LeNet-5应用
目录
实验1:实现MNIST手写数字识别
1、导入需要的库
2、使用GPU训练
3、图像增强
4、载入数据
5、图片可视化
6、LeNet模型
7、加载模型并打印参数
8、损失函数,优化器
9、训练函数
10 、可视化预测结果
实验2:将LeNet5应用在FashionMNIST上
尝试改变参数提高精度
(1)epoch=10。
(2)换不同的优化器
2.1 SGD优化器
实验1:实现MNIST手写数字识别
(152条消息) 用PyTorch实现MNIST手写数字识别(非常详细)_小锋学长生活大爆炸的博客-CSDN博客_mnist pytorch
1、导入需要的库
import os
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim #优化算法
import torchvision.transforms as transforms
from torchsummary import summary#打印模型参数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
os.environ['KMP_DUPLICATE_LIB_OK']='True'#绘图时需要,要不然会有OMP错误2、使用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))3、图像增强
transform = transforms.Compose(
[transforms.ToTensor(),#张量
transforms.Normalize(mean=(0.5), std=(0.5))])因为是灰度图,所以mean和std都只有一个参数,如果为RGB,都为(0.5,0.5,0.5)
4、载入数据
train_set = torchvision.datasets.MNIST(root='./data', #存目录
train=True,#训练用
download=False, #下载
transform=transform)#数据增强
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=32,
shuffle=True, #乱序
num_workers=0)#单线程
val_set = torchvision.datasets.MNIST(root='./data',
train=False,
download=False,
transform=transform)
val_loader = torch.utils.data.DataLoader(val_set,
batch_size=10000,#将所有验证数据导入
shuffle=False,
num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)数据导入有两步,先用datasets导入,然后用dataloader加载。如果需要下载就设置download=True即可。
5、图片可视化
显示前16个图片。
fig = plt.figure()
for i in range(16):
plt.subplot(4,4,i+1)
plt.tight_layout()
plt.imshow(val_image[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(val_label[i]))
plt.xticks([])
plt.yticks([])
plt.show()
MNIST共有70000张图片,60000张训练集,10000张测试集。图片大小28*28,灰度图。
6、LeNet模型
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1,6,5,1,2)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
#定义前向传播,输入为x
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x7、加载模型并打印参数
net = LeNet()
net.to(device)
summary(net,input_size=(1,28,28),device="cuda")----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 156
MaxPool2d-2 [-1, 6, 14, 14] 0
Conv2d-3 [-1, 16, 10, 10] 2,416
MaxPool2d-4 [-1, 16, 5, 5] 0
Linear-5 [-1, 120] 48,120
Linear-6 [-1, 84] 10,164
Linear-7 [-1, 10] 850
================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.24
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
8、损失函数,优化器
#损失函数
loss_function = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001)9、训练函数
tr_loss=[]
val_acc=[]
#开始训练
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad() #梯度清零
# forward + backward + optimize
outputs = net(inputs.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image.to(device)) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label.to(device)).sum().item() / val_label.size(0)
tr_loss.append(running_loss / 500)
val_acc.append(accuracy)
print('[%d, %5d] train_loss: %.3f acc:%d/%d %.0f%%' %
(epoch + 1, step + 1, running_loss / 500,torch.eq(predict_y, val_label.to(device)).sum().item(),val_label.size(0),100.*accuracy))
running_loss = 0.0
print('Finished Training')
plt.plot(tr_loss,label='loss')
plt.plot(val_acc,label='accuracy')
plt.legend()
plt.show()
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)[1, 500] train_loss: 0.443 acc:9659/10000 97%
[1, 1000] train_loss: 0.127 acc:9765/10000 98%
[1, 1500] train_loss: 0.085 acc:9767/10000 98%
[2, 500] train_loss: 0.065 acc:9773/10000 98%
[2, 1000] train_loss: 0.059 acc:9812/10000 98%
[2, 1500] train_loss: 0.059 acc:9757/10000 98%
[3, 500] train_loss: 0.049 acc:9853/10000 99%
[3, 1000] train_loss: 0.042 acc:9859/10000 99%
[3, 1500] train_loss: 0.044 acc:9868/10000 99%
[4, 500] train_loss: 0.036 acc:9878/10000 99%
[4, 1000] train_loss: 0.035 acc:9821/10000 98%
[4, 1500] train_loss: 0.035 acc:9872/10000 99%
[5, 500] train_loss: 0.024 acc:9908/10000 99%
[5, 1000] train_loss: 0.028 acc:9871/10000 99%
[5, 1500] train_loss: 0.028 acc:9865/10000 99%
Finished Training
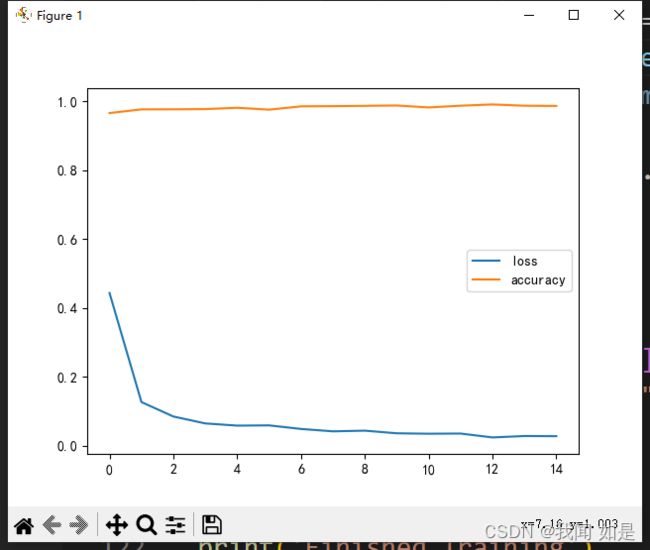
预测结果epoch=3的时候已经成绩达到99%。
10 、可视化预测结果
examples = enumerate(val_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = net(example_data.to(device))
fig = plt.figure()
for i in range(16):
plt.subplot(4,4,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()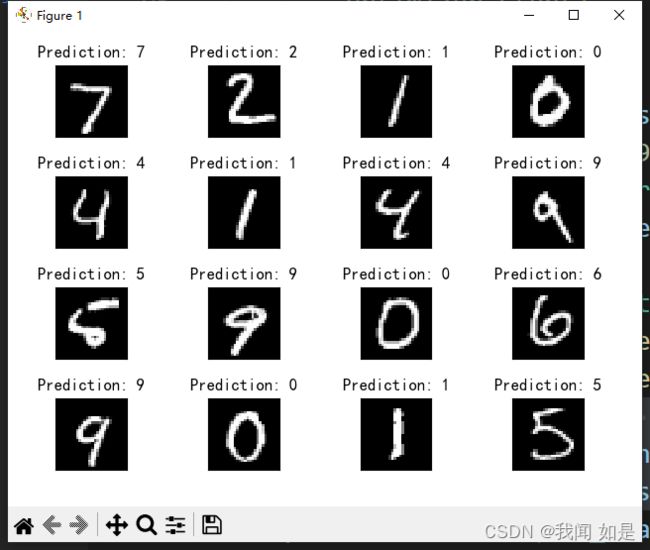
全部预测成功。 LeNet在MNIST上的效果很好。
完整的程序:
##################################################
#导入需要的库
##################################################
import os
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim #优化算法
import torchvision.transforms as transforms
from torchsummary import summary#打印模型参数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
os.environ['KMP_DUPLICATE_LIB_OK']='True'#绘图时需要,要不然会有OMP错误
def main():
#使用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
##################################################
#图像增强
#如果是灰度图,设置transforms.Normalize((0.5),(0.5))即可。
# RGB图,需要改为transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
##################################################
transform = transforms.Compose(
[transforms.ToTensor(),#张量
transforms.Normalize(mean=(0.5), std=(0.5))])#归一化,std=0.5,mean=0.5
##################################################
#加载训练数据集
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
##################################################
train_set = torchvision.datasets.MNIST(root='./data', #存目录
train=True,#训练用
download=True, #下载
transform=transform)#数据增强
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=32,
shuffle=True, #乱序
num_workers=0)#单线程
##################################################
#加载验证集
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
##################################################
val_set = torchvision.datasets.MNIST(root='./data',
train=False,
download=True,
transform=transform)
val_loader = torch.utils.data.DataLoader(val_set,
batch_size=10000,#将所有验证数据导入
shuffle=False,
num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
########################################################
#显示前4个验证集图片
########################################################
fig = plt.figure()
for i in range(16):
plt.subplot(4,4,i+1)
plt.tight_layout()
plt.imshow(val_image[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(val_label[i]))
plt.xticks([])
plt.yticks([])
plt.show()
#加载模型
net = LeNet()
net.to(device)
summary(net,input_size=(1,28,28),device="cuda")
#损失函数
loss_function = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001)
tr_loss=[]
val_acc=[]
#开始训练
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad() #梯度清零
# forward + backward + optimize
outputs = net(inputs.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image.to(device)) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label.to(device)).sum().item() / val_label.size(0)
tr_loss.append(running_loss / 500)
val_acc.append(accuracy)
print('[%d, %5d] train_loss: %.3f acc:%d/%d %.0f%%' %
(epoch + 1, step + 1, running_loss / 500,torch.eq(predict_y, val_label.to(device)).sum().item(),val_label.size(0),100.*accuracy))
running_loss = 0.0
examples = enumerate(val_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = net(example_data.to(device))
fig = plt.figure()
for i in range(16):
plt.subplot(4,4,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
print('Finished Training')
fig1=plt.figure()
plt.plot(tr_loss,label='loss')
plt.plot(val_acc,label='accuracy')
plt.legend()
plt.show()
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
实验2:将LeNet5应用在FashionMNIST上
FashionMNIST数据集的介绍:(152条消息) Fashion MNIST数据集介绍及下载_Dick-andy的博客-CSDN博客_“fashion-mnist”数据集下载
大小和MNIST一样。只是把数字0-9换成了衣物。
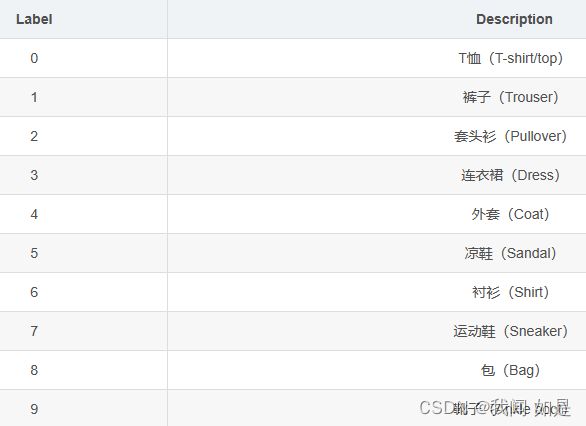
修改的地方:
1、数据加载
train_set = torchvision.datasets.FashionMNIST(root='./data', #存目录
train=True,#训练用
download=True, #下载
transform=transform)#数据增强
val_set = torchvision.datasets.FashionMNIST(root='./data',
train=False,
download=True,
transform=transform)可视化显示16个图片。

其它都不需要修改,直接可以进行训练。
[1, 500] train_loss: 0.774 acc:7761/10000 78%
[1, 1000] train_loss: 0.499 acc:8063/10000 81%
[1, 1500] train_loss: 0.434 acc:8410/10000 84%
[2, 500] train_loss: 0.371 acc:8617/10000 86%
[2, 1000] train_loss: 0.343 acc:8739/10000 87%
[2, 1500] train_loss: 0.326 acc:8749/10000 87%
[3, 500] train_loss: 0.309 acc:8774/10000 88%
[3, 1000] train_loss: 0.309 acc:8872/10000 89%
[3, 1500] train_loss: 0.283 acc:8846/10000 88%
[4, 500] train_loss: 0.276 acc:8882/10000 89%
[4, 1000] train_loss: 0.269 acc:8943/10000 89%
[4, 1500] train_loss: 0.262 acc:8888/10000 89%
[5, 500] train_loss: 0.253 acc:8930/10000 89%
[5, 1000] train_loss: 0.236 acc:8983/10000 90%
[5, 1500] train_loss: 0.248 acc:8966/10000 90%
Finished Training
训练结果在epoch=5时,能达到91%。可视化预测结果,可以看出,16个预测14个准确,准确率87.5%。

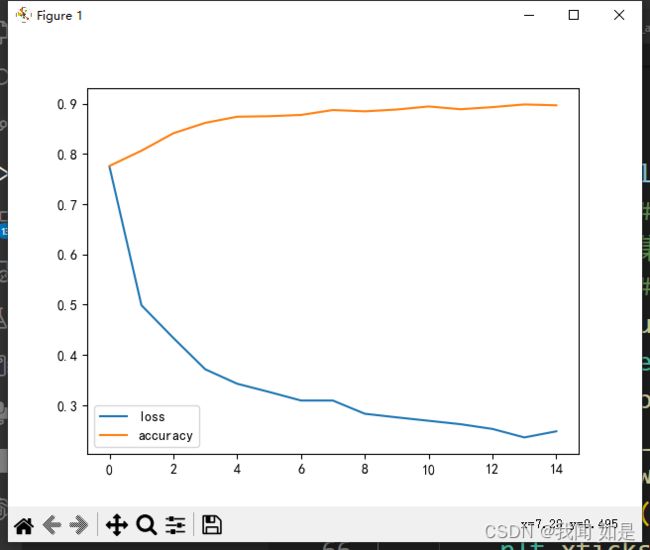
尝试改变参数提高精度
(1)epoch=10。
[1, 500] train_loss: 0.779 acc:7839/10000 78%
[1, 1000] train_loss: 0.508 acc:8168/10000 82%
[1, 1500] train_loss: 0.428 acc:8383/10000 84%
[2, 500] train_loss: 0.373 acc:8564/10000 86%
[2, 1000] train_loss: 0.361 acc:8621/10000 86%
[2, 1500] train_loss: 0.349 acc:8659/10000 87%
[3, 500] train_loss: 0.305 acc:8714/10000 87%
[3, 1000] train_loss: 0.306 acc:8760/10000 88%
[3, 1500] train_loss: 0.305 acc:8860/10000 89%
[4, 500] train_loss: 0.281 acc:8892/10000 89%
[4, 1000] train_loss: 0.270 acc:8801/10000 88%
[4, 1500] train_loss: 0.279 acc:8841/10000 88%
[5, 500] train_loss: 0.246 acc:8871/10000 89%
[5, 1000] train_loss: 0.251 acc:8907/10000 89%
[5, 1500] train_loss: 0.253 acc:8895/10000 89%
[6, 500] train_loss: 0.232 acc:8934/10000 89%
[6, 1000] train_loss: 0.236 acc:8944/10000 89%
[6, 1500] train_loss: 0.243 acc:8952/10000 90%
[7, 500] train_loss: 0.214 acc:8962/10000 90%
[7, 1000] train_loss: 0.221 acc:8965/10000 90%
[7, 1500] train_loss: 0.227 acc:9020/10000 90%
[8, 500] train_loss: 0.198 acc:8993/10000 90%
[8, 1000] train_loss: 0.206 acc:9022/10000 90%
[8, 1500] train_loss: 0.219 acc:8912/10000 89%
[9, 500] train_loss: 0.190 acc:8908/10000 89%
[9, 1000] train_loss: 0.198 acc:8982/10000 90%
[9, 1500] train_loss: 0.190 acc:8979/10000 90%
[10, 500] train_loss: 0.178 acc:8966/10000 90%
[10, 1000] train_loss: 0.184 acc:9026/10000 90%
[10, 1500] train_loss: 0.186 acc:9043/10000 90%
Finished Training
能达到90%精度。预测图100%正确。所以提高epoch还是有用的。

(2)换不同的优化器
2.1 SGD优化器
optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.5)[1, 500] train_loss: 2.292 acc:1722/10000 17%
[1, 1000] train_loss: 2.255 acc:3446/10000 34%
[1, 1500] train_loss: 2.010 acc:3746/10000 37%
[2, 500] train_loss: 0.990 acc:6620/10000 66%
[2, 1000] train_loss: 0.849 acc:6817/10000 68%
[2, 1500] train_loss: 0.794 acc:7136/10000 71%
[3, 500] train_loss: 0.727 acc:7248/10000 72%
[3, 1000] train_loss: 0.714 acc:7303/10000 73%
[3, 1500] train_loss: 0.693 acc:7329/10000 73%
[4, 500] train_loss: 0.664 acc:7398/10000 74%
[4, 1000] train_loss: 0.659 acc:7560/10000 76%
[4, 1500] train_loss: 0.634 acc:7469/10000 75%
[5, 500] train_loss: 0.627 acc:7608/10000 76%
[5, 1000] train_loss: 0.612 acc:7593/10000 76%
[5, 1500] train_loss: 0.595 acc:7665/10000 77%
[6, 500] train_loss: 0.584 acc:7771/10000 78%
[6, 1000] train_loss: 0.582 acc:7712/10000 77%
[6, 1500] train_loss: 0.566 acc:7746/10000 77%
[7, 500] train_loss: 0.556 acc:7802/10000 78%
[7, 1000] train_loss: 0.551 acc:7895/10000 79%
[7, 1500] train_loss: 0.545 acc:7887/10000 79%
[8, 500] train_loss: 0.531 acc:8042/10000 80%
[8, 1000] train_loss: 0.518 acc:8029/10000 80%
[8, 1500] train_loss: 0.525 acc:7823/10000 78%
[9, 500] train_loss: 0.506 acc:8093/10000 81%
[9, 1000] train_loss: 0.503 acc:8084/10000 81%
[9, 1500] train_loss: 0.508 acc:7940/10000 79%
[10, 500] train_loss: 0.484 acc:8078/10000 81%
[10, 1000] train_loss: 0.481 acc:8153/10000 82%
[10, 1500] train_loss: 0.487 acc:8236/10000 82%
准确性只有80%。性能不升反而降低了。