Verilog语言编写 串行数据转矩阵模块
在我们对图片进行处理的时候,通常会用到许多地方需要我们将串行数据转换为矩阵使用(如腐蚀,膨胀,卷积等),所以这一步是必不可少的。
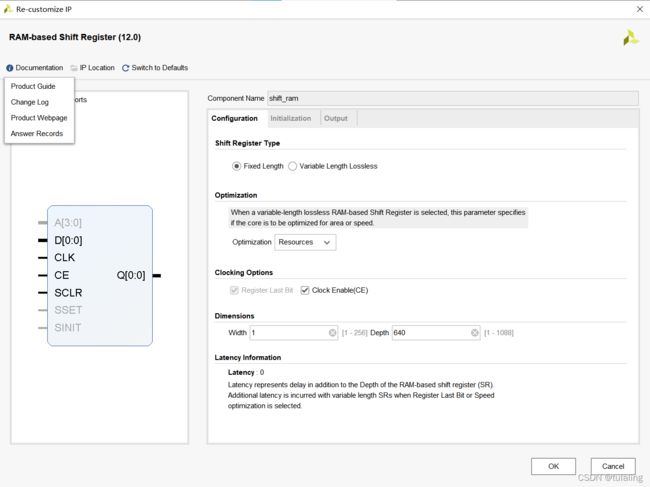
在这个子模块的设计中,我们调用了VIVADO中的一个IP核Sgift Register来实现目的,该IP核的具体功能和各个接口的作用,可以点击Documentation去查询。
这里为们以480*640的情况下的1bit为例,如果需要设计其他深度的矩阵转换模块,可以自行改变以为寄存器的位宽和深度。因为是640一行,所以深度设置为640.
下面,我们进行模块设计,首先进行端口的声明
module Matrix_Generate_3X3_1Bit (
//global signals
input clk, //cmos video pixel clock
input rst_n, //global reset
//signals from senor
input per_frame_vsync,
input per_frame_href,
input per_frame_clken,
input per_img_Bit,
//signals has been processd
output matrix_frame_vsync,
output matrix_frame_href,
output matrix_frame_clken,
output reg matrix_p11, matrix_p12, matrix_p13, //3X3 Matrix output
output reg matrix_p21, matrix_p22, matrix_p23,
output reg matrix_p31, matrix_p32, matrix_p33
);在这里先对输入数据通过clk_en打一拍,因为我们后面移位寄存器的使能信号就是clk_en。这样处理可以让三行数据的起始保持同步。
//sync row3_data with per_frame_clken & row1_data & raw2_data
wire row1_data; //frame data of the 1th row
wire row2_data; //frame data of the 2th row
reg row3_data; //frame data of the 3th row
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
row3_data <= 0;
else
begin
if(per_frame_clken)
row3_data <= per_img_Bit;
else
row3_data <= row3_data;
end
end
调用我们上面配置好的IP核
wire shift_clk_en = per_frame_clken;
shift_ram_1bit1 shift_ram_1bit_1(
.D (row3_data ), // input wire [0 : 0] D
.CLK (clk ), // input wire CLK
.CE (per_frame_clken ), // input wire CE
//.SCLR (~rst_n ), // input wire SCLR
.Q (row2_data ) // output wire [0 : 0] Q
);
shift_ram_1bit1 shift_ram_1bit_2(
.D (row2_data ), // input wire [0 : 0] D
.CLK (clk ), // input wire CLK
.CE (per_frame_clken ), // input wire CE
//.SCLR (~rst_n ), // input wire SCLR
.Q (row1_data ) // output wire [0 : 0] Q
);
reg[1:0] frame_vsync_r;
reg[1:0] frame_href_r;
reg[1:0] frame_clken_r;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin
frame_vsync_r <=0;
frame_href_r <=0;
frame_clken_r <=0;
end
else
begin
frame_vsync_r <={frame_vsync_r [0],per_frame_vsync};
frame_href_r <={frame_href_r [0],per_frame_href};
frame_clken_r <={frame_clken_r [0],per_frame_href};
end
//lag clocks make sure signals sync
wire read_frame_href = per_frame_href_r[0]; //RAM read href sync signal
wire read_frame_clken = per_frame_clken_r[0]; //RAM read enable说了这么多,终于要到矩阵生成的部分了,在这里我们需要注意一下,生成的矩阵和我们放在移位寄存器中的数据的位置的关系。
---------- Convert Matrix ----------
[ P31 -> P32 -> P33 -> ] ---> [ P11 P12 P13 ]
[ P21 -> P22 -> P23 -> ] ---> [ P21 P22 P23 ]
[ P11 -> P12 -> P11 -> ] ---> [ P31 P32 P33 ]
//generate the correct matrix
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
{matrix_p11, matrix_p12, matrix_p13} <= 3'b0;
{matrix_p21, matrix_p22, matrix_p23} <= 3'b0;
{matrix_p31, matrix_p32, matrix_p33} <= 3'b0;
end
else if(read_frame_href) begin
if(read_frame_clken) //Shift_RAM data read clock enable
begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data};
end
else
begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
else
begin
{matrix_p11, matrix_p12, matrix_p13} <= 3'b0;
{matrix_p21, matrix_p22, matrix_p23} <= 3'b0;
{matrix_p31, matrix_p32, matrix_p33} <= 3'b0;
end
end
这样是一个非常简单的产生3*3矩阵的方式,但是也不难看出,这个设计是偷懒了的。按照这个方案,图片的前两行数据在进入Shift-RAM是也会产生3*3的矩阵,但是这是不对的,并且每行的前两个数据也会产生错误3*3的矩阵。但是为了算法的简便性暂时牺牲掉这点细节。
//lag 2 clocks for sync
assign matrix_frame_vsync = per_frame_vsync_r[1];
assign matrix_frame_href = per_frame_href_r[1];
assign matrix_frame_clken = per_frame_clken_r[1];我们在将数据寄存至Shift-RAM时,数据慢了一个时钟。在将数据放进3*3矩阵的寄存器时,数据又慢了一个时钟,所以在这里打两拍保证数据和控制信号的同步。
endmodule
到此为止,图像处理常用两个工具模块我们已经设计完成了
下一步我们进行腐蚀模块的设计