AAAI 2022 | 负样本问题:时间基础度量学习的复兴
本文介绍我们组NJU-MCG 在多模态视频片段定位领域(Temporal Grounding和Spatio-temporal Grounding任务)被AAAI 2022接收的一篇工作 Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding。
TL;DR: 本方法(Mutual Matching Network, MMN)主要是从两个角度对现有方法进行改进:
第一个角度是使用跨模态对比学习增加文本和视频特征的可辨别性(more discriminative)从而提高最终的定位效果,具体做法是增加了一个使得两个模态双向匹配(mutual matching)的损失函数从而构造了许多新的监督信号。我们首次使用了此前方法忽视的文本负样本,并且首次揭示了跨视频负样本的重要性。我们对于负样本的探究对应了标题中的negative sample matters。
第二个角度是从度量学习的角度使用了一个多模态联合建模空间(joint visual-language embedding space)替换复杂的多模态融合模块,从而大幅降低了计算开销,并且使得前面提到的双向匹配loss成为可能。
虽然此前有过一个方法使用度量学习进行建模,但其方法效果较差因此后续没有人follow这个思路。本方法的标题使用了a renaissance of metric learning试图说明度量学习的角度其实依然是一个很好的建模思路,希望有更多的后续工作follow这个思路。
论文链接(camera ready version已经更新):
https://arxiv.org/abs/2109.04872
代码链接(代码和网络权重已经开源):
https://link.zhihu.com/?target=https%3A//github.com/MCG-NJU/MMN
任务介绍
简单介绍一下什么是视频片段语言定位(Temporal Grounding)任务:属于视频领域的多模态任务(视频+文本),是视频时序检测任务的多模态版本,也是跨模态视频检索的片段版本。以下列举了一些视频领域的相关任务。
动作识别 (Action Recognition) : 对每个输入视频进行分类,识别出视频中人物做出的动作。即输入一个视频,得到视频对应的类别。方法主要是Two-Stream和3D Conv两个流派,常常作为后续视频任务的特征提取器。此任务可以关注我们组近期的工作TDN。
时序动作检测 (Temporal Action Detection/Localization) :输入一个未经裁剪的长视频 (untrimmed video),即视频中既包括有动作的前景区间,也包括没有明确语义的背景区间。任务需要检测(或定位,此任务中这两个词等价)出动作开始和结束的区间,并判断区间内动作的类别。即输入未经裁剪的视频序列,得到动作出现的区间和对应的类别。常用数据集为THUMOS14与ActivityNet。此任务可以关注我们组近期工作RTD。
跨模态视频检索(Cross-modal Video Retrieval):在一个给定的视频数据库中查询与一句话的语义最相关的那个视频。虽然与temporal grounding任务只相差一个片段定位过程,但是两个任务的方法上几乎没有相似性。这个领域使用度量学习角度的方法比较多,但是在temporal grounding领域几乎没有人follow。
视频片段语言定位 (Temporal Grounding) :输入一个未经裁剪的长视频和一句话,任务要求检测与这句话语义一致的片段的区间。本任务有很多名字,例如temporal/video grounding, cross-modal moment retrieval, natural language moment retrieval, temporal localization via language query等,代表了不同的领域对于这个任务从不同角度的看法。本任务也没有一个固定的中文名字,我们给它起的暂定的名字是多模态视频时序检测,之后提到的时候主要还是使用英文名。
这个任务的产生主要可以有两个角度来看:
(1)作为时序检测的多模态版本,使用一句话替代时序检测中固定的类别体系,从而使得视频时序检测的类别更加开放和动态变化。
(2)作为跨模态视频检索的一个更加细化的版本(即从在一个视频库中检索一个视频变为在一个视频检索一个片段),使得检索方法不仅可以查询一个短视频,更可以从一个长视频中查询一个短片段,从而具有此前视频检索方法达不到的一些效果。一般来说CV研究者都是从第一个角度进行建模的,即使标题中含有retrieval的很多方法基本上也是从时序检测的角度进行思考的。
此前的方法主要有4类:
(1) detection:在融合过的多模态特征上使用anchor-based(基于早期目标检测方法)/anchor-free(基于CenterNet/FCOS)/transformer(基于DETR)/boundary classification(类似于BSN)等方法进行时序检测。
(2) regression:在融合过的多模态特征上利用attention模块形成一个全局特征,然后直接预测片段的开始结束。
(3) reinforcement learning:通过强化学习的算法逐渐逼近最终的预测结果。
(4) metric learning:使用joint visual-language embedding space中两个模态的相似度进行建模,这个思路此前的方法只有一篇文章,没有很多人follow。
多模态视频预训练(Video-Language Pretraining):利用视频和与其弱相关的字幕(通过ASR得到)或者标题(通过一些Meta-info得到)进行预训练,目的是为了利用互联网上不需要标注的信息进行弱监督或自监督学习从而得到更好的特征表示。这个预训练任务得到的特征的好坏与下游任务的性能息息相关,因此十分重要,自从自监督学习变得火热以后这个领域的文章也非常多。
本文使用的跨模态对比学习损失函数常见于Video-Language Pretraining任务中,具体来说本文使用的loss是在我们组此前的工作CPD上经过修改而成,并且给这个loss在temporal grounding任务中赋予了新的意义。需要注意的是本文的方法并没有使用任何的预训练数据集,所有的监督信号都是从temporal grounding数据集本身中构造的。
其他Grounding任务:
(1)Visual Grounding:目标检测的多模态版本,将目标检测中的类别换为一句话。(2)Spatio-temporal Video Grounding:时空动作检测的多模态版本,我们的AAAI文章中基于提出的temporal grounding方法构造了一个Spatio-temporal Video Grounding的方法并且取得了2021年HC-STVG比赛的第一。
(3)Refering Image/Video Segmentation:语义分割或视频目标分割(Video Object Segmentation)的多模态版本。
以下还有一些其他的相关任务,是本任务的拓展任务或者是其他角度的相关任务,可跳过。
Video Captioning/Dense Video Captioning:是Temporal Grounding的逆任务,输入一个视频,任务要求使用一句或者多句自然语言描述本视频。Temporal Grounding任务中最大的数据集ActivityNet-Captions同样具有captioning这个任务。
Video-Subtitle Moment Retrieval (TVR数据集近期提出):输入一个视频数据库和一句话,根据这句话的语义首先在在一个视频库中检索视频,然后定位一个短片段。是Temporal Grounding任务和Cross-modal Video Retrieval任务的结合。以后temporal grounding任务数据集刷到饱和以后这个任务应该是一个比较好的进阶版本任务。
研究动机
正如任务介绍部分提到的,目前的temporal grounding方法主要都是从detection的角度去解决这个任务,因此他们的研究重点主要有两个:
(1)设计复杂的cross-modal fusion模块来更好的align两个模态之间的信息。
(2)设计复杂的定位(检测)模块来更好的预测片段的位置,这个角度直白一点来说和时序动作检测比除了数据集不一样以外没什么区别,并且大部分工作是follow目标检测的最新进展,也有一些工作利用了时序一维信息的特点(例如follow BSN和BMN的思路)。
还有一些temporal grounding方法从聚合全局特征然后regression的角度出发,但是他们往往只能出一个预测框,这一点对于动作边界歧义性比较大的视频数据集来说其实是不太友好的。基于现有的思路,我们在想能不能跳出常用的框架,从而做一些与其他人不太一样的东西。
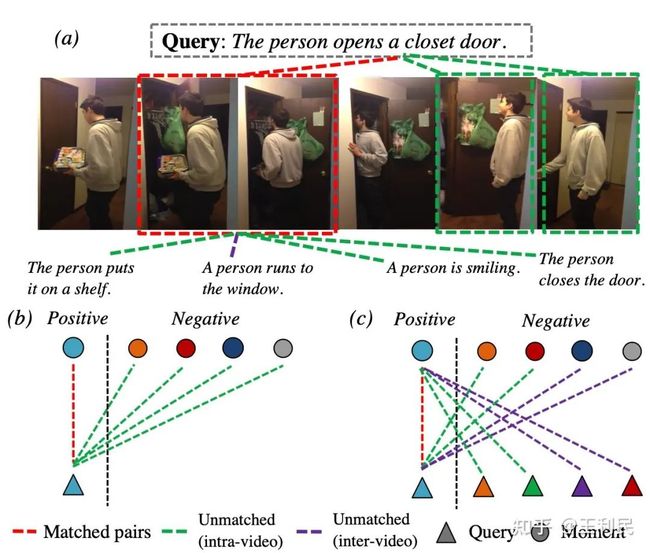
我们的动机:基于视频数据集的规模往往都较小的事实,如何构造新的监督信号来帮助模型训练的更好?如图所示,子图a表示了一个视频和语句的例子,图中的连线关系代表了监督信号(正负样本)的构造。此前的proposal-based方法都是给定一句话(query),利用视频框的正负样本来监督网络(子图b)。我们提出除了利用已有的监督信号以外,可以对称地构造出一组对应的新的监督信号,即给定一个gt moment,利用语句的正负样本作为监督信号(子图c),从而达到两个模态双向匹配(mutual matching)的效果,即我们的网络名字Mutual Matching Network的由来。
最终,回到子图a的例子,它的上半部分中,红框表示正样本,其他绿框表示负样本,这些红色与绿色框与query相连的虚线表示此前的监督信号,我们增加了下半部分对于红框的一些语句负样本,即绿线(同一个视频内)和紫线(其他视频中的)相连的语句负样本。增加监督信号的idea有了,下面如何能够完成这件事情?直观来说,这个idea虽然直觉上应该是效果比较好的,但是这样一个比较简单的idea为什么此前都没有人做呢?为了实现这种新的监督信号的构造,我们回到了此前没有人follow的metric learning思路来分别建模两个模态的特征,然后通过一个简单的内积来计算近似度。此前的方法由于在早期就进行了模态融合,因此是没有办法像我们一样构造新的监督信号的,只有把两个模态的建模方式分开才有可能构造以上提到的新的监督信号。
使用了metric learning之后,我们还发现了几个额外的优点:
(1)对于此前一直使用的子图b中的监督信号,由于此前方法没有使用一个joint embedding space进行建模,他们没有办法使用其他视频中的moment负样本,我们的方法也是可以使用的。因此第一个额外的优点是能够使用其他视频中的sentence和moment负样本。
(2)由于将模态分开,因此对于同一个视频和同一个语句,我们都只需要对他们做一次建模即可,而此前的early-fusion方法对于每一个视频-语句对都需要进行一次建模,从而导致我们的计算开销大幅降低。数学上,如果一个视频内平均具有k个语句,那我们的计算开销应该是early-fusion方法的1/k(因为语言建模网络的计算复杂度比视频框建模网络的复杂度小很多)。
实际上,我们训练ActivityNet-Captions花了10 GPU hours,而我们的baseline在使用和我们几乎一样多的网络层的情况下需要36 GPU hours(类似的事情在测试时也是成立的)。
具体方法
由于我们的主要贡献是监督信号,因此我们的网络结构相比于baseline(2D-TAN)来说改动只有最后的joint embedding space部分。此外,由于LSTM网络使用的设定往往存在很大差异,并且实际上也给我们复现其他方法造成了一些困扰,因此基于标准化的考虑(call for standardization),我们使用了一个预训练过的DistilBERT,这样可以保证大家使用的语言特征编码器是公平比较的。
我们也在两个此前工作上进行了替换DistilBERT的实验(与LSTM效果相差不大),从而与我们的方法公平比较。我们这里同样为了保持尽可能的与2D-TAN一致从而公平比较,我们保留了一个joint embedding space用来进行2D-TAN原本的loss,并且在一个新的embedding space里面进行我们增加的监督信号的学习。

损失函数:我们使用了两个损失函数。(1)与2D-TAN一样的BCE Loss (下标bce)。(2)用来使用新的监督信号的跨模态对比学习损失函数 Cross-modal Pair Discrimination Loss,这是一个跨模态相互监督版本的Instance Discrimination方法,使用了类似于InfoNCE的损失函数形式。它在我们的方法(Mutual Matching Network)里称为Mutual Matching Loss (下标mm)。如图所示,我们从语言负样本和跨视频负样本两个角度增加了监督信号。

BCE loss:

Cross-modal Pair Discrimination Loss:

最终训练时两个loss加权相加,score归一化后相乘。需要注意的一点是,由于这两个loss作用的embedding space共享同样的视频/语言特征编码器,因此训练完成后直接拿  进行测试的结果就会远好于2D-TAN的效果。
进行测试的结果就会远好于2D-TAN的效果。

实验结果
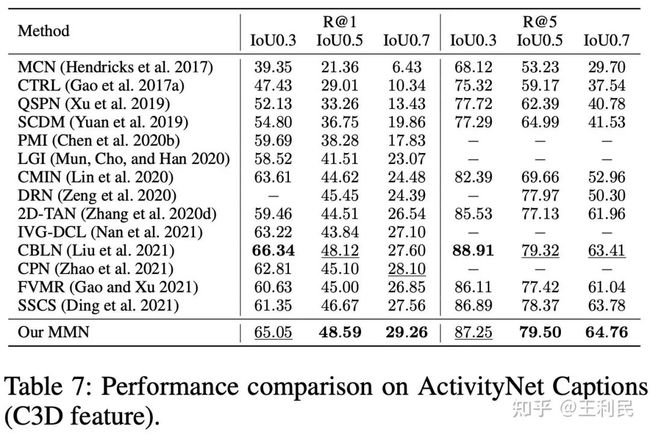
这里我们首先通过实验证明我们提出的监督信号比较有用。我们分别在ActivityNet-Captions(最大,最权威)和Charades-STA(最小,我们的方法最明显)两个数据集上做了ablation study。我们有以下几个观察:
(1)加入语言负样本的效果是比较明显的。
(2)由于跨视频的负样本较多,加入跨视频负样本可以进一步地较大提升最终效果,并且只用跨视频负样本的效果往往也比只用视频内的负样本效果更好。这里其实可能会有一些反直觉的地方,因为视频内的负样本往往是难样本,而视频外的负样本往往是简单样本。但是我们同时还有一个只针对视频内负样本的bce loss,因此我们认为bce loss主要针对难样本,mutual matching主要通过大量的负样本改进特征提取器的特征表示效果(这一点在可视化中也可以看出来,bce loss的score distribution比较sharp但有可能定位偏移,而mutual matching的score distribution比较模糊但一般来说偏移较小)。
(3)只使用我们附加的loss可以得到与bce loss差不多甚至更好的效果。


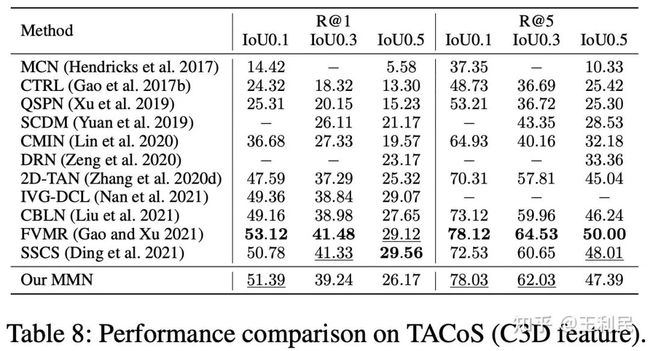
其次我们给出ActivityNet-Captions,TACoS, Charades-STA数据集上的SOTA效果比较,这三个数据集也是CV领域做这个任务最常使用的数据集。此外还有一个数据集(DiDeMo)由于标注粒度是5s而不是常用的逐帧/逐0.1s标注,因此使用的人不是太多。我们的方法重点比较了一些近期刚刚放出来的同期工作,例如CVPR21, ICCV21的方法等。
我们的工作在21年3月已经完成并且拿到了21年6月初截止的HC-STVG比赛的第一,可以说明我们在做这项工作的时候是不知道这些同期工作的。
(1)IVG-DCL (CVPR21) 和SSCS (ICCV21) 都使用了对比学习来改进temporal grounding方法,但是他们都是不够直接的sentence-clip pair或者clip-clip pair的对比学习,而我们是和temporal grounding的最终结果更加相似和直接的sentence-moment pair的对比学习。因此,他们没有用metric learning框架从而缺少了我们提出的mutual matching,即无法利用sentence负样本和跨视频负样本。他们在使用了更加复杂的模块之后(IVG-DCL多用了IVG模块,SSCS多用了captioning和support-set模块)的效果依然比我们差一点。
(2)FVMR (ICCV21) 与我们一样使用了metric learning框架来建模,因此也具有计算开销少的特点,但是FVMR的主要idea是利用一个distillation loss来通过复杂的语言编码器增强简单的语言编码器的效果。FVMR没有提出构造新的监督信号的方式也没有使用对比学习,因此同样缺少我们提出的mutual matching。

最后我们给出本方法拓展到spatio-temporal video grounding任务上的版本,我们在仅仅依靠我们的MMN进行跨模态关系建模的情况下超越了一些使用很强的多模态预训练模型的方法(例如LXMERT和MDETR)。具体实现方法部分请参考我们的论文。

作者:王利民
|关于深延科技|
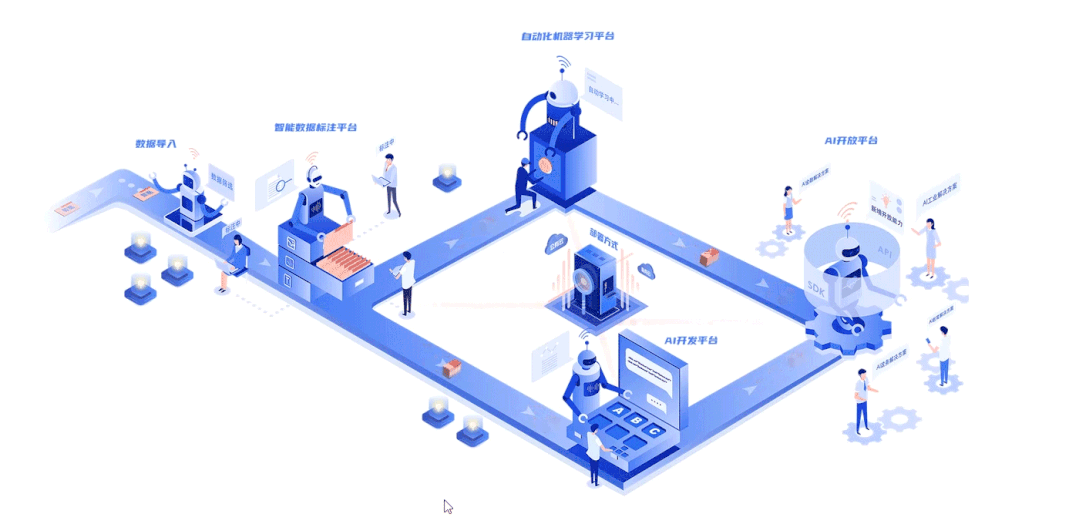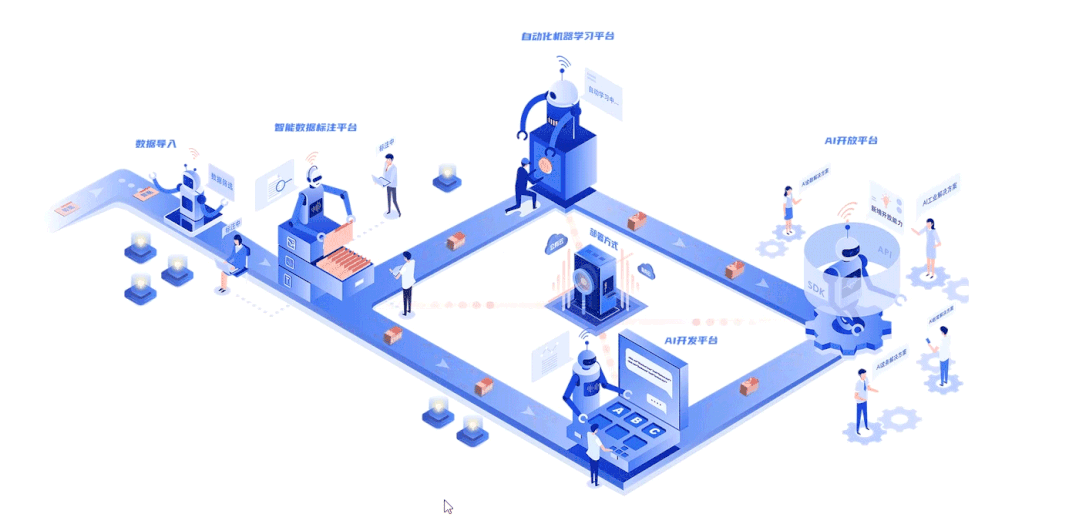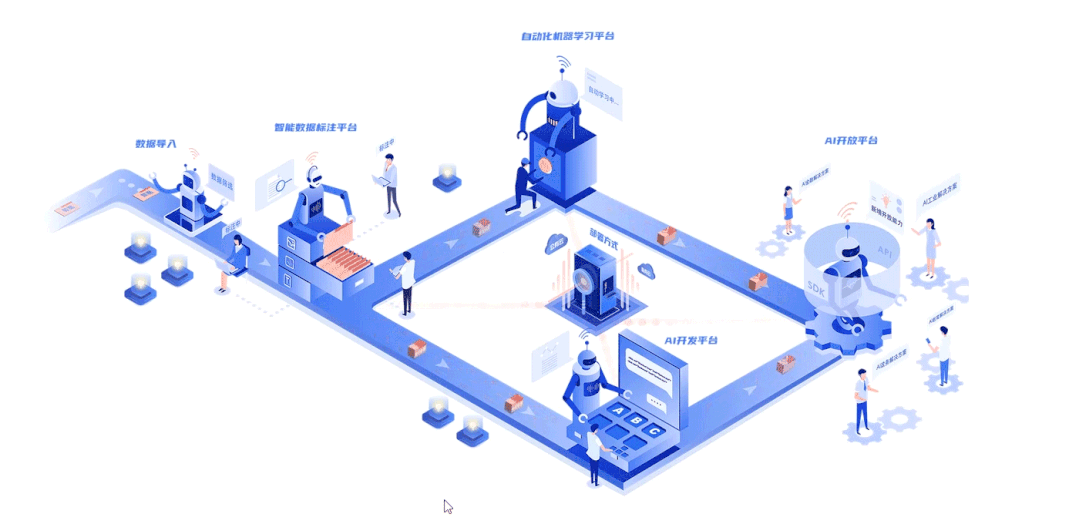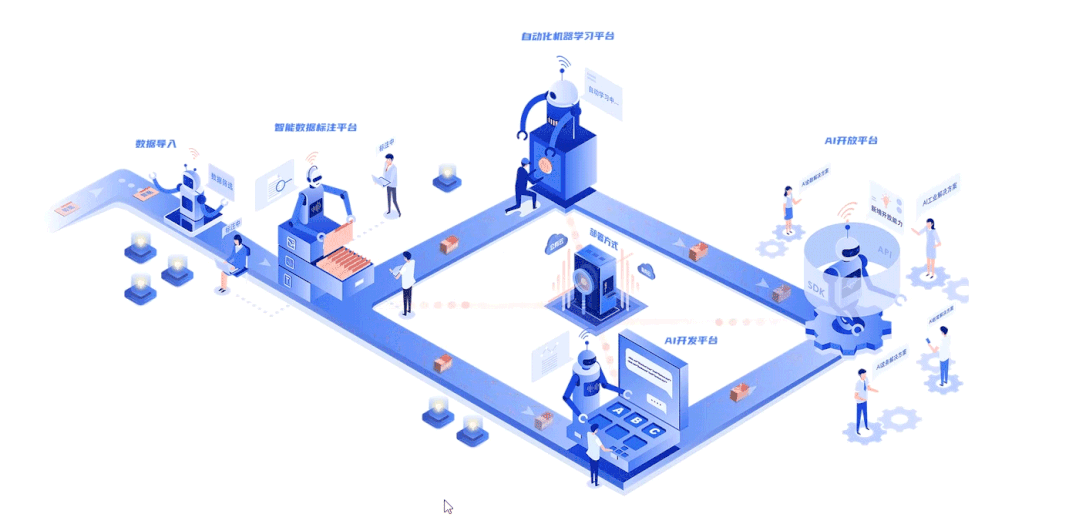
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。