基于中心先验的深度贝叶斯哈希算法的多模态神经影像检索(CenterHash)
确定了研究课题,跨模态检索在医学图像的应用。有很多疑惑的地方,有道是,如果还有疑惑就多读论文,所以就找了这篇论文来读。论文写得不错,建议从事这个方向的学者阅读一下,也解决了我很多不解,了解到医学神经影像的模态鸿沟,跨模态检索方法的发展过程,哈希函数使用方法等。但是有一点就是不接受的——没有官方代码。没有code的paper都是吹牛逼。代码,后续可能会自己写。这篇博客是以自己的角度总结这篇论文。
论文:Deep Bayesian Hashing With Center Prior for Multi-Modal Neuroimage Retrieval
基于中心先验的深度贝叶斯哈希算法的多模态神经影像检索
- 摘要
- 1. 介绍
- 2. 跨模态检索发展综述
-
- A. 基于连续表示方法
- B. 基于二进制表示方法
- 3. CenterHash方法
- 4. 实验
-
- A. 数据集
- B. 方法和评估标准
- 5. 结论
摘要
通过向医生提供以前的病例(视觉上相似的神经影像)和相应的诊断报告,多模态神经影像检索极大地促进了临床实践中决策的效率和准确性。然而,现有的图像检索方法在直接应用于多模态神经影像数据库时往往会失败,因为与自然图像相比,医学影像通常具有较小的类间差异和较大的模态差异。为此,我们提出了一个深度贝叶斯哈希学习框架,称为CenterHash,它可以将多模态数据映射到共享的海明空间,并从不平衡的多模态神经影像中学习判别哈希码。解决小类间差异和大模态差异的关键思想是为来自不同模态的相似的神经影像学习一个共同中心表示,并鼓励哈希码显式地靠近它们对应的中心表示。具体来说,我们计算哈希码和它们对应的中心表示之间的相似性,并将其作为贝叶斯学习框架(CenterHash)的中心先验。一个加权对数似然损失函数也被开发来促进从不平衡的神经影像中进行哈希学习。综合的实验证据表明,我们的方法可以生成有效的哈希码,并在三个多模态神经影像数据集上产生最先进的跨模态检索性能。
1. 介绍
神经影像分析对现代临床分析、影像引导手术和自动诊断研究做出了深远的贡献。目前,各种各样的数字图像技术已经发展到产生大脑组织的异质视觉表征,如结构磁共振成像(sMRI),正电子发射断层摄影术(PET) 和 计算机断层扫描(CT)。然而,神经影像的解释是一项复杂的任务,通常需要广泛的专业知识。在实践中,向医生提供以前的病例(视觉上相似的神经影像)和相应的治疗记录是很重要的,这有助于基于病例的推理和临床的决策。因此,多模态神经影像检索技术,即能从异构(不同模态)的神经影像数据库中返回相似的病例,在该领域引起了越来越多的关注。
本文重点研究了基于哈希的多模态神经影像检索,在检索性能和计算成本之间取得了很好的平衡。通常,跨模态哈希检索的目的是将异构模态图像映射到一个二进制的公共海明空间中。根据是否有监督标志,现有的方法大致可以分为两类:
(1)无监督哈希。它根据原始数据结构和分布学习哈希函数;
(2)有监督哈希。通过利用原始数据及其语义标签学习哈希函数。
近年来,许多无监督和有监督的跨模态哈希方法被用于自然图像检索。不幸的是,由于以下原因,当直接应用于多模态神经影像数据库时,现有的方法通常会获得较差结果。一方面,与自然图像相比,神经影像通常包含复杂的组织纹理和解剖结构。大脑局部区域细微病变可显著且准确影响诊断结果,这是因为神经影像具有小的类间变异。另一方面,即使对于同一受试者,不同的神经成像技术也会产生不同的视觉表征(例如,来自同一受试者的一对sMRI和PET扫描),这就带来了很大的跨模态差异(模态鸿沟)。开发高级哈希技术来解决小类间变异和大模态间差异的问题,以有效地检索多模态神经影像是非常需要的。
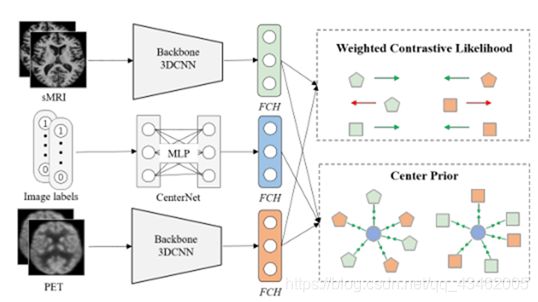
如图所示。提出了用于多模态神经影像检索的深度跨模态哈希方法(称为CenterHash),包括三个关键组成部分:
(1)两个模态特定网络(即主干网3DCNNs)将sMRI和PET投影到二进制哈希码;
(2)采用多层感知器(MLP)体系结构,建立了海明空间中每个类别的中心表示学习中心网;
(3)加权对数可能性损失和中心先验,均来自贝叶斯学习框架。不同的颜色表示不同的形态,不同的标记(圆圈除外)表示不同的类别。蓝色圆圈表示需要学习的中心表示。FCH:全连接哈希层。
为此,论文提出了一种新颖的深度跨模态神经影像哈希方法(见上图),称为CenterHash,旨在将来自不同模态的神经影像映射到一个共同的海明空间,并很好地保留跨模态语义相似性。具体来说,我们设计了一个深度多模态贝叶斯哈希学习框架,该框架可以同时学习多模态神经影像的深度表示和二进制哈希码。通过假设最优对象从同一类的二进制代码(甚至不同形式)应该接近公共表示,我们提出一个中心之前学到的二进制代码,作为重要组成部分地址小类的变异和大的挑战方式差异。我们还提出了一个加权的对比似然损失函数来实现对不平衡神经影像对的有效哈希码学习。大量的实验证明,CenterHash在三个多模态神经影像数据集上的性能达到了最先进的水平。
2. 跨模态检索发展综述
我们现在简要回顾一下相关的研究,包括基于连续表示和二进制表示(通过哈希码)的多模态图像检索方法。
A. 基于连续表示方法
传统的医学图像检索方法通常依赖于连续图像表示。例如,Cao等人扩展了概率潜在语义分析(pLSA)模型,以整合医学图像的视觉和纹理特征,并开发了基于深度玻尔兹曼机器的多模态学习框架,以获得缺失的模态
[Y.Cao et al.,“Medical image retrieval: a multimodal approach,” Cancer Informatics, vol. 13, pp. CIN–S14 053, 2014]
Vikram等人提出了一种基于潜在Dirichlet分配(LDA)的视觉特征编码技术,探索了早期融合和晚期融合,将视觉特征与文本特征结合起来。
[M.Vikram, A.Anantharaman, and S.BS,“An approach for multimodal medical image retrieval using latent dirichlet allocation,”in COMAD, 2019, pp. 44–51.]
Gao等人提出了一种基于多图学习的方法,该方法包括两个阶段:查询类别预测和排序。尽管这些方法取得了良好的效果,但它们往往受到特征维度的诅咒,不适合现代神经影像搜索系统。
[Y.Gao, E.Adeli-M, M.Kim, P.Giannakopoulos, S.Haller, and D.Shen,“Medical image retrieval using multi-graph learning for MCI diagnostic assistance,” in MICCAI. Springer, 2015, pp. 86–93.]
B. 基于二进制表示方法
为了提高图像检索的效率,人们提出了各种基于二进制表示(如哈希码)的快速多模态图像检索方法。根据学习阶段是否涉及监督信号,现有的多模态哈希方法可以分为两类:
- 无监督方法
- 监督方法。
下面我们将分别从这两组中总结出一些有代表性的方法。
无监督方法通常通过利用数据结构、拓扑信息和数据分布来学习哈希函数从原始特征空间到海明空间。语义主题多模态哈希通过语义主题的组合来解释多模态数据,并使用二进制代码表示对应主题的存在。
[D.Wang, X.Gao, X.Wang, and L.He, “Semantic topic multimodal hashing for cross-media retrieval,” in IJCAI, 2015, pp. 3890–3896.]
交替共量化(ACQ)通过同时最小化每个模态的二进制量化器并在不同模态之间保留数据相似性来学习哈希函数。
[G. Irie, H. Arai, and Y . Taniguchi, “Alternating co-quantization for cross modal hashing,” in ICCV, 2015, pp. 1886–1894.]
无监督生成对抗跨模态哈希(UGACH)提出了一个相关图来捕获多重结构,并利用生成对抗网络(GANs)来匹配从相关图中生成的数据对和对。
[J. Zhang, Y . Peng, and M. Y uan, “Unsupervised generative adversarial cross-modal hashing,” in AAAI, 2018, pp. 539–546.]
通过集成深度学习和矩阵分解来解决散列问题。
[G. Wu, Z. Lin, J. Han, L. Liu, G. Ding, B. Zhang, and J. Shen,“Unsupervised deep hashing via binary latent factor models for large,scale cross-modal retrieval.” in IJCAI, 2018, pp. 2854–2860.]
有监督的跨模态哈希方法可以探索语义信息,以增强不同模态之间的数据相关性,因此通常比无监督的同类方法获得更好的性能。交叉视图哈希(CVH)方法试图优化不同成对样本之间的相似性加权累积海明距离,以学习哈希函数。
[S. Kumar and R. Udupa, “Learning hash functions for cross-view similarity search,” in IJCAI, 2011.] [M. M. Bronstein, A. M. Bronstein, F. Michel, and N. Paragios, “Data fusion through cross-modality metric learning using similarity-sensitive hashing,” in CVPR, 2010, pp. 3594–3601.]
语义相关最大化(SCM)无缝地将语义标签集成到哈希学习过程中,并可以使用所有具有线性时间复杂度的监督信息。该算法利用海明空间中的语义相似性,以获得的哈希码作为监督信号,通过核逻辑回归学习哈希函数。虽然这些方法已经取得了一定的进展,但它们通常采用手工制作的图像特征,这可能会降低检索性能。
[D. Zhang and W.-J. Li, “Large-scale supervised multimodal hashing with semantic correlation maximization,” in AAAI, 2014.]
最近,深度学习已经彻底改变了计算机视觉、机器学习和许多其他相关领域。基于深度学习的跨模态哈希方法也被提出用于图像检索。
[Y.Cao, B.Liu, M.Long, and J.Wang, “Cross-modal hamming hashing,” in ECCV, 2018, pp. 202–218.]
[Q. Jiang and W. Li, “Deep cross-modal hashing,” in CVPR, 2017, pp. 3232–3240.]
[E. Yang, C. Deng, W. Liu, X. Liu, D. Tao, and X. Gao, “Pairwise relationship guided deep hashing for cross-modal retrieval.” in AAAI, 2017, pp. 1618–1625.]
[C. Li, C. Deng, N. Li, W. Liu, X. Gao, and D.Tao, “Self-supervised adversarial hashing networks for cross-modalretrieval,” in CVPR, 2018, pp. 4242–4251.]
深度跨模态哈希(DCMH)利用跨不同模式的成对标签来保持海明空间中的语义关系。
[Q. Jiang and W. Li, “Deep cross-modal hashing,” in CVPR, 2017, pp.3232–3240.]
考虑了模内和模间的相似性,并设计了一个正则化术语来最大化哈希码的表示能力。
[E. Yang, C. Deng, W. Liu, X. Liu, D. Tao, and X. Gao, “Pairwise relationship guided deep hashing for cross-modal retrieval.” in AAAI, 2017, pp. 1618–1625.]
基于排名的深度跨模态哈希(deep cross-modal hash, RDCMH)[40]通过利用多标签的多级排序语义结构来学习哈希函数。
[X. Liu, G. Y u, C. Domeniconi, J. Wang, Y . Ren, and M. Guo, “Ranking based deep cross-modal hashing,” in AAAI, 2019, pp. 4400–4407.]
自监督对抗哈希(SSAH)采用对抗学习的方法最大限度地提高了不同形式之间的表示相关性,并设计了一个自监督语义网络来从多标签标注中发现语义信息。
[C. Li, C. Deng, N. Li, W. Liu, X. Gao, and D. Tao, “Self-supervised adversarial hashing networks for cross-modal retrieval,” in CVPR, 2018, pp. 4242–4251.]
跨模态深度变分哈希(CMDVH)设计了跨模态融合网络和模态特定网络,并利用变分学习来匹配学习到的哈希码。
[V . Erin Liong, J. Lu, Y .-P . Tan, and J. Zhou, “Cross-modal deep variational hashing,” in ICCV, 2017, pp. 4077–4085.]
跨模态海明哈希(CMHH)利用指数分布推动相关数据对具有更小的海明距离。
[Y . Cao, B. Liu, M. Long, and J. Wang, “Cross-modal hamming hashing,” in ECCV, 2018, pp. 202–218.]
注意,这些方法通常集中在自然图像上,而不考虑神经影像的独特属性。因此,当直接应用于神经成像数据时,它们可能会导致不理想的性能。
3. CenterHash方法
对于多模态神经影像搜索,查询对象的模态可能与数据库中查询对象的模态不同。这里,我们假设D={X,Y}是给定的多模态神经影像数据集,其中X和Y是来自两种不同模态(如sMRI和PET)的医学图像集合。
以o为类别数目, ![]() 包含n个例子和
包含n个例子和 ![]() 是对应x的标签集。
是对应x的标签集。
![]() 包含m的例子和
包含m的例子和 ![]() 是对应y的标签集。
是对应y的标签集。
![]() 和
和 ![]() 是二进制值,表示xi和yi是否属于第d类。
是二进制值,表示xi和yi是否属于第d类。
多模态哈希的目标是学习特定于模态的哈希函数:
hx(x):x→{−1 + 1}k
hy(y):y→{−1 + 1}k,
可把原始的数据xi和yi编码成k-bit的哈希编码
![]()
![]()
在公共海明空间中,最大限度地保留原有的语义相似度, ![]() 和
和 ![]() 分别指示
分别指示 ![]() 和
和![]() 的第d个元素。
的第d个元素。
为了解决类间变化小和跨模态差异大的挑战,并从不平衡的神经影像数据中学习,本文提出了一种用于多模态神经影像搜索的深度贝叶斯哈希学习方法(称为CenterHash),其架构如图1所示。提出的CenterHash使用多模态神经影像(即sMRI和PET)及其标签作为输入,并可以通过端到端管道同时学习神经影像表示和二进制哈希码。包括三个部分:
- 两个通道特定网络(即骨干3DCNNs),将输入图像投影到二进制哈希码;
- 提出的海明空间中心表示学习中心网;
- 加权对比似然损失和新颖的中心先验,均来自贝叶斯学习框架。详情请参阅以下内容。
4. 实验
A. 数据集
我们在三个流行的基准数据集上评估我们的方法:
(1)阿尔茨海默病神经成像计划(ADNI1),
(2)ANDI2
(3)澳大利亚成像、生物标志物和生活方式数据集(AIBL)。下面,我们将对每个数据集进行更详细的介绍。
ADNI1包含821名受试者进行1.5T t1加权sMRI扫描,其中只有397名受试者有PET图像。每个受试者都用分类级标签标注,即阿尔茨海默病(AD)、正常控制(NC)或轻度认知障碍(MCI)。这些标签是根据标准的临床标准确定的,包括微型精神状态检查评分和临床痴呆评级。在ADNI1 sMRI扫描的受试者中,NC 229例,MCI 393例,AD 199例。对于ADNI1的PET数据,有100名NC、93名AD和204名MCI受试者。
ADNI2包含636名受试者3T t1加权sMRI扫描,309名受试者PET图像。根据ADNI1相同的临床标准,将这些图像分为AD、NC和MCI三种类型。对于sMRI数据,有200名NC、277名MCI和159名AD受试者。对于PET数据,有94名NC、149名MCI和66名AD受试者。
AIBL包括612名3T t1加权sMRI扫描者和560名PET扫描者。与ADNI1和ADNI2类似,这些图像分别被分为AD、NC和MCI。在sMRI模式上,有447名NC、94名MCI和71名AD受试者。在PET模式方面,有407名NC、91名MCI和62名AD受试者。
所有这三个数据集,我们随机选择10%每个类的图像形式测试集,剩下的图像作为检索集。为了优化该方法,我们进一步随机选择90%的图像检索设置为训练集和治疗其他验证集。我们预处理sMRI和PET扫描使用一个标准的管道,包括前连合(AC)后连合(PC)修正,强度修正,剥去头颅,切除小脑。仿射配准也被执行以使每个PET图像与它相应的sMRI扫描对齐。
B. 方法和评估标准
本文采用四种评价指标,分别为平均精度平均值(MAP)、recall@K、Top-n精度和PR曲线。前三个指标基于海明空间排名,它根据返回数据点到查询的海明距离对它们进行排名。PR曲线指标基于散列查找,因为它首先构建一个散列查找表,并返回预定义的海明半径内的数据点。给定一个查询和一个排序为Q的检索示例列表,该查询的平均精度(AP)定义为
其中,R为数据库中与地真相关的点个数,P(q)为检索到的上q点的精度值。当第q个检索点与查询相关时,δ(q) = 1,否则δ(q) = 0。在我们的实验中,三个数据集的Q都设置为100。映射被定义为所有查询的平均ap。Recall@K被定义为来自top K返回实例的ground-truth邻居在所有语义相关点中的百分比。TopN-precision表示基于海明距离(Hamming distance)的所有给定查询的top N返回点中语义相关实例的平均比例。在本文中,我们设K和N都为100。查全率反映了不同查全率下的检索精度,被认为是一个很好的检索性能指标。
5. 结论
本文提出了一种用于多模态神经影像检索的中心哈希算法。具体来说,提出的CenterHash在贝叶斯学习框架中提出了哈希码学习问题,其中提出了一个中心先验来明确鼓励来自不同模式的同类哈希码接近。此外,本文还提出了一个加权对比似然损失函数来解决数据不平衡的问题。综合的经验证据表明,我们的CenterHash在三个多模态神经影像数据集上产生了最先进的跨模态检索性能。在未来的工作中,将相关性反馈整合到这个框架中以进一步提高信息检索系统的搜索性能是很有趣的。