多模态检索论文总结
1.年份梯度:
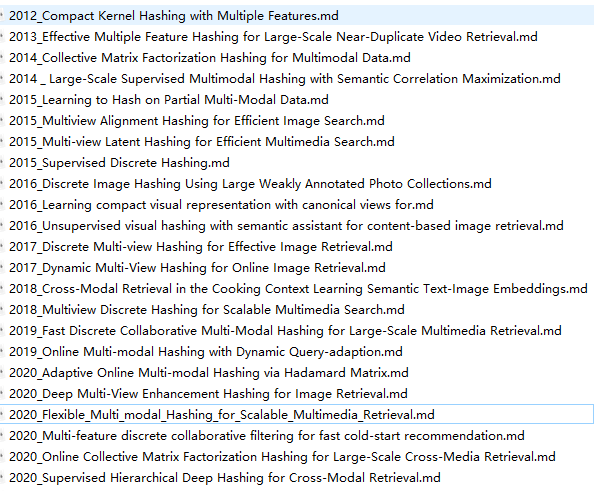
2.从模态定义来看
目标:研究多模态哈希检索。
上述文章其实本质上单模态哈希,跨模态哈希和多模态哈希都有包括。但是我们可以通过窥探他们各自的思想来看看是否对我们多模态的研究提供思路
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TgnUazXC-1636104175271)(C:\Users\winter\AppData\Roaming\Typora\typora-user-images\image-20210905231230309.png)]
上述文章中属于单模态哈希的有3篇:
**2012 Compact Kernel Hashing with Multiple Features **引用:45
**2013 Effective Multiple Feature Hashing for Large-Scale Near-Duplicate Video Retrieval ** 引用:225
离线的第一阶段,作者使用所提出的算法学习一系列哈希函数,每个哈希函数根据给定的多个特征为一个关键帧(特征)生成一位哈希码。使用派生的散列函数,数据集视频的每个关键帧可以由线性时间内生成的大小为的散列码表示。
在联机的第二阶段中,查询视频的关键帧也由哈希函数映射的大小哈希码表示。通过对散列码进行有效的异或运算和比特计数运算来计算两个视频之间的相似性。
2020 Deep Multi-View Enhancement Hashing for Image Retrieval 引用:125
计算稳定性评估那一块不是很懂?
是 state-of-the-art single-view and multi-view hashing methods。引用量颇高。
单模态哈希方法思路借鉴和思考:
和很多经典图像单模态哈希类似:
单模态哈希方法是专门为单模态数据设计的。不管是图片还是视频,重点在提取单模态特征(近些年sota文章利用数据的低级分布语义和高级提取语义相结合),然后利用单一模态特征去学习相似性以完成检索任务。如果要支持多媒体搜索,需要先将多模态特征连接到一个特征向量中(文本对齐势必会产生较差性能),然后再导入到单模态哈希模型中。在这种情况下,不同模态特征之间的互补语义关联,以及模态间的冗余要好好考虑(多视图角度符合这个想法)。
上述文章中属于跨模态哈希的有5篇:
2016 Discrete Image Hashing Using Large Weakly Annotated Photo Collections引用:20
用户生成的图像注释通常有噪声且不完整。传统监管和协同监管之间的主要区别在于后者不认为未观察到的标签是负面的。这对于弱标记数据集的训练至关重要。
协同过滤(CF)用于分析图像和标签之间弱而丰富的关联,然后预测新的(未观察到的)图像标签关联(见图1(b))。关键的动机是CF可以通过有效的稀疏矩阵分解优雅地避免建模丢失注释的大部分,并且CF自然支持多标签训练图像。(详见论文)
2016 Unsupervised visual hashing with semantic assistant for content-based image retrieval.
利用辅助文本,通过无监督学习提高视觉哈希的质量
核心思想是自动从带有噪声的关联文本中提取语义,以增强哈希码的识别能力,希望得到的结果图如下图中的d。
不只是考虑视觉特征,也不平等地对待图像和文本,而是特别利用辅助文本来辅助视觉哈希。利用主题超图对图像进行语义关联建模,利用集合矩阵分解对图像和潜在共享主题进行关联 。
但是构造图会增加计算和存储的复杂性
2020 Supervised Hierarchical Deep Hashing for Cross-Modal Retrieval 引用:6
通过显式地挖掘分层标签来学习散列码。具体地说,标签层次结构的每一层的相似性和不同层之间的关联性都被植入到哈希码学习中。此外,还提出了一种迭代优化算法来直接学习离散哈希码,而不是放松二进制约束。
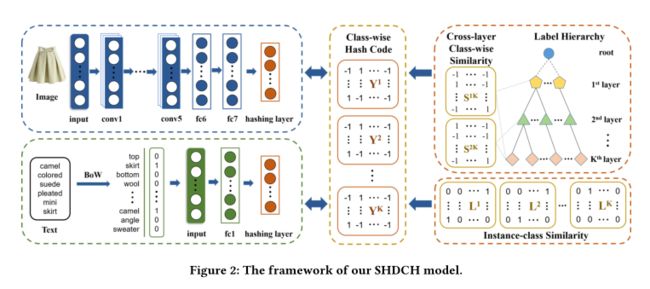
总体框架如图2所示。包括两个主要组件:特征学习和哈希码学习。在特征学习部分,采用CNN网络和MLP网络来获取图像和文本模式的强大语义特征。对于散列码学习,有各层实例类相似性的定义以及跨层类相似性的定义。然后,通过将它们嵌入到目标函数中,进一步得到中间产物:class-wise哈希码。最后,实例的哈希代码可以在中间产品的帮助下生成,同时保留定义的相似性。
2018 Cross-Modal Retrieval in the Cooking Context Learning Semantic Text-lmage Embeddings** 引用103
个人总结:
(1)挖掘潜在空间,制定了一个具有跨模态检索和分类损失的联合目标函数来构造潜在空间。在表征学习过程中直接注入基于类的证据源更有效地将高层次结构强加给潜在空间。
(2)改进损失达到提升细粒度和更完善高级语义信息的作用。
**2020 Online Collective Matrix Factorization Hashing for Large-Scale Cross-Media Retrieval **引用8
在集合矩阵分解散列(CMFH)的基础上提出了在线集合矩阵分解散列(OCMFH),可以根据散列模型的动态变化自适应地更新旧数据的散列码,而无需访问旧数据
理论性较强
#### 跨模态哈希方法思路借鉴和思考:
因为哈希最后是二进制码,各种跨模态哈希方法的核心思想是挖掘不同模态之间共享的汉明空间,从而实现不同模态之间的搜索过程。但是图片信息语义更高阶,在处理时,如果和文本同等处理,就很可能让图片丢失语义,也就是可用的汉明语义空间会变小(如下图),所以感觉现在都是在使用文本和图像时,使用一些图结构非同等对待图像和文本,或者直接用深度学习,而且很多之前看的跨模态文章,训练时采样方式是获取训练集中相似或者不相似的子集对或者子集组合(二元组和三元组)。如果是这样做,一个大规模数据不好处理,另一个是图片与图片之间不单纯是相似或者不相似,高阶语义是复杂的,这有语义的模糊和损失。

结合之前看的一些文章,我觉得
创新点集中在:
1.利用一些新的结构和技巧(如图分析,语义聚集分析,矩阵分解理论等)设计一个更好的共有语义空间(细粒度增加,共同语义空间的表征加强等)
2.,离散哈希优化,缓解松弛带来的量化损失
狭义跨模态是单模态去查询,我们是要实现 配合弱监督情景下的多模态哈希,在查询阶段就提供了多模态特性,应该注重模态之间语义融合进入模型后 语义的缺失和冗余,所以跨模态模型用来做多模态应该不是很合适。降低量化损失的手段可以参考,降低模型计算复杂度的手段也可以参考,但是感觉数学理论性较强。
上述文章中属于多视角多模态哈希的有篇:
2015 Multiview Alignment Hashing for Efficient Image Search 引用:139
为了进行比单视角更全面的描述,对象总是通过几种不同类型的特征来表示,并且每种特征都有自己特点。因此,希望将这些异构特征描述合并到学习散列函数中,从而实现多视图多视角学习。
通过非负矩阵分解(NMF)利用了有区分度的低维嵌入。NMF是数据挖掘任务(包括聚类、协同过滤、异常值检测等)中的一种流行方法。与其他具有正负值的嵌入方法不同,NMF寻求学习基于非负部分的表示法,该表示法可以更好地直观解释高维数据的因式分解矩阵。NMF将原始矩阵分解为基于零件的表示,从而更好地解释非负数据的因式分解矩阵。将NMF应用于多视图融合任务时,基于零件的表示可以减少任意两个视图之间的损坏,并获得更具鉴别能力的编码。这是第一次使用NMF组合多个视图进行图像哈希处理。
2017 Discrete Multi-view Hashing for Effective Image Retrieval 引用:17
处理单视图的方法不能充分利用多视图数据中包含的丰富信息。虽然已经提出了一些用于多视图数据的方法;它们通常放松二进制约束或将哈希函数和二进制码的学习过程分为两个独立的阶段,以绕过处理二进制码离散约束进行优化的障碍,这可能会产生较大的量化误差。针对这些问题,本文提出了一种新的哈希方法。可以直接处理多视图数据,充分利用多视图数据中丰富的信息。此外,在DMVH中,我们直接优化离散码,而不是放松二进制约束,从而获得高质量的哈希码。同时,提出了一种新的相似度矩阵构造方法,该方法既能保持局部相似度结构,又能保持数据点之间的语义相似度。
2017 Dynamic Multi-View Hashing for Online Image Retrieval 引用:75
根据图像的动态变化自适应地增加哈希码。当当前代码不能有效地表示新图像时,它可以增加代码长度。此外,为了进一步提高整体性能,为每个视图分配了权重,可以在在线学习过程中有效地更新权重。为了避免代码长度和视图权重的频繁更新,设计了一种智能缓冲方案来保存重要数据,以保持DMVH的良好有效性。
在动态哈希码中,蓝色区域、红色区域和黄色区域分别表示旧码、新数据的哈希码和扩充码。该数据库由许多图像组成,这些图像具有视觉和文本内容。当新图像到达时,通过多视图字典学习,提取多种视觉特征和一种文本特征并进行组合。微分阈值确定图像是否可以由当前哈希代码表示。如果没有,则将其添加到缓冲区,并使用缓冲区数据扩充哈希代码,直到缓冲区中没有更多可用空间。
2018 Multiview Discrete Hashing for Scalable Multimedia Search 引用:41 (无监督)

MvDH进行矩阵分解,生成哈希码作为多个视图共享的潜在表示,在此过程中同时进行谱聚类。通过哈希码和聚类标签的联合学习。在保证收敛性和低计算复杂度的前提下,提出了一种交替算法来求解该优化问题。采用离散循环坐标下降法(DCC)对二进制码进行优化,以减小量化误差。
矩阵分解过程中第i个对象的重构误差:
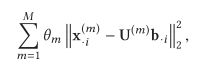
θm是对该视图重构误差进行加权的变量。
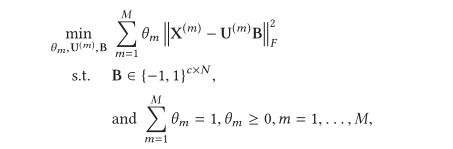
Multiview Alignment Hashing for Efficient Image Search 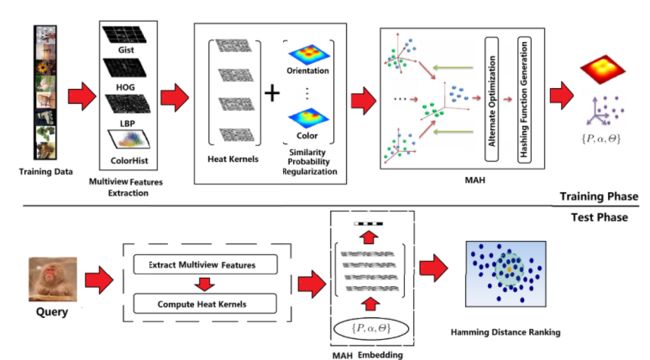
在训练阶段,通过对核权重α和分解矩阵(U,V)进行交替优化得到优化方法。该算法利用多变量logistic回归,输出投影矩阵和回归矩阵P生成哈希函数,直接在测试阶段使用。
2015 Learning to Hash on Partial Multi-Modal Data 引用 25
面对模态缺失的问题,提出了一种处理部分多模态数据的哈希方法。具体来说,哈希码的学习是通过隐子空间学习确保不同模式之间的数据一致性,并通过图拉普拉斯算子保持相同模态内的数据相似性。在此基础上,利用正交不变性进一步改进了正交旋转编码。
偏理论
2017 Discrete Multi-view Hashing for Effective Image Retrieval 引用17
总结:针对之前放松二进制约束的问题,直接进行直接优化离散码,从而获得理论上高质量的哈希码。同时,提出了一种新的构造相似度矩阵的方法。
**2020 Adaptive Online Multi-modal Hashing via Hadamard Matrix ** arxiv
作者受Hadamard矩阵的启发,以自适应的方式捕获多模态特征信息,并保留哈希码中的有区别的语义信息。超参数少。
**2020 Flexible Multi-modal Hashing for Scalable Multimedia Retrieval ** 引用28
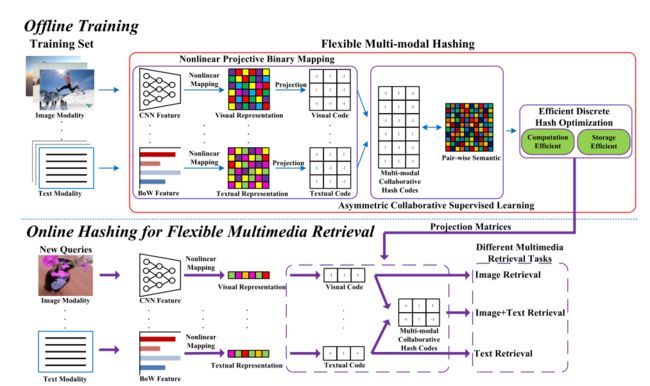
FMH在一个模型中同时学习多模态特定哈希码和多模态协作哈希码。查询提供任意一种或多种模态特性
2019 Online Multi-modal Hashing with Dynamic Query-adaption 引用27
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JKDIkzjs-1636104175293)(C:\Users\winter\AppData\Roaming\Typora\typora-user-images\image-20210914012255630.png)]
针对现有多模态哈希方法采用固定模态组合权值生成在线查询哈希码的问题,提出了一种查询自适应、自加权的在线哈希模块,以准确捕获不同查询的变化。此外,在线模块是无参数的。它可以避免无监督查询哈希过程中耗费时间和不准确的参数调整
多模态哈希方法思路借鉴和思考:
多视角主流且解释性好