed', '1', '561728b1887d471e9dd07d8dee66597e', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '66666666666666666666666666666666666666666666666666666666', '2020-09-23 13:28:00');
INSERT INTO `zxy_comment` VALUES ('142', 'faa8a4108ae441d3878a16902e8f162d', '2', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '666\r\n', '2020-09-23 13:28:17');
INSERT INTO `zxy_comment` VALUES ('143', '7a500047696f4566be618c644f531259', '2', '7b17b466935f4226bb9c48c710854ca7', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', 'ok\r\n', '2020-09-23 13:57:38');
4.zxy_download(资源信息)
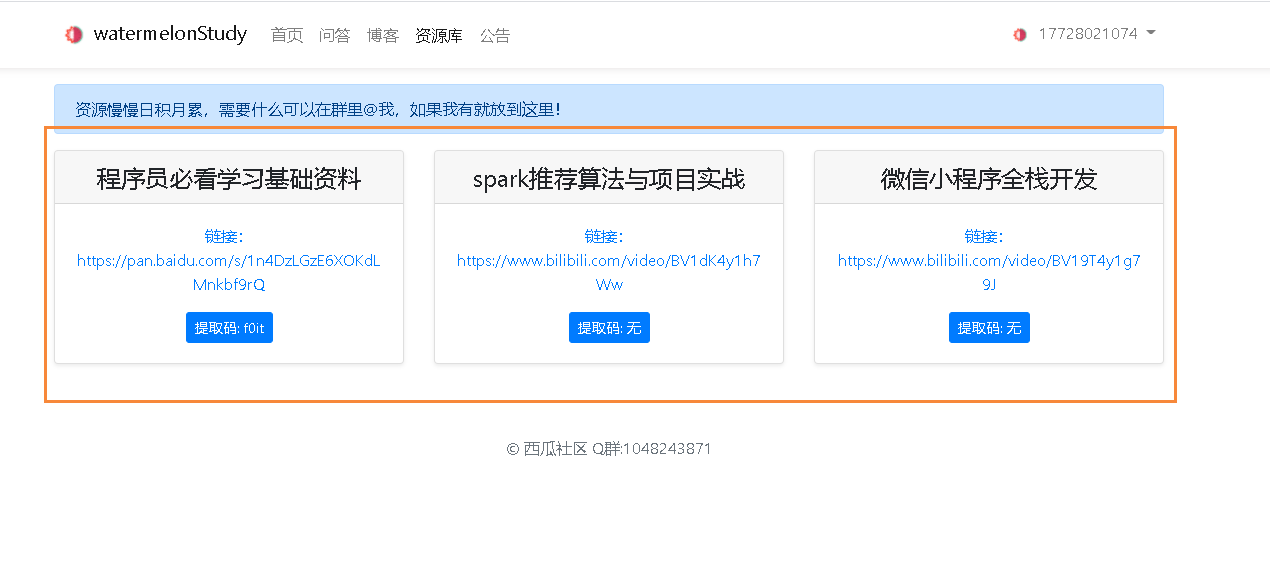
zxy_download这个table主要用于存储资源中的信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_download
-- ----------------------------
DROP TABLE IF EXISTS `zxy_download`;
CREATE TABLE `zxy_download` (
`dname` varchar(100) NOT NULL COMMENT '资源名',
`ddesc` varchar(500) NOT NULL COMMENT '资源链接',
`dcode` varchar(50) NOT NULL COMMENT '提取码'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_download
-- ----------------------------
INSERT INTO `zxy_download` VALUES ('程序员必看学习基础资料', 'https://pan.baidu.com/s/1n4DzLGzE6XOKdLMnkbf9rQ', 'f0it');
INSERT INTO `zxy_download` VALUES ('spark推荐算法与项目实战', 'https://www.bilibili.com/video/BV1dK4y1h7Ww', '无');
INSERT INTO `zxy_download` VALUES ('微信小程序全栈开发', 'https://www.bilibili.com/video/BV19T4y1g79J', '无');
5.zxy_invite(注册邀请码信息)
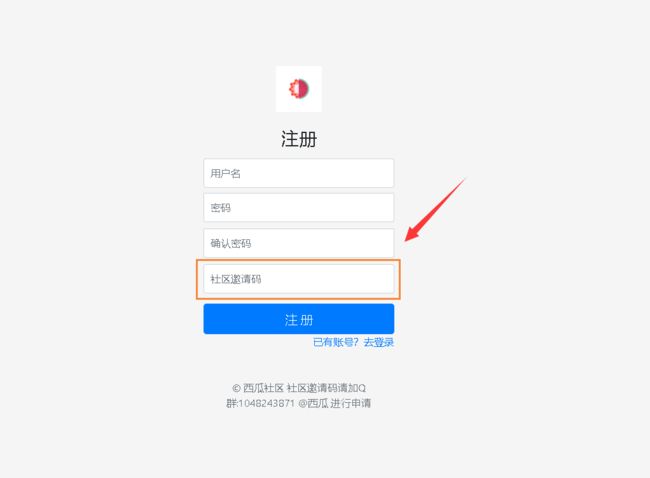
zxy_invite这个table主要用于存储邀请码信息,注意用户需要有邀请码才能注册账户!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_invite
-- ----------------------------
DROP TABLE IF EXISTS `zxy_invite`;
CREATE TABLE `zxy_invite` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`code` varchar(200) NOT NULL COMMENT '邀请码',
`uid` varchar(200) DEFAULT NULL COMMENT '用户id',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '状态 0 未使用 1 使用',
`active_time` datetime DEFAULT NULL COMMENT '激活时间',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1217 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_invite
-- ----------------------------
INSERT INTO `zxy_invite` VALUES ('1', '1111', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '1', '2020-09-22 15:56:27', '2020-09-22 15:54:17');
INSERT INTO `zxy_invite` VALUES ('2', '2222', '792f0067471f4da683370288a32e8165', '1', '2020-09-23 13:26:57', '2020-09-22 17:46:03');
INSERT INTO `zxy_invite` VALUES ('3', '3333', '04624db4faa74bdf9b1f728a51ff045a', '1', '2020-09-22 22:02:05', '2020-09-22 18:20:06');
INSERT INTO `zxy_invite` VALUES ('4', '4444', '3eba03a0de3842d3921ec4df7948f38c', '1', '2020-09-22 21:48:40', '2020-09-22 18:20:13');
INSERT INTO `zxy_invite` VALUES ('5', '5555', 'f4941f85aae24d2dbb4e3cea3c5db323', '1', '2020-09-22 23:07:43', '2020-09-22 23:05:17');
INSERT INTO `zxy_invite` VALUES ('6', '6666', 'f5005d60326c45f7b31046fa3c1f1753', '1', '2020-09-23 20:15:38', '2020-09-22 23:51:26');
INSERT INTO `zxy_invite` VALUES ('7', '7777', 'e8c38b7a4c31497b9d98119e0ea62bec', '1', '2020-09-23 20:56:07', '2020-09-22 23:51:36');
INSERT INTO `zxy_invite` VALUES ('8', '8888', 'aee71a1ddc86453db0c8d500741b8db9', '1', '2020-09-23 20:55:59', '2020-09-22 23:51:45');
INSERT INTO `zxy_invite` VALUES ('9', '9999', null, '0', null, '2020-09-22 23:51:54');
INSERT INTO `zxy_invite` VALUES ('10', '10-10', 'fe765316b02741d096d6c7809ce1cbd9', '1', '2020-09-25 19:26:31', '2020-09-22 23:52:05');
INSERT INTO `zxy_invite` VALUES ('11', '11-11', null, '0', null, '2020-09-22 23:52:28');
6.zxy_question(问答信息)
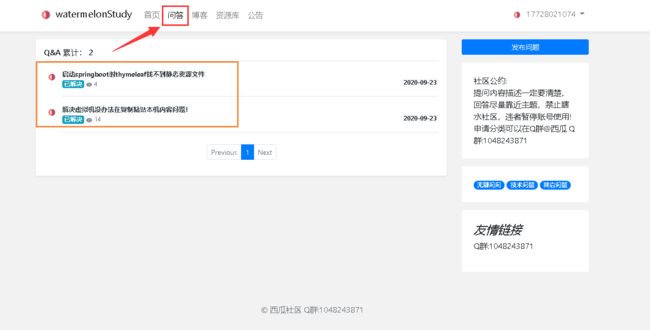
zxy_question这个table主要用于存储问答中信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_question
-- ----------------------------
DROP TABLE IF EXISTS `zxy_question`;
CREATE TABLE `zxy_question` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`qid` varchar(200) NOT NULL COMMENT '问题id',
`title` varchar(200) NOT NULL COMMENT '问题标题',
`content` longtext NOT NULL COMMENT '问题内容',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '状态 0 未解决 1 已解决',
`sort` int(1) NOT NULL DEFAULT '0' COMMENT '排序 0 普通 1 置顶',
`views` int(10) NOT NULL DEFAULT '0' COMMENT '浏览量',
`author_id` varchar(200) NOT NULL COMMENT '作者id',
`author_name` varchar(200) NOT NULL COMMENT '作者名',
`author_avatar` varchar(500) NOT NULL COMMENT '作者头像',
`category_id` int(10) NOT NULL COMMENT '问题分类id',
`category_name` varchar(50) NOT NULL COMMENT '问题分类名称',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=38 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_question
-- ----------------------------
INSERT INTO `zxy_question` VALUES ('36', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', '解决虚拟机没办法在复制粘贴本机内容问题!', '# 1.下载xshell\r\n下载链接:https://www.netsarang.com/zh/xshell/#learnmore\r\n学生可以申请学生认证,无需花钱\r\n\r\n# 2.获取虚拟机ip地址\r\n\r\n获取ip地址之前需要将虚拟机网络配置好!\r\n确定可以上网验证方法:\r\n```shell\r\nping www.baidu.com\r\n```\r\n\r\n\r\n出现图片情况即网络配置成功!\r\n\r\n使用ifconfig获取ip地址\r\n\r\n\r\n# 3.利用xshell进行登陆\r\n\r\n\r\n\r\n# 4.复制粘贴操作\r\n\r\n我们在xshell中右键可以看到:\r\n复制:ctrl+insert\r\n粘贴:shift+insert\r\n\r\n我们在windows中复制的内容就可以在xshell中进行**shift+insert**粘贴操作!', '1', '0', '13', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '3', '无聊问问', '2020-09-22 23:57:34', '2020-09-23 13:57:54');
INSERT INTO `zxy_question` VALUES ('37', '7b17b466935f4226bb9c48c710854ca7', '启动springboot时thymeleaf找不到静态资源文件', ' 1、首先需要在配置文件中加入配置:\r\n ```xml\r\nspring.resources.static-locations=classpath:/static/\r\n```\r\n2、在html页面中引用的地方(以引用js文件为例)\r\n```js\r\n\r\n```', '1', '0', '4', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '2', '技术问题', '2020-09-23 13:57:27', '2020-09-23 13:57:27');
7.zxy_question_category(问答中分类的信息)

zxy_question_category这个table主要用于存储问答中分类的信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_question_category
-- ----------------------------
DROP TABLE IF EXISTS `zxy_question_category`;
CREATE TABLE `zxy_question_category` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`category` varchar(50) NOT NULL COMMENT '问题分类',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_question_category
-- ----------------------------
INSERT INTO `zxy_question_category` VALUES ('1', '无聊问问');
INSERT INTO `zxy_question_category` VALUES ('2', '技术问题');
INSERT INTO `zxy_question_category` VALUES ('3', '其它问题');
8.zxy_say(公告的信息)
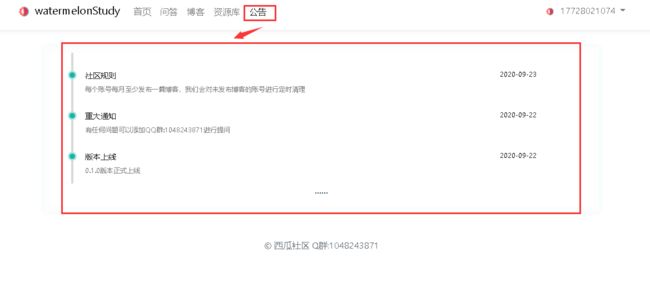
zxy_say这个table主要用于存储公告的信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_say
-- ----------------------------
DROP TABLE IF EXISTS `zxy_say`;
CREATE TABLE `zxy_say` (
`id` varchar(200) NOT NULL COMMENT '唯一id',
`title` varchar(200) NOT NULL COMMENT '标题',
`content` varchar(5000) NOT NULL COMMENT '内容',
`gmt_create` datetime NOT NULL COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_say
-- ----------------------------
INSERT INTO `zxy_say` VALUES ('1', '版本上线', '0.1.0版本正式上线', '2020-09-22 18:38:18');
INSERT INTO `zxy_say` VALUES ('2', '重大通知', '有任何问题可以添加QQ群:1048243871进行提问', '2020-09-22 21:37:20');
INSERT INTO `zxy_say` VALUES ('3', '社区规则', '每个账号每月至少发布一篇博客,我们会对未发布博客的账号进行定时清理', '2020-09-23 23:47:20');
9.zxy_user(用户账户信息)
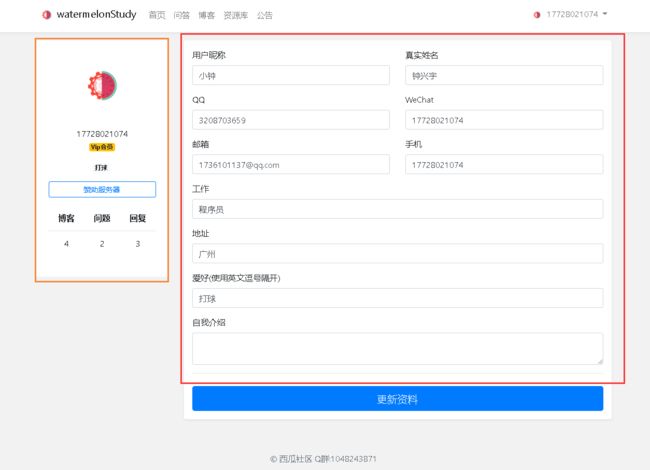
zxy_user这个table主要用于存储用户账户信息,密码经过加密处理!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_user
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user`;
CREATE TABLE `zxy_user` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`uid` varchar(200) NOT NULL COMMENT '用户编号',
`role_id` int(10) NOT NULL COMMENT '角色编号',
`username` varchar(100) NOT NULL COMMENT '用户名',
`password` varchar(200) NOT NULL COMMENT '密码',
`avatar` varchar(500) NOT NULL DEFAULT '/images/avatar/avatar-1.jpg' COMMENT '头像',
`login_date` datetime NOT NULL COMMENT '登录时间',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=851 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_user
-- ----------------------------
INSERT INTO `zxy_user` VALUES ('840', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '2', '17728021074', '$2a$10$ncC7.yRCa7MhMghssqTlbe4EzwtRGNftUAs4vOQW7DpAmti46WGve', '/images/avatar/avatar-1.jpg', '2020-09-22 15:56:27', '2020-09-22 15:56:27');
INSERT INTO `zxy_user` VALUES ('843', '3eba03a0de3842d3921ec4df7948f38c', '2', 'okc123', '$2a$10$ISrB8PjEYpWFHMKykxSirOY7Cm9d2dWhy.0tg/gDh332296zXHCDq', '/images/avatar/avatar-1.jpg', '2020-09-22 21:48:40', '2020-09-22 21:48:40');
INSERT INTO `zxy_user` VALUES ('844', '04624db4faa74bdf9b1f728a51ff045a', '2', '大佳', '$2a$10$ifvl59ZGOJ6lxQMZJJqNz.S8H66PDACFTcD.vay6tcJacw4d.jPQC', '/images/avatar/avatar-1.jpg', '2020-09-22 22:02:05', '2020-09-22 22:02:05');
INSERT INTO `zxy_user` VALUES ('845', 'f4941f85aae24d2dbb4e3cea3c5db323', '2', '小小12138', '$2a$10$HB7mFXU5eKcQQqEBnDSgFegUG1pdlSnjYw1OoxAeo/E3hIEzNDOyG', '/images/avatar/avatar-1.jpg', '2020-09-22 23:07:43', '2020-09-22 23:07:43');
INSERT INTO `zxy_user` VALUES ('846', '792f0067471f4da683370288a32e8165', '2', '13006703947', '$2a$10$..Ch/d/wOvED/NKusu8NaeYfE/S7MZUzWZTfwSC.C9YyLpAyQNbsS', '/images/avatar/avatar-1.jpg', '2020-09-23 13:26:57', '2020-09-23 13:26:57');
INSERT INTO `zxy_user` VALUES ('847', 'f5005d60326c45f7b31046fa3c1f1753', '2', '陈林浩', '$2a$10$pfEYX3hyooKOckkumPM7K.1PUo2wCMXvWW50DmRDIKab5Iw3JBU8S', '/images/avatar/avatar-1.jpg', '2020-09-23 20:15:38', '2020-09-23 20:15:38');
INSERT INTO `zxy_user` VALUES ('848', 'aee71a1ddc86453db0c8d500741b8db9', '2', 'lincanfeng', '$2a$10$FK1rL8sJ5kzPK5qapNc.7uqUIk/5ehhSQnsEKv3SmtduP1GPRYrJy', '/images/avatar/avatar-1.jpg', '2020-09-23 20:55:59', '2020-09-23 20:55:59');
INSERT INTO `zxy_user` VALUES ('849', 'e8c38b7a4c31497b9d98119e0ea62bec', '2', 'JUNJIE_H', '$2a$10$tkUBeIdm35M11yhpcN3NtuU6yLJ5A.eDzvRcdBVkHVcc9VlsRtovi', '/images/avatar/avatar-1.jpg', '2020-09-23 20:56:07', '2020-09-23 20:56:07');
INSERT INTO `zxy_user` VALUES ('850', 'fe765316b02741d096d6c7809ce1cbd9', '2', 'choudc', '$2a$10$rmAm/HsQVJxLZDRW8bBzee2HUDsmqUm6dc58EU0RTMExFThxVSYoq', '/images/avatar/avatar-1.jpg', '2020-09-25 19:26:31', '2020-09-25 19:26:31');
10.zxy_user_info(用户账户的个人信息)
zxy_user_info这个table主要用于存储用户账户的个人信息!具体字段请看代码中的comment
-- ----------------------------
-- Table structure for zxy_user_info
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user_info`;
CREATE TABLE `zxy_user_info` (
`uid` varchar(200) NOT NULL COMMENT '用户id',
`nickname` varchar(80) DEFAULT NULL COMMENT '用户昵称',
`realname` varchar(80) DEFAULT NULL COMMENT '真实姓名',
`qq` varchar(20) DEFAULT NULL COMMENT 'QQ',
`wechat` varchar(200) DEFAULT NULL COMMENT 'WeChat',
`email` varchar(500) DEFAULT NULL COMMENT '邮箱',
`phone` varchar(20) DEFAULT NULL COMMENT '手机',
`work` varchar(200) DEFAULT NULL COMMENT '工作',
`address` varchar(500) DEFAULT NULL COMMENT '地址',
`hobby` varchar(500) DEFAULT NULL COMMENT '爱好',
`intro` varchar(2000) DEFAULT NULL COMMENT '自我介绍'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of ks_user_info
-- ----------------------------
INSERT INTO `zxy_user_info` VALUES ('a2ff39a3a7944181a4d3e5bc05ae7c64', '小钟', '钟兴宇', '3208703659', '17728021074', '[email protected]', '17728021074', '程序员', '广州', '打球', '');
INSERT INTO `zxy_user_info` VALUES ('3eba03a0de3842d3921ec4df7948f38c', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('04624db4faa74bdf9b1f728a51ff045a', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('f4941f85aae24d2dbb4e3cea3c5db323', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('792f0067471f4da683370288a32e8165', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('f5005d60326c45f7b31046fa3c1f1753', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('aee71a1ddc86453db0c8d500741b8db9', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('e8c38b7a4c31497b9d98119e0ea62bec', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('fe765316b02741d096d6c7809ce1cbd9', null, null, null, null, null, null, null, null, null, null);
11.全部sql代码
/*
Navicat MySQL Data Transfer
Source Server : 本机
Source Server Version : 80011
Source Host : localhost:3306
Source Database : watermelonstudy
Target Server Type : MYSQL
Target Server Version : 80011
File Encoding : 65001
Date: 2020-09-27 10:21:48
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for zxy_blog
-- ----------------------------
DROP TABLE IF EXISTS `zxy_blog`;
CREATE TABLE `zxy_blog` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`bid` varchar(200) NOT NULL COMMENT '博客id',
`title` varchar(200) NOT NULL COMMENT '博客标题',
`content` longtext NOT NULL COMMENT '博客内容',
`sort` int(1) NOT NULL DEFAULT '0' COMMENT '排序 0 普通 1 置顶',
`views` int(10) NOT NULL DEFAULT '0' COMMENT '浏览量',
`author_id` varchar(200) NOT NULL COMMENT '作者id',
`author_name` varchar(200) NOT NULL COMMENT '作者名',
`author_avatar` varchar(500) NOT NULL COMMENT '作者头像',
`category_id` int(10) NOT NULL COMMENT '问题分类id',
`category_name` varchar(50) NOT NULL COMMENT '问题分类名称',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=42 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_blog
-- ----------------------------
INSERT INTO `zxy_blog` VALUES ('31', 'a712139528b7441c8b627781d48a8e7a', 'hadoop配置', ' # Hadoop配置\r\n\r\n# 必看\r\n\r\n**配置千万条,网络第一条。**\r\n\r\n**配置不规范,bug改到吐。**\r\n\r\n **内外ip要分清,本机配置内ip,连接请用外ip**\r\n\r\n\r\n\r\n## 1.下载上传插件rz\r\n\r\n【安装命令】:\r\n\r\n```powershell\r\nyum install -y lrzsz\r\n```\r\n\r\n## 2.上传hadoop压缩包\r\n\r\n【上传命令】:\r\n\r\n```powershell\r\n## 上传压缩包\r\nrz\r\n\r\n## 压缩\r\ntar -zxvf [包名]\r\n```\r\n\r\n# 3.配置hadoop\r\n\r\n(1)编辑.bashrc文件\r\n在所有节点的.bashrc文件中添加如下内容:(也可以在profile文件中添加)\r\n\r\n```powershell\r\n# jdk\r\nexport JAVA_HOME=/root/jdk1.8.0_241\r\nexport PATH=$PATH:$JAVA_HOME/bin\r\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar\r\n\r\n# hadoop\r\nexport HADOOP_HOME=/root/hadoop-2.7.1\r\nexport PATH=$PATH:$HADOOP_HOME/bin\r\nexport PATH=$PATH:$HADOOP_HOME/sbin\r\n\r\nexport HADOOP_MAPRED_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_HOME=$HADOOP_HOME\r\nexport HADOOP_HDFS_HOME=$HADOOP_HOME\r\nexport YARN_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_HOME=$HADOOP_HOME\r\nexport HADOOP_HDFS_HOME=$HADOOP_HOME\r\nexport YARN_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native\r\nexport HADOOP_OPTS=\"-Djava.library.path=$HADOOP_HOME/lib\"\r\nexport JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH\r\nexport HADOOP_HOME_WARN_SUPPRESS=1\r\n\r\n# spark\r\nexport SPARK_HOME=/root/spark\r\nexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin\r\n```\r\n\r\n其中JAVA_HOME和HADOOP_HOME需要换成你自己的安装路径。\r\n\r\n执行:source .bashrc使编辑的内容生效。\r\n\r\n# 4.编辑/etc/hosts文件\r\n\r\n| Ip地址 | 主机名 | Namenode | Secondary namenode | Datanode | ResourceManager | NodeManager |\r\n| ------------- | --------- | -------- | ------------------ | -------- | --------------- | ----------- |\r\n| 116.85.43.227 | hadoop-01 | Y | Y | N | Y | N |\r\n| 106.12.48.46 | hadoop-02 | N | N | Y | N | Y |\r\n| 47.95.0.108 | hadoop-03 | N | N | Y | N | Y |\r\n\r\n编辑所有节点的/etc/hosts文件,\r\n\r\n```shell\r\n116.85.43.227 hadoop-03\r\n106.12.48.46 hadoop-02\r\n47.95.0.108(本机在这里要填内网ip) hadoop-01\r\n```\r\n\r\n保存退出。\r\n\r\n查看下/etc/hostname中的值是否和你的主机名一致,若不一致,则改成你的主机名,否则就不需要改。\r\n\r\n\r\n\r\n# 5.配置hadoop conf\r\n\r\n\r\n\r\n1.编辑hadoop-env.sh,yarn-env.sh文件\r\n编辑所有节点的hadoop-env.sh文件(位于hadoop/conf/下)\r\n先取消export JAVA_HOME的注释,然后修改后面的路径为你自己的安装路径\r\n\r\n```\r\nexport JAVA_HOME=/root/jdk1.8.0_241\r\n```\r\n\r\n2.编辑core-site.xml文件\r\n编辑所有节点的core-site.xml文件,添加如下内容:\r\n\r\n```\r\n\r\n\r\nfs.default.name \r\nhdfs://hadoop-01:9000 \r\n \r\n\r\n\r\nhadoop.tmp.dir \r\n/root/hadoop-2.7.1/tmp \r\n \r\n```\r\n\r\nhadoop-01是我的namenode节点的主机名,你可以替换成你的namenode节点的主机名。\r\n\r\n3.编辑hdfs-site.xml,yarn-site.xml文件\r\n编辑所有节点的hdfs-site.xml文件,添加如下内容:\r\n\r\n```\r\n\r\ndfs.namenode.name.dir \r\nfile:/root/hadoop-2.7.1/hadoop_data/hdfs/namenode \r\n \r\n\r\n\r\ndfs.datanode.data.dir \r\nfile:/root/hadoop-2.7.1/hadoop_data/hdfs/datanode \r\n \r\n\r\n\r\n\r\ndfs.replication \r\n1 \r\n \r\n\r\n\r\ndfs.namenode.datanode.registration.ip-hostname-check \r\nfalse \r\n \r\n\r\n\r\ndfs.nameservices \r\nhadoop-cluster1 \r\n \r\n\r\n\r\ndfs.namenode.secondary.http-address \r\nhadoop-01:50090 \r\n \r\n\r\n\r\ndfs.webhdfs.enabled \r\ntrue \r\n \r\n```\r\n\r\ndfs.namenode.name.dir是namenode节点存放目录,dfs.datanode.data.dir是datanode节点的存放目录,均可以替换成你自己想要存放的路径。\r\n\r\n编辑所有节点的yarn-site.xml文件,添加如下内容:\r\n\r\n```powershell\r\n \r\n yarn.resourcemanager.hostname \r\n hadoop-01 \r\n \r\n\r\n \r\n yarn.nodemanager.aux-services \r\n mapreduce_shuffle \r\n \r\n \r\n yarn.resourcemanager.address \r\n hadoop-01:8032 \r\n \r\n \r\n yarn.resourcemanager.scheduler.address \r\n hadoop-01:8030 \r\n \r\n \r\n yarn.resourcemanager.resource-tracker.address \r\n hadoop-01:8031 \r\n \r\n \r\n yarn.resourcemanager.admin.address \r\n hadoop-01:8033 \r\n \r\n \r\n yarn.resourcemanager.webapp.address \r\n hadoop-01:8088 \r\n \r\n\r\n```\r\n\r\n\r\n\r\n4..编辑mapred-site.xml文件\r\n编辑所有节点的mapred-site.xml文件,添加如下内容:\r\n\r\n```\r\n\r\n\r\n \r\n mapreduce.framework.name \r\n yarn \r\n \r\n \r\n mapreduce.jobtracker.http.address \r\n hadoop-01:50030 \r\n \r\n \r\n mapred.job.tracker \r\n http://hadoop-01:9001 \r\n \r\n \r\n mapreduce.jobhistory.address \r\n hadoop-01:10020 \r\n \r\n \r\n mapreduce.jobhistory.webapp.address \r\n hadoop-01:19888 \r\n \r\n\r\n \r\n\r\n```\r\n\r\nhadoop-01是我的jobtracker节点的主机名,你可以替换成你自己的jobtracker节点所在的主机名。\r\n\r\n5.编辑slaves文件\r\n\r\n打开slaves,将localhost替换成\r\nhadoop-02\r\n\r\nhadoop-03\r\n保存退出\r\n\r\n\r\n\r\n6.将配置好的hadoop文件复制到其他节点上\r\n\r\n```powershell\r\nscp -r /root/hadoop-2.7.1/etc/hadoop root@hadoop-02:/root/hadoop-2.7.1/etc/\r\nscp -r /root/hadoop-2.7.1/etc/hadoop root@hadoop-03:/root/hadoop-2.7.1/etc/\r\n```\r\n\r\n\r\n\r\n# 6.运行hadoop\r\n\r\n```shell\r\n./bin/hdfs namenode -format\r\n\r\nsource /etc/profile\r\n\r\n./start-dfs.sh\r\n```\r\n\r\n\r\n\r\n\r\n\r\n# 7.配置hadoop-HA\r\n\r\n\r\n\r\n\r\n\r\nhdfs-site.xml在原有的基础上添加\r\n\r\n```xml\r\n\r\n dfs.nameservices \r\n ns \r\n \r\n\r\n\r\n dfs.ha.namenodes.ns \r\n nn1,nn2 \r\n \r\n\r\n\r\n dfs.namenode.rpc-address.ns.nn1 \r\n hadoop01:8020 \r\n \r\n\r\n dfs.namenode.rpc-address.ns.nn2 \r\n hadoop02:8020 \r\n \r\n\r\n\r\n dfs.namenode.http-address.ns.nn1 \r\n hadoop01:50070 \r\n \r\n\r\n dfs.namenode.http-address.ns.nn2 \r\n hadoop02:50070 \r\n \r\n\r\n\r\n dfs.namenode.shared.edits.dir \r\n qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns \r\n \r\n\r\n\r\n dfs.journalnode.edits.dir \r\n 自己建个目录 \r\n \r\n\r\n\r\n dfs.client.failover.proxy.provider.ns \r\n org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider \r\n \r\n\r\n\r\n dfs.ha.fencing.methods \r\n sshfence \r\n \r\n\r\n\r\n dfs.ha.fencing.ssh.private-key-files \r\n /root/.ssh/id_rsa(自己的ssh目录) \r\n \r\n\r\n \r\n dfs.ha.automatic-failover.enabled.ns \r\n true \r\n \r\n\r\n \r\n ha.zookeeper.quorum \r\n hadoop01:2181,hadoop02:2181,hadoop03:2181 \r\n \r\n```\r\n\r\n\r\n\r\ncore-site.xml\r\n\r\n```xml\r\n\r\n fs.defaultFS \r\n hdfs://ns \r\n \r\n```\r\n\r\n\r\n\r\n\r\n# 8.配置yarn-HA\r\n\r\n\r\n\r\nyarn-site.xml加上去\r\n\r\n```xml\r\n\r\n yarn.resourcemanager.ha.enabled \r\n true \r\n \r\n\r\n\r\n yarn.resourcemanager.cluster-id \r\n rs \r\n \r\n\r\n\r\n yarn.resourcemanager.ha.rm-ids \r\n rm1,rm2 \r\n \r\n\r\n\r\n yarn.resourcemanager.hostname.rm1 \r\n hadoop01 \r\n \r\n\r\n yarn.resourcemanager.hostname.rm2 \r\n hadoop02 \r\n \r\n\r\n yarn.resourcemanager.webapp.address.rm1 \r\n hadoop01:8088 \r\n \r\n\r\n yarn.resourcemanager.webapp.address.rm2 \r\n hadoop02:8088 \r\n \r\n\r\n yarn.resourcemanager.zk-address \r\n hadoop01:2181,hadoop02:2181,hadoop03:2181 \r\n \r\n\r\n\r\n yarn.resourcemanager.recovery.enabled \r\n true \r\n \r\n\r\n\r\n yarn.resourcemanager.store.class \r\n org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore \r\n \r\n```\r\n\r\n', '0', '18', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '3', 'java', '2020-09-22 17:00:22', '2020-09-22 21:26:29');
INSERT INTO `zxy_blog` VALUES ('33', '561728b1887d471e9dd07d8dee66597e', 'Linux基础配置', '# Linux配置\r\n\r\n## 1.下载上传插件rz\r\n\r\n【安装命令】:\r\n\r\n```powershell\r\nyum install -y lrzsz\r\n```\r\n\r\n## 2.关闭Linux防火墙\r\n\r\n```powershell\r\n1:查看防火状态\r\n\r\nsystemctl status firewalld\r\n\r\nservice iptables status\r\n\r\n2:暂时关闭防火墙\r\n\r\nsystemctl stop firewalld\r\n\r\nservice iptables stop\r\n\r\n3:永久关闭防火墙\r\n\r\nsystemctl disable firewalld\r\n\r\nchkconfig iptables off\r\n\r\n4:重启防火墙\r\n\r\nsystemctl enable firewalld\r\n\r\nservice iptables restart \r\n\r\n5:永久关闭后重启\r\n\r\n//暂时还没有试过\r\n\r\nchkconfig iptables on\r\n```\r\n\r\n\r\n\r\n## 3.ssh免密登录\r\n\r\n```powershell\r\nssh-keygen -t rsa\r\n```\r\n\r\n一直按回车\r\n\r\n此时会在/root/.ssh目录下生成密钥对\r\n\r\n三台机器都需要生成密钥对\r\n\r\n三台机器都需要拷贝公钥到同一台机器:\r\n\r\n```powershell\r\nssh-copy-id hadoop-01\r\n```\r\n\r\n复制master机器的认证到其他机器\r\n\r\n```powershell\r\nscp /root/.ssh/authorized_keys root@hadoop-02:/root/.ssh\r\n\r\nscp /root/.ssh/authorized_keys root@hadoop-03:/root/.ssh\r\n```\r\n\r\n## 4.时间同步\r\n\r\n通过网络,所有主机和时钟同步服务器保持同步\r\n\r\n```powershell\r\n## 安装\r\nyum install -y ntp\r\n\r\n## 启动定时任务\r\ncrontab -e\r\n```\r\n\r\n随后在输入界面键入\r\n\r\n```powershell\r\n*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com\r\n```\r\n\r\n## 5.jdk安装\r\n\r\n查看是否自带jdk\r\n\r\n```powershell\r\nrpm -qa | grep java\r\n\r\nrpm -e [包名] [包名] [包名] \r\n```\r\n\r\n创建安装目录\r\n\r\n```powershell\r\nmkdir -p / root/softwares\r\n```\r\n\r\n上传jdk压缩包并解压\r\n\r\n```powershell\r\n## 上传压缩包\r\nrz\r\n\r\n## 压缩\r\ntar -zxvf [包名]\r\n```\r\n\r\n配置环境变量\r\n\r\n```powershell\r\nvi /etc/profile\r\n```\r\n\r\nexport JAVA_HOME=/root/jdk1.8.0_241\r\nexport PATH=$PATH:$JAVA_HOME/bin\r\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar\r\n\r\n\r\n\r\n加载配置\r\n\r\n```powershell\r\nsource /etc/profile\r\n```\r\n\r\n发送给其他机器\r\n\r\n```powershell\r\nscp -r [文件名] hdp-01:$PWD\r\n\r\nscp -r [文件名] hdp-02:$PWD\r\n```\r\n\r\n给其他机器进行环境变量配置\r\n\r\n用which Java查看是否配置成功\r\n\r\n \r\n\r\n# 必看\r\n\r\n**配置千万条,网络第一条。配置不规范,bug改到吐。 内外ip要分清,本机配置内ip,连接请用外ip**\r\n\r\n', '0', '6', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-22 21:22:37', '2020-09-22 21:22:37');
INSERT INTO `zxy_blog` VALUES ('34', '52aebdb1efe34c29b2bd9b01d8745488', 'spark配置', ' # 必看\r\n\r\n**配置千万条,网络第一条。配置不规范,bug改到吐。 内外ip要分清,本机配置内ip,连接请用外ip**\r\n\r\n\r\n\r\n## 1.下载上传插件rz\r\n\r\n【安装命令】:\r\n\r\n```powershell\r\nyum install -y lrzsz\r\n```\r\n\r\n## 2.上传spark压缩包\r\n\r\n【上传命令】:\r\n\r\n```powershell\r\n## 上传压缩包\r\nrz\r\n\r\n## 压缩\r\ntar -zxvf [包名]\r\n```\r\n\r\n# 3.配置spark\r\n\r\n(1)编辑.bashrc文件\r\n在所有节点的.bashrc文件中添加如下内容:(也可以在profile文件中添加)\r\n\r\n```powershell\r\n# jdk\r\nexport JAVA_HOME=/root/jdk1.8.0_241\r\nexport PATH=$PATH:$JAVA_HOME/bin\r\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar\r\n\r\n# hadoop\r\nexport HADOOP_HOME=/root/hadoop-2.7.1\r\nexport PATH=$PATH:$HADOOP_HOME/bin\r\nexport PATH=$PATH:$HADOOP_HOME/sbin\r\n\r\nexport HADOOP_MAPRED_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_HOME=$HADOOP_HOME\r\nexport HADOOP_HDFS_HOME=$HADOOP_HOME\r\nexport YARN_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_HOME=$HADOOP_HOME\r\nexport HADOOP_HDFS_HOME=$HADOOP_HOME\r\nexport YARN_HOME=$HADOOP_HOME\r\nexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native\r\nexport HADOOP_OPTS=\"-Djava.library.path=$HADOOP_HOME/lib\"\r\nexport JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH\r\nexport HADOOP_HOME_WARN_SUPPRESS=1\r\n\r\n# spark\r\nexport SPARK_HOME=/root/spark-2.4.5-bin-hadoop2.7\r\nexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin\r\n```\r\n\r\n其中JAVA_HOME,SPARK_HOME和HADOOP_HOME需要换成你自己的安装路径。\r\n\r\n执行:source .bashrc使编辑的内容生效。\r\n\r\n## 4.编辑/conf文件\r\n\r\n- 配置slaves文件\r\n 将 slaves.template 拷贝到 slaves\r\n\r\n```bash\r\ncp slaves.template slaves\r\n```\r\n\r\nShell 命令\r\n\r\nslaves文件设置Worker节点。编辑slaves内容,把默认内容localhost替换成如下内容:\r\n\r\n```\r\nhadoop-02\r\nhadoop-03\r\n```\r\n\r\n- 配置spark-env.sh文件\r\n\r\n 将 spark-env.sh.template 拷贝到 spark-env.sh\r\n\r\n \r\n\r\n ```bash\r\n cp spark-env.sh.template spark-env.sh\r\n ```\r\n\r\n Shell 命令\r\n\r\n 编辑spark-env.sh,添加如下内容:\r\n\r\n ```\r\n export SPARK_DIST_CLASSPATH=$(/root/hadoop-2.7.1 classpath)\r\n export SPARK_MASTER_IP=192.168.0.4\r\n export SPARK_MASTER_PORT=7077\r\n export SPARK_MASTER_WEBUI_POST=8080\r\n export SPARK_WORKER_MEMORY=500M\r\n export SPARK_WORKER_PORT=7078\r\n export SPARK_WORKER_WEBUI_PORT=8081\r\n export JAVA_HOME=/root/jdk1.8.0_241\r\n export HADOOP_HOME=/root/hadoop-2.7.1\r\n export HADOOP_CONF_DIR=/root/hadoop-2.7.1/etc/hadoop\r\n \r\n ```\r\n\r\n SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;\r\n\r\n配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。在Master主机上执行如下命令:将配置好的hadoop文件复制到其他节点上\r\n\r\n```powershell\r\nscp -r /root/spark-2.4.5-bin-hadoop2.7/conf root@hadoop-02:/root/spark-2.4.5-bin-hadoop2.7/\r\n\r\nscp -r /root/spark-2.4.5-bin-hadoop2.7/conf root@hadoop-03:/root/spark-2.4.5-bin-hadoop2.7/\r\n```\r\n\r\n\r\n\r\n报错:\r\n\r\n如果worker报这个错误,那么在spark-env.sh中加入spark-local-ip=外网ip\r\n\r\n```shell\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7078. Attempting port 7079.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7079. Attempting port 7080.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7080. Attempting port 7081.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7081. Attempting port 7082.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7082. Attempting port 7083.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7083. Attempting port 7084.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7084. Attempting port 7085.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7085. Attempting port 7086.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7086. Attempting port 7087.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7087. Attempting port 7088.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7088. Attempting port 7089.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7089. Attempting port 7090.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7090. Attempting port 7091.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7091. Attempting port 7092.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7092. Attempting port 7093.\r\n20/08/07 00:27:41 WARN util.Utils: Service \'sparkWorker\' could not bind on port 7093. Attempting port 7094.\r\n20/08/07 00:27:41 ERROR util.SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[main,5,main]\r\njava.net.BindException: Cannot assign requested address: Service \'sparkWorker\' failed after 16 retries (starting from 7078)! Consider explicitly setting the appropriate port for the service \'sparkWorker\' (for example spark.ui.port for SparkUI) to an available port or increasing spark.port.maxRetries.\r\n at sun.nio.ch.Net.bind0(Native Method)\r\n at sun.nio.ch.Net.bind(Net.java:433)\r\n at sun.nio.ch.Net.bind(Net.java:425)\r\n at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)\r\n at io.netty.channel.socket.nio.NioServerSocketChannel.doBind(NioServerSocketChannel.java:132)\r\n at io.netty.channel.AbstractChannel$AbstractUnsafe.bind(AbstractChannel.java:551)\r\n at io.netty.channel.DefaultChannelPipeline$HeadContext.bind(DefaultChannelPipeline.java:1346)\r\n at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:503)\r\n at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:488)\r\n at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:985)\r\n at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:247)\r\n at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:344)\r\n at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:163)\r\n at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:510)\r\n at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:518)\r\n at io.netty.util.concurrent.SingleThreadEventExecutor$6.run(SingleThreadEventExecutor.java:1044)\r\n at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)\r\n at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\r\n at java.lang.Thread.run(Thread.java:748)\r\n\r\n\r\n\r\n```\r\n\r\n', '0', '3', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-22 21:29:46', '2020-09-22 21:29:46');
INSERT INTO `zxy_blog` VALUES ('35', '92f0434c4b3043dfa4f03b3cda5b97de', '常用数据结构', ' \r\n\r\n数据结构是算法的基石,如果没有扎实的数据结构基础,想要把算法学好甚至融会贯通是非常困难的,而优秀的算法又往往取决于你采用哪种数据结构。\r\n\r\n \r\n\r\n所以,接下来两节课的主题是,在算法面试中经常会被用到的数据结构以及一些实用技巧。同时穿插一些经典的题目,加深理解。这节课主要讲:\r\n\r\n数组、字符串\r\n\r\n链表\r\n\r\n栈\r\n\r\n队列\r\n\r\n双端队列\r\n\r\n树\r\n\r\n数组、字符串(Array & String)\r\n字符串转化\r\n数组和字符串是最基本的数据结构,在很多编程语言中都有着十分相似的性质,而围绕着它们的算法面试题也是最多的。\r\n\r\n \r\n\r\n很多时候,在分析字符串相关面试题的过程中,我们往往要针对字符串当中的每一个字符进行分析和处理,甚至有时候我们得先把给定的字符串转换成字符数组之后再进行分析和处理。\r\n\r\n \r\n\r\n举例:翻转字符串“algorithm”。\r\n\r\n\r\n\r\n\r\n\r\n\r\n \r\n\r\n解法:用两个指针,一个指向字符串的第一个字符 a,一个指向它的最后一个字符 m,然后互相交换。交换之后,两个指针向中央一步步地靠拢并相互交换字符,直到两个指针相遇。这是一种比较快速和直观的方法。\r\n\r\n \r\n\r\n注意:由于无法直接修改字符串里的字符,所以必须先把字符串变换为数组,然后再运用这个算法。\r\n\r\n数组的优缺点\r\n\r\n要掌握一种数据结构,就必须要懂得分析它的优点和缺点。数组的优点在于:\r\n\r\n构建非常简单\r\n\r\n能在 O(1) 的时间里根据数组的下标(index)查询某个元素\r\n\r\n而数组的缺点在于:\r\n\r\n构建时必须分配一段连续的空间\r\n\r\n查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间(其中,n 是元素的个数)\r\n\r\n删除和添加某个元素时,同样需要耗费 O(n) 的时间\r\n\r\n所以,当你在考虑是否应当采用数组去辅助你的算法时,请务必考虑它的优缺点,看看它的缺点是否会阻碍你的算法复杂度以及空间复杂度。\r\n\r\n例题分析\r\n\r\nLeetCode 第 242 题:给定两个字符串 s 和 t,编写一个函数来判断 t 是否是 s 的字母异位词。\r\n\r\n \r\n\r\n说明:你可以假设字符串只包含小写字母。\r\n\r\n \r\n\r\n示例 1\r\n\r\n输入: s = \"anagram\", t = \"nagaram\"\r\n\r\n输出: true\r\n\r\n \r\n\r\n示例 2\r\n\r\n输入: s = \"rat\", t = \"car\"\r\n\r\n输出: false\r\n\r\n \r\n\r\n字母异位词,也就是两个字符串中的相同字符的数量要对应相等。例如,s 等于 “anagram”,t 等于 “nagaram”,s 和 t 就互为字母异位词。因为它们都包含有三个字符 a,一个字符 g,一个字符 m,一个字符 n,以及一个字符 r。而当 s 为 “rat”,t 为 “car”的时候,s 和 t 不互为字母异位词。\r\n\r\n解题思路\r\n\r\n一个重要的前提“假设两个字符串只包含小写字母”,小写字母一共也就 26 个,因此:\r\n\r\n可以利用两个长度都为 26 的字符数组来统计每个字符串中小写字母出现的次数,然后再对比是否相等;\r\n\r\n可以只利用一个长度为 26 的字符数组,将出现在字符串 s 里的字符个数加 1,而出现在字符串 t 里的字符个数减 1,最后判断每个小写字母的个数是否都为 0。\r\n\r\n按上述操作,可得出结论:s 和 t 互为字母异位词。\r\n\r\n \r\n\r\n建议:限于篇幅不对此题进行代码剖析,但是这道题非常经典,建议大家到 LeetCode 上试试。\r\n\r\n链表(LinkedList)\r\n单链表:链表中的每个元素实际上是一个单独的对象,而所有对象都通过每个元素中的引用字段链接在一起。\r\n\r\n \r\n\r\n双链表:与单链表不同的是,双链表的每个结点中都含有两个引用字段。\r\n\r\n链表的优缺点\r\n链表的优点如下:\r\n\r\n链表能灵活地分配内存空间;\r\n\r\n能在 O(1) 时间内删除或者添加元素,前提是该元素的前一个元素已知,当然也取决于是单链表还是双链表,在双链表中,如果已知该元素的后一个元素,同样可以在 O(1) 时间内删除或者添加该元素。\r\n\r\n链表的缺点是:\r\n\r\n不像数组能通过下标迅速读取元素,每次都要从链表头开始一个一个读取;\r\n\r\n查询第 k 个元素需要 O(k) 时间。\r\n\r\n应用场景:如果要解决的问题里面需要很多快速查询,链表可能并不适合;如果遇到的问题中,数据的元素个数不确定,而且需要经常进行数据的添加和删除,那么链表会比较合适。而如果数据元素大小确定,删除插入的操作并不多,那么数组可能更适合。\r\n\r\n经典解法\r\n链表是实现很多复杂数据结构的基础,经典解法如下。\r\n\r\n \r\n\r\n1. 利用快慢指针(有时候需要用到三个指针)\r\n\r\n典型题目例如:链表的翻转,寻找倒数第 k 个元素,寻找链表中间位置的元素,判断链表是否有环等等。\r\n\r\n \r\n\r\n2. 构建一个虚假的链表头\r\n\r\n \r\n\r\n一般用在要返回新的链表的题目中,比如,给定两个排好序的链表,要求将它们整合在一起并排好序。又比如,将一个链表中的奇数和偶数按照原定的顺序分开后重新组合成一个新的链表,链表的头一半是奇数,后一半是偶数。\r\n\r\n \r\n\r\n在这类问题里,如果不用一个虚假的链表头,那么在创建新链表的第一个元素时,我们都得要判断一下链表的头指针是否为空,也就是要多写一条 if else 语句。比较简洁的写法是创建一个空的链表头,直接往其后面添加元素即可,最后返回这个空的链表头的下一个节点即可。\r\n\r\n \r\n\r\n建议:在解决链表的题目时,可以在纸上或者白板上画出节点之间的相互关系,然后画出修改的方法,既可以帮助你分析问题,又可以在面试的时候,帮助面试官清楚地看到你的思路。\r\n\r\n例题分析\r\nLeetCode 第 25 题:给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。\r\n\r\n \r\n\r\n说明:\r\n\r\n你的算法只能使用常数的额外空间。\r\n\r\n你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。\r\n\r\n\r\n\r\n示例:\r\n\r\n给定这个链表:1->2->3->4->5\r\n\r\n当 k=2 时,应当返回:2->1->4->3->5\r\n\r\n当 k=3 时,应当返回:3->2->1->4->5\r\n\r\n解题思路\r\n\r\n这道题考察了两个知识点:\r\n\r\n对链表翻转算法是否熟悉\r\n\r\n对递归算法的理解是否清晰\r\n\r\n\r\n\r\n在翻转链表的时候,可以借助三个指针:prev、curr、next,分别代表前一个节点、当前节点和下一个节点,实现过程如下所示。\r\n\r\n \r\n\r\n将 curr 指向的下一节点保存到 next 指针;\r\n\r\ncurr 指向 prev,一起前进一步;\r\n\r\n重复之前步骤,直到 k 个元素翻转完毕;\r\n\r\n当完成了局部的翻转后,prev 就是最终的新的链表头,curr 指向了下一个要被处理的局部,而原来的头指针 head 成为了链表的尾巴。\r\n\r\n \r\n\r\n注意:这道题是“LeetCode 第 24 题,两个一组翻转链表“的扩展,即当 k 等于 2 时,第 25 题就变成了第 24 题。\r\n\r\n栈(Stack)\r\n特点:栈的最大特点就是后进先出(LIFO)。对于栈中的数据来说,所有操作都是在栈的顶部完成的,只可以查看栈顶部的元素,只能够向栈的顶部压⼊数据,也只能从栈的顶部弹出数据。\r\n\r\n \r\n\r\n实现:利用一个单链表来实现栈的数据结构。而且,因为我们都只针对栈顶元素进行操作,所以借用单链表的头就能让所有栈的操作在 O(1) 的时间内完成。\r\n\r\n \r\n\r\n应用场景:在解决某个问题的时候,只要求关心最近一次的操作,并且在操作完成了之后,需要向前查找到更前一次的操作。\r\n\r\n \r\n\r\n如果打算用一个数组外加一个指针来实现相似的效果,那么,一旦数组的长度发生了改变,哪怕只是在最后添加一个新的元素,时间复杂度都不再是 O(1),而且,空间复杂度也得不到优化。\r\n\r\n \r\n\r\n注意:栈是许多 LeetCode 中等难度偏上的题目里面经常需要用到的数据结构,掌握好它是十分必要的。\r\n\r\n例题分析一\r\nLeetCode 第 20 题:给定一个只包括 \'(\',\')\',\'{\',\'}\',\'[\',\']\' 的字符串,判断字符串是否有效。\r\n\r\n \r\n\r\n有效字符串需满足:\r\n\r\n左括号必须用相同类型的右括号闭合。\r\n\r\n左括号必须以正确的顺序闭合。\r\n\r\n注意:空字符串可被认为是有效字符串。\r\n\r\n \r\n\r\n示例 1\r\n\r\n输入: \"()\"\r\n\r\n输出: true\r\n\r\n \r\n\r\n示例 2\r\n\r\n输入: \"(]\"\r\n\r\n输出: false\r\n\r\n解题思路\r\n\r\n利用一个栈,不断地往里压左括号,一旦遇上了一个右括号,我们就把栈顶的左括号弹出来,表示这是一个合法的组合,以此类推,直到最后判断栈里还有没有左括号剩余。\r\n\r\n \r\n\r\n例题分析二\r\nLeetCode 第 739 题:根据每日气温列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高超过该日的天数。如果之后都不会升高,请在该位置用 0 来代替。\r\n\r\n \r\n\r\n提示:气温列表 temperatures 长度的范围是 [1, 30000]。\r\n\r\n \r\n\r\n示例:给定一个数组 T 代表了未来几天里每天的温度值,要求返回一个新的数组 D,D 中的每个元素表示需要经过多少天才能等来温度的升高。\r\n\r\n给定 T:[23, 25, 21, 19, 22, 26, 23]\r\n\r\n返回 D: [ 1, 4, 2, 1, 1, 0, 0]\r\n\r\n解题思路\r\n\r\n第一个温度值是 23 摄氏度,它要经过 1 天才能等到温度的升高,也就是在第二天的时候,温度升高到 24 摄氏度,所以对应的结果是 1。接下来,从 25 度到下一次温度的升高需要等待 4 天的时间,那时温度会变为 26 度。\r\n\r\n \r\n\r\n思路 1:最直观的做法就是针对每个温度值向后进行依次搜索,找到比当前温度更高的值,这样的计算复杂度就是 O(n2)。\r\n\r\n \r\n\r\n但是,在这样的搜索过程中,产生了很多重复的对比。例如,从 25 度开始往后面寻找一个比 25 度更高的温度的过程中,经历了 21 度、19 度和 22 度,而这是一个温度由低到高的过程,也就是说在这个过程中已经找到了 19 度以及 21 度的答案,它就是 22 度。\r\n\r\n \r\n\r\n思路 2:可以运用一个堆栈 stack 来快速地知道需要经过多少天就能等到温度升高。从头到尾扫描一遍给定的数组 T,如果当天的温度比堆栈 stack 顶端所记录的那天温度还要高,那么就能得到结果。\r\n\r\n \r\n\r\n对第一个温度 23 度,堆栈为空,把它的下标压入堆栈;\r\n\r\n下一个温度 24 度,高于 23 度高,因此 23 度温度升高只需 1 天时间,把 23 度下标从堆栈里弹出,把 24 度下标压入;\r\n\r\n同样,从 24 度只需要 1 天时间升高到 25 度;\r\n\r\n21 度低于 25 度,直接把 21 度下标压入堆栈;\r\n\r\n19 度低于 21 度,压入堆栈;\r\n\r\n22 度高于 19 度,从 19 度升温只需 1 天,从 21 度升温需要 2 天;\r\n\r\n由于堆栈里保存的是下标,能很快计算天数;\r\n\r\n22 度低于 25 度,意味着尚未找到 25 度之后的升温,直接把 22 度下标压入堆栈顶端;\r\n\r\n后面的温度与此同理。\r\n\r\n该方法只需要对数组进行一次遍历,每个元素最多被压入和弹出堆栈一次,算法复杂度是 O(n)。\r\n\r\n \r\n\r\n利用堆栈,还可以解决如下常见问题:\r\n\r\n求解算术表达式的结果(LeetCode 224、227、772、770)\r\n\r\n求解直方图里最大的矩形区域(LeetCode 84)\r\n\r\n队列(Queue)\r\n特点:和栈不同,队列的最大特点是先进先出(FIFO),就好像按顺序排队一样。对于队列的数据来说,我们只允许在队尾查看和添加数据,在队头查看和删除数据。\r\n\r\n \r\n\r\n实现:可以借助双链表来实现队列。双链表的头指针允许在队头查看和删除数据,而双链表的尾指针允许我们在队尾查看和添加数据。\r\n\r\n \r\n\r\n应用场景:直观来看,当我们需要按照一定的顺序来处理数据,而该数据的数据量在不断地变化的时候,则需要队列来帮助解题。在算法面试题当中,广度优先搜索(Breadth-First Search)是运用队列最多的地方,我们将在第 06 课时中详细介绍。\r\n\r\n双端队列(Deque)\r\n特点:双端队列和普通队列最大的不同在于,它允许我们在队列的头尾两端都能在 O(1) 的时间内进行数据的查看、添加和删除。\r\n\r\n \r\n\r\n实现:与队列相似,我们可以利用一个双链表实现双端队列。\r\n\r\n \r\n\r\n应用场景:双端队列最常用的地方就是实现一个长度动态变化的窗口或者连续区间,而动态窗口这种数据结构在很多题目里都有运用。\r\n\r\n例题分析\r\nLeetCode 第 239 题:给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口 k 内的数字,滑动窗口每次只向右移动一位。返回滑动窗口最大值。\r\n\r\n \r\n\r\n注意:你可以假设 k 总是有效的,1 ≤ k ≤ 输入数组的大小,且输入数组不为空。\r\n\r\n \r\n\r\n示例:给定一个数组以及一个窗口的长度 k,现在移动这个窗口,要求打印出一个数组,数组里的每个元素是当前窗口当中最大的那个数。\r\n\r\n输入:nums = [1, 3, -1, -3, 5, 3, 6, 7],k = 3\r\n\r\n输出:[3, 3, 5, 5, 6, 7]\r\n\r\n解题思路\r\n思路 1:移动窗口,扫描,获得最大值。假设数组里有 n 个元素,算法复杂度就是 O(n)。这是最直观的做法。\r\n\r\n \r\n\r\n思路 2:利用一个双端队列来保存当前窗口中最大那个数在数组里的下标,双端队列新的头就是当前窗口中最大的那个数。通过该下标,可以很快地知道新的窗口是否仍包含原来那个最大的数。如果不再包含,我们就把旧的数从双端队列的头删除。\r\n\r\n \r\n\r\n因为双端队列能让上面的这两种操作都能在 O(1) 的时间里完成,所以整个算法的复杂度能控制在 O(n)。\r\n\r\n  \r\n\r\n初始化窗口 k=3,包含 1,3,-1,把 1 的下标压入双端队列的尾部;\r\n\r\n把 3 和双端队列的队尾的数据逐个比较,3 >1,把 1 的下标弹出,把 3 的下标压入队尾;\r\n\r\n-1<3,-1 压入双端队列队尾保留到下一窗口进行比较;\r\n\r\n3 为当前窗口的最大值;\r\n\r\n窗口移动,-3 与队尾数据逐个比较,-3<-1,-3 压入双端队列队尾保留;\r\n\r\n3 为当前窗口的最大值;\r\n\r\n窗口继续移动,5>-3,-3 从双端队列队尾弹出;\r\n\r\n5>-1,-1 从队尾弹出;\r\n\r\n3 超出当前窗口,从队列头部弹出;\r\n\r\n5 压入队列头部,成为当前窗口最大值;\r\n\r\n继续移动窗口,操作与上述同理。\r\n\r\n\r\n\r\n窗口最大值只需读取双端队列头部元素。\r\n\r\n树(Tree)\r\n树的结构十分直观,而树的很多概念定义都有一个相同的特点:递归,也就是说,一棵树要满足某种性质,往往要求每个节点都必须满足。例如,在定义一棵二叉搜索树时,每个节点也都必须是一棵二叉搜索树。\r\n\r\n \r\n\r\n正因为树有这样的性质,大部分关于树的面试题都与递归有关,换句话说,面试官希望通过一道关于树的问题来考察你对于递归算法掌握的熟练程度。\r\n\r\n树的形状\r\n在面试中常考的树的形状有:普通二叉树、平衡二叉树、完全二叉树、二叉搜索树、四叉树(Quadtree)、多叉树(N-ary Tree)。\r\n\r\n \r\n\r\n对于一些特殊的树,例如红黑树(Red-Black Tree)、自平衡二叉搜索树(AVL Tree),一般在面试中不会被问到,除非你所涉及的研究领域跟它们相关或者你十分感兴趣,否则不需要特别着重准备。\r\n\r\n \r\n\r\n关于树的考题,无非就是要考查树的遍历以及序列化(serialization)。\r\n\r\n树的遍历\r\n\r\n1. 前序遍历(Preorder Traversal)\r\n\r\n方法:先访问根节点,然后访问左子树,最后访问右子树。在访问左、右子树的时候,同样,先访问子树的根节点,再访问子树根节点的左子树和右子树,这是一个不断递归的过程。\r\n\r\n \r\n\r\n \r\n\r\n应用场景:运用最多的场合包括在树里进行搜索以及创建一棵新的树。\r\n\r\n \r\n\r\n2. 中序遍历(Inorder Traversal)\r\n\r\n方法:先访问左子树,然后访问根节点,最后访问右子树,在访问左、右子树的时候,同样,先访问子树的左边,再访问子树的根节点,最后再访问子树的右边。\r\n\r\n \r\n\r\n应用场景:最常见的是二叉搜索树,由于二叉搜索树的性质就是左孩子小于根节点,根节点小于右孩子,对二叉搜索树进行中序遍历的时候,被访问到的节点大小是按顺序进行的。\r\n\r\n \r\n\r\n3. 后序遍历(Postorder Traversal)\r\n\r\n方法:先访问左子树,然后访问右子树,最后访问根节点。\r\n\r\n \r\n\r\n应用场景:在对某个节点进行分析的时候,需要来自左子树和右子树的信息。收集信息的操作是从树的底部不断地往上进行,好比你在修剪一棵树的叶子,修剪的方法是从外面不断地往根部将叶子一片片地修剪掉。\r\n\r\n \r\n\r\n注意:\r\n\r\n掌握好这三种遍历的递归写法和非递归写法是非常重要的,懂得分析各种写法的时间复杂度和空间复杂度同样重要。\r\n\r\n无论是前端工程师,还是后端工程师,在准备面试的时候,树这个数据结构都是最应该花时间学习的,既能证明你对递归有很好的认识,又能帮助你学习图论(关于图论,我们将在下一节课一起讨论)。树的许多性质都是面试的热门考点,尤其是二叉搜索树(BST)。\r\n\r\n\r\n\r\n建议:练习一道经典的 LeetCode 第 250 题,在一棵二叉树里,统计有多少棵子树,要求子树里面的元素拥有相同的数字。\r\n\r\n例题分析\r\nLeetCode 第 230 题:给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素。\r\n\r\n \r\n\r\n说明:你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数。\r\n\r\n解题思路\r\n\r\n这道题考察了两个知识点:\r\n\r\n二叉搜索树的性质\r\n\r\n二叉搜索树的遍历\r\n\r\n\r\n\r\n二叉搜索树的性质:对于每个节点来说,该节点的值比左孩子大,比右孩子小,而且一般来说,二叉搜索树里不出现重复的值。\r\n\r\n \r\n\r\n二叉搜索树的中序遍历是高频考察点,节点被遍历到的顺序是按照节点数值大小的顺序排列好的。即,中序遍历当中遇到的元素都是按照从小到大的顺序出现。\r\n\r\n \r\n\r\n因此,我们只需要对这棵树进行中序遍历的操作,当访问到第 k 个元素的时候返回结果就好。\r\n\r\n \r\n\r\n注意:这道题可以变成求解第 K 大的元素,方法就是对这个二叉搜索树进行反向的中序遍历,那么数据的被访问顺序就是由大到小了。', '0', '25', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '6', '其它', '2020-09-22 21:32:21', '2020-09-22 21:32:21');
INSERT INTO `zxy_blog` VALUES ('36', '673e6c764e854c91a2e16a81c3c5cb25', '微信小程序开发环境安装以及开发者账号注册', '# **微信小程序开发环境安装以及开发者账号注册**\r\n\r\n\r\n微信小程序,小程序的一种,英文名Wechat Mini Program,是一种不需要下载安装即可使用的应用,它实现了应用“触手可及”的梦想,用户扫一扫或搜一下即可打开应用。许多小伙伴肯定都想开发一款属于自己的小程序,快来跟我一起学吧。\r\n\r\n\r\n## 安装开发环境\r\n\r\n安装小程序开发环境,是开发小程序的第一步:\r\n 1. 登录微信小程序官方网站:[https://developers.weixin.qq.com/miniprogram/dev/devtools/download.html](https://developers.weixin.qq.com/miniprogram/dev/devtools/download.html)\r\n 2. 点击对应的操作系统(Windows 64 、 Windows 32 、 macOS)下载,建议下载稳定版的。\r\n\r\n\r\n\r\n 3. 下载完即可安装。安装过程比较简单,这里就不细讲。\r\n\r\n点击下一步。\r\n\r\n选择好安装的位置,建议别安装在C盘。\r\n\r\n安装后即可打开。这就是微信小程序开发环境了。\r\n\r\n\r\n\r\n\r\n\r\n\r\n## 注册微信小程序开发者账号\r\n1. 打开网址 [https://mp.weixin.qq.com/](https://mp.weixin.qq.com/) 点击立即注册按钮\r\n\r\n\r\n2. 选择 “小程序”\r\n\r\n\r\n3. 填写个人信息(注意:填写的邮箱必须是未被微信公众平台注册,未被微信开放平台注册,未被个人微信号绑定的邮箱)\r\n\r\n4.平台会进行邮箱验证,点击超链接即可完成验证。\r\n\r\n\r\n5.验证成功后,即可用账号在前面安装的微信开发者工具登录了。\r\n点击 + 号,创建自己的第一个项目吧!\r\n\r\n**以下是我个人的一些学习分享,希望对刚入门的小白有所帮助,后续我会更新一些开发的内容。** ', '0', '3', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '5', '前端', '2020-09-23 20:19:10', '2020-09-23 20:19:10');
INSERT INTO `zxy_blog` VALUES ('37', '0f6672b914884afda7ee22abddbf787d', '大数据实验环境准备与配置(1/4)', '# 大数据实验环境准备与配置(1/4)\r\nLinux下JDK软件的安装与配置(2/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108619802\r\n掌握Linux下Eclipse软件的安装与配置(3/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108691921\r\n熟悉的Hadoop的下载与解压(4/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108697510\r\n###### 第一部分:Hadoop环境搭建前的Linux环境安装与配置\r\n(1) 搜索 “Ubuntu”,选择官方下载。或者打开网站:[https://ubuntu.com/download/desktop](https://ubuntu.com/download/desktop)\r\n\r\n\r\n(2) 点击绿色的 Download按钮。\r\n\r\n(3) 这个官方网站是全速下载,这里391KB/s是因为我网络全速就这样/(ㄒoㄒ)/~~\r\n\r\n(4) iso文件下载完成后,在已经准备好的虚拟机软件VMware里面进行Ubuntu系统的安装\r\n\r\n选择 “创建新的虚拟机”\r\n\r\n(5) 选择 “典型(推荐)”\r\n\r\n(6) 点击“浏览”找到前面下载的iso文件。再点击下一步。\r\n\r\n\r\n(7)填写简易的安装信息。\r\n(8) 选择好安装的位置。\r\n\r\n\r\n(9) 磁盘大小选择100G,如果感觉自己磁盘不够的同学,可以适当减少。但是不要低于25G\r\n\r\n(10) 点击“自定义硬件”\r\n\r\n\r\n\r\n(11) 内存分配建议在2G以上,这里我个人给到的是8G(我是双通道16G的内存,如果你电脑只有8G建议给到4G,加开系统安装速度)\r\n\r\n(12) 安装完成后,会有以下画面。选择Ubuntu 64位,输入前面设置的用户名密码。\r\n\r\n\r\n这样,桌面版的Ubuntu操作系统就完成安装了\r\n\r\n温馨提示:安装Ubuntu虚拟机前必须到BIOS中开启虚拟化技术支持。\r\n\r\n\r\n(13) 鼠标右键点击桌面,选择“Open Terminal”打开终端\r\n(14) 创建hadoop用户并安装vim编辑器\r\n终端命令:sudo adduser hadoop\r\n\r\n\r\n终端命令:sudo apt-get install vim \r\n\r\n(如果提示没有vim安装包,首先执行第(16)步,再执行apt-get update更新软件包,然后再进行vim安装。)\r\n\r\n\r\n(15) 用刚创建的hadoop用户进入Ubuntu系统,,测试hadoop用户是否创建成功。\r\n终端命令:su hadoop\r\n\r\n\r\n(16) 进入root用户/etc目录,编辑sudoers\r\n终端命令:\r\nsu root \r\ncd /etc\r\nvi sudoers\r\n\r\n编辑sudoers时候,用的是vim,与传统的文本编辑器不一样,没用鼠标操作,需要特殊的命令\r\nvim操作教程:[https://www.runoob.com/linux/linux-vim.html](https://www.runoob.com/linux/linux-vim.html)\r\n给hadoop用户增加权限\r\n\r\n(17) 安装SSH\r\n集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:\r\n\r\n终端命令:sudo apt-get install openssh-server\r\n \r\n\r\n安装后,可以使用如下命令登陆本机:\r\nssh localhost\r\n此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。\r\n \r\n\r\n(18) 配置SSH无密码登陆\r\n但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。\r\n\r\n首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:\r\nexit # 退出刚才的 ssh localhost\r\ncd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost\r\nssh-keygen -t rsa # 会有提示,都按回车就可以\r\ncat ./id_rsa.pub >> ./authorized_keys # 加入授权\r\n\r\n\r\n\r\n此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。\r\n\r\n \r\n\r\n\r\n**关于这个实验的第一步到此就完成了,因为内容比较多,所以我分成了四个部分,后续会继续更新。坚持做到这里的小伙伴都很棒!希望各位小伙伴保持对技术的追求。**', '0', '7', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-23 20:20:22', '2020-09-23 20:26:02');
INSERT INTO `zxy_blog` VALUES ('38', 'd948078b57cb4cf7878a55404eb3b4ab', '大数据实验环境准备与配置(2/4)', ' # 大数据实验环境准备与配置(2/4)\r\n##### 第二部分:JDK软件的安装与配置\r\nHadoop环境构建前的Linux环境安装与配置(1/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108614907\r\n掌握Linux下Eclipse软件的安装与配置(3/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108691921\r\n熟悉的Hadoop的下载与解压(4/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108697510\r\n(1)下载JDK软件\r\n有两种方法:在线安装以及拖拽安装包进行手动安装。\r\n在线安装比较简单,这里就只讲第二种:在Windows上下载jdk安装包,然后拖拽到Ubuntu系统里面进行安装\r\n以下是官方网站\r\n[https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html](https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html)\r\n\r\n点击后会提示登录后下载,输入账户后,会自动下载。\r\n\r\n(没有账户的也可以用邮箱注册,流程很简单)\r\n下载的速度与之前的Ubuntu镜像一样是全速下载。\r\n\r\n下载完成后,把安装包拖拽到该文件夹内\r\n\r\n\r\n(2)进入/opt目录,创建java文件夹,然后解压JDK到该文件夹。\r\n终端命令:sudo mkdir /opt/java\r\n终端命令:sudo tar -zxvf jdk-8u261-linux-x64.tar.gz -C /opt/java/\r\n\r\n(3)配置jdk环境变量(有2种方式,修改profile或者.bashrc,任选一即可,二者区别自行学习)\r\n编辑profile时候,用的是vim,与传统的文本编辑器不一样,没用鼠标操作,需要特殊的命令\r\nvim操作教程:[https://www.runoob.com/linux/linux-vim.html](https://www.runoob.com/linux/linux-vim.html)\r\n\r\n终端命令:sudo vim /etc/profile\r\n\r\n\r\n增加如下内容:\r\nexport JAVA_HOME=/opt/java/jdk1.8.0_261\r\nexport PATH=$PATH: $JAVA_HOME/bin\r\n\r\n(4)重新加载环境变量脚本\r\n终端命令:source /etc/profile\r\n\r\n\r\n\r\n\r\n\r\n\r\n(5)验证Java是否生效\r\njava -version \r\n\r\n**当出现上述验证成功后,第二部分也就完成了,这一部分比较简单,接下来会继续更新后续,敬请期待。** ', '0', '5', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-23 20:21:25', '2020-09-23 20:26:32');
INSERT INTO `zxy_blog` VALUES ('39', '507d5287b7ab42a2a8b90e8071027e04', '大数据实验环境准备与配置(3/4)', '# 大数据实验环境准备与配置(3/4)\r\n#### 第三部分:Linux下Eclipse软件的安装与配置\r\n\r\nHadoop环境构建前的Linux环境安装与配置(1/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108614907\r\nLinux下JDK软件的安装与配置(2/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108619802\r\n熟悉的Hadoop的下载与解压(4/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108697510\r\n\r\n(1)在线下载并拷贝到当前用户Downloads目录下面\r\n下载地址:[https://www.eclipse.org/downloads/](https://www.eclipse.org/downloads/)\r\n点击 “Download Packages”\r\n\r\n选择对应的操作系统下载。\r\n这里注意!选择其他镜像\r\n\r\n\r\n选择国内的下载点,才能达到全速下载。\r\n\r\n拷贝到Downloads目录下(直接拖拽进去)\r\n\r\n\r\n\r\n(2) 解压eclipse到/opt目录下\r\n鼠标右键点击空白处,选择打开终端”Open in Terminal“\r\n\r\n输入终端命令:sudo tar -zxvf eclipse-committers-2020-09-R-linux-gtk-x86_64.tar.gz -C /opt\r\n\r\n(3) 在linux系统中设置eclipse快捷方式并向eclipse .desktop中添加以下内容:\r\n\r\n终端命令:sudo gedit /usr/share/applications/eclipse.desktop\r\n\r\n添加的内容:\r\n[Desktop Entry]\r\nEncoding=UTF-8\r\nName=Eclipse\r\nComment=Eclipse IDE\r\nExec=/opt/eclipse/eclipse \r\nIcon=/opt/eclipse/icon.xpm\r\nTerminal=false\r\nStartupNotify=true\r\nType=Application\r\nCategories=Application;Developmet;\r\n\r\n\r\n(4) 给eclipse .desktop文件赋权 :\r\n\r\n终端命令:cd /usr/share/applications\r\n\r\n终端命令:sudo chmod u+x eclipse.desktop(如果想让所有用户可以用把u+x改成a+x)\r\n\r\n\r\n(5)找到/usr/share/applications/eclipse.desktop(可以看到Eclipse的图标),鼠标右键选择 copy to desktop,即可。\r\n\r\n\r\n\r\n\r\n(6)打开并创建自己第一个项目。\r\n双击打开Eclipse \r\n\r\n创建自己的第一个项目\r\n\r\n\r\n\r\n\r\n```javascript\r\npublic class clh {\r\n public static void main(String[] args){\r\n System.out.println(\"hello world\");\r\n }\r\n}\r\n```\r\n\r\n\r\n** 第三部分到这里就结束了,第三第四都会比较简单,加把劲把它完成 **\r\n', '0', '6', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-23 20:22:01', '2020-09-23 20:27:09');
INSERT INTO `zxy_blog` VALUES ('40', '9b9c9d1971ac44e7ae543ca1af95ecb8', ' 大数据实验环境准备与配置(第四部分完结)', '# 大数据实验环境准备与配置(第四部分完结)\r\n\r\n#### 第四部分:Hadoop的下载与解压\r\n\r\nHadoop环境构建前的Linux环境安装与配置(1/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108614907\r\nLinux下JDK软件的安装与配置(2/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108619802\r\n掌握Linux下Eclipse软件的安装与配置(3/4)\r\nhttps://blog.csdn.net/weixin_43640161/article/details/108691921\r\n\r\n(1)Hadoop安装包下载\r\n下载地址:[http://hadoop.apache.org/releases.html](http://hadoop.apache.org/releases.html)\r\n(在Ubuntu系统里面的浏览器打开)\r\n可以自己选择版本,最新版是hadoop-3.3.0.tar.gz\r\n\r\n\r\n下载完成后,可以在\"Downloads\"里面查看\r\n\r\n(2)解压安装包\r\n先新建文件夹bigdata,解压到该目录下。\r\n终端命令:sudo mkdir /bigdata\r\n\r\n解压安装包:\r\n终端命令:sudo tar -zxvf hadoop-3.3.0-src.tar.gz -C /bigdata/\r\n\r\n\r\n在Hadoop安装包目录下有几个比较重要的目录\r\nsbin : 启动或停止Hadoop相关服务的脚本\r\nbin :对Hadoop相关服务(HDFS,YARN)进行操作的脚本\r\netc : Hadoop的配置文件目录\r\nshare :Hadoop的依赖jar包和文档,文档可以被删掉\r\nlib :Hadoop的本地库(对数据进行压缩解压缩功能的)\r\n\r\n都在这些文件夹下。\r\n\r\n(4)修改文件夹权限:\r\n**做到这里,大数据实验环境准备与配置就全部完成了,接下来会更新一些大数据的学习实验大家不要放弃,要对技术有追求**', '0', '4', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-23 20:22:48', '2020-09-23 20:27:42');
INSERT INTO `zxy_blog` VALUES ('41', 'f2e39cebae9d4953be9401f9f65b4696', 'Hadoop环境配置与测试', '# Hadoop环境配置与测试\r\n前面的实验我们做好了Linux环境和Hadoop环境的准备与配置工作,因此这一实验我们在上一实验的基础上进行Hadoop环境的配置和测试。\r\n\r\nHadoop环境搭建前的Linux环境安装与配置\r\n[https://blog.csdn.net/weixin_43640161/article/details/108614907](https://blog.csdn.net/weixin_43640161/article/details/108614907)\r\nLinux下JDK软件的安装与配置\r\n[https://blog.csdn.net/weixin_43640161/article/details/108619802](https://blog.csdn.net/weixin_43640161/article/details/108619802)\r\n掌握Linux下Eclipse软件的安装与配置\r\n[https://blog.csdn.net/weixin_43640161/article/details/108691921](https://blog.csdn.net/weixin_43640161/article/details/108691921)\r\n熟悉Hadoop的下载与解压\r\n[https://blog.csdn.net/weixin_43640161/article/details/108697510](https://blog.csdn.net/weixin_43640161/article/details/108697510)\r\n\r\nHadoop的安装方式有三种,分别是单机模式,伪分布式模式,分布式模式。\r\n• 单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。\r\n• 伪分布式模式:Hadoop可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。\r\n• 分布式模式:使用多个节点构成集群环境来运行Hadoop。\r\n• 本实验采取单机伪分布式模式进行安装。\r\n\r\n重要知识点提示:\r\n1. Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件\r\n2. Hadoop 的配置文件位于 hadoop/etc/hadoop/ 中,伪分布式需要修改5个配置文件hadoop-env.sh、 core-site.xml 、 hdfs-site.xml 、mapred-site.xml和yarn-site.xml\r\n3. Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现\r\n实验步骤:\r\n1. 修改配置文件:hadoop-env.sh、core-site.xml,hdfs-site.xml,mapred-site.xml、yarn-site.xml\r\n2. 初始化文件系统hadoop namenode -format\r\n4. 启动所有进程start-all.sh或者start-dfs.sh、start-yarn.sh\r\n5. 访问web界面,查看Hadoop信息\r\n6. 运行实例\r\n7. 停止所有实例:stop-all.sh\r\n\r\n\r\n\r\n### 第一步:配置Hadoop环境(jdk版本不同,修改的内容也不同,我这里是jdk1.8.0_181和hadoop-3.1.1)\r\n1.配置Hadoop(伪分布式),修改其中的5个配置文件即可\r\n1) 进入到Hadoop的etc目录下\r\n终端命令:cd /bigdata/hadoop-3.1.1/etc/hadoop\r\n\r\n\r\n2) 修改第1个配置文\r\n终端命令:sudo vi hadoop-env.sh\r\n \r\n\r\n找到第54行,修改JAVA_HOME如下(记得去掉前面的 # 号):\r\n```\r\nexport JAVA_HOME=/opt/java/jdk1.8.0_181\r\n```\r\n\r\n\r\n\r\n\r\n3) 修改第2个配置文件\r\n终端命令:sudo vi core-site.xml\r\n \r\n\r\n\r\n```\r\n\r\n \r\n \r\n fs.defaultFS \r\n hdfs://localhost:9000 \r\n \r\n\r\n \r\n \r\n hadoop.tmp.dir \r\n file:/bigdata/hadoop-3.1.1/tmp \r\n \r\n \r\n```\r\n\r\n4) 修改第3个配置文件\r\n终端命令:sudo vi hdfs-site.xml\r\n \r\n\r\n```\r\n\r\n \r\n \r\n dfs.replication \r\n 1 \r\n \r\n\r\n dfs.namenode.http-address \r\n localhost:50070 \r\n \r\n\r\n\r\n dfs.namenode.name.dir \r\n file:/bigdata/hadoop-3.1.1/tmp/dfs/name \r\n \r\n \r\n dfs.datanode.data.dir \r\n file:/bigdata/hadoop-3.1.1/tmp/dfs/data \r\n \r\n\r\n \r\n```\r\n此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。\r\n\r\n\r\n5) 修改第4个配置文件:\r\n终端命令:sudo vi mapred-site.xml\r\n \r\n\r\n```\r\n\r\n \r\n \r\n mapreduce.framework.name \r\n yarn \r\n \r\n \r\n \r\n```\r\n6) 修改第5个配置文件\r\nsudo vi yarn-site.xml\r\n \r\n\r\n```\r\n\r\n \r\n \r\n yarn.resourcemanager.hostname \r\n localhost \r\n \r\n \r\n \r\n \r\n yarn.nodemanager.aux-services \r\n mapreduce_shuffle \r\n \r\n \r\n \r\n```\r\n7) 对hdfs进行初始化(格式化HDFS)\r\n终端命令:\r\ncd /bigdata/hadoop-3.1.1/bin/\r\nsudo ./hdfs namenode -format\r\n \r\n\r\n8) 如果提示如下信息,证明格式化成功:\r\n \r\n\r\n\r\n### 第二步:启动并测试Hadoop\r\n1)\r\n终端命令:\r\ncd /bigdata/hadoop-3.1.1/sbin/\r\nssh localhost\r\nsudo ./start-dfs.sh\r\nsudo ./start-yarn.sh\r\nstart-all.sh\r\n \r\n\r\n如果报以上错误,请修改下面4个文件如下:\r\n在/hadoop/sbin路径下: \r\n将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数\r\n```\r\n#!/usr/bin/env bash\r\nHDFS_DATANODE_USER=root\r\nHADOOP_DATANODE_SECURE_USER=hdfs\r\nHDFS_NAMENODE_USER=root\r\nHDFS_SECONDARYNAMENODE_USER=root\r\n```\r\n终端命令: sudo vi start-dfs.sh\r\n\r\n\r\n\r\n终端命令: sudo vi stop-dfs.sh\r\n\r\n\r\n\r\n\r\n\r\n还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:\r\n ```\r\n#!/usr/bin/env bash\r\nYARN_RESOURCEMANAGER_USER=root\r\nHADOOP_SECURE_DN_USER=yarn\r\nYARN_NODEMANAGER_USER=root\r\n```\r\n 终端命令: sudo vi start-yarn.sh\r\n \r\n\r\n 终端命令: sudo vi start-yarn.sh\r\n \r\n\r\n修改后重启./start-all.sh,成功!\r\n \r\n此外,如果出现以下错误:\r\n\r\n用以下方式解决:\r\n终端命令:\r\nssh localhost\r\ncd /bigdata/hadoop-3.1.1/\r\nsudo chmod -R 777 logs\r\nsudo chmod -R 777 tmp\r\n\r\n\r\n\r\n2) 使用jps命令检查进程是否存在,总共5个进程(jps除外),每次重启,进程ID号都会不一样。如果要关闭可以使用 stop-all.sh命令。\r\n4327 DataNode\r\n4920 NodeManager\r\n4218 NameNode\r\n4474 SecondaryNameNode\r\n4651 ResourceManager\r\n5053 Jps\r\n \r\n\r\n3) 访问hdfs的管理界面\r\nlocalhost:50070\r\n \r\n\r\n4) 访问yarn的管理界面\r\nlocalhost:8088\r\n \r\n\r\n\r\n5) 如果点击节点Nodes,发现ubuntu:8042也可访问\r\n \r\n\r\n\r\n\r\n6) 如果想停止所有服务,请输入sbin/stop-all.sh\r\n \r\n\r\n\r\n\r\n**以上就是Hadoop环境配置与测试的内容,如果遇到一些奇奇怪怪的错误,可以在评论区留言。**\r\n', '0', '6', 'f5005d60326c45f7b31046fa3c1f1753', '陈林浩', '/images/avatar/avatar-1.jpg', '3', '大数据', '2020-09-23 20:24:55', '2020-09-23 20:24:55');
-- ----------------------------
-- Table structure for zxy_blog_category
-- ----------------------------
DROP TABLE IF EXISTS `zxy_blog_category`;
CREATE TABLE `ks_blog_category` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`category` varchar(50) NOT NULL COMMENT '博客分类',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_blog_category
-- ----------------------------
INSERT INTO `zxy_blog_category` VALUES ('1', '量化投资');
INSERT INTO `zxy_blog_category` VALUES ('2', '金融财经');
INSERT INTO `zxy_blog_category` VALUES ('3', '大数据');
INSERT INTO `zxy_blog_category` VALUES ('4', '后端');
INSERT INTO `zxy_blog_category` VALUES ('5', '前端');
INSERT INTO `zxy_blog_category` VALUES ('6', '其它');
-- ----------------------------
-- Table structure for zxy_comment
-- ----------------------------
DROP TABLE IF EXISTS `zxy_comment`;
CREATE TABLE `zxy_comment` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`comment_id` varchar(200) NOT NULL COMMENT '评论唯一id',
`topic_category` int(1) NOT NULL COMMENT '1博客 2问答',
`topic_id` varchar(200) NOT NULL COMMENT '评论主题id',
`user_id` varchar(200) NOT NULL COMMENT '评论者id',
`user_name` varchar(200) NOT NULL COMMENT '评论者昵称',
`user_avatar` varchar(500) NOT NULL COMMENT '评论者头像',
`content` longtext NOT NULL COMMENT '评论内容',
`gmt_create` datetime NOT NULL COMMENT '评论创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=144 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_comment
-- ----------------------------
INSERT INTO `zxy_comment` VALUES ('137', '13a7c0777b774bb0b907117ad5a27dde', '2', 'b0c4c0e64d0644678e7ef6dcb245311f', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '沙雕', '2020-09-22 16:08:53');
INSERT INTO `zxy_comment` VALUES ('138', '14c60b2b67674c4ca636f4c22d167ac1', '1', '92f0434c4b3043dfa4f03b3cda5b97de', 'f4941f85aae24d2dbb4e3cea3c5db323', '小小12138', '/images/avatar/avatar-1.jpg', '大神666', '2020-09-22 23:10:14');
INSERT INTO `zxy_comment` VALUES ('139', 'd7496bb4a00d44b986e66d66bd7ec0e8', '2', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '测试成功\r\n', '2020-09-22 23:57:47');
INSERT INTO `zxy_comment` VALUES ('140', '417866117d15495d94ed1a4a4ab39a07', '1', '92f0434c4b3043dfa4f03b3cda5b97de', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '66666666666666666666666666666666666666666666666', '2020-09-23 13:27:28');
INSERT INTO `zxy_comment` VALUES ('141', 'd989c4b67cc64522abc8959d925d17ed', '1', '561728b1887d471e9dd07d8dee66597e', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '66666666666666666666666666666666666666666666666666666666', '2020-09-23 13:28:00');
INSERT INTO `zxy_comment` VALUES ('142', 'faa8a4108ae441d3878a16902e8f162d', '2', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', '792f0067471f4da683370288a32e8165', '13006703947', '/images/avatar/avatar-1.jpg', '666\r\n', '2020-09-23 13:28:17');
INSERT INTO `zxy_comment` VALUES ('143', '7a500047696f4566be618c644f531259', '2', '7b17b466935f4226bb9c48c710854ca7', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', 'ok\r\n', '2020-09-23 13:57:38');
-- ----------------------------
-- Table structure for zxy_download
-- ----------------------------
DROP TABLE IF EXISTS `zxy_download`;
CREATE TABLE `zxy_download` (
`dname` varchar(100) NOT NULL COMMENT '资源名',
`ddesc` varchar(500) NOT NULL COMMENT '资源链接',
`dcode` varchar(50) NOT NULL COMMENT '提取码'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_download
-- ----------------------------
INSERT INTO `zxy_download` VALUES ('程序员必看学习基础资料', 'https://pan.baidu.com/s/1n4DzLGzE6XOKdLMnkbf9rQ', 'f0it');
INSERT INTO `zxy_download` VALUES ('spark推荐算法与项目实战', 'https://www.bilibili.com/video/BV1dK4y1h7Ww', '无');
INSERT INTO `zxy_download` VALUES ('微信小程序全栈开发', 'https://www.bilibili.com/video/BV19T4y1g79J', '无');
-- ----------------------------
-- Table structure for zxy_invite
-- ----------------------------
DROP TABLE IF EXISTS `zxy_invite`;
CREATE TABLE `zxy_invite` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`code` varchar(200) NOT NULL COMMENT '邀请码',
`uid` varchar(200) DEFAULT NULL COMMENT '用户id',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '状态 0 未使用 1 使用',
`active_time` datetime DEFAULT NULL COMMENT '激活时间',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1217 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_invite
-- ----------------------------
INSERT INTO `zxy_invite` VALUES ('1', '1111', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '1', '2020-09-22 15:56:27', '2020-09-22 15:54:17');
INSERT INTO `zxy_invite` VALUES ('2', '2222', '792f0067471f4da683370288a32e8165', '1', '2020-09-23 13:26:57', '2020-09-22 17:46:03');
INSERT INTO `zxy_invite` VALUES ('3', '3333', '04624db4faa74bdf9b1f728a51ff045a', '1', '2020-09-22 22:02:05', '2020-09-22 18:20:06');
INSERT INTO `zxy_invite` VALUES ('4', '4444', '3eba03a0de3842d3921ec4df7948f38c', '1', '2020-09-22 21:48:40', '2020-09-22 18:20:13');
INSERT INTO `zxy_invite` VALUES ('5', '5555', 'f4941f85aae24d2dbb4e3cea3c5db323', '1', '2020-09-22 23:07:43', '2020-09-22 23:05:17');
INSERT INTO `zxy_invite` VALUES ('6', '6666', 'f5005d60326c45f7b31046fa3c1f1753', '1', '2020-09-23 20:15:38', '2020-09-22 23:51:26');
INSERT INTO `zxy_invite` VALUES ('7', '7777', 'e8c38b7a4c31497b9d98119e0ea62bec', '1', '2020-09-23 20:56:07', '2020-09-22 23:51:36');
INSERT INTO `zxy_invite` VALUES ('8', '8888', 'aee71a1ddc86453db0c8d500741b8db9', '1', '2020-09-23 20:55:59', '2020-09-22 23:51:45');
INSERT INTO `zxy_invite` VALUES ('9', '9999', null, '0', null, '2020-09-22 23:51:54');
INSERT INTO `zxy_invite` VALUES ('10', '10-10', 'fe765316b02741d096d6c7809ce1cbd9', '1', '2020-09-25 19:26:31', '2020-09-22 23:52:05');
INSERT INTO `zxy_invite` VALUES ('11', '11-11', null, '0', null, '2020-09-22 23:52:28');
-- ----------------------------
-- Table structure for zxy_question
-- ----------------------------
DROP TABLE IF EXISTS `zxy_question`;
CREATE TABLE `zxy_question` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`qid` varchar(200) NOT NULL COMMENT '问题id',
`title` varchar(200) NOT NULL COMMENT '问题标题',
`content` longtext NOT NULL COMMENT '问题内容',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '状态 0 未解决 1 已解决',
`sort` int(1) NOT NULL DEFAULT '0' COMMENT '排序 0 普通 1 置顶',
`views` int(10) NOT NULL DEFAULT '0' COMMENT '浏览量',
`author_id` varchar(200) NOT NULL COMMENT '作者id',
`author_name` varchar(200) NOT NULL COMMENT '作者名',
`author_avatar` varchar(500) NOT NULL COMMENT '作者头像',
`category_id` int(10) NOT NULL COMMENT '问题分类id',
`category_name` varchar(50) NOT NULL COMMENT '问题分类名称',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=38 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_question
-- ----------------------------
INSERT INTO `zxy_question` VALUES ('36', 'fe4f2ad1d4b94bbbb419ae789c3e5a65', '解决虚拟机没办法在复制粘贴本机内容问题!', '# 1.下载xshell\r\n下载链接:https://www.netsarang.com/zh/xshell/#learnmore\r\n学生可以申请学生认证,无需花钱\r\n\r\n# 2.获取虚拟机ip地址\r\n\r\n获取ip地址之前需要将虚拟机网络配置好!\r\n确定可以上网验证方法:\r\n```shell\r\nping www.baidu.com\r\n```\r\n\r\n\r\n出现图片情况即网络配置成功!\r\n\r\n使用ifconfig获取ip地址\r\n\r\n\r\n# 3.利用xshell进行登陆\r\n\r\n\r\n\r\n# 4.复制粘贴操作\r\n\r\n我们在xshell中右键可以看到:\r\n复制:ctrl+insert\r\n粘贴:shift+insert\r\n\r\n我们在windows中复制的内容就可以在xshell中进行**shift+insert**粘贴操作!', '1', '0', '13', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '3', '无聊问问', '2020-09-22 23:57:34', '2020-09-23 13:57:54');
INSERT INTO `zxy_question` VALUES ('37', '7b17b466935f4226bb9c48c710854ca7', '启动springboot时thymeleaf找不到静态资源文件', ' 1、首先需要在配置文件中加入配置:\r\n ```xml\r\nspring.resources.static-locations=classpath:/static/\r\n```\r\n2、在html页面中引用的地方(以引用js文件为例)\r\n```js\r\n\r\n```', '1', '0', '4', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '17728021074', '/images/avatar/avatar-1.jpg', '2', '技术问题', '2020-09-23 13:57:27', '2020-09-23 13:57:27');
-- ----------------------------
-- Table structure for zxy_question_category
-- ----------------------------
DROP TABLE IF EXISTS `zxy_question_category`;
CREATE TABLE `zxy_question_category` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`category` varchar(50) NOT NULL COMMENT '问题分类',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_question_category
-- ----------------------------
INSERT INTO `zxy_question_category` VALUES ('1', '无聊问问');
INSERT INTO `zxy_question_category` VALUES ('2', '技术问题');
INSERT INTO `zxy_question_category` VALUES ('3', '其它问题');
-- ----------------------------
-- Table structure for zxy_say
-- ----------------------------
DROP TABLE IF EXISTS `zxy_say`;
CREATE TABLE `zxy_say` (
`id` varchar(200) NOT NULL COMMENT '唯一id',
`title` varchar(200) NOT NULL COMMENT '标题',
`content` varchar(5000) NOT NULL COMMENT '内容',
`gmt_create` datetime NOT NULL COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_say
-- ----------------------------
INSERT INTO `zxy_say` VALUES ('1', '版本上线', '0.1.0版本正式上线', '2020-09-22 18:38:18');
INSERT INTO `zxy_say` VALUES ('2', '重大通知', '有任何问题可以添加QQ群:1048243871进行提问', '2020-09-22 21:37:20');
INSERT INTO `zxy_say` VALUES ('3', '社区规则', '每个账号每月至少发布一篇博客,我们会对未发布博客的账号进行定时清理', '2020-09-23 23:47:20');
-- ----------------------------
-- Table structure for zxy_user
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user`;
CREATE TABLE `zxy_user` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`uid` varchar(200) NOT NULL COMMENT '用户编号',
`role_id` int(10) NOT NULL COMMENT '角色编号',
`username` varchar(100) NOT NULL COMMENT '用户名',
`password` varchar(200) NOT NULL COMMENT '密码',
`avatar` varchar(500) NOT NULL DEFAULT '/images/avatar/avatar-1.jpg' COMMENT '头像',
`login_date` datetime NOT NULL COMMENT '登录时间',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=851 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_user
-- ----------------------------
INSERT INTO `zxy_user` VALUES ('840', 'a2ff39a3a7944181a4d3e5bc05ae7c64', '2', '17728021074', '$2a$10$ncC7.yRCa7MhMghssqTlbe4EzwtRGNftUAs4vOQW7DpAmti46WGve', '/images/avatar/avatar-1.jpg', '2020-09-22 15:56:27', '2020-09-22 15:56:27');
INSERT INTO `zxy_user` VALUES ('843', '3eba03a0de3842d3921ec4df7948f38c', '2', 'okc123', '$2a$10$ISrB8PjEYpWFHMKykxSirOY7Cm9d2dWhy.0tg/gDh332296zXHCDq', '/images/avatar/avatar-1.jpg', '2020-09-22 21:48:40', '2020-09-22 21:48:40');
INSERT INTO `zxy_user` VALUES ('844', '04624db4faa74bdf9b1f728a51ff045a', '2', '大佳', '$2a$10$ifvl59ZGOJ6lxQMZJJqNz.S8H66PDACFTcD.vay6tcJacw4d.jPQC', '/images/avatar/avatar-1.jpg', '2020-09-22 22:02:05', '2020-09-22 22:02:05');
INSERT INTO `zxy_user` VALUES ('845', 'f4941f85aae24d2dbb4e3cea3c5db323', '2', '小小12138', '$2a$10$HB7mFXU5eKcQQqEBnDSgFegUG1pdlSnjYw1OoxAeo/E3hIEzNDOyG', '/images/avatar/avatar-1.jpg', '2020-09-22 23:07:43', '2020-09-22 23:07:43');
INSERT INTO `zxy_user` VALUES ('846', '792f0067471f4da683370288a32e8165', '2', '13006703947', '$2a$10$..Ch/d/wOvED/NKusu8NaeYfE/S7MZUzWZTfwSC.C9YyLpAyQNbsS', '/images/avatar/avatar-1.jpg', '2020-09-23 13:26:57', '2020-09-23 13:26:57');
INSERT INTO `zxy_user` VALUES ('847', 'f5005d60326c45f7b31046fa3c1f1753', '2', '陈林浩', '$2a$10$pfEYX3hyooKOckkumPM7K.1PUo2wCMXvWW50DmRDIKab5Iw3JBU8S', '/images/avatar/avatar-1.jpg', '2020-09-23 20:15:38', '2020-09-23 20:15:38');
INSERT INTO `zxy_user` VALUES ('848', 'aee71a1ddc86453db0c8d500741b8db9', '2', 'lincanfeng', '$2a$10$FK1rL8sJ5kzPK5qapNc.7uqUIk/5ehhSQnsEKv3SmtduP1GPRYrJy', '/images/avatar/avatar-1.jpg', '2020-09-23 20:55:59', '2020-09-23 20:55:59');
INSERT INTO `zxy_user` VALUES ('849', 'e8c38b7a4c31497b9d98119e0ea62bec', '2', 'JUNJIE_H', '$2a$10$tkUBeIdm35M11yhpcN3NtuU6yLJ5A.eDzvRcdBVkHVcc9VlsRtovi', '/images/avatar/avatar-1.jpg', '2020-09-23 20:56:07', '2020-09-23 20:56:07');
INSERT INTO `zxy_user` VALUES ('850', 'fe765316b02741d096d6c7809ce1cbd9', '2', 'choudc', '$2a$10$rmAm/HsQVJxLZDRW8bBzee2HUDsmqUm6dc58EU0RTMExFThxVSYoq', '/images/avatar/avatar-1.jpg', '2020-09-25 19:26:31', '2020-09-25 19:26:31');
-- ----------------------------
-- Table structure for zxy_user_donate
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user_donate`;
CREATE TABLE `zxy_user_donate` (
`uid` varchar(200) NOT NULL COMMENT '用户id',
`donate_json` varchar(2000) NOT NULL COMMENT '赞赏二维码信息'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_user_donate
-- ----------------------------
-- ----------------------------
-- Table structure for zxy_user_info
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user_info`;
CREATE TABLE `zxy_user_info` (
`uid` varchar(200) NOT NULL COMMENT '用户id',
`nickname` varchar(80) DEFAULT NULL COMMENT '用户昵称',
`realname` varchar(80) DEFAULT NULL COMMENT '真实姓名',
`qq` varchar(20) DEFAULT NULL COMMENT 'QQ',
`wechat` varchar(200) DEFAULT NULL COMMENT 'WeChat',
`email` varchar(500) DEFAULT NULL COMMENT '邮箱',
`phone` varchar(20) DEFAULT NULL COMMENT '手机',
`work` varchar(200) DEFAULT NULL COMMENT '工作',
`address` varchar(500) DEFAULT NULL COMMENT '地址',
`hobby` varchar(500) DEFAULT NULL COMMENT '爱好',
`intro` varchar(2000) DEFAULT NULL COMMENT '自我介绍'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of ks_user_info
-- ----------------------------
INSERT INTO `zxy_user_info` VALUES ('a2ff39a3a7944181a4d3e5bc05ae7c64', '小钟', '钟兴宇', '3208703659', '17728021074', '[email protected]', '17728021074', '程序员', '广州', '打球', '');
INSERT INTO `zxy_user_info` VALUES ('3eba03a0de3842d3921ec4df7948f38c', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('04624db4faa74bdf9b1f728a51ff045a', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('f4941f85aae24d2dbb4e3cea3c5db323', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('792f0067471f4da683370288a32e8165', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('f5005d60326c45f7b31046fa3c1f1753', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('aee71a1ddc86453db0c8d500741b8db9', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('e8c38b7a4c31497b9d98119e0ea62bec', null, null, null, null, null, null, null, null, null, null);
INSERT INTO `zxy_user_info` VALUES ('fe765316b02741d096d6c7809ce1cbd9', null, null, null, null, null, null, null, null, null, null);
-- ----------------------------
-- Table structure for zxy_user_role
-- ----------------------------
DROP TABLE IF EXISTS `zxy_user_role`;
CREATE TABLE `zxy_user_role` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '角色编号',
`name` varchar(200) NOT NULL COMMENT '角色名称',
`description` varchar(500) NOT NULL DEFAULT '无描述...' COMMENT '角色描述',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of zxy_user_role
-- ----------------------------
INSERT INTO `zxy_user_role` VALUES ('2', '17728021074', '无描述...', '2020-09-22 16:01:23');
项目依赖解析

项目依赖主要分为三类:
- springboot 全家桶依赖:spring-boot-starter-web(web项目依赖),spring-boot-devtools(热部署依赖),spring-boot-starter-security(权限安全依赖),spring-boot-configuration-processor(传统的xml或properties配置依赖)
- 数据crub依赖:fastjson(json格式依赖),joda-time(时间格式依赖),springfox-swagger2(数据接口文档依赖),springfox-swagger-ui(数据接口文档依赖),mybatis-plus-boot-starter(数据库操作依赖),mysql-connector-java(数据库mysql依赖),lombok(pojo类偷懒神器)
- 前端模板引擎依赖:velocity-engine-core前端模板引擎),spring-boot-starter-thymeleaf(前端模板引擎),thymeleaf-extras-springsecurity5(thymeleaf权限安全依赖)
打包插件,过滤配置
<build>
<resources>
<resource>
<directory>src/main/javadirectory>
<includes>
<include>**/*.xmlinclude>
includes>
<filtering>truefiltering>
resource>
<resource>
<directory>src/main/resourcesdirectory>
<includes>
<include>*.propertiesinclude>
<include>static/**include>
<include>templates/**include>
includes>
<filtering>falsefiltering>
resource>
resources>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
全部依赖xml
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-securityartifactId>
dependency>
<dependency>
<groupId>org.thymeleaf.extrasgroupId>
<artifactId>thymeleaf-extras-springsecurity5artifactId>
<version>3.0.4.RELEASEversion>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.68version>
dependency>
<dependency>
<groupId>joda-timegroupId>
<artifactId>joda-timeartifactId>
<version>2.10.1version>
dependency>
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger2artifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger-uiartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.apache.velocitygroupId>
<artifactId>velocity-engine-coreartifactId>
<version>2.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
dependencies>
项目properties代码解析
properties有三个分别为:
- application.properties:总控制properties,主要用于本项目使用application-dev.properties还是application-prod.properties
spring.profiles.active=dev
- application-dev.properties:开发环境,使用开发环境数据源,开启接口文档
server.port=8080
spring.favicon.enabled = false
# 关闭缓存
spring.thymeleaf.cache=false
# swagger
swagger.enable=true
# 数据库连接
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/watermelonstudy?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
# mybatis日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.mapper-locations=classpath*:com/zxy/mapper/xml/*.xml
mybatis-plus.type-aliases-package=com.zxy.pojo
- application-prod.properties::生产环境,使用生产环境数据源,不开启接口文档
server.port=8080
# 开启缓存
spring.thymeleaf.cache=true
# swagger
swagger.enable=false
# 服务器数据库连接
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/watermelonstudy?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
# mybatis日志
# mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.mapper-locations=classpath*:com/zxy/mapper/xml/*.xml
mybatis-plus.type-aliases-package=com.zxy.pojo
项目前端资源文件
百度网盘:https://pan.baidu.com/s/107uzxZQ-BLoNBhAyEZs2BA 提取码:0qck

将下载好的前端资源文件替换掉项目中的resources文件
到此为止项目所有需要加载的资源都已完成,接下来就是使用springboot进行开发!
项目环境测试
先将test文件夹删掉
在controller文件夹下,创建一个helloController类进行测试
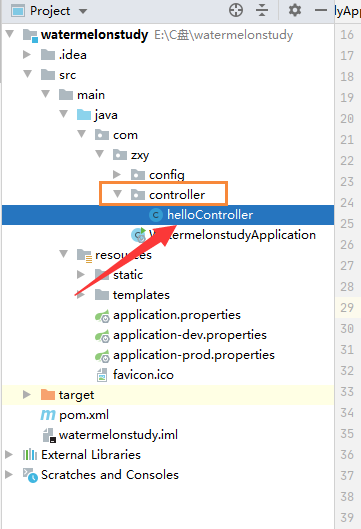
package com.zxy.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class helloController {
@RequestMapping({"/","/index"})
public String hello(){
return "/index";
}
}
启动springboot,在浏览器中输入localhost:8080/我们会看到进入localhost:8080/login页面
这是因为我们在项目依赖中添加了spring-security,其会自动拦截我们所有跳转的页面,所以我们需要对spring-security进行配置
在config文件夹下,创建一个SecurityConfig 类
package com.zxy.config;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
//请求授权验证
@Override
protected void configure(HttpSecurity http) throws Exception {
// .denyAll(); //拒绝访问
// .authenticated(); //需认证通过
// .permitAll(); //无条件允许访问
// 访问权限
http.authorizeRequests()
.antMatchers("/","/index","/register","/login","/toLogin").permitAll()// "/","/index","/register","/login","/toLogin"对这些网页进行无条件允许访问
.antMatchers("/*").permitAll() //对所有网页进行无条件允许访问
// .antMatchers("/*")authenticated();// 将其它页面进行需认证通过方可访问
}
配置完config后重启springboot,在浏览器中访问http://localhost:8080/index,可以看到index页面
出现index就说明我们环境测试成功!
项目数据库配置
我们采用mybatis-plus进行代码自动生成
在generator文件夹下,创建一个CodeGenerator类
package com.zxy.generator;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
public class CodeGenerator {
public static void main(String[] args) {
// 1、创建代码生成器
AutoGenerator mpg = new AutoGenerator();
// 2、全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath + "/src/main/java");
gc.setAuthor("zxy");
gc.setOpen(false); //生成后是否打开资源管理器
gc.setFileOverride(false); //重新生成时文件是否覆盖
gc.setServiceName("%sService"); //去掉Service接口的首字母I
gc.setIdType(IdType.ID_WORKER_STR); //主键策略
gc.setDateType(DateType.ONLY_DATE);//定义生成的实体类中日期类型
gc.setSwagger2(true);//开启Swagger2模式
mpg.setGlobalConfig(gc);
// 3、数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/watermelonstudy?useUnicode=true&characterEncoding=utf-8&useSSL=false");
dsc.setDriverName("com.mysql.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("123456");
dsc.setDbType(DbType.MYSQL);
mpg.setDataSource(dsc);
// 4、包配置
PackageConfig pc = new PackageConfig();
pc.setModuleName("zxy");
pc.setParent("com");
pc.setController("controller");
pc.setEntity("pojo");
pc.setService("service");
pc.setMapper("mapper");
mpg.setPackageInfo(pc);
// 5、策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setInclude("zxy_\\w*");//设置要映射的表名
//strategy.setInclude("zxy_download");//设置要映射的表名
strategy.setNaming(NamingStrategy.underline_to_camel);//数据库表映射到实体的命名策略
strategy.setTablePrefix("zxy_");//设置表前缀不生成
strategy.setColumnNaming(NamingStrategy.underline_to_camel);//数据库表字段映射到实体的命名策略
strategy.setEntityLombokModel(true); // lombok 模型 @Accessors(chain = true) setter链式操作
strategy.setRestControllerStyle(true); //restful api风格控制器
strategy.setControllerMappingHyphenStyle(true); //url中驼峰转连字符
mpg.setStrategy(strategy);
// 6、执行
mpg.execute();
}
}
//在WatermelonstudyApplication上加入@MapperScan("com.zxy.mapper")
package com.zxy;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.zxy.mapper")
public class WatermelonstudyApplication {
public static void main(String[] args) {
SpringApplication.run(WatermelonstudyApplication.class, args);
}
}
允许CodeGenerator类,我们可以看到mybatis-plus的代码生成器给我们生成了controller,pojo,mapper等等
项目接口文档配置
在config文件夹下,创建一个Swagger2Config类
package com.zxy.config;
import com.google.common.base.Predicates;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
// localhost:8080/swagger-ui.html
@Configuration
@EnableSwagger2
public class Swagger2Config {
@Value("${swagger.enable}")
private Boolean enable;
@Bean
public Docket webApiConfig(){
return new Docket(DocumentationType.SWAGGER_2)
.groupName("watermelonStudy-Api")
.apiInfo(webApiInfo())
.enable(enable) // 是否显示
.select()
.paths(Predicates.not(PathSelectors.regex("/error.*")))
.build();
}
private ApiInfo webApiInfo(){
return new ApiInfoBuilder()
.title("watermelonStudy-Api")
.description("watermelonStudy-Api")
.version("1.0")
.contact(new Contact("zxy", "http://localhost:8080/", "[email protected]"))
.build();
}
}
重启springboot,在浏览器访问localhost:8080/swagger-ui.html

我们可以看到接口文档自动生成好了
项目注册业务开发
在controller文件夹下,将helloController类改名为LoginController类
package com.zxy.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class LoginController {
@GetMapping({"/","/index"})
public String hello(){
return "/index";
}
@GetMapping("/toLogin")
public String toLogin(){
return "login";
}
@GetMapping("/register")
public String toRegister(){
return "register";
}
}
构建注册方法
创建vo和utils文件夹,在vo文件夹下创建RegisterForm类
package com.zxy.vo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class RegisterForm {
@ApiModelProperty(value = "用户名")
private String username;
@ApiModelProperty(value = "密码")
private String password;
@ApiModelProperty(value = "确认密码")
private String repassword;
@ApiModelProperty(value = "邀请码")
private String code;
}
在zxyUtils类中添加一些常用方法
package com.zxy.utils;
import java.sql.Timestamp;
import java.util.Date;
import java.util.UUID;
public class zxyUtils {
public static String getUuid(){
return UUID.randomUUID().toString().replaceAll("-","");
}
public static Timestamp getTime(){
return new Timestamp(new Date().getTime());
}
static boolean printFlag = true;
public static void print(String msg){
if (printFlag){
System.out.println("zxy:=>"+msg);
}
}
}
回到LoginController类中编写注册代码
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.zxy.pojo.Invite;
import com.zxy.pojo.User;
import com.zxy.pojo.UserInfo;
import com.zxy.service.InviteService;
import com.zxy.service.UserInfoService;
import com.zxy.service.UserService;
import com.zxy.utils.zxyUtils;
import com.zxy.vo.RegisterForm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
@Controller
public class LoginController {
@Autowired
InviteService inviteService;
@Autowired
UserService userService;
@Autowired
UserInfoService userInfoService;
@GetMapping({"/","/index"})
public String index(){
return "index";
}
@GetMapping("/toLogin")
public String toLogin(){
return "login";
}
@GetMapping("/register")
public String toRegister(){
return "register";
}
// 注册业务
@PostMapping("/register")
public String register(RegisterForm registerForm, Model model){
zxyUtils.print("注册表单信息:"+registerForm.toString());
// 表单密码重复判断
if (!registerForm.getPassword().equals(registerForm.getRepassword())){
model.addAttribute("registerMsg","密码输入有误");
return "register";
}
// 用户名已存在
User hasUser = userService.getOne(new QueryWrapper<User>().eq("username", registerForm.getUsername()));
if (hasUser!=null){
model.addAttribute("registerMsg","用户名已存在");
return "register";
}
// 验证邀请码
Invite invite = inviteService.getOne(new QueryWrapper<Invite>().eq("code", registerForm.getCode()));
if (invite==null){
model.addAttribute("registerMsg","邀请码不存在");
return "register";
}else {
// 邀请码存在,判断邀请码是否有效
if (invite.getStatus()==1){
model.addAttribute("registerMsg","邀请码已被使用");
return "register";
}else {
// 构建用户对象
User user = new User();
user.setUid(zxyUtils.getUuid()); // 用户唯一id
user.setRoleId(2);
user.setUsername(registerForm.getUsername());
// 密码加密
String bCryptPassword = new BCryptPasswordEncoder().encode(registerForm.getPassword());
user.setPassword(bCryptPassword);
user.setGmtCreate(zxyUtils.getTime());
user.setLoginDate(zxyUtils.getTime());
// 保存对象!
userService.save(user);
zxyUtils.print("新用户注册成功:"+user);
// 激活邀请码
invite.setActiveTime(zxyUtils.getTime());
invite.setStatus(1);
invite.setUid(user.getUid());
inviteService.updateById(invite);
// todo: 用户信息
userInfoService.save(new UserInfo().setUid(user.getUid()));
// 注册成功,重定向到登录页面
return "redirect:/toLogin";
}
}
}
}
项目登陆权限开发
在service文件夹下的impl文件夹下的UserServiceImpl类中进行登陆配置
package com.zxy.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.zxy.pojo.User;
import com.zxy.mapper.UserMapper;
import com.zxy.pojo.UserRole;
import com.zxy.service.UserRoleService;
import com.zxy.service.UserService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.stereotype.Service;
import javax.servlet.http.HttpSession;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
*
* 服务实现类
*
*
* @author zxy
* @since 2020-09-27
*/
// UserDetailsService接口用于返回用户相关数据。
// 它有loadUserByUsername()方法,根据username查询用户实体,可以实现该接口覆盖该方法,实现自定义获取用户过程。
// 该接口实现类被DaoAuthenticationProvider 类使用,用于认证过程中载入用户信息。
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService, UserDetailsService {
@Autowired
UserService userService;
@Autowired
UserRoleService roleService;
@Autowired
HttpSession session;
// 用户登录逻辑和验证处理
@Override
public UserDetails loadUserByUsername(String s) throws UsernameNotFoundException {
// 通过用户名查询用户
User user = userService.getOne(new QueryWrapper<User>().eq("username", s));
// 放入session
session.setAttribute("loginUser",user);
//创建一个新的UserDetails对象,最后验证登陆的需要
UserDetails userDetails=null;
if(user!=null){
//System.out.println("未加密:"+user.getPassword());
//String BCryptPassword = new BCryptPasswordEncoder().encode(user.getPassword());
// 登录后会将登录密码进行加密,然后比对数据库中的密码,数据库密码需要加密存储!
String password = user.getPassword();
//创建一个集合来存放权限
Collection<GrantedAuthority> authorities = getAuthorities(user);
//实例化UserDetails对象
userDetails=new org.springframework.security.core.userdetails.User(s,password,
true,
true,
true,
true, authorities);
}
return userDetails;
}
// 获取角色信息
private Collection<GrantedAuthority> getAuthorities(User user){
List<GrantedAuthority> authList = new ArrayList<GrantedAuthority>();
UserRole role = roleService.getById(user.getRoleId());
//注意:这里每个权限前面都要加ROLE_。否在最后验证不会通过
authList.add(new SimpleGrantedAuthority("ROLE_"+role.getName()));
return authList;
}
}
在config中的SecurityConfig添加权限设置
package com.zxy.config;
import com.zxy.service.impl.UserServiceImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
UserServiceImpl userService;
//请求授权验证
@Override
protected void configure(HttpSecurity http) throws Exception {
// .denyAll(); //拒绝访问
// .authenticated(); //需认证通过
// .permitAll(); //无条件允许访问
// 访问权限
http.authorizeRequests()
.antMatchers("/","/index").permitAll()
.antMatchers("/register","/login","/toLogin").permitAll()
.antMatchers("/*").authenticated();
// 登录配置
http.formLogin()
.usernameParameter("username")
.passwordParameter("password")
.loginPage("/toLogin")
.loginProcessingUrl("/login") // 登陆表单提交请求
.defaultSuccessUrl("/index"); // 设置默认登录成功后跳转的页面
// 注销配置
http.headers().contentTypeOptions().disable();
http.headers().frameOptions().disable(); // 图片跨域
http.csrf().disable();//关闭csrf功能:跨站请求伪造,默认只能通过post方式提交logout请求
http.logout().logoutSuccessUrl("/");
// 记住我配置
http.rememberMe().rememberMeParameter("remember");
}
// 用户授权验证
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.userDetailsService(userService)
.passwordEncoder(passwordEncoder());
}
// 密码加密方式
@Bean
public PasswordEncoder passwordEncoder(){
return new BCryptPasswordEncoder();
}
}
项目用户中心开发
先设置userinfo中找到uid将其设置为input
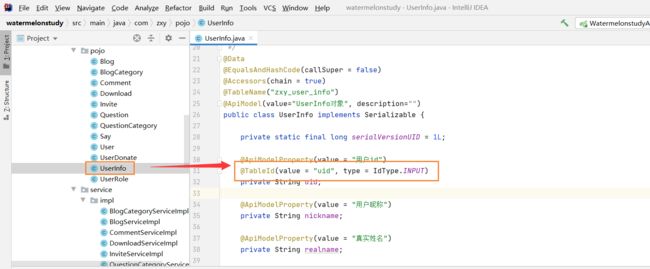
在vo文件夹中添加LayerPhoto和LayerPhotoData类
LayerPhoto类
package com.zxy.vo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
import java.util.List;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class LayerPhoto {
@ApiModelProperty(value = "相册标题")
private String title;
@ApiModelProperty(value = "相册id")
private int id;
@ApiModelProperty(value = "初始显示的图片序号,默认0")
private int start;
@ApiModelProperty(value = "相册包含的图片,数组格式")
private List<LayerPhotoData> data;
}
LayerPhotoData类
package com.zxy.vo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class LayerPhotoData {
@ApiModelProperty(value = "图片名")
private String alt;
@ApiModelProperty(value = "图片id")
private int pid;
@ApiModelProperty(value = "原图地址")
private String src;
@ApiModelProperty(value = "缩略图地址")
private String thumb;
}
在controller中的UserController类进行开发用户中心功能
package com.zxy.controller;
import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Blog;
import com.zxy.pojo.Comment;
import com.zxy.pojo.Question;
import com.zxy.pojo.UserInfo;
import com.zxy.service.BlogService;
import com.zxy.service.CommentService;
import com.zxy.service.QuestionService;
import com.zxy.service.UserInfoService;
import com.zxy.utils.zxyUtils;
import com.zxy.vo.LayerPhoto;
import com.zxy.vo.LayerPhotoData;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class UserController {
@Autowired
UserInfoService userInfoService;
@Autowired
BlogService blogService;
@Autowired
QuestionService questionService;
@Autowired
CommentService commentService;
@GetMapping("/user/{uid}")
public String userIndex(@PathVariable String uid, Model model){
// 用户信息回填
userInfoCallBack(uid,model);
// 用户的博客列表
Page<Blog> pageParam = new Page<>(1, 10);
blogService.page(pageParam,new QueryWrapper<Blog>().eq("author_id", uid)
.orderByDesc("gmt_create"));
// 结果
List<Blog> blogList = pageParam.getRecords();
model.addAttribute("blogList",blogList);
model.addAttribute("pageParam",pageParam);
return "user/index";
}
@GetMapping("/user/blog/{uid}/{page}/{limit}")
public String userIndexBlog(@PathVariable String uid,
@PathVariable int page,
@PathVariable int limit,
Model model){
// 用户信息回填
userInfoCallBack(uid,model);
// 用户的博客列表
if (page < 1){
page = 1;
}
Page<Blog> pageParam = new Page<>(page, limit);
blogService.page(pageParam,new QueryWrapper<Blog>().eq("author_id", uid)
.orderByDesc("gmt_create"));
// 结果
List<Blog> blogList = pageParam.getRecords();
model.addAttribute("blogList",blogList);
model.addAttribute("pageParam",pageParam);
return "user/index";
}
@GetMapping("/user/question/{uid}/{page}/{limit}")
public String userIndexQuestion(@PathVariable String uid,
@PathVariable int page,
@PathVariable int limit,
Model model){
// 用户信息回填
userInfoCallBack(uid,model);
//
if (page < 1){
page = 1;
}
Page<Question> pageParam = new Page<>(page, limit);
questionService.page(pageParam,new QueryWrapper<Question>().eq("author_id", uid)
.orderByDesc("gmt_create"));
// 结果
List<Question> blogList = pageParam.getRecords();
model.addAttribute("questionList",blogList);
model.addAttribute("pageParam",pageParam);
return "user/user-question";
}
@GetMapping("/user/comment/{uid}/{page}/{limit}")
public String userIndexComment(@PathVariable String uid,
@PathVariable int page,
@PathVariable int limit,
Model model){
// 用户信息回填
userInfoCallBack(uid,model);
//
if (page < 1){
page = 1;
}
Page<Comment> pageParam = new Page<>(page, limit);
commentService.page(pageParam,new QueryWrapper<Comment>().eq("user_id", uid)
.orderByDesc("gmt_create"));
// 结果
List<Comment> commentList = pageParam.getRecords();
model.addAttribute("commentList",commentList);
model.addAttribute("pageParam",pageParam);
return "user/user-comment";
}
// 用户信息回填
private void userInfoCallBack(String uid,Model model){
UserInfo userInfo = userInfoService.getById(uid);
model.addAttribute("userInfo",userInfo);
if (userInfo.getHobby()!=null && !userInfo.getHobby().equals("")){
String[] hobbys = userInfo.getHobby().split(",");
model.addAttribute("infoHobbys",hobbys);
}
// 获取用户的问题,博客,回复数
int blogCount = blogService.count(new QueryWrapper<Blog>().eq("author_id", uid));
int questionCount = questionService.count(new QueryWrapper<Question>().eq("author_id", uid));
int commentCount = commentService.count(new QueryWrapper<Comment>().eq("user_id", uid));
model.addAttribute("blogCount",blogCount);
model.addAttribute("questionCount",questionCount);
model.addAttribute("commentCount",commentCount);
}
// 捐赠layer弹窗二维码
@GetMapping("/user/donate/{uid}")
@ResponseBody
public String userLayerDonate(@PathVariable String uid){
// todo: 数据库设计
ArrayList<LayerPhotoData> layerPhotos = new ArrayList<>();
layerPhotos.add(new LayerPhotoData().setAlt("支付宝").setPid(1).setSrc("/images/donate/alipay.png").setThumb(""));
layerPhotos.add(new LayerPhotoData().setAlt("微信").setPid(2).setSrc("/images/donate/wechat.jpg").setThumb(""));
LayerPhoto donate = new LayerPhoto().setTitle("赞赏").setId(666).setStart(1);
donate.setData(layerPhotos);
String donateJsonString = JSONObject.toJSONString(donate);
zxyUtils.print(donateJsonString);
return donateJsonString;
}
// 更新头像
@GetMapping("/user/update-avatar/{uid}")
public String toUpdateAvatar(@PathVariable String uid,Model model){
// 用户信息回填
userInfoCallBack(uid,model);
return "user/update-avatar";
}
}
mybatis-plus分页设置
在config中添加MybatisPlusConfig类
package com.zxy.config;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
//分页插件
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}
项目用户更新资料
在controller中的UserInfoController类中添加代码
@Controller
public class UserInfoController {
@Autowired
UserInfoService userInfoService;
@Autowired
BlogService blogService;
@Autowired
QuestionService questionService;
@Autowired
CommentService commentService;
// 更新用户资料
@GetMapping("/userinfo/setting/{uid}")
public String userSetting(@PathVariable String uid, Model model){
// 用户信息回填
userInfoCallBack(uid,model);
// todo: 可扩展
return "user/settings";
}
@PostMapping("/userinfo/update/{uid}")
public String userInfo(@PathVariable String uid,UserInfo userInfo){
// 获取用户信息;
userInfoService.updateById(userInfo);
return "redirect:/user/"+uid;
}
// 用户信息回填
private void userInfoCallBack(String uid,Model model){
UserInfo userInfo = userInfoService.getById(uid);
model.addAttribute("userInfo",userInfo);
if (userInfo.getHobby()!=null && !userInfo.getHobby().equals("")){
String[] hobbys = userInfo.getHobby().split(",");
model.addAttribute("infoHobbys",hobbys);
}
// 获取用户的问题,博客,回复数
int blogCount = blogService.count(new QueryWrapper<Blog>().eq("author_id", uid));
int questionCount = questionService.count(new QueryWrapper<Question>().eq("author_id", uid));
int commentCount = commentService.count(new QueryWrapper<Comment>().eq("user_id", uid));
model.addAttribute("blogCount",blogCount);
model.addAttribute("questionCount",questionCount);
model.addAttribute("commentCount",commentCount);
}
}
项目问答功能开发
百度网盘:https://pan.baidu.com/s/107uzxZQ-BLoNBhAyEZs2BA 提取码:0qck
下载upload文件放置在watermelon文件夹下
在config文件下添加MyMvcConfig类
package com.zxy.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/upload/**")
.addResourceLocations("file:"+System.getProperty("user.dir")+"/upload/");
}
}
在vo文件夹下添加QuestionWriteForm类
package com.zxy.vo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class QuestionWriteForm {
@ApiModelProperty(value = "问题标题")
private String title;
@ApiModelProperty(value = "问题内容")
private String content;
@ApiModelProperty(value = "问题分类id")
private Integer categoryId;
@ApiModelProperty(value = "作者id")
private String authorId;
@ApiModelProperty(value = "作者名称")
private String authorName;
@ApiModelProperty(value = "作者头像")
private String authorAvatar;
}
在controller文件夹下QuestionCategoryController类中添加
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Question;
import com.zxy.pojo.QuestionCategory;
import com.zxy.service.QuestionCategoryService;
import com.zxy.service.QuestionService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class QuestionCategoryController {
@Autowired
QuestionCategoryService questionCategoryService;
@Autowired
QuestionService questionService;
@GetMapping("/question/category/{cid}/{page}/{limit}")
public String questionPage(
@PathVariable int cid,
@PathVariable int page,
@PathVariable int limit,
Model model){
if (page < 1){
page = 1;
}
// 查询这个分类下的所有问题,获取查询的数据信息
Page<Question> pageParam = new Page<>(page, limit);
questionService.page(pageParam,new QueryWrapper<Question>()
.eq("category_id",cid).orderByDesc("gmt_create"));
List<Question> records = pageParam.getRecords();
model.addAttribute("questionList",records);
model.addAttribute("pageParam",pageParam);
// 查询这个分类信息
QuestionCategory category = questionCategoryService.getById(cid);
model.addAttribute("thisCategoryName",category.getCategory());
// 全部分类信息
List<QuestionCategory> categoryList = questionCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "question/list";
}
}
在controller文件夹下的QuestionController类中添加
package com.zxy.controller;
import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Comment;
import com.zxy.pojo.Question;
import com.zxy.pojo.QuestionCategory;
import com.zxy.service.CommentService;
import com.zxy.service.QuestionCategoryService;
import com.zxy.service.QuestionService;
import com.zxy.utils.zxyUtils;
import com.zxy.vo.QuestionWriteForm;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.http.HttpServletRequest;
import java.io.File;
import java.io.IOException;
import java.util.Calendar;
import java.util.List;
import java.util.UUID;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class QuestionController {
@Autowired
QuestionCategoryService questionCategoryService;
@Autowired
QuestionService questionService;
@Autowired
CommentService commentService;
// 问题列表展示
@GetMapping("/question")
public String questionList(Model model){
Page<Question> pageParam = new Page<>(1, 10);
questionService.page(pageParam,new QueryWrapper<Question>().orderByDesc("gmt_create"));
// 结果
List<Question> questionList = pageParam.getRecords();
model.addAttribute("questionList",questionList);
model.addAttribute("pageParam",pageParam);
// 分类信息
List<QuestionCategory> categoryList = questionCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "question/list";
}
@GetMapping("/question/{page}/{limit}")
public String questionListPage(
@PathVariable int page,
@PathVariable int limit,
Model model){
if (page < 1){
page = 1;
}
Page<Question> pageParam = new Page<>(page, limit);
questionService.page(pageParam,new QueryWrapper<Question>().orderByDesc("gmt_create"));
// 结果
List<Question> questionList = pageParam.getRecords();
model.addAttribute("questionList",questionList);
model.addAttribute("pageParam",pageParam);
// 分类信息
List<QuestionCategory> categoryList = questionCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "question/list";
}
// 发布问题
@GetMapping("/question/write")
public String toWrite(Model model){
List<QuestionCategory> categoryList = questionCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "question/write";
}
@PostMapping("/question/write")
public synchronized String write(QuestionWriteForm questionWriteForm){
// 构建问题对象
Question question = new Question();
question.setQid(zxyUtils.getUuid());
question.setTitle(questionWriteForm.getTitle());
question.setContent(questionWriteForm.getContent());
question.setStatus(0);
question.setSort(0);
question.setViews(0);
question.setAuthorId(questionWriteForm.getAuthorId());
question.setAuthorName(questionWriteForm.getAuthorName());
question.setAuthorAvatar(questionWriteForm.getAuthorAvatar());
QuestionCategory category = questionCategoryService.getById(questionWriteForm.getCategoryId());
question.setCategoryId(questionWriteForm.getCategoryId());
question.setCategoryName(category.getCategory());
question.setGmtCreate(zxyUtils.getTime());
question.setGmtUpdate(zxyUtils.getTime());
// 存储对象
questionService.save(question);
// 重定向到列表页面
return "redirect:/question";
}
// 阅读问题
@GetMapping("/question/read/{qid}")
public String read(@PathVariable("qid") String qid,Model model){
Question question = questionService.getOne(new QueryWrapper<Question>().eq("qid", qid));
// todo: redis缓存. 防止阅读重复
question.setViews(question.getViews()+1);
questionService.updateById(question);
model.addAttribute("question",question);
// todo: 查询评论.
List<Comment> commentList = commentService.list(new QueryWrapper<Comment>().eq("topic_id", qid).orderByDesc("gmt_create"));
model.addAttribute("commentList",commentList);
return "question/read";
}
// 评论
@PostMapping("/question/comment/{qid}")
public String comment(@PathVariable("qid") String qid, Comment comment){
// 存储评论
comment.setCommentId(zxyUtils.getUuid());
comment.setTopicCategory(2);
comment.setGmtCreate(zxyUtils.getTime());
commentService.save(comment);
// 状态改为已解决
Question question = questionService.getOne(new QueryWrapper<Question>().eq("qid", qid));
question.setStatus(1);
questionService.updateById(question);
// 重定向到列表页面
return "redirect:/question/read/"+qid;
}
// 编辑问题
@GetMapping("/question/editor/{uid}/{qid}")
public synchronized String toEditor(@PathVariable("uid") String uid,
@PathVariable("qid") String qid,Model model){
Question question = questionService.getOne(new QueryWrapper<Question>().eq("qid", qid));
if (!question.getAuthorId().equals(uid)){
zxyUtils.print("禁止非法编辑");
return "redirect:/question";
}
model.addAttribute("question",question);
List<QuestionCategory> categoryList = questionCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "question/editor";
}
@PostMapping("/question/editor")
public String editor(Question question){
Question queryQuestion = questionService.getOne(new QueryWrapper<Question>().eq("qid", question.getQid()));
queryQuestion.setTitle(question.getTitle());
queryQuestion.setCategoryId(question.getCategoryId());
queryQuestion.setContent(question.getContent());
queryQuestion.setGmtUpdate(zxyUtils.getTime());
questionService.updateById(queryQuestion);
return "redirect:/question/read/"+question.getQid();
}
// 删除问题
@GetMapping("/question/delete/{uid}/{qid}")
public String delete(@PathVariable("uid") String uid,
@PathVariable("qid") String qid){
Question question = questionService.getOne(new QueryWrapper<Question>().eq("qid", qid));
if (!question.getAuthorId().equals(uid)){
zxyUtils.print("禁止非法删除");
return "redirect:/question";
}
questionService.removeById(question);
// 重定向到列表页面
return "redirect:/question";
}
// md 文件上传
@ApiOperation(value = "md文件上传问题")
@RequestMapping("/question/write/file/upload")
@ResponseBody
public JSONObject fileUpload(@RequestParam(value = "editormd-image-file", required = true) MultipartFile file, HttpServletRequest request) throws IOException {
//获得SpringBoot当前项目的路径:System.getProperty("user.dir")
String path = System.getProperty("user.dir")+"/upload/";
//按照月份进行分类:
Calendar instance = Calendar.getInstance();
String month = (instance.get(Calendar.MONTH) + 1)+"月";
path = path+month;
File realPath = new File(path);
if (!realPath.exists()){
realPath.mkdir();
}
//上传文件地址
zxyUtils.print("上传文件保存地址:"+realPath);
//解决文件名字问题:我们使用uuid;
String filename = "ks-"+ UUID.randomUUID().toString().replaceAll("-", "");
String originalFilename = file.getOriginalFilename();
// KuangUtils.print(originalFilename);
assert originalFilename != null;
int i = originalFilename.lastIndexOf(".");
String suffix = originalFilename.substring(i + 1);
String outFilename = filename + "."+suffix;
zxyUtils.print("文件名:" + outFilename);
//通过CommonsMultipartFile的方法直接写文件(注意这个时候)
file.transferTo(new File(realPath +"/"+ outFilename));
//给editormd进行回调
JSONObject res = new JSONObject();
res.put("url","/upload/"+month+"/"+ outFilename);
res.put("success", 1);
res.put("message", "upload success!");
zxyUtils.print(res.toJSONString());
return res;
}
}
项目博客功能开发
在controller文件夹下的BlogCategoryController类中添加
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Blog;
import com.zxy.pojo.BlogCategory;
import com.zxy.service.BlogCategoryService;
import com.zxy.service.BlogService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class BlogCategoryController {
@Autowired
BlogCategoryService blogCategoryService;
@Autowired
BlogService blogService;
@GetMapping("/blog/category/{bid}/{page}/{limit}")
public String blogPage(
@PathVariable int bid,
@PathVariable int page,
@PathVariable int limit,
Model model){
if (page < 1){
page = 1;
}
// 查询这个分类下的所有问题,获取查询的数据信息
Page<Blog> pageParam = new Page<>(page, limit);
blogService.page(pageParam,new QueryWrapper<Blog>()
.eq("category_id",bid).orderByDesc("gmt_create"));
List<Blog> records = pageParam.getRecords();
model.addAttribute("blogList",records);
model.addAttribute("pageParam",pageParam);
// 查询这个分类信息
BlogCategory category = blogCategoryService.getById(bid);
model.addAttribute("thisCategoryName",category.getCategory());
// 全部分类信息
List<BlogCategory> categoryList = blogCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "blog/list";
}
}
在controller文件夹下的BlogController类中添加
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Blog;
import com.zxy.pojo.BlogCategory;
import com.zxy.pojo.Comment;
import com.zxy.service.BlogCategoryService;
import com.zxy.service.BlogService;
import com.zxy.service.CommentService;
import com.zxy.utils.zxyUtils;
import com.zxy.vo.QuestionWriteForm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class BlogController {
@Autowired
BlogCategoryService blogCategoryService;
@Autowired
BlogService blogService;
@Autowired
CommentService commentService;
// 列表展示
@GetMapping("/blog")
public String blogList(Model model){
Page<Blog> pageParam = new Page<>(1, 10);
blogService.page(pageParam,new QueryWrapper<Blog>().orderByDesc("views"));
// 结果
List<Blog> blogList = pageParam.getRecords();
model.addAttribute("blogList",blogList);
model.addAttribute("pageParam",pageParam);
// 分类信息
List<BlogCategory> categoryList = blogCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "blog/list";
}
@GetMapping("/blog/{page}/{limit}")
public String blogListPage(
@PathVariable int page,
@PathVariable int limit,
Model model){
if (page < 1){
page = 1;
}
Page<Blog> pageParam = new Page<>(page, limit);
blogService.page(pageParam,new QueryWrapper<Blog>().orderByDesc("views"));
// 结果
List<Blog> blogList = pageParam.getRecords();
model.addAttribute("blogList",blogList);
model.addAttribute("pageParam",pageParam);
// 分类信息
List<BlogCategory> categoryList = blogCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "blog/list";
}
// 写文章
@GetMapping("/blog/write")
public String toWrite(Model model){
List<BlogCategory> categoryList = blogCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "blog/write";
}
@PostMapping("/blog/write")
public synchronized String write(QuestionWriteForm questionWriteForm){
// 构建问题对象
Blog blog = new Blog();
blog.setBid(zxyUtils.getUuid());
blog.setTitle(questionWriteForm.getTitle());
blog.setContent(questionWriteForm.getContent());
blog.setSort(0);
blog.setViews(0);
blog.setAuthorId(questionWriteForm.getAuthorId());
blog.setAuthorName(questionWriteForm.getAuthorName());
blog.setAuthorAvatar(questionWriteForm.getAuthorAvatar());
BlogCategory category = blogCategoryService.getById(questionWriteForm.getCategoryId());
blog.setCategoryId(questionWriteForm.getCategoryId());
blog.setCategoryName(category.getCategory());
blog.setGmtCreate(zxyUtils.getTime());
blog.setGmtUpdate(zxyUtils.getTime());
// 存储对象
blogService.save(blog);
// 重定向到列表页面
return "redirect:/blog";
}
// 阅读文章
@GetMapping("/blog/read/{bid}")
public String read(@PathVariable("bid") String bid,Model model){
Blog blog = blogService.getOne(new QueryWrapper<Blog>().eq("bid", bid));
// todo: redis缓存. 防止阅读重复
blog.setViews(blog.getViews()+1);
blogService.updateById(blog);
model.addAttribute("blog",blog);
// todo: 查询评论
List<Comment> commentList = commentService.list(new QueryWrapper<Comment>().eq("topic_id", bid).orderByDesc("gmt_create"));
model.addAttribute("commentList",commentList);
return "blog/read";
}
// 编辑问题
@GetMapping("/blog/editor/{uid}/{bid}")
public synchronized String toEditor(@PathVariable("uid") String uid,
@PathVariable("bid") String bid,Model model){
Blog blog = blogService.getOne(new QueryWrapper<Blog>().eq("bid", bid));
if (!blog.getAuthorId().equals(uid)){
zxyUtils.print("禁止非法编辑");
return "redirect:/blog";
}
model.addAttribute("blog",blog);
List<BlogCategory> categoryList = blogCategoryService.list(null);
model.addAttribute("categoryList",categoryList);
return "blog/editor";
}
@PostMapping("/blog/editor")
public String editor(Blog blog){
Blog queryBlog = blogService.getOne(new QueryWrapper<Blog>().eq("bid", blog.getBid()));
queryBlog.setTitle(blog.getTitle());
queryBlog.setCategoryId(blog.getCategoryId());
queryBlog.setContent(blog.getContent());
queryBlog.setGmtUpdate(zxyUtils.getTime());
blogService.updateById(queryBlog);
return "redirect:/blog/read/"+blog.getBid();
}
// 删除问题
@GetMapping("/blog/delete/{uid}/{bid}")
public String delete(@PathVariable("uid") String uid,
@PathVariable("bid") String bid){
Blog blog = blogService.getOne(new QueryWrapper<Blog>().eq("bid", bid));
if (!blog.getAuthorId().equals(uid)){
zxyUtils.print("禁止非法删除");
return "redirect:/blog";
}
blogService.removeById(blog);
// 重定向到列表页面
return "redirect:/blog";
}
// 评论
@PostMapping("/blog/comment/{bid}")
public String comment(@PathVariable("bid") String bid, Comment comment){
// 存储评论
comment.setCommentId(zxyUtils.getUuid());
comment.setTopicCategory(1);
comment.setGmtCreate(zxyUtils.getTime());
commentService.save(comment);
// 重定向到列表页面
return "redirect:/blog/read/"+bid;
}
}
问答功能和博客功能的评论删除
在controller文件夹下的CommentController类中添加
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.zxy.pojo.Comment;
import com.zxy.service.CommentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class CommentController {
@Autowired
CommentService commentService;
// 删除评论
@GetMapping("/user/comment/delete/{uid}/{cid}")
public String deleteComment(@PathVariable String uid, @PathVariable String cid){
commentService.remove(new QueryWrapper<Comment>().eq("comment_id", cid));
return "redirect:/user/comment/"+uid+"/1/10";
}
}
项目资源功能开发
在pojo文件夹下的DownloadMapper中添加注释
package com.zxy.mapper;
import com.zxy.pojo.Download;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.springframework.stereotype.Repository;
/**
*
* Mapper 接口
*
*
* @author zxy
* @since 2020-09-27
*/
@Repository
public interface DownloadMapper extends BaseMapper<Download> {
}
在controller文件夹下的DownloadController类中添加
package com.zxy.controller;
import com.zxy.mapper.DownloadMapper;
import com.zxy.pojo.Download;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class DownloadController {
@Autowired
DownloadMapper downloadMapper;
@GetMapping({"/download"})
public String download(Model model){
List<Download> downloadList = downloadMapper.selectList(null);
model.addAttribute("downloadList",downloadList);
return "page/download";
}
}
项目公告功能开发
在controller文件夹下的SayController类中添加
package com.zxy.controller;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.zxy.pojo.Say;
import com.zxy.service.SayService;
import com.zxy.utils.zxyUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
*
* 前端控制器
*
*
* @author zxy
* @since 2020-09-27
*/
@Controller
public class SayController {
@Autowired
SayService sayService;
@GetMapping("/say")
public String userIndexBlog(Model model){
Page<Say> pageParam = new Page<>(1, 50);
sayService.page(pageParam,new QueryWrapper<Say>().orderByDesc("gmt_create"));
// 结果
List<Say> sayList = pageParam.getRecords();
model.addAttribute("sayList",sayList);
model.addAttribute("pageParam",pageParam);
return "page/say";
}
@PostMapping("/say/{role}")
public String saveSay(@PathVariable("role") int role, Say say){
// 防止请求提交
if (role!=1){
return "redirect:/say";
}
say.setId(zxyUtils.getUuid());
say.setGmtCreate(zxyUtils.getTime());
// 结果
sayService.save(say);
return "redirect:/say";
}
}
结尾
这个时候我们再来看这张流程图应该就有不错的理解了
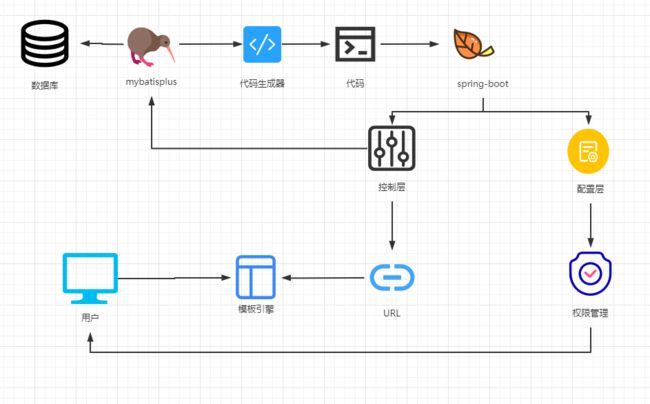
到此为止西瓜社区0.1.0版本的全代码解析就正式结束了,实现了基本的博客功能,至于为什么只构建怎么简单的功能就发布呢?
是因为我认为项目有三难:
- 从0-1难:一个项目从无到有需要思考很多的问题,从一开始的功能定位,到技术选型,数据库设计,再到开发等等。
- 从10-100难:当一个项目刚刚从襁褓中出来后,他又将面临一系列的生存问题,像高并发,网络延迟,负载均衡,缓存穿透等等,这个时候可能需要将部分高访问的功能拆分出来构建分布式来解决。
- 从100-无限难:项目勉勉强强生存下来后,我们又希望将他越做越大,这时我们需要面对用户体验优化,底层架构拆分,重新构建数据层,用架构的思维将项目中一个个功能拔出来重新整合,我们可能会面临当前开源项目无法满足需求的情况,这就需要我们去从开源项目源码中优化或者重构等等。
西瓜社区0.1.0版本就是基于从0-1进行开发的,具有高度的可扩展性,后续的功能可以直接插入,当然我认为万物启于源,如果到从10-100在发布的话可能需要理解的东西就太多了!完结,撒花~~~~