机器学习实战(4)——训练模型
目录
1 线性回归
2 标准方程
3 复杂度
4 梯度下降
5 批量梯度下降
6 随机梯度下降
7 小批量梯度下降
8 多项式回归
9 学习曲线
10 正则线性模型
10.1 岭回归
10.2 套索回归
10.3 弹性网络
10.4 早期停止法
10.5 逻辑回归
10.5.1 概率估算
10.5.2 训练和成本函数
10.5.3 决策边界
11 Softmax回归
1 线性回归
概括来说,线性模型就是对输入特征加权求和,再加上一个我们称为偏置项(或截距项)的常数,以此进行预测。
线性回归模型预测:

向量化形式表达如下:

训练模型就是设置模型参数直到模型最适应训练集的过程。达到这个目的,我们需要知道怎么衡量模型对训练数据的拟合程度是好还是差,最常见的性能指标是均方根误差(RMSE),因此,在训练线性模型时,我们需要找到最小化 RMSE 的 ![]() 值。在实践中,将均方误差(MSE)最小化比均方根误差(RMSE)更为简单,且二者效果相同。
值。在实践中,将均方误差(MSE)最小化比均方根误差(RMSE)更为简单,且二者效果相同。
线性回归模型的MSE成本函数:
为假设函数,这些符号中与之前我们提到过的唯一区别就是
)。后面,我们为了简化,直接将该函数写成MSE(
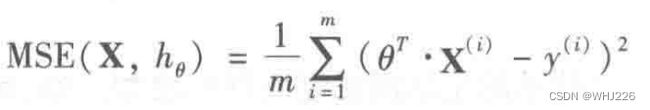
2 标准方程
为了得到使成本函数最小的![]() 值,有一个闭式求解法—— 一个直接解出结果的数学方程,即标准方程。
值,有一个闭式求解法—— 一个直接解出结果的数学方程,即标准方程。
标准方程:
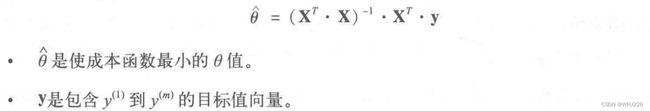
举个例子:
常规模块的导入以及图像可视化的设置:
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
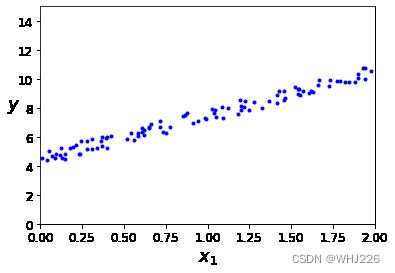
mpl.rc('ytick', labelsize=12)我们生成一些线性数据:
import numpy as np
X = 2 * np.random.rand(100,1)
y = 4 + 3 * X + np.random.rand(100,1)数据可视化:
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()运行结果如下:
现在我们使用标准方程来计算 ![]() 。使用NumPy的线性代数模块(np.linalg)中的 inv() 函数对矩阵求逆,并用 dot() 方法计算矩阵的内积:
。使用NumPy的线性代数模块(np.linalg)中的 inv() 函数对矩阵求逆,并用 dot() 方法计算矩阵的内积:
X_b = np.c_[np.ones((100,1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) #标准方程求解
theta_best运行结果如下:
array([[4.51359766],
[2.98323418]])这里我们讲一下np.c_和np.r_
np.c_[]可以拼接多个数组,要求待拼接的多个数组的行数必须相同。
np.r_[]可以拼接多个数组,要求待拼接的多个数组的列数必须相同
我们实际用来生成数据的函数应是![]() 高斯噪声。因此我们期待的是
高斯噪声。因此我们期待的是 ![]() ,
,![]() ,但噪声的存在使其不可能完全还原为原本的函数。
,但噪声的存在使其不可能完全还原为原本的函数。
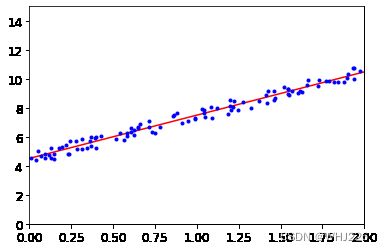
我们用 ![]() 做出预测:
做出预测:
X_new = np.array([[0],[2]])
X_new_b = np.c_[np.ones((2,1)), X_new]
y_predict = X_new_b.dot(theta_best)
y_predict运行结果如下:
array([[ 4.51359766],
[10.48006601]])绘制模型预测结果:
plt.plot(X_new , y_predict, "r-")
plt.plot(X, y, "b.")
plt.axis([0, 2, 0, 15])
plt.show()运行结果如下:
拓展:Scikit-Learn的等效代码如下:
Scikit-Learn将偏置项(intercept_)和特征权重(coef_)分类开了。
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) lin_reg.intercept_, lin_reg.coef_运行结果如下:
(array([4.51359766]), array([[2.98323418]]))lin_reg.predict(X_new)运行结果如下:
array([[ 4.51359766], [10.48006601]])
3 复杂度
标准方程求逆的矩阵![]() ,是一个n×n矩阵(n是特征数量)。对这种矩阵求逆的计算复杂度通常为
,是一个n×n矩阵(n是特征数量)。对这种矩阵求逆的计算复杂度通常为![]() 到
到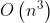 之间。如果特征数量翻倍,那么计算时间将乘以大约
之间。如果特征数量翻倍,那么计算时间将乘以大约![]() 倍到
倍到![]() 倍之间。
倍之间。
幸运的是,相对于训练集中的实例数量来说,方程是线性的,所以能够有效的处理大量的训练集,只要内存足够。同样,线性回归模型一经训练(不论是标准方程还是其他算法),预测就非常快速。
4 梯度下降
梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使成本函数最小化。梯度下降的做法:通过测量参数向量  相关的误差函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为0,到达最小值。具体来说,首先使用一个随机的 值(随机初始化),然后逐步改进,每次踏出一步,每一步都尝试降低一点成本函数,直到算法收敛出一个最小值,如下图。
相关的误差函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为0,到达最小值。具体来说,首先使用一个随机的 值(随机初始化),然后逐步改进,每次踏出一步,每一步都尝试降低一点成本函数,直到算法收敛出一个最小值,如下图。
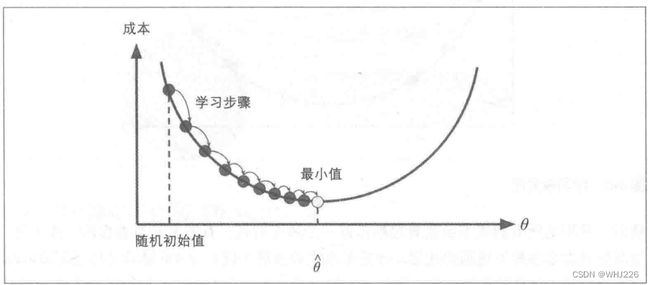
梯度下降中一个重要参数是每一步的步长,这取决于超参数的学习率。如果学习率太低,算法需要经过大量的迭代才能收敛。如果学习率太高,导致算法发散,值越来越大,最后无法找到最好的解决方案。
 学习率太低
学习率太低 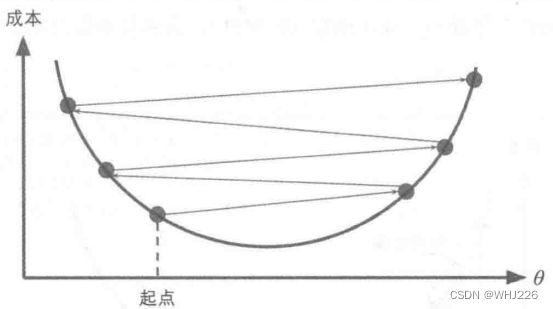 学习率太高
学习率太高
梯度下降的挑战:如果随机初始化,算法从左侧起步,那么会收敛到一个局部最小值,而不是全局最小值;如果算法从右侧起步,那么需要经过很长时间才能越过山谷,如果停下得太早,可能永远达不到全局最小值。
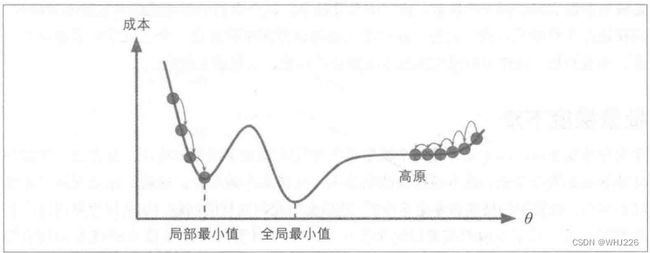 梯度下降挑战
梯度下降挑战
幸运的是,线性回归模型的MSE成本函数恰好是个凸函数,这意味着连接曲线上任意两个点的线段永远不会跟曲线相交,也就是说不存在局部最小,只有一个全局最优值。同时,它是一个连续函数,所以斜率不会产生陡峭的变化。结论就是:即便乱走,梯度下降都可以趋近到全局最小值。
下图所示的梯度下降很好地体现了不同特征尺寸差别,左边的训练集上特征1和特征2具有相同的数值规模,而右边的训练集上,特征1的值比特征2要小得多。(因为特征1的值比较小,所以  需要更大的变化来影响成本函数,这就是为什么碗形会沿着 轴拉长)。我们在应用梯度下降时,通过归一化和标准化处理可以保证所有特征值的大小比例都差不多。
需要更大的变化来影响成本函数,这就是为什么碗形会沿着 轴拉长)。我们在应用梯度下降时,通过归一化和标准化处理可以保证所有特征值的大小比例都差不多。
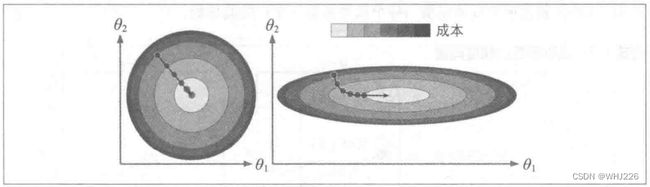 特征值缩放和特征值无缩放的梯度下降
特征值缩放和特征值无缩放的梯度下降
5 批量梯度下降
要实现梯度下降,我们需要计算每个模型关于参数 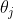 的成本函数的梯度。换言之,我们需要计算的是如果改变 ,成本函数会改变多少,这也被称为偏导数。关于参数 的成本函数的偏导数,记作
的成本函数的梯度。换言之,我们需要计算的是如果改变 ,成本函数会改变多少,这也被称为偏导数。关于参数 的成本函数的偏导数,记作![]() 。
。
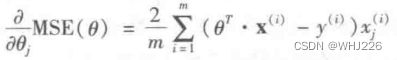 成本函数的偏导数公式
成本函数的偏导数公式
如果不想单独计算这些梯度,可以使用下面的公式对其进行一次性计算。梯度向量,记作![]() ,包含所有成本函数的偏导数。
,包含所有成本函数的偏导数。
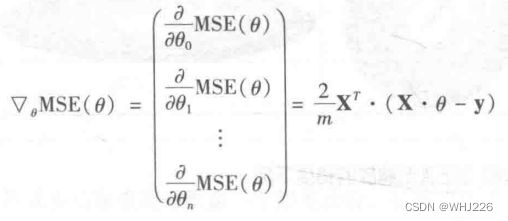 成本函数的梯度向量
成本函数的梯度向量
有了梯度向量,哪个点向上,就朝反方向下坡。也就是从 ![]() 中减去
中减去 ![]() 。这时学习率
。这时学习率 ![]() 就发挥作用了,用梯度向量乘以
就发挥作用了,用梯度向量乘以 ![]() 确定下坡步长的大小。
确定下坡步长的大小。
那么算法该如何实现:
eta = 0.1 #学习率
n_iterations = 1000
m = 100
theta = np.random.randn(2,1) #random initialization,2和1分别代表行和列
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
theta运行结果如下:
array([[4.51359766],
[2.98323418]])与标准方程结果一样。这里我们学习率设置的是0.1,如果学习率不同会有什么表现呢?
theta_path_bgd = []
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.plot(X, y, "b.")
n_iterations = 1000
for iteration in range(n_iterations):
if iteration < 10:
y_predict = X_new_b.dot(theta)
style = "b-" if iteration > 0 else "r--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
if theta_path is not None:
theta_path.append(theta)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 2, 0, 15])
plt.title(r"$\eta = {}$".format(eta), fontsize=16)
np.random.seed(42)
theta = np.random.randn(2,1) # random initialization
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(theta, eta=0.02)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd)
plt.subplot(133); plot_gradient_descent(theta, eta=0.5)
plt.show()运行结果如下:
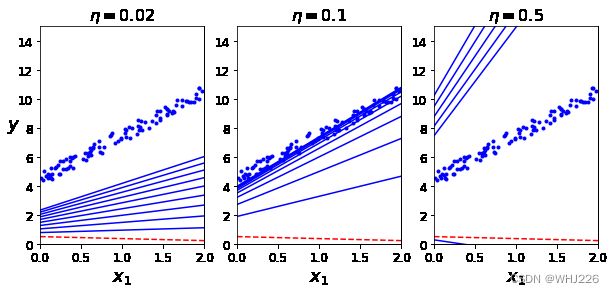 不同学习率的梯度下降
不同学习率的梯度下降
图中结果为梯度下降的前10步(虚线表示起点)。左图的学习率太低,算法最终能找到解决方法,耗时长;中间的学习率几次迭代就收敛出最终解;右边学习率太高,算法发散,并且每一步都离实际解决方案越来越远。
要找到合适的学习率,可是使用网格搜索,但是需要限制迭代次数,这样可以淘汰收敛耗时较长的模型。那么迭代次数怎么设置呢?一个简单的办法是,在开始时设置一个非常大的迭代次数,但是当梯度向量的值变得很微小时中断算法——也就是当它的范数变得低于  (容差)时,因为这时梯度下降已经(几乎)达到最小值。
(容差)时,因为这时梯度下降已经(几乎)达到最小值。
6 随机梯度下降
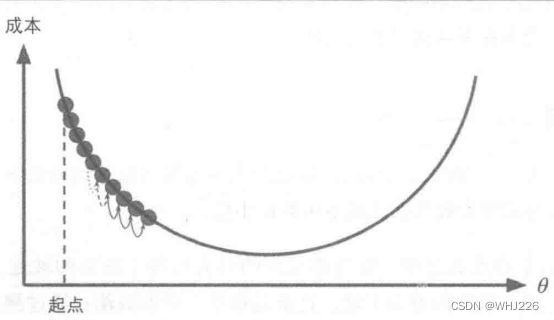
批量梯度下降的主要问题是它用于整个训练集来计算每一步的梯度,所以训练集很大时,算法特别慢。与之相反,随机梯度下降,每一步在训练集中随机选择一个实例,并且仅基于该单个实例来计算梯度。另一方面,由于算法的随机性质,它比批量梯度下降要不规则的多。成本函数将不再是缓缓降低直到最小值,而是不断上上下下。但是从整体来看,还是在缓慢下降。但是即使它达到最小值依旧还会持续反弹,永远不会停止,所以算法停下来的参数值肯定是足够好的,但不是最优的。
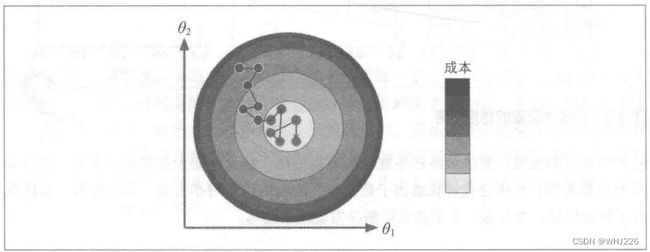 随机梯度下降
随机梯度下降
随机性的好处在于可以逃离局部最优,但缺点是永远定位不出最小值。我们可以通过逐步降低学习率来解决。开始步长比较大(有助于加快进展和逃离局部最小值),然后步长越来越小,让算法尽量靠近全局最小值。
下面使用一个简单的学习计划实现随机梯度下降:
theta_path_sgd = []
m = len(X_b)
np.random.seed(42)
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t): #定义学习率函数
return t0 / (t + t1)
theta = np.random.randn(2,1) # random initialization
for epoch in range(n_epochs):
for i in range(m):
if epoch == 0 and i < 20:
y_predict = X_new_b.dot(theta)
style = "b-" if i > 0 else "r--"
plt.plot(X_new, y_predict, style)
random_index = np.random.randint(m) #随机选择一个实例
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients
theta_path_sgd.append(theta)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show() 运行结果如下:
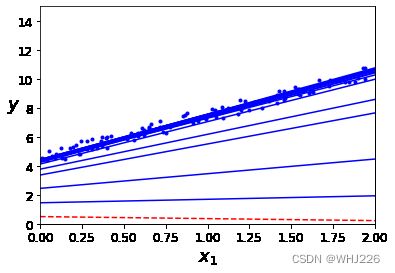 随机梯度下降的前10步
随机梯度下降的前10步
m表迭代次数,这段代码迭代了50次就得到了一个相当不错的解。
thetaarray([[4.51548062],
[2.9775157 ]])在 Scikit-Learn里,用SGD执行线性回归可以使用SGDRegressor类,其默认优化的成本函数是平方误差。下面这段代码从学习率0.1开始,使用默认的学习计划运行了50轮,而且没有使用任何正则化(penalty = None):
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter = 50, penalty = None, eta0 = 0.1)
sgd_reg.fit(X,y.ravel())我们会再次得到一个跟标准方程的解非常相近的解决方案:
sgd_reg.intercept_, sgd_reg.coef_运行结果如下:
(array([4.49695399]), array([2.98441378]))7 小批量梯度下降
每一步的梯度计算,既不是基于整个训练集(批量梯度下降)也不是基于单个实例(如随机梯度下降),而是基于一小部分随机的实例集也就是小批量。相比随机梯度下降,小批量梯度下降的主要优势在于可以从矩阵运算的硬件优化中获得显著的性能提升,特别是需要用到图形处理器时。这个算法在参数空间层面的前进过程也不想SGD那样稳定,特别是批量较大时。所以小批量梯度下降最终会比SGD更接近最小值些。但是另一方面,它可能更难从局部最小值中逃脱(对于那些深受局部最小值陷阱困扰的问题)。
下图显示了三种梯度下降算法在训练过程中参数空间里的行进路线。它们最终都汇聚在最小值附近,批量梯度下降最终停在了最小值上,而随机梯度下降和小批量梯度下降还在继续游走。但是,批量梯度下降花费了大量时间计算每一步,而随机梯度下降和小批量梯度下降也同样能达到最小值。
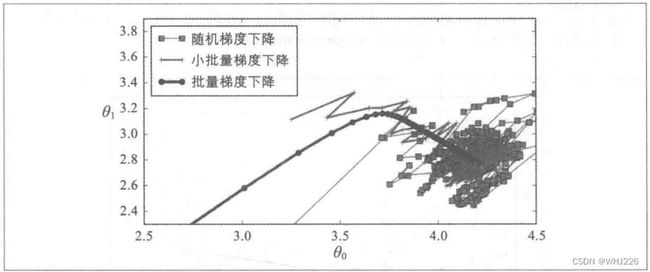 梯度下降的参数路径
梯度下降的参数路径
代码实现:
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
np.random.seed(42)
theta = np.random.randn(2,1) # random initialization
t0, t1 = 200, 1000
def learning_schedule(t):
return t0 / (t + t1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = np.random.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size):
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(t)
theta = theta - eta * gradients
theta_path_mgd.append(theta)
theta_path_bgd = np.array(theta_path_bgd)
theta_path_sgd = np.array(theta_path_sgd)
theta_path_mgd = np.array(theta_path_mgd)
plt.figure(figsize=(7,4))
plt.plot(theta_path_sgd[:, 0], theta_path_sgd[:, 1], "r-s", linewidth=1, label="Stochastic")
plt.plot(theta_path_mgd[:, 0], theta_path_mgd[:, 1], "g-+", linewidth=2, label="Mini-batch")
plt.plot(theta_path_bgd[:, 0], theta_path_bgd[:, 1], "b-o", linewidth=3, label="Batch")
plt.legend(loc="upper left", fontsize=16)
plt.xlabel(r"$\theta_0$", fontsize=20)
plt.ylabel(r"$\theta_1$ ", fontsize=20, rotation=0)
plt.axis([2.5, 4.5, 2.3, 3.9])
plt.show()运行结果如下:
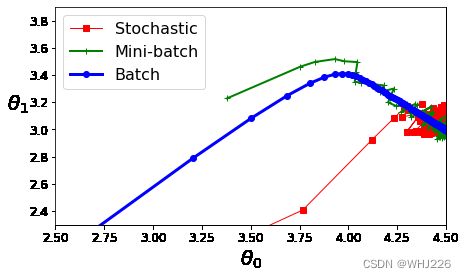
我们比较一下这些线性回归算法(m是训练实例的数量,n是特征数量):
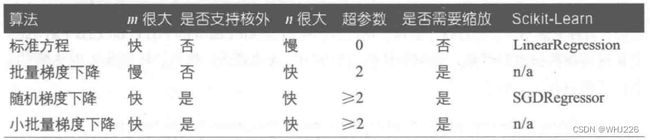 线性回归算法比较
线性回归算法比较
训练后的模型几乎无差别,所有这些算法最后出来的模型都非常相似,并且以完全相同的方式做出预测。
8 多项式回归
如果数据比简单的直线更为复杂,我们可以用线性模型来拟合非线性数据。一个简单的方法就是将每个特征的幂次方添加一个新特征,然后再这个拓展过的特征集上训练线性模型。这种方法称为多项式回归。
我们先看个简单的例子,基于简单的二次方程制造一些非线性数据(添加随机噪声)。
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X**2 + X + 2 + np.random.rand(m, 1)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([-3, 3, 0, 10])
plt.show()运行结果如下:
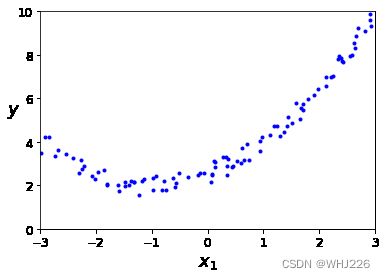
很显然,直线永远不可能拟合这个数据。因此我们使用Scikit-Learn的 PolynomialFeatures 类来对训练数据进行转换,将每个特征的平方(二次多项式)作为新特征加入训练集(这个例子中只有一个特征):
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias = False)
X_poly = poly_features.fit_transform(X)
X[0]运行结果如下:
array([2.38942838])X_poly[0]运行结果如下:
array([2.38942838, 5.709368 ])X_poly包含原本的特征和该特征的平方。现在训练模型:
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
lin_reg.intercept_, lin_reg.coef_运行结果如下:
(array([2.5278938]), array([[0.9804785 , 0.49468385]]))原本的函数是![]() 高斯噪声,模型预估
高斯噪声,模型预估![]() 。
。
可视化:
X_new=np.linspace(-3, 3, 100).reshape(100, 1)
X_new_poly = poly_features.transform(X_new)
y_new = lin_reg.predict(X_new_poly)
plt.plot(X, y, "b.")
plt.plot(X_new, y_new, "r-", linewidth=2, label="Predictions")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.legend(loc="upper left", fontsize=14)
plt.axis([-3, 3, 0, 10])
plt.show()运行结果如下:
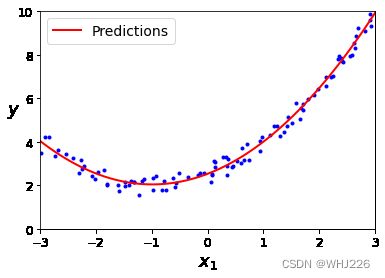
注意:当存在多个特征时,多项式回归能够发现特征和特征之间的关系(纯线性回归模型做不到)。因为 PolynomialFeatures 会在给定的多项式阶数下,添加所有特征组合。例如,有两个特征 ![]() 和
和 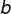 ,阶数degree = 3, PolynomialFeatures不会只添加特征
,阶数degree = 3, PolynomialFeatures不会只添加特征 ![]() ,还会添加组合
,还会添加组合![]() 。(PolynomialFeatures(degree = d)可以将一个包含n个特征的数组转换为包含
。(PolynomialFeatures(degree = d)可以将一个包含n个特征的数组转换为包含![]() 个特征的数组)
个特征的数组)
9 学习曲线
高阶多项式回归对训练数据的拟合,很可能会比简单线性回归要好。
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
for style, width, degree in (("g-", 1, 300), ("b--", 2, 2), ("r-+", 2, 1)):
polybig_features = PolynomialFeatures(degree=degree, include_bias=False)
std_scaler = StandardScaler()
lin_reg = LinearRegression()
polynomial_regression = Pipeline([
("poly_features", polybig_features),
("std_scaler", std_scaler),
("lin_reg", lin_reg),
])
polynomial_regression.fit(X, y)
y_newbig = polynomial_regression.predict(X_new)
plt.plot(X_new, y_newbig, style, label=str(degree), linewidth=width)
plt.plot(X, y, "b.", linewidth=3)
plt.legend(loc="upper left")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([-3, 3, 0, 10])
plt.show()运行结果如下:
上图使用了一个300阶多项式模型来处理训练数据,并将结果与一个纯线性模型和一个二次模型进行对比。从图像结果看,高阶多项式回归模型严重地过度拟合了训练数据,而线性模型则是拟合不足。那么一般我们怎么判断模型的复杂程度,怎么判断过度拟合还是拟合不足?
注意:有关Pipeline的解释推荐以下两位博主的博客:
sklearn 中的 Pipeline 机制_五道口纳什的博客-CSDN博客_pipeline sklearn
学习笔记:Sklearn中Pipeline的使用_YXR11111的博客-CSDN博客
一种方法是观察学习曲线:这个曲线绘制的是模型在训练集和验证集上,关于“训练集大小”的性能函数。要生成这个曲线,只需要在不同大小的训练子集上多次训练模型即可。
下面通过在给定训练集下定义一个函数,绘制模型的学习曲线:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=10)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Training set size", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
lin_reg = LinearRegression()
plot_learning_curves(lin_reg, X, y)
plt.axis([0, 80, 0, 3])
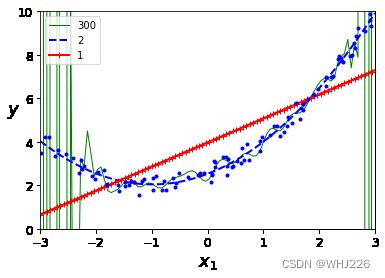
plt.show() 运行结果如下:
 纯线性回归模型学习曲线
纯线性回归模型学习曲线
我们来看一下训练数据上的性能:当训练集中只包括一两个实例时,模型可以完美拟合,这也是为什么曲线是从0开始的。但是,随着新的实例被添加进训练集中,模型不再能完美拟合训练数据了,因为数据有噪声,并且根本就不是线性的。所以训练集的误差一路上升,直到抵达一个高地,从这一点开始,添加新实例到训练集中不再使平均误差上升或下降。我们再来看看验证集的性能表现,当训练集实例非常少时,模型不能很好的泛化,这是为什么验证集误差的值一开始非常大,随着模型经历更多的训练数据,它开始学习,因此误差慢慢下降。
这条学习曲线是典型的模型拟合不足。两条曲线均到达高地,而且非常接近,相当高。(注意:如果我们的模型对训练数据拟合不足,即使添加更多训练实例也于事无补。这时需要使用更复杂的模型或者找到更好的特征)
现在我们再来看看在同样的数据集上,一个10阶多项式模型的学习曲线:
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("lin_reg", LinearRegression()),
])
plot_learning_curves(polynomial_regression, X, y)
plt.axis([0, 80, 0, 3])
plt.show()运行结果如下:
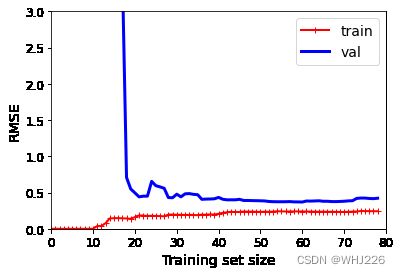 多项式回归模型的学习曲线
多项式回归模型的学习曲线
与前一条学习曲线差不多,但是有两个非常重大的区别:
- 训练数据的误差远低于线性回归模型。
- 两条曲线之间有一定的差距。则意味着该模型在训练数据上的表现比验证集上要好很多,这正是过度拟合的标志。如果,我们使用更大的训练集,这两条曲线将会越来越近。
改进模型过度拟合的方法之一是提供更多的训练数据,直到验证误差接近训练误差。
拓展:
偏差/方差权衡
模型的泛化误差可以被表示为三个截然不同的误差之和:
偏差
这部分泛化误差的原因在于错误的假设,比如我们假设数据是线性的,而实际上是二次的。
方差
这部分误差是由于模型对训练数据的微小变化过度敏感导致的。具有高自由度的模型(例如高阶多项式模型)可能有高方差,所以很容易对训练数据过度拟合。
不可避免的误差
数据本身的噪声导致,清理数据即可减少该误差。
增加模型的复杂度通常会显著提升模型的方差,减少偏差,反之,降低模型的复杂度则会提升模型的偏差,降低方差。
10 正则线性模型
减少过度拟合的一个好办法就是对模型正则化(约束):模型拥有的自由度越低,就越不容易过度拟合数据。
10.1 岭回归
岭回归(也叫作吉洪诺夫正则化):在成本函数中添加一个等于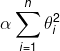 的正则项。这使得学习中的算法不仅需要拟合数据,同时还要让模型权重保持最小。注意:正则项只能在训练的时候添加到成本函数中,一旦训练完成,我们需要使用未经正则化的性能指标来评估模型性能。(除了正则化之外,因为训练时的成本函数通常都可以使用优化过的衍生函数,而测试用的性能指标需要尽可能接近最终目标)
的正则项。这使得学习中的算法不仅需要拟合数据,同时还要让模型权重保持最小。注意:正则项只能在训练的时候添加到成本函数中,一旦训练完成,我们需要使用未经正则化的性能指标来评估模型性能。(除了正则化之外,因为训练时的成本函数通常都可以使用优化过的衍生函数,而测试用的性能指标需要尽可能接近最终目标)
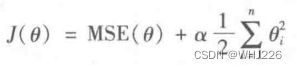 岭回归成本函数
岭回归成本函数
超参数 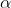 控制的是对模型进行正则化的程度。
控制的是对模型进行正则化的程度。
注意,这里偏置项 ![]() 没有正则化(求和是从 i=1 开始)。如果我们将 w 定义为特征权重的向量(
没有正则化(求和是从 i=1 开始)。如果我们将 w 定义为特征权重的向量(![]() ), 那么正则项即等于
), 那么正则项即等于![]() ,其中
,其中 ![]() 为权重向量的
为权重向量的 ![]() 范数,对于梯度下降,只需要在MSE梯度向量上添加
范数,对于梯度下降,只需要在MSE梯度向量上添加 ![]() 即可。
即可。
在执行岭回归之前,必须对数据进行缩放(例如使用StandardScaler),因为它对输入特征的大小非常敏感。
from sklearn.linear_model import Ridge
np.random.seed(42)
m = 20
X = 3 * np.random.rand(m, 1)
y = 1 + 0.5 * X + np.random.randn(m, 1) / 1.5
X_new = np.linspace(0, 3, 100).reshape(100, 1)
def plot_model(model_class, polynomial, alphas, **model_kargs):
for alpha, style in zip(alphas, ("b-", "g--", "r:")):
model = model_class(alpha, **model_kargs) if alpha > 0 else LinearRegression()
if polynomial:
model = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("std_scaler", StandardScaler()),
("regul_reg", model),
])
model.fit(X, y)
y_new_regul = model.predict(X_new)
lw = 2 if alpha > 0 else 1
plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$\alpha = {}$".format(alpha))
plt.plot(X, y, "b.", linewidth=3)
plt.legend(loc="upper left", fontsize=15)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 3, 0, 4])
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Ridge, polynomial=False, alphas=(0, 10, 100), random_state=42)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Ridge, polynomial=True, alphas=(0, 10**-5, 1), random_state=42)
plt.show()运行结果如下:
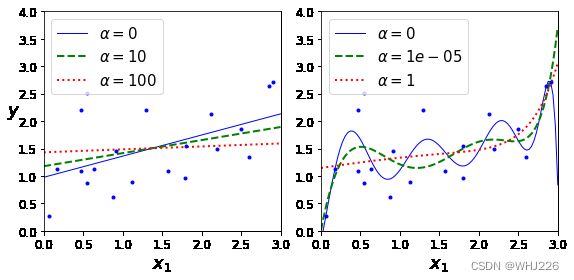
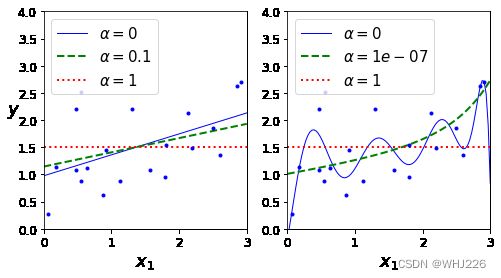
上图显示了使用不同 值对某个线性数据进行训练的几种岭回归模型。左边直接使用岭回归,导致预测是线性的,而右边,首先使用PolynomiaFeatures(degree=10)对数据进行扩展,然后使用StandardScaler进行缩放,最后再将岭回归模型用于结果特征:即岭正则化后的多项式回归。
与线性回归一样,我们也可以在计算闭式方程或者执行梯度下降时,执行岭回归。
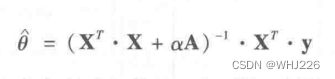 闭式解的岭回归
闭式解的岭回归
其中,A是一个n×n的单位矩阵。
看不懂上面代码中岭回归的执行可以看下面的代码:
下面展示如何使用 Scikit-Learn执行闭式解的岭回归(利用矩阵因式分解法):
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)
ridge_reg.predict([[1.5]])运行结果如下:
array([[1.55071465]])使用随机梯度下降:
sgd_reg = SGDRegressor(penalty="l2")
sgd_reg.fit(X, y.ravel())
sgd_reg.predict([[1.5]])运行结果如下:
array([1.46543286])超参数penalty设置的是使用正则项的类型。设为“l2”表示希望SGD在成本函数中添加一个正则项,等于权重向量的l2范数的平方的一半,即岭回归。
10.2 套索回归
线性回归的而另一种正则化,叫做最小绝对收缩和选择算子回归(Least Absolute Shrinkage and Selection Operator Regression, 简称Lasso回归)。与岭回归一样,也是向成本函数中添加正则项,但是它增加的是权重向量的l1范数,而不是l2范数的平方的一半。
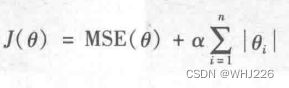
from sklearn.linear_model import Lasso
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Lasso, polynomial=False, alphas=(0, 0.1, 1), random_state=42)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Lasso, polynomial=True, alphas=(0, 10**-7, 1), tol=1, random_state=42)
plt.show()运行结果如下:
Lasso回归的一个重要特点是它倾向于完全消除掉最不重要特征的权重。换句话说,Lasso回归会自动执行特征选择并输出一个稀疏模型(即只有很少的特征有非零权重)。
t1a, t1b, t2a, t2b = -1, 3, -1.5, 1.5
# ignoring bias term
t1s = np.linspace(t1a, t1b, 500)
t2s = np.linspace(t2a, t2b, 500)
t1, t2 = np.meshgrid(t1s, t2s)
T = np.c_[t1.ravel(), t2.ravel()]
Xr = np.array([[-1, 1], [-0.3, -1], [1, 0.1]])
yr = 2 * Xr[:, :1] + 0.5 * Xr[:, 1:]
J = (1/len(Xr) * np.sum((T.dot(Xr.T) - yr.T)**2, axis=1)).reshape(t1.shape)
N1 = np.linalg.norm(T, ord=1, axis=1).reshape(t1.shape)
N2 = np.linalg.norm(T, ord=2, axis=1).reshape(t1.shape)
t_min_idx = np.unravel_index(np.argmin(J), J.shape)
t1_min, t2_min = t1[t_min_idx], t2[t_min_idx]
t_init = np.array([[0.25], [-1]])
def bgd_path(theta, X, y, l1, l2, core = 1, eta = 0.1, n_iterations = 50):
path = [theta]
for iteration in range(n_iterations):
gradients = core * 2/len(X) * X.T.dot(X.dot(theta) - y) + l1 * np.sign(theta) + 2 * l2 * theta
theta = theta - eta * gradients
path.append(theta)
return np.array(path)
plt.figure(figsize=(12, 8))
for i, N, l1, l2, title in ((0, N1, 0.5, 0, "Lasso"), (1, N2, 0, 0.1, "Ridge")):
JR = J + l1 * N1 + l2 * N2**2
tr_min_idx = np.unravel_index(np.argmin(JR), JR.shape)
t1r_min, t2r_min = t1[tr_min_idx], t2[tr_min_idx]
levelsJ=(np.exp(np.linspace(0, 1, 20)) - 1) * (np.max(J) - np.min(J)) + np.min(J)
levelsJR=(np.exp(np.linspace(0, 1, 20)) - 1) * (np.max(JR) - np.min(JR)) + np.min(JR)
levelsN=np.linspace(0, np.max(N), 10)
path_J = bgd_path(t_init, Xr, yr, l1=0, l2=0)
path_JR = bgd_path(t_init, Xr, yr, l1, l2)
path_N = bgd_path(t_init, Xr, yr, np.sign(l1)/3, np.sign(l2), core=0)
plt.subplot(221 + i * 2)
plt.grid(True)
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
plt.contourf(t1, t2, J, levels=levelsJ, alpha=0.9)
plt.contour(t1, t2, N, levels=levelsN)
plt.plot(path_J[:, 0], path_J[:, 1], "w-o")
plt.plot(path_N[:, 0], path_N[:, 1], "y-^")
plt.plot(t1_min, t2_min, "rs")
plt.title(r"$\ell_{}$ penalty".format(i + 1), fontsize=16)
plt.axis([t1a, t1b, t2a, t2b])
if i == 1:
plt.xlabel(r"$\theta_1$", fontsize=20)
plt.ylabel(r"$\theta_2$", fontsize=20, rotation=0)
plt.subplot(222 + i * 2)
plt.grid(True)
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
plt.contourf(t1, t2, JR, levels=levelsJR, alpha=0.9)
plt.plot(path_JR[:, 0], path_JR[:, 1], "w-o")
plt.plot(t1r_min, t2r_min, "rs")
plt.title(title, fontsize=16)
plt.axis([t1a, t1b, t2a, t2b])
if i == 1:
plt.xlabel(r"$\theta_1$", fontsize=20)
plt.show()运行结果如下:
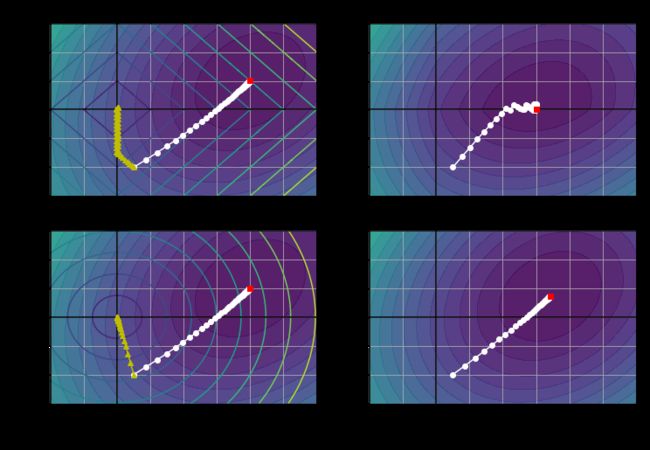 Lasso回归与岭回归
Lasso回归与岭回归
在左上图中,背景轮廓(椭圆)表示未经正则化的MSE成本函数(![]() ),白色圆点表示该成本函数下,批量梯度下降(BGD)的路径。背景轮廓(菱形)表示l1惩罚函数,黄色三角形表示该惩罚函数下,批量梯度下降的路径(
),白色圆点表示该成本函数下,批量梯度下降(BGD)的路径。背景轮廓(菱形)表示l1惩罚函数,黄色三角形表示该惩罚函数下,批量梯度下降的路径(![]() ) 。注意看这个路线是怎么走的,首先到达
) 。注意看这个路线是怎么走的,首先到达![]() ,然后一路沿轴滚动,直到
,然后一路沿轴滚动,直到![]() 。在右上图中,背景轮廓表示同样的成本函数加上一个
。在右上图中,背景轮廓表示同样的成本函数加上一个![]() 的l1惩罚函数。全局最小值位于
的l1惩罚函数。全局最小值位于![]() 轴上。批量梯度下降先是到达了
轴上。批量梯度下降先是到达了![]() ,再沿轴滚动到全局最小值。底部的两张图与上图的含义相同,但是把l1换成了l2惩罚函数。可以看出,正则化后的最小值虽然比未经正则化的最小值更接近于
,再沿轴滚动到全局最小值。底部的两张图与上图的含义相同,但是把l1换成了l2惩罚函数。可以看出,正则化后的最小值虽然比未经正则化的最小值更接近于![]() ,但是权重并没有完全被消除。(注意:在Lasso回归成本函数下,BGD最后的路线似乎在轴上不断上下反弹,这是因为当
,但是权重并没有完全被消除。(注意:在Lasso回归成本函数下,BGD最后的路线似乎在轴上不断上下反弹,这是因为当![]() 时,斜率突变。我们需要逐渐降低学习率来保证它向全局最小值收敛)
时,斜率突变。我们需要逐渐降低学习率来保证它向全局最小值收敛)
当![]() ,Lasso回归成本函数是不可微的,但是,当任意
,Lasso回归成本函数是不可微的,但是,当任意![]() 时,如果使用次梯度向量g(我们可以把不可微的点上的次梯度向量想象为这个点周围的梯度向量之间的中间矢量)作为替代,依旧可以让梯度下降正常运转。下面公式表示次梯度向量公式,可用于Lasso成本函数的梯度下降。
时,如果使用次梯度向量g(我们可以把不可微的点上的次梯度向量想象为这个点周围的梯度向量之间的中间矢量)作为替代,依旧可以让梯度下降正常运转。下面公式表示次梯度向量公式,可用于Lasso成本函数的梯度下降。
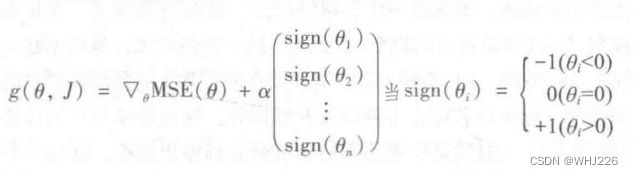 Lasso回归次梯度向量
Lasso回归次梯度向量
我们演示一个Lasso类的小例子:
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
lasso_reg.predict([[1.5]])运行结果如下:
array([1.53788174])10.3 弹性网络
弹性网络是岭回归与Lasso回归之间的中间地带。其正则项就是岭回归和Lasso回归的正则项的混合,混合比例通过r来控制。当r=0时,弹性网络等同于岭回归,当r=1时,弹性网络等同于Lasso回归。
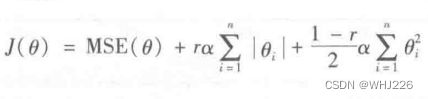
那么,到底如何选择线性回归、岭回归、 Lasso回归和弹性网络?大多数情况下,我们应该避免使用纯线性回归。岭回归是个不错的默认选择,但是如果实际用到的特征只有少数几个,就应该更倾向于 Lasso回归或者是弹性网络,因为他们会将无用特征的权重降为0。一般而言,弹性网络优于 Lasso回归,因为当特征数量超过训练实例数量,又或者是几个特征强相关时, Lasso回归的表现可能非常不稳定。
我们演示一个小例子:
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5, random_state=42)
elastic_net.fit(X, y)
elastic_net.predict([[1.5]])运行结果如下:
array([1.54333232])10.4 早期停止法
在验证误差达到最小值时停止训练,该方法叫作早期停止法。
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 2 + X + 0.5 * X**2 + np.random.randn(m, 1)
X_train, X_val, y_train, y_val = train_test_split(X[:50], y[:50].ravel(), test_size=0.5, random_state=10)
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler()),
])
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.transform(X_val)
sgd_reg = SGDRegressor(max_iter=1,
tol=-np.infty,
penalty=None,
eta0=0.0005,
warm_start=True,
learning_rate="constant",
random_state=42)
n_epochs = 500
train_errors, val_errors = [], []
for epoch in range(n_epochs):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_train_predict = sgd_reg.predict(X_train_poly_scaled)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
train_errors.append(mean_squared_error(y_train, y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
best_epoch = np.argmin(val_errors)
best_val_rmse = np.sqrt(val_errors[best_epoch])
plt.annotate('Best model',
xy=(best_epoch, best_val_rmse),
xytext=(best_epoch, best_val_rmse + 1),
ha="center",
arrowprops=dict(facecolor='black', shrink=0.05),
fontsize=16,
)
best_val_rmse -= 0.03 # just to make the graph look better
plt.plot([0, n_epochs], [best_val_rmse, best_val_rmse], "k:", linewidth=2)
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="Validation set")
plt.plot(np.sqrt(train_errors), "r--", linewidth=2, label="Training set")
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Epoch", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
plt.show()运行结果如下:
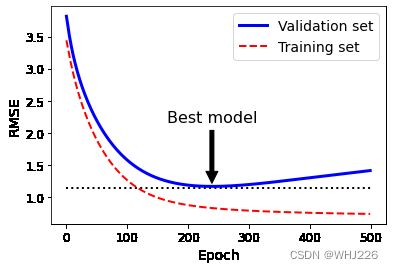 早期停止法正则化
早期停止法正则化
上图结果展现了一个用批量梯度下降训练的复杂模型(高阶多项式回归模型)。我们看到经过不断的学习,训练集上的预测误差(RMSE)自然不断下降,验证集上的预测误差也随之下降。但是,一段时间之后,验证误差停止下降开始上升,说明模型开始过度拟合训练数据。通过早期停止法,一旦验证误差达到最小值就立刻停止训练。
注意:对随机梯度下降和小批量梯度下降来说,曲线没有这么平滑,所以很难知道是否已经达到最小值。一种解决方法是等验证误差超过最小值一段时间之后再停止(这时我们可以确信模型不会变得更好了),然后将模型参数回滚到验证误差最小时的位置。
早期停止法的基本实现:
from sklearn.base import clone
sgd_reg = SGDRegressor(max_iter=1, warm_start=True, penalty=None,
learning_rate="constant", eta0=0.0005, random_state=42)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train) # continues where it left off
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predict)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg)
best_epoch, best_model运行结果如下:
(239,
SGDRegressor(eta0=0.0005, learning_rate='constant', max_iter=1, penalty=None,
random_state=42, warm_start=True))注意,当warm_start=True时,调用fit()方法,会从停下的地方继续开始训练。
10.5 逻辑回归
逻辑回归被广泛用于估算一个实例属于某个特定类别的概率。(比如,这封电子邮件属于垃圾邮件的概率是多少?)如果预估概率超过50%,则模型预测该实例属于该类别(称为正类,标记为“1”),反之,则预测不是(“负类”,标记为“0”)。
10.5.1 概率估算
跟线性回归模型一样,逻辑回归模型也是计算输入特征的加权和(加上偏置项),但是不同于线性回归模型直接输出结果,它输出的是结果的数理逻辑。
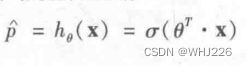 逻辑回归模型概率估算(向量化形式)
逻辑回归模型概率估算(向量化形式)
逻辑模型是一个sigmoid函数(s形),记作![]() , 它的输出为一个0到1之间的数字。
, 它的输出为一个0到1之间的数字。
 逻辑函数
逻辑函数
t = np.linspace(-10, 10, 100)
sig = 1 / (1 + np.exp(-t))
plt.figure(figsize=(9, 3))
plt.plot([-10, 10], [0, 0], "k-")
plt.plot([-10, 10], [0.5, 0.5], "k:")
plt.plot([-10, 10], [1, 1], "k:")
plt.plot([0, 0], [-1.1, 1.1], "k-")
plt.plot(t, sig, "b-", linewidth=2, label=r"$\sigma(t) = \frac{1}{1 + e^{-t}}$")
plt.xlabel("t")
plt.legend(loc="upper left", fontsize=20)
plt.axis([-10, 10, -0.1, 1.1])
plt.show()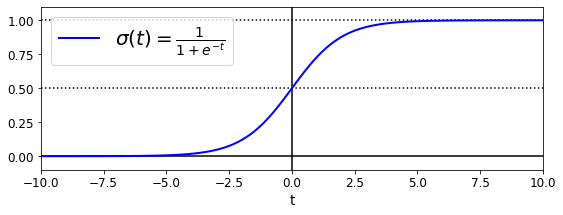 逻辑函数
逻辑函数
一旦逻辑回归模型估算出实例x属于正类的概率![]() ,就可以轻松做出预测
,就可以轻松做出预测![]() 。
。
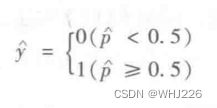 逻辑回归模型预测
逻辑回归模型预测
注意:当t<0时,![]() ;当t>=0时,
;当t>=0时,![]() 。所以如果
。所以如果![]() 是正类,逻辑回归模型预测结果是1,如果是负类,则预测为0。
是正类,逻辑回归模型预测结果是1,如果是负类,则预测为0。
10.5.2 训练和成本函数
训练的目的就是设置参数向量 ![]() ,使模型对正类实例做出高概率估算(y=1),对负类实例做出低概率估算(y=0)。让我们看一下单个训练实例的成本函数。
,使模型对正类实例做出高概率估算(y=1),对负类实例做出低概率估算(y=0)。让我们看一下单个训练实例的成本函数。
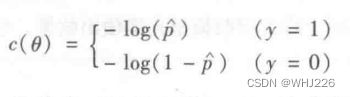 单个训练实例的成本函数
单个训练实例的成本函数
当t接近于0时,-log(t)会变得非常大,所以如果模型估算一个正类实例的概率接近于0,成本将会变得很高 。同理估算出一个负类实例的概率接近于1,成本也会很高。反过来,当t接近于1时,-log(t)接近于0,所以对一个负类实例估算出的概率接近于0,对一个正类实例估算出的概率接近于1,而成本则都接近于0。
整个训练集的成本函数即为所有训练实例的平均样本。它可以记成一个单独的表达式,这个函数被称为log损失函数。
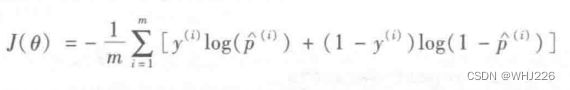 log损失函数
log损失函数
但是这个函数没有已知的闭式方程(不存在一个标准方程的等价方程)来计算出最小化成本函数的 ![]() 值。不过,这是个凸函数,可以通过梯度下降(或者优化算法)保证能够找出全局最小值。下面的公式给出了成本函数关于第 j 个模型参数
值。不过,这是个凸函数,可以通过梯度下降(或者优化算法)保证能够找出全局最小值。下面的公式给出了成本函数关于第 j 个模型参数 ![]() 的偏导数方程。
的偏导数方程。
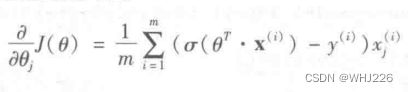
计算出每个实例的预测误差,并将其乘以第j个特征值,然后再对所有训练实例求平均值。一旦有了包括所有偏导数的梯度向量就可以使用梯度下降算法了。就是这样,现在知道如何训练逻辑模型了。对随机梯度下降,一次使用一个实例;对小批量梯度下降,一次使用一个小批量。
10.5.3 决策边界
这里我们使用自带的鸢尾花数据集来说明逻辑回归。
我们试试仅基于花瓣宽度这一个特征,创建一个分类器来检测Virginica鸢尾花。首先加载数据:
from sklearn import datasets
iris = datasets.load_iris()
X = iris["data"][:, 3:] # petal width
y = (iris["target"] == 2).astype(np.int) # 1 if Iris-Virginica, else 0训练逻辑回归模型:
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X, y)
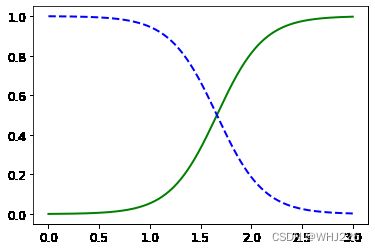
我们来看看对于花瓣宽度在0到3厘米之间的鸢尾花,模型估算出的概率。
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label="Iris-Virginica")
plt.plot(X_new, y_proba[:, 0], "b--", linewidth=2, label="Not Iris-Virginica")运行结果如下:
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
decision_boundary = X_new[y_proba[:, 1] >= 0.5][0]
plt.figure(figsize=(8, 3))
plt.plot(X[y==0], y[y==0], "bs")
plt.plot(X[y==1], y[y==1], "g^")
plt.plot([decision_boundary, decision_boundary], [-1, 2], "k:", linewidth=2)
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label="Iris-Virginica")
plt.plot(X_new, y_proba[:, 0], "b--", linewidth=2, label="Not Iris-Virginica")
plt.text(decision_boundary+0.02, 0.15, "Decision boundary", fontsize=14, color="k", ha="center")
plt.arrow(decision_boundary, 0.08, -0.3, 0, head_width=0.05, head_length=0.1, fc='b', ec='b')
plt.arrow(decision_boundary, 0.92, 0.3, 0, head_width=0.05, head_length=0.1, fc='g', ec='g')
plt.xlabel("Petal width (cm)", fontsize=14)
plt.ylabel("Probability", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 3, -0.02, 1.02])
plt.show()运行结果如下:
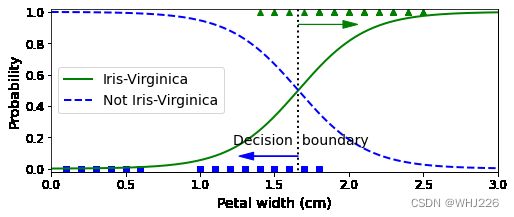
decision_boundary运行结果如下:
array([1.66066066])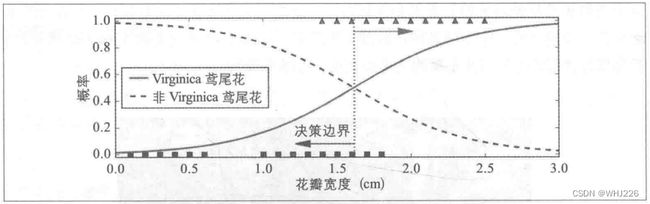 估算概率和决策边界
估算概率和决策边界
Virginica鸢尾花(三角形表示)的花瓣宽度范围为1.4~2.5厘米,而其他两种鸢尾花(正方形所示)花瓣通常较窄,花瓣宽度范围为0.1~1.8厘米。注意,这里有一部分是重叠的。对花瓣宽度超过2厘米的话,分类器可以很有信心地说它是一朵Virginica鸢尾花(对该类别输出一个高概率值),对花瓣宽度低于1厘米以下的,也可以有信心的说它不是(对“非Virginica鸢尾花”类输出一个高概率值)。在这个重叠部分,分类器把握则不是很大。但是,如果你要求它预测出类别(使用predict()方法而不是predict_proba()方法),它将可能返回一个可能性最大的类别。也就是说,在大约1.6厘米出存在一个决策边界,如果花瓣宽度大于1.6厘米,分类器就预测它是Virginica鸢尾花,否则不是。
log_reg.predict([[1.7], [1.5]])运行结果如下:
array([1, 0])如果训练两个特征呢?我们用花瓣宽度和花瓣长度。
from sklearn.linear_model import LogisticRegression
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.int)
log_reg = LogisticRegression(solver="liblinear", C=10**10, random_state=42)
log_reg.fit(X, y)
x0, x1 = np.meshgrid(
np.linspace(2.9, 7, 500).reshape(-1, 1),
np.linspace(0.8, 2.7, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = log_reg.predict_proba(X_new)
plt.figure(figsize=(10, 4))
plt.plot(X[y==0, 0], X[y==0, 1], "bs")
plt.plot(X[y==1, 0], X[y==1, 1], "g^")
zz = y_proba[:, 1].reshape(x0.shape)
contour = plt.contour(x0, x1, zz, cmap=plt.cm.brg)
left_right = np.array([2.9, 7])
boundary = -(log_reg.coef_[0][0] * left_right + log_reg.intercept_[0]) / log_reg.coef_[0][1]
plt.clabel(contour, inline=1, fontsize=12)
plt.plot(left_right, boundary, "k--", linewidth=3)
plt.text(3.5, 1.5, "Not Iris-Virginica", fontsize=14, color="b", ha="center")
plt.text(6.5, 2.3, "Iris-Virginica", fontsize=14, color="g", ha="center")
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.axis([2.9, 7, 0.8, 2.7])
plt.show()运行结果如下:
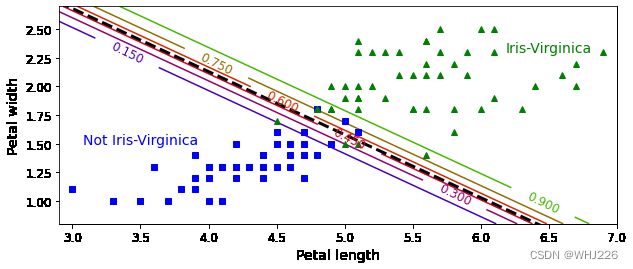
虚线表示模型估算概率为50%的点,即模型决策边界。注意,这里是一个线性边界。每条平行线都分别代表一个模型输出的特定概率,从左下的15%到右上的90%。
与其他线性模型一样,逻辑回归模型可以用l1或l2 惩罚函数来正则化。默认添加l2函数。
注意:控制Scikit-Learn的LogisticRegression模型正则化程度的超参数不是alpha(其他线性模型使用alpha),而是它的逆反:C ,C的值越高,模型正则化程度越高。
11 Softmax回归
逻辑回归模型经过推广,可以直接支持多个类别,而不需要训练并组合多个二元分类器,这就是Softmax回归,或者叫多元逻辑回归。
原理:对于一个给定的实例x,Softmax回归模型首先计算出每个类别k的分数![]() ,然后对这些分数应用softmax函数(归一化指数),估算出每个类别的概率。
,然后对这些分数应用softmax函数(归一化指数),估算出每个类别的概率。
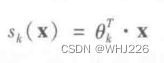
注意,每个类别都有自己特定的参数向量 ![]() ,所有这些向量通常都作为行存储在参数矩阵
,所有这些向量通常都作为行存储在参数矩阵![]() 中。
中。
计算完实例x每个类别的分数后,就可以通过Softmax函数来计算分数:计算出每个分数的指数,然后对它们进行归一化处理(除以所有指数的总和)即得到![]() ,也就是实例属于类别k的概率。
,也就是实例属于类别k的概率。
 Softmax函数
Softmax函数
跟逻辑回归分类器一样,Softmax回归分类器将估算概率值最高的类别作为预测类别。
 Softmax回归分类器预测
Softmax回归分类器预测
注意:Softmax回归分类器一次只会预测一个类别(它是多类别,但不是多输出),所以他应该仅适用于互斥的类别之上。
下面我们进行训练,训练目标是得到一个能对目标类别做出高概率估算的模型。我们可以将下面的成本函数(交叉熵)最小化来实现这个目标,因为当模型对目标类别做出较低概率的估算时,会受到惩罚。交叉熵经常被用于衡量一组估算出的类别概率跟目标类别的匹配程度。
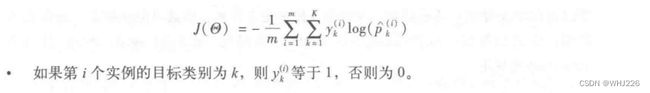
注意,当只有两个类别(K=2)时,该成本函数等价于逻辑回归的成本函数。
拓展
交叉熵
交叉熵源于信息理论。假设你想要有效传递每天的天气信息,选项(睛、下雨等)有 8个,那么你可以用3比特对每个选项进行编码,因为2^3=8。但是,如果你认为几乎每天都是睛天,那么,对“睛天”用1比特(0),其他七个类别用4比特(从1开始)进行编码,显然会更有效率一些。交叉熵衡量的是你每次发送天气选项的平均比特数。如果你对天气的假设是完美的,交叉熵将会等于天气本身的熵(也就是其本身固有的不可预测性)。但是如果你的假设是错误的(比如经常下雨),交叉熵将会变大, 增加的这一部分我们称之为KL散度(Kullback-Leibler divergence,也叫作相对熵)。
两个概率分布p和q之间的交叉熵定义为(至少在离散分布时可以这样定义)。
下面的公式给出了该成本函数关于 ![]() 的梯度向量。
的梯度向量。
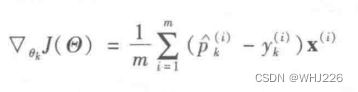
现在可以计算出每个类别的梯度向量,然后使用梯度下降(或任意其他优化算法)找到最小化成本函数的参数矩阵![]() 。
。
我们使用Softmax回归将鸢尾花分为三类。当用两个以上的类别训练时,Scikit-Learn 的LogisticRegressio默认选择使用的是一对多的训练方式,不过将超参数multi_ class 设置为"multinomial",可以将其切换成Softmax回归。还必须指定一个支持Softmax回归的求解器,比如"lbfgs"求解器(详细解释见Scikit-Learn文档)。默认使用l2正则化,我们可以通过超参数C进行控制。
X = iris["data"][:, (2, 3)] # petal length, petal width
y = iris["target"]
softmax_reg = LogisticRegression(multi_class="multinomial",solver="lbfgs", C=10, random_state=42)
softmax_reg.fit(X, y)softmax_reg.predict([[5, 2]])运行结果如下:
array([2])softmax_reg.predict_proba([[5, 2]])运行结果如下:
array([[6.38014896e-07, 5.74929995e-02, 9.42506362e-01]])一朵鸢尾花,花瓣长5厘米宽2厘米,模型预测结果: 94.3%的概率是Virginica鸢尾花(第2类)或者5.7%的概率为 Versicolor尾花 。
x0, x1 = np.meshgrid(
np.linspace(0, 8, 500).reshape(-1, 1),
np.linspace(0, 3.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = softmax_reg.predict_proba(X_new)
y_predict = softmax_reg.predict(X_new)
zz1 = y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==2, 0], X[y==2, 1], "g^", label="Iris-Virginica")
plt.plot(X[y==1, 0], X[y==1, 1], "bs", label="Iris-Versicolor")
plt.plot(X[y==0, 0], X[y==0, 1], "yo", label="Iris-Setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
contour = plt.contour(x0, x1, zz1, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 7, 0, 3.5])
plt.show()运行结果如下:
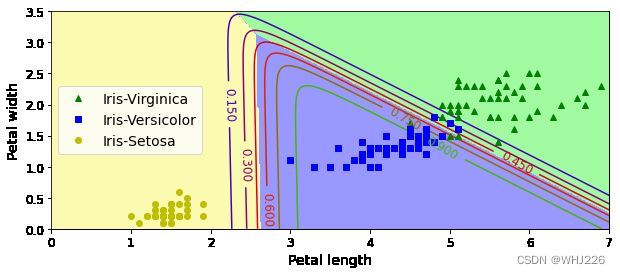
上图展现了由不同背景色表示的决策边界。注意,任何两个类别之间的决策边界都是线性的。图中的折线表示属于Versicolor鸢尾花的概率(例如,标记为0.45的线代表45%的概率边界)。注意一点,该模型预测出的类别,其估算概率有可能低于50%,比如,在所有决策边界相交的地方,所有类别的估算概率都为33%。
学习笔记——《机器学习实战:基于Scikit-Learn和TensorFlow》