【论文解读 NIPS 2019 | GTNs】Graph Transformer Networks

论文题目:Graph Transformer Networks
论文来源:NIPS 2019
论文链接:https://arxiv.org/abs/1911.06455
代码链接:https://github.com/seongjunyun/Graph_Transformer_Networks
文章目录
- 1 摘要
- 2 引言
- 3 模型
-
- 3.1 定义
-
- 3.1.1 异质图
- 3.1.2 元路径
- 3.1.3 GCN
- 3.2 元路径的生成
-
- 3.2.1 GT层
- 3.2.2 多层堆叠
- 3.3 Graph Transformer Networks
- 4 实验
- 5 总结
1 摘要
本文解决的是HIN中的节点嵌入学习问题。
现有的GNN大多在固定且同质的图上进行节点的表示学习。
本文提出了一种能够生成新的图数据结构的图变换网络(Graph Transformer Networks, GTNs),它包括识别原始图数据中未连接节点之间的有用连接,同时以端到端方式学习新图数据中有效的节点表示。
图变换层(Graph Transformer layer)是GTNs中的核心层,它可以选择出边类型和组合关系,以生成有用的多跳连接,即元路径。
实验表明GTNs基于无先验知识的数据和任务,通过在新图上进行卷积,可以学习出有效的节点表示。
在三个基线的节点分类任务上超越state-of-the-art,并且对比的这些方法都需要预先定义元路径。
2 引言
GNN的局限性:
(1)大多数GNN是能在固定且同质的图上进行运算。如果图上有噪声,缺失连边或者有错误的连边,就会导致与图上错误的邻居进行无效的卷积。
(2)大多数GNN忽略了节点/边的类型,使用人为设定的元路径将异质图转化成同质图,不能充分利用图中的信息。并且选择的元路径将会在很大程度上影响下游任务的准确率。
这种方式是**两步走(two-stage)**的方法:
- 针对特定任务/数据集,人为设计元路径;
- 根据元路径将异质图转化为同质图,在其上面应用GNN。
作者提出:
作者提出GTN,可以看成是空间转换网络(STN)向图数据的扩展。具体表现为将HIN转换成由元路径定义的新的图结构,就可以直接在新图上进行节点的表示学习,是**端到端(end-to-end)**的学习模式。
将HIN转换为元路径定义的新的图结构带来的挑战:
- 元路径的长度不固定,元路径中边的类型也是任意的;
- 能应用于有向图的GNN相对较少。
基于上述挑战,作者提出:
提出模型生成新的图结构,该模型基于HIN中由所选边类型相连的复合关系,并在给定问题下的图结构上进行卷积操作以学习到节点表示。
3 模型
GTNs框架的目的是为原始图生成新的图结构,并在新图上进行节点表示学习。
与大多数在给定图上进行CNN的方法不同,GTNs使用多个候选的邻接矩阵生成新的图结构,以实现更有效的图卷积,学习到表示能力更强的节点嵌入表示。
3.1 定义
3.1.1 异质图
- 异质图 G = ( V , E ) G=(V, E) G=(V,E), V V V是节点集合, E E E是边集合;
- T v , T e T^v, T^e Tv,Te分别是节点类型集合和边类型集合;
- 异质图可表示成一组邻接矩阵 { A k } k = 1 K , K = ∣ T e ∣ {\{A_k\}^K_{k=1}}, K=|T^e| {Ak}k=1K,K=∣Te∣。 A k ∈ R N × N A_k\in R^{N\times N} Ak∈RN×N是邻接矩阵,若节点 j j j到 i i i之间有第 k k k中类型的边相连,则 A k [ i , j ] ≠ 0 A_k[i, j]\ne 0 Ak[i,j]=0。也可以写成张量的形式: A ∈ R N × N × K A\in R^{N\times N\times K} A∈RN×N×K;
- 节点的特征矩阵为 X ∈ R N × D X\in R^{N\times D} X∈RN×D.
3.1.2 元路径
元路径 P P P的邻接矩阵表示成元路径中不同类型的边对应的邻接矩阵的乘积:
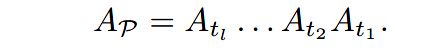
3.1.3 GCN
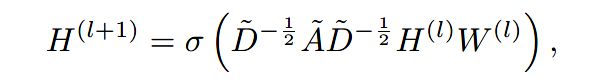
其中 A ~ = A + I ∈ R N × N \tilde{A}=A+I\in R^{N\times N} A~=A+I∈RN×N, D ~ \tilde{D} D~是 A ~ \tilde{A} A~的度矩阵, W ( l ) ∈ R d × d W^{(l)}\in R^{d\times d} W(l)∈Rd×d是可训练的参数矩阵。
对于有向图则将 D ~ − 1 2 A ~ D ~ − 1 2 \tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}} D~−21A~D~−21换成 D ~ − 1 A ~ \tilde{D}^{-1}\tilde{A} D~−1A~
由上式可以看出,卷积操作是由给定的图结构决定的,且只有针对节点的线性转换参数 H ( l ) W ( l ) H^{(l)}W^{(l)} H(l)W(l)是可学习的。因此,卷积层可以被解释成固定卷积的组合,在图上经过节点级别的线性变换后再通过一个激活函数。
3.2 元路径的生成
先前的工作都是人工定义元路径,然后在其基础上进行GNN。本文提出的GTNs为给定的数据和任务学习到元路径,然后在学习到的元路径图(meta-path graphs)上进行图卷积。
3.2.1 GT层

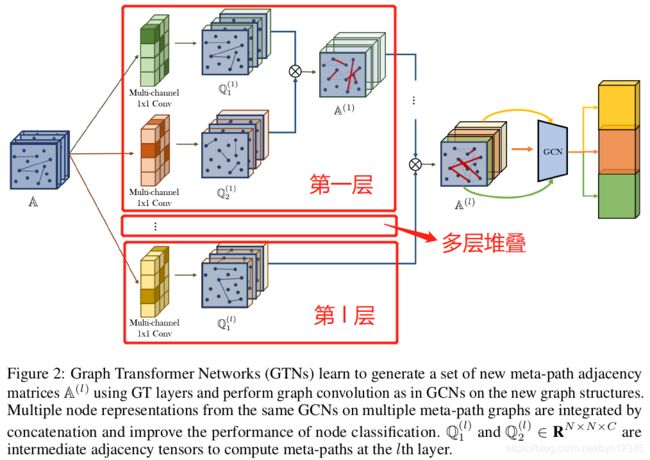
元路径图的生成过程如上图的图变换层(GT)层所示,分为两步:
-
首先,GT层从候选的邻接矩阵 A A A(每一片都代表一种边类型)中选择出两个图结构 Q 1 , Q 2 Q_1, Q_2 Q1,Q2;
-
然后,将其组合得到新的图结构(例如 将两个邻接矩阵相乘, Q 1 Q 2 Q_1Q_2 Q1Q2)。
接下来逐步分析一下
(1)邻接矩阵 Q Q Q是通过下式的计算选择出来的:
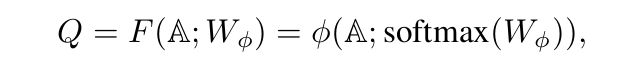
其中 ϕ \phi ϕ表示卷积操作, W ϕ ∈ R 1 × 1 × K W_{\phi}\in R^{1\times 1\times K} Wϕ∈R1×1×K是 ϕ \phi ϕ的参数。其实 Q Q Q的选择类似使用了注意力机制。
以图1为例,输入的原始图的邻接矩阵 A ∈ R N × N × K \mathbb{A}\in R^{N\times N\times K} A∈RN×N×K( K = 4 K=4 K=4)一共有4片,每一片对应着一种类型的边的邻接矩阵,即原始图中一共有4种类型的边。
使用 s o f t m a x softmax softmax函数归一化后的 W ϕ ∈ R 1 × 1 × K W_{\phi}\in R^{1\times 1\times K} Wϕ∈R1×1×K就是 1 × 1 1\times 1 1×1卷积层的参数。卷积后得到的邻接矩阵,可以看成是在原邻接矩阵上应用了注意力机制,为各个片分配了不同的注意力系数作为每片的权重,加权求和得到新的邻接矩阵 Q Q Q。
矩阵 Q Q Q的每一片 Q i Q_i Qi可以表示成: ∑ t l ∈ T e α t l ( l ) A t l \sum_{t_l\in T^e} \alpha^{(l)}_{t_l} A_{t_l} ∑tl∈Teαtl(l)Atl,其中 α t l ( l ) \alpha^{(l)}_{t_l} αtl(l)就是 1 × 1 1\times 1 1×1卷积层中的参数, l l l表示位于第几层。
图1中的 Q 1 , Q 2 Q_1, Q_2 Q1,Q2分别是 Q Q Q的两个片,也就是说经过 1 × 1 1\times 1 1×1卷积操作后,输入从 A ∈ R N × N × 4 \mathbb{A}\in R^{N\times N\times 4} A∈RN×N×4转换成了 Q ∈ R N × N × 2 Q\in R^{N\times N\times 2} Q∈RN×N×2。
(2)将选择出的邻接矩阵组合得到新的图结构:
采用矩阵相乘的方式,如图1所示: A ( l ) = Q 1 Q 2 A^{(l)}=Q_1Q_2 A(l)=Q1Q2。为了数值稳定,使用度矩阵进行归一化: A ( l ) = D − 1 Q 1 Q 2 A^{(l)}=D^{-1}Q_1Q_2 A(l)=D−1Q1Q2。
长度为 l l l的元路径对应的邻接矩阵 A P A_P AP计算为:

其中 T e T^e Te表示边类型的集合, α t l ( l ) \alpha^{(l)}_{t_l} αtl(l)为对类型为 t l t_l tl的边在第 l l l层中的权重。
3.2.2 多层堆叠
由3.2.1可知,当 α \alpha α不是one-hot向量时, A P A_P AP就可以看成是所有长度为 l l l的元路径的邻接矩阵的加权和。
因此堆叠 l l l层GT层就可以学习到任意的长度为 l l l的元路径图结构,如图2所示。
假定卷积的输出通道为 1 1 1,第 l l l层GT层为新的元路径图生成的邻接矩阵 A ( l ) A^{(l)} A(l)计算如下:

将迭代展开后可得:

其中 T e T^e Te表示边类型的集合, α t l ( l ) \alpha^{(l)}_{t_l} αtl(l)为对类型为 t l t_l tl的边在第 l l l层中的权重。因此, A ( l ) A^{(l)} A(l)可以看成是对所有长度为 1 1 1~ l l l的元路径的加权和。元路径 t l , t l − 1 , . . . , t 0 t_l,t_{l-1},...,t_0 tl,tl−1,...,t0的贡献度计算为 ∏ i = 0 l α t i ( i ) \prod_{i=0}^{l}\alpha^{(i)}_{t_i} ∏i=0lαti(i)。
注意:
生成的元路径长度等于GT层的层数,所以堆叠的层数越多,则生成的元路径越长,而且堆叠多层后原始图中的连边可能不存在了。然而,有的时候短的元路径也很重要。
为了学习到包含原始图中连边的长的元路径和短的元路径,在 A \mathbb{A} A中加入单位矩阵 I I I,例如 A 0 = I A_0=I A0=I。这样,当有 l l l层GT层时,就可以学习到长度为 1 1 1~ l l l的元路径。
3.3 Graph Transformer Networks
为了同时生成多种类型的元路径,将图1中卷积的输出通道设置为 C C C,如图2所示。随后GT层产生一组元路径,图1中的 Q 1 , Q 2 Q_1,Q_2 Q1,Q2成为图2中的张量 Q 1 ( l ) , Q 2 ( l ) ∈ R N × N × C \mathbb{Q^{(l)}_1}, \mathbb{Q^{(l)}_2}\in R^{N\times N\times C} Q1(l),Q2(l)∈RN×N×C。 Q 1 ( l ) , Q 2 ( l ) \mathbb{Q^{(l)}_1}, \mathbb{Q^{(l)}_2} Q1(l),Q2(l)是为了计算元路径,得到的第 l l l层的邻接张量的中间值。
通过多个不同的图结构学习到不同的节点表示是很有帮助的。
l l l表示生成的元路径的最大长度, C C C表示生成几条元路径。
在 l l l个GT层堆叠后,将GCN应用于元路径张量 A l ∈ R N × N × C \mathbb{A}^l\in R^{N\times N\times C} Al∈RN×N×C的每个通道,并将多个节点的向量表示拼接起来:

其中, ∣ ∣ || ∣∣是连接操作, C C C是通道数, A ^ i ( l ) = A i ( l ) + i \hat{A}^{(l)}_i=A^{(l)}_i+i A^i(l)=Ai(l)+i是 A ( l ) \mathbb{A}^{(l)} A(l)的第 i i i个通道的邻接矩阵, D ^ i \hat{D}_i D^i是 A ^ i ( l ) \hat{A}^{(l)}_i A^i(l)的度矩阵, W ∈ R d × d W\in R^{d\times d} W∈Rd×d是 1 × 1 1\times 1 1×1卷积中需要训练的权重矩阵, X ∈ R N × d X\in R^{N\times d} X∈RN×d是输入的特征矩阵。
Z Z Z包含节点在 C C C个元路径图中的表示,元路径的长度最长为 l l l。
将 Z Z Z用于有监督的节点分类任务,构造优化目标。分类器的结构为: Z Z Z输入到2层的稠密层,然后再过一层softmax。损失函数是交叉熵函数。
整个模型架构可以看成是:在由GT层学习到的多个元路径图(meta-path graphs)上进行GCN。
4 实验
实验并分析,回答如下的几个问题:
- GTN生成的新的图结构对节点的表示学习有效吗?
- GTN是否能根据数据集自适应地生成变长的元路径?
- 如何从GTN生成的邻接矩阵来解释每个元路径的重要性?
数据集:

实验任务:节点分类
对比方法:
(1)传统的网络嵌入学习方法
- DeepWalk
- metapath2vec
(2)基于GCN的方法
- GCN
- GAT
- HAN
实验结果:
(1)节点分类实验结果
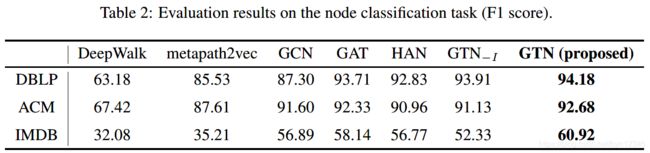
其中 G T N − I GTN_{-I} GTN−I表示候选邻接矩阵 A \mathbb{A} A没有包含单位矩阵。实验可以看出,使用3层的GT层,只能为IMDB数据集生成长度为4的元路径,效果很不好,因为IMDB中长度更短的元路径更合适。
(2)解释元路径的重要性
由3.2.2可知,元路径 t l , t l − 1 , . . . , t 0 t_l,t_{l-1},...,t_0 tl,tl−1,...,t0的注意力分数计算为 ∏ i = 0 l α t i ( i ) \prod_{i=0}^{l}\alpha^{(i)}_{t_i} ∏i=0lαti(i),代表了在预测任务中这条元路径的重要性。表3就展示了GTNs学习到的注意力得分最高的元路径,以及预定义的元路径,证明了GTNs可以学习到针对特定任务的比较重要的元路径。

(3)GTNs根据数据集自适应地学习到变长的元路径
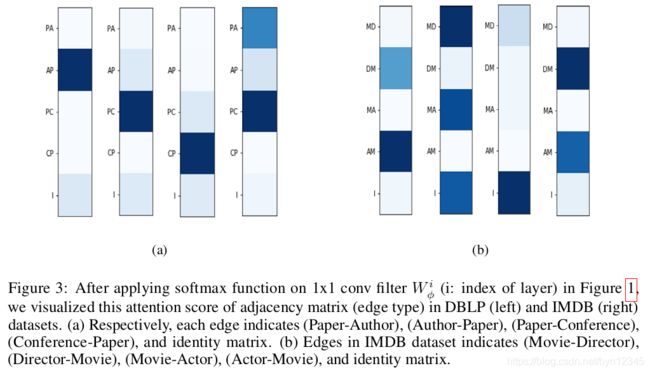
图3展示了每层GT层不同邻接矩阵(不同类型的边)的注意力分数。IMDB和DBLP相比,单位矩阵的注意力分数较高,说明GTNs能学习到比GT层数少的较短的元路径。
5 总结
这篇文章很有开创性。
本文提出图转换网络(GTNs)用于HIN上的节点表示学习。
将HIN转换为多个由元路径定义的新图,并且元路径中的边类型任意,长度是从 1 1 1~ l l l的任意长度( l l l为GT层层数)。然后在学习到的元路径图上通过卷积操作,进行节点表示的学习。
GTNs的一大特点是,不需要预先定义元路径,也就是不需要专家的先验知识。GTNs可以为给定的数据集自适应地学习到合适长度的元路径,元路径的重要性体现为注意力分数。
未来的研究方向:
(1)本文在GT层之后使用的数GCN方法,后续可以研究使用其他的GNN方法;
(2)本文只在节点分类任务上体现出了很好的效果,后续可以研究在其他任务上的效果,例如链接预测、图分类等。