【大数据处理技术】「#0」实验环境准备
文章目录
- 实验步骤解析
- 「Mac系统」安装配置Linux虚拟机
-
- 虚拟机下载安装
- Ubuntu下载安装
-
- 设置共享文件夹
- 安装Hadoop
-
- 创建hadoop用户(可忽略,本实验不使用hadoop用户)
- 更新apt(安装Ubuntu桌面版时更新了)
- 安装ssh、配置ssh无密码登录
- 安装java环境(java1.8/java8)
- 安装Hadoop2
-
- Hadoop伪分布式配置
- 运行Hadoop伪分布式实例
- 安装MySQL
-
- 安装MySQL
- 解决利用sqoop导入MySQL中文乱码的问题
- MySQL常用操作
- 安装Hive
-
- Hive 安装配置
- 启动Hive测试
- 安装Sqoop
- 安装Spark
- 「电脑本地」安装IDEA、WebStorm、Echarts
-
- 安装JetBrains全家桶(略)
- 为Vue安装Echarts插件(略)
实验步骤解析
- 实验步骤:
- 步骤0:实验环境准备
- 步骤1:本地数据集上传到数据仓库Hive
- 步骤2:Hive数据分析
- 步骤3:将数据从Hive导入到MySQL
- 步骤4:利用Spark预测回头客
- 步骤5:利用ECharts进行数据可视化分析
- 实验说明:
- 采用「本地电脑+虚拟机结合」方法进行试验:
- 本地:获取数据、前端(Vue+Springboot+ECharts)
- 虚拟机:数据存储&数据处理(MySQL、Hive、Sqoop)、数据分析(Spark)
- 采用「本地电脑+虚拟机结合」方法进行试验:
- 软件版本说明:
- 虚拟机: UTM
- Linux系统:Ubuntu-22.04.1(arm64)
- Hadoop:hadoop-3.3.4
- MySQL:8.0.31-0ubuntu0.22.04.1
- Hive:hive-3.1.2 / hive-3.1.3
- Sqoop:sqoop-1.4.6(sqoop1)
- Spark:
- Java1.8
- 由于Mac M1芯片电脑目前仅支持安装arm架构的Ubuntu虚拟机,以下设计软件均使用arm版!
「Mac系统」安装配置Linux虚拟机
虚拟机下载安装
下载地址:VMware Fusion Blog【寄】- 就是安装不了镜像,不知道原因
- 想法:本地虚拟机(Ubuntu) + 云服务器(CentOS7)

- 购买安装UTM
Ubuntu下载安装
- ❎AMD版:Ubuntu-20.04.5镜像地址
- ✅ARM版: Ubuntu-22.04.1-live-server-arm64
- 安装Ubuntu-22.04.1-live-server-arm64
- 【注意:重启会卡住,手动选择右上角弹出后,手动关闭再打开虚拟机!】

- 安装完毕后reboot
- 升级为桌面版 Installing Ubuntu Desktop
- If you installed Ubuntu Server, then at the end of the installation, you will not have any GUI. To install Ubuntu Desktop, log in and run:
sudo apt update
sudo apt install ubuntu-desktop
sudo reboot
设置共享文件夹
- 安装samba
# 安装samba则安装
sudo apt-get install samba smbfs
# 把当前用户添加到sambashare组里
sudo adduser yourname sambashare
安装Hadoop
创建hadoop用户(可忽略,本实验不使用hadoop用户)
- 创建新用户
sudo useradd -m hadoop -s /bin/bash
- 设置用户密码
sudo passwd hadoop
- 增加管理员权限
sudo adduser hadoop sudo
更新apt(安装Ubuntu桌面版时更新了)
- 更新apt-get
sudo apt-get update
- 若出现如 “Hash校验和不符” 的提示,可通过更改软件源来解决
- 更新vim/gedit
sudo apt-get install vim
安装ssh、配置ssh无密码登录
- Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server
sudo apt-get install openssh-server
- 使用命令登陆本机(密码:hadoop)
ssh localhost
- 如果有提示,按照提示输入yes回车
- 退出刚才的 ssh,回到原先的终端窗口,利用 ssh-keygen 生成密钥,并将密钥加入到授权中
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
- 此时再用 ssh localhost 命令,无需输入密码就可以直接登陆

安装java环境(java1.8/java8)
- 官网下载
- 解压安装
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
- 配置环境变量
cd ~
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_351 # 自己安装java的位置
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc
- 查看是否生效
java -version

安装Hadoop2
- hadoop下载地址:
- Apache hadoop官网
- 清华镜像

- 解压安装
sudo tar -zxf ~/下载/hadoop-3.3.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.4/ ./hadoop # 将文件夹名改为hadoop
# 修改文件权限
sudo chown -R hadoop ./hadoop
sudo chmod -R 777 ./hadoop # 常用这个命令改变权限
- 检查是否可用
cd /usr/local/hadoop
./bin/hadoop version

Hadoop伪分布式配置
- Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中
- 伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
# 使用gedit更方便
gedit ./etc/hadoop/core-site.xml
- 修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- 配置完成后,执行 NameNode 的格式化
cd /usr/local/hadoop
./bin/hdfs namenode -format
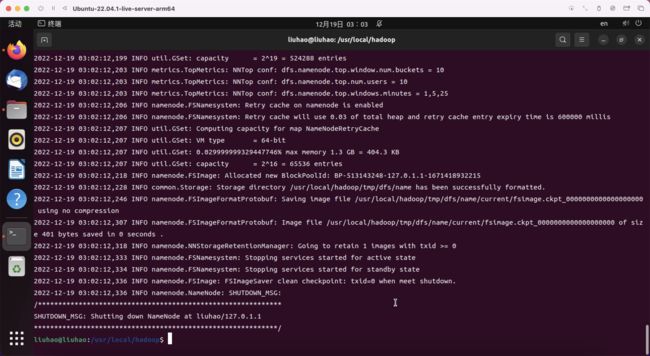
- 在hadoop-env.sh中重新声明JAVA_HOME
- 配置hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- 开启 NameNode 和 DataNode 守护进程
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
- 如果出现warn警告可以忽略,可以自行删除警告(百度)

- 访问 Web 界面 http://localhost:9870 ,查看 NameNode 和 Datanode 信息

运行Hadoop伪分布式实例
- 在 HDFS 中创建用户目录
./bin/hdfs dfs -mkdir -p /user/liuhao
- 将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
- 复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input

安装MySQL
安装MySQL
- 命令安装MySQL
sudo apt-get update #更新软件源
sudo apt-get install mysql-server #安装mysql
- 启动和关闭MySQL服务器
service mysql start
service mysql stop
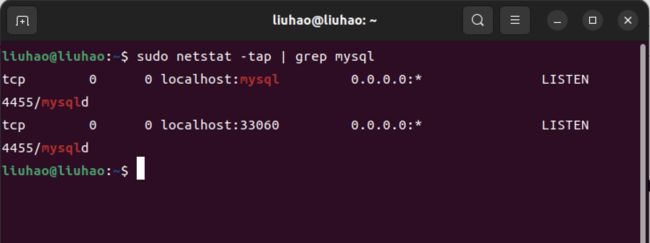
- 确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql
- 修改默认密码
- 设置为允许无密码登陆
- 重启mysql,以root身份进入mysql
- 先将密码设置为空,刷新之后再将密码修改为准备好的密码
- 仿照第一步,将mysqld.cnf中加入的 那条语句删掉
- 重启mysql,并尝试用你设置的密码登录root账户
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
# 在mysqlId里加入语句
skip-grant-tables
# 重启mysql,以root身份进入mysql(输入下面的第二条语句之后直接按回车即可):
service mysql restart
mysql -u root -p
# 先将密码设置为空,刷新之后再将密码修改为准备好的密码(依次输入下列语句)
mysql> use mysql;
mysql> flush privileges;
mysql> UPDATE user SET authentication_string='' WHERE user='root';
mysql> flush privileges;
mysql> mysql> alter user 'root'@'localhost' identified with mysql_native_password by '123';
mysql> quit;
# 重启mysql,并尝试用你设置的密码登录root账户
service mysql restart
mysql -u root -p
- 进入MySQL SHELL 界面
mysql -u root -p
解决利用sqoop导入MySQL中文乱码的问题
- 编辑配置文件。
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf - 在[mysqld]下添加一行
character_set_server=utf8 - 重启MySQL服务。
service mysql restart - 登陆MySQL,并查看MySQL目前设置的编码。
show variables like "char%";

MySQL常用操作
- 显示数据库
mysql> show databases;
# MySql刚安装完有两个数据库:mysql和test。
# mysql库非常重要,它里面有MySQL的系统信息,我们改密码和新增用户,实际上就是用这个库中的相关表进行操作。
2、显示数据库中的表
mysql> use mysql; # 打开库,对每个库进行操作就要打开此库
Database changed
mysql> show tables;
3、显示数据表的结构:
describe 表名;
4、显示表中的记录:
select * from 表名;
# 例如:显示mysql库中user表中的纪录。所有能对MySQL用户操作的用户都在此表中。
select * from user;
5、建库:
create database 库名;
# 例如:创建一个名字位aaa的库
mysql> create database aaa;
6、建表:
use 库名;
create table 表名 (字段设定列表);
# 例如:在刚创建的aaa库中建立表person,表中有id(序号,自动增长),xm(姓名),xb(性别),csny(出身年月)四个字段
use aaa;
mysql> create table person (id int(3) auto_increment not null primary key, xm varchar(10),xb varchar(2),csny date);
# 可以用describe命令察看刚建立的表结构。
mysql> describe person;
describe-person
7、增加记录
# 例如:增加几条相关纪录。
mysql>insert into person values(null,'张三','男','1997-01-02');
mysql>insert into person values(null,'李四','女','1996-12-02');
# 注意,字段的值('张三','男','1997-01-02')是使用两个英文的单撇号包围起来,后面也是如此。
# 因为在创建表时设置了id自增,因此无需插入id字段,用null代替即可。
# 可用select命令来验证结果。
mysql> select * from person;
select-from-person
8、修改纪录
# 例如:将张三的出生年月改为1971-01-10
mysql> update person set csny='1971-01-10' where xm='张三';
9、删除纪录
# 例如:删除张三的纪录。
mysql> delete from person where xm='张三';
10、删库和删表
drop database 库名;
drop table 表名;
11、查看mysql版本
# 在mysql5.0中命令如下:
show variables like 'version';
# 或者
select version();
安装Hive
Hive 安装配置
- 官网下载
- 镜像下载

- 解压安装
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
sudo chmod -R 777 hive # 修改文件权限
- 配置环境变量
vim ~/.bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
source ~/.bashrc
- 修改/usr/local/hive/conf下的hive-site.xml
cd /usr/local/hive/conf
# 将hive-default.xml.template重命名为hive-default.xml
mv hive-default.xml.template hive-default.xml
cd /usr/local/hive/conf
vim hive-site.xml
- 在hive-site.xml中添加如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
- 注意!
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
# 需要改成自己数据库的用户名和密码(这里应该是设置Hive自己的密码,MySQL创建数据库根据这个连接Hive),不然hive无法连接数据库!

启动Hive测试
- 下载安装mysql jdbc 包
- 下载地址

- 解压安装
tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压
#将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
- 启动并登陆mysql shell
service mysql start #启动mysql服务
mysql -u root -p #登陆shell界面
- 新建hive数据库
#这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据
mysql> create database hive;
- 创建hive用户,配置mysql允许hive接入
#将所有数据库的所有表的所有权限赋给hive用户
# 后面的hive是配置hive-site.xml中配置的连接密码
grant all on *.* to hive@localhost identified by 'hive';
# 高版本MySQL无法按照上述方法修改用户权限,需要分步
create user 'hive'@'%' identified by '123';
grant all privileges on *.* to 'hive'@'%' with grant option;
flush privileges; #刷新mysql系统权限关系表
- 初始化
schematool -dbType mysql -initSchema
- 启动hive
start-dfs.sh #启动Hadoop的HDFS
hive #启动hive

注意,我们这里已经配置了PATH,所以,不要把start-all.sh和hive命令的路径加上。如果没有配置PATH,请加上路径才能运行命令,比如,本教程Hadoop安装目录是“/usr/local/hadoop”,Hive的安装目录是“/usr/local/hive”,因此,启动hadoop和hive,也可以使用下面带路径的方式:
cd /usr/local/hadoop #进入Hadoop安装目录
./sbin/start-dfs.sh
cd /usr/local/hive
./bin/hive

安装Sqoop
-
下载地址
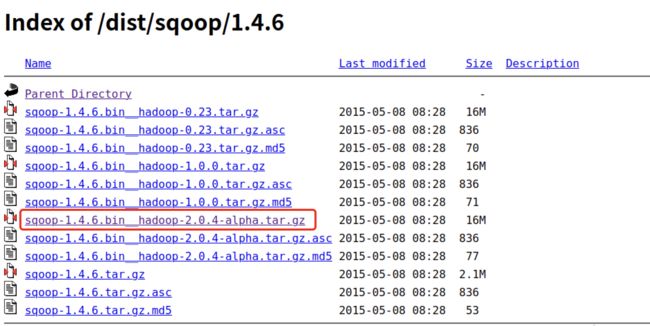
-
解压安装
sudo tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local #解压安装文件
cd /usr/local
sudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop #修改文件名
sudo chmod -R 777 sqoop #修改文件夹属主,如果你当前登录用户名不是hadoop,请修改成你自己的用户名
- 修改配置文件sqoop-env.sh
cd sqoop/conf/
cat sqoop-env-template.sh >> sqoop-env.sh #将sqoop-env-template.sh复制一份并命名为sqoop-env.sh
vim sqoop-env.sh #编辑sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase # 可选
export HIVE_HOME=/usr/local/hive
#export ZOOCFGDIR= #如果读者配置了ZooKeeper,也需要在此配置ZooKeeper的路径
- 配置环境变量
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SBT_HOME/bin:$SQOOP_HOME/bin
export CLASSPATH=$CLASSPATH:$SQOOP_HOME/lib
- 将mysql驱动包拷贝到$SQOOP_HOME/lib
- 测试与MySQL的连接
# 启动MySQL
service mysql start
# 连接数据库
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P

安装Spark
- Spark官方下载地址
- 清华镜像

- 解压安装
sudo tar -zxf ~/下载/spark-1.6.2-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-1.6.2-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
- 修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
# 编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
- 通过运行Spark自带的示例,验证Spark是否安装成功
cd /usr/local/spark
bin/run-example SparkPi
# 可以通过 grep 命令进行过滤
bin/run-example SparkPi 2>&1 | grep "Pi is"

「电脑本地」安装IDEA、WebStorm、Echarts
安装JetBrains全家桶(略)

为Vue安装Echarts插件(略)
【参考资料】
MySQL和Hive安装
Spark安装
林子雨老师参考