论文解读Motion Transformer with Global IntentionLocalization and Local Movement Refinement
Motion Transformer with Global IntentionLocalization and Local Movement Refinement 论文精读
此篇论文是2022年发表NeurIPS上的文章,代码即将在GitHub开源。目前占据waymo open dataset leadboard运动预测榜单榜首。
摘要:预测交通参与者的行为对于自动驾驶车辆做决策至关重要。现有工作通过latent feature(收敛慢)预测轨迹或者利用dense goal候选(效率低)来识别目标,本文提出了运动变换器MTR框架,全局意图优化和局部运动细化联合优化对运动预测进行建模。不使用目标候选,采用可学习的运动query结合空间意向先验,每个查询对负责特定运动模式和轨迹预测细化。
Introduction
运动预测是自动驾驶的一项基本任务,他对于自动驾驶理解场景,做出决策至关重要。运动预测需要根据agent 状态和路线来预测交通参与者的未来行为,挑战在于物体多模态行为以及复杂的场景环境。主要两种方法两种,
1:基于goal的 采用目标候选覆盖所有的目的地,预测每个候选到达真实目的的概率,候选少降低性能,大会增加内存和计算
2:direct regression 编码agent特征,自适应的覆盖代理未来行为,收敛速度慢,需要从相同的代理特征中回归不同的运动
在我们提出的motion transform中,采用一种新的运动查询对建模运动预测,第一个全局意图定位任务粗略识别代理意图,第二个局部运动细化旨在自适应细化每个意图的轨迹预测。我们的方法不仅稳定了训练过程不依赖目标候选,通过每个运动模式的局部细化,实现了灵活和自适应轨迹预测。
每个运动查询对,有两个组件组成,静态意图查询和动态搜索查询。
1.静态意图查询引入全局意图定位,基于一小组空间分布的意图点来表达,每个静态查询都是生成的特定运动模式轨迹的可学习位置嵌入。 好处,显式使用不同模式的不同查询稳定训练过程;通过每个查询负责大区域,消除候选的依赖。
2.动态搜索查询用于局部细化,被初始化为意图点的可学习嵌入,负责检索每个意图点的周围的细粒度局部特征。根据预测的轨迹的动态更新动态搜索查询,自适应从可变形局部收集最新的轨迹特征。用于迭代运动细化
两个查询相互补充,预测多模态未来运动。现有工作侧重对过去轨迹代理的交互进行建模,忽略未来轨迹的交互,为了补偿这些信息,我们采用一个简单的辅助回归头密集的每个代理的未来轨迹和速度,这些轨迹和速度被编码为额外的上下文特征。
我们的贡献3个方面
(1)新的运动查询对的解码器网络采用两种类型的查询来建模运动预测
(2)辅助的密集未来预测任务,以实现我们感兴趣的代理和其他的交互
(3)提出MTR框架,多模态预测的transformer编码解码器
related work
motion prediction for autonomous driving 一般使用自动驾驶的道路地图和历史状态作为输入,早期生成近似分布,基于goal
transformer自然语言处理Detr
Motion transformer
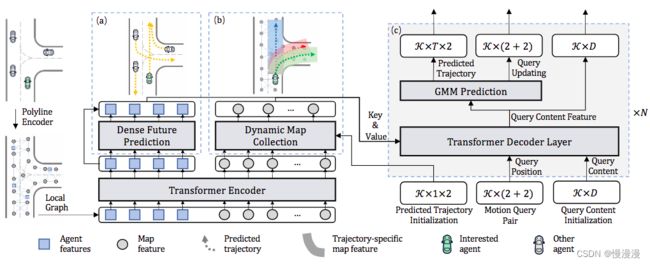
a)密集预测模块,先预测一条路径,huangse虚线
b)指示动态地图收集模块,收集沿每个预测轨迹的地图元素,为运动解码器网络提供特定特征
c)运动解码器网络,K是查询对数量,T是未来帧,D是隐藏层特征维度,N是transformer解码器数量。预测的轨迹、运动查询对和查询内容特征是来自上一个解码器层的输出,并将作为下一个解码器的输入。第一层解码器的初始查询都被初始化为意图点,初始地图收集的意图点被替代为预测轨迹,查询内容向量初始化为0
3.1scene context modeling transformer encoder
现有方法建模场景上下文通过建立全局交互图或者将地图特征汇总为智能体特征。locality structure重要,提出局部自注意力的transformer encoder network
输入表示:向量化表示输入轨迹和road map![]() Na智能体,t表示历史帧数,Ca表示状态信息
Na智能体,t表示历史帧数,Ca表示状态信息
![]()
Nm是地图段的数量,n是每个段点的数量,Cm是每个点的属性
![]()
MLP多次感知机,最大池化
Scene context encoding with local transformer encoder.
构建并行lane的关系很重要,attention是全局的,我们引入先验知识构造局部attention,attention module的公式
Dense future prediction for future interactions
先前的工作提出使用基于中枢主机的网络[67]、动态关系推理[28]、社会时空网络[58]等来建模多代理交互。然而,大多数现有的工作通常侧重于学习过去轨迹中的这种相互作用,而忽略了未来轨迹的相互作用。
![]()
Si=(Na,4)每个代理在时间步长i的未来位置和速度,以及T是要预测的未来帧的数量
3.2 Transformer Decoder with Motion Pair
静态意图查询和动态搜素查询
global intention localization:生成K表示意图点I k*2。每个意图点的可学习嵌入表示。PE表示正弦位置编码,需要64个query。
每个意图查询负责预测特定运动模式的轨迹,这稳定了训练过程,并有助于预测多模态轨迹,因为每个运动模式都有自己的可学习嵌入
**local movement refinement:**旨在通过迭代聚集细粒度轨迹特征以细化轨迹来补充全局意图定位。我们提出了动态搜索查询,以自适应地探测每个运动模式的轨迹特征。每个动态搜索查询也是空间点的位置嵌入,该空间点用其对应的意图点初始化,但将根据每个解码器层中的预测轨迹动态更新。具体而言,给定预测的未来轨迹Yi,在第j个解码器层中,第(j+1)个解码器层的动态搜索查询更新如下:Qj+1S=MLP(PE(YjT))。
对于每个运动查询对,我们提出了一个动态地图收集模块,通过从轨迹对齐的局部区域中查询地图特征来提取细粒度轨迹特征。通过收集中心最接近预测轨迹的L条折线来实现的。由于代理的行为在很大程度上取决于路线图,因此这种局部运动细化策略能够持续关注最新的局部上下文信息,以进行迭代运动细化。
Attention module with motion query pair:在每个解码器层中,静态意图查询用于在不同的运动意图之间传播信息,而动态搜索查询用于从场景上下文特征中聚合轨迹特定特征。具体来说,我们使用静态查询作为自我关注模块的位置嵌入,接下来,我们利用动态搜索查询作为交叉关注的查询位置嵌入,从编码器的输出中探测轨迹特定特征。我们将查询和关键字的内容特征和位置嵌入连接起来,以分离它们对注意力权重的贡献。
Multimodal motion prediction with Gaussian Mixture Mode:对于每个解码器层,我们将预测头附加到Cj以生成未来轨迹。由于代理的行为是高度多模态的,添加预测头用GMM表示预测轨迹的分布。
对于未来时间步{1…T},用高斯组件预测了概率p和miu,sita,表示成Pji(o) =K∑k=1pk·Nk(ox−μx,σx;oy−μy,σy;ρ)。Pji(o)是代理在空间位置o的发生概率.可以通过简单地提取高斯分量的预测中心来生成预测的轨迹Yj1:Tc
Training Loss
第一个辅助损失是L1回归损失,以优化等式(3)的输出。对于第二个高斯回归损失,我们根据等式(9)采用负对数似然损失,以最大化地面真实轨迹的似然性
实验细节
WOMD中有两项任务具有独立的评估指标:(1)边缘运动预测挑战,独立评估每个代理的预测运动(每个场景最多8个代理)。(2) 联合运动预测挑战需要预测两个相互作用的代理的联合未来位置以进行评估。这两种方法都提供了1秒的历史数据,并旨在预测未来8秒钟内的边缘或关节轨迹。每次挑战共有487k个训练场景,约44k个验证场景和44k个测试场景。我们使用官方评估工具来计算评估指标,其中mAP和错过率是官方排行榜中最重要的指标。
对于上下文编码,我们堆叠了6个变压器编码器层。路线图表示为多条多段线,其中每条多段线最多包含20个点(约10分钟WOMD)。我们在感兴趣的代理周围选择Nm=768最近的地图多段线。编码器的本地自我关注中的邻居数量设置为16。编码器隐藏特征维度设置为D=256。对于解码器模块,我们堆叠6个解码器层。Lis设置为128,以从上下文编码器收集最接近的地图多段线,用于运动细化。默认情况下,我们使用64个运动查询对,其中通过对训练集执行k均值聚类算法来生成它们的意图点。为了生成6个用于评估的未来轨迹,我们使用非最大抑制(NMS),通过计算端点之间的距离,从64个预测轨迹中选择前6个预测,距离阈值设置为2.5m
我们的模型由AdamW优化器以端到端的方式进行训练,学习率为0.0001,批量大小为80个场景。我们用8个GPU(NVDIA RTX 8000)训练了30个时期的模型,每2个时期学习率衰减0.5倍。权重衰减设置为0.01,我们不使用任何数据增强。用于端到端运动预测的MTR-e2e。我们还提出了一种端到端的MTR变体,称为MTR-e2e,其中仅采用6个运动查询对,以消除NMS后处理。在训练过程中,MTR-e2不是像MTR那样使用静态意图点进行目标分配,而是通过计算其6个预测目标和GT轨迹之间的距离来选择正混合成分,因为6个意图点太稀疏,无法很好地覆盖所有潜在的未来运动。
Conclusion
在本文中,我们提出了一种新的多模态运动预测框架MTR。运动查询对被定义为将运动预测建模为全局意图定位和局部运动细化的联合优化。全局意图定位采用一小组可学习的静态意图查询来有效地捕捉代理的运动意图,而局部运动重新定义通过不断探测细粒度轨迹特征来进行迭代运动细化。对大规模WOMD数据集的边缘和联合运动预测挑战的实验表明,我们的方法实现了最先进的性能