transformer与vit代码阅读
tansformer

如上图所示左半部分为编码器,右半部分为译码器。整个代码也从将这两部分代码拆解开。
1.Encoder
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# %% id="xqVTz9MkTsqD"
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)Encoder将N层EncoderLayer连接,如上面代码和下图所示:
 图1.Encoder
图1.Encoder
1.1 LayerNorm
由图一可以看出,EncoderLayer包含了两个子层,并且两个子层都包含Residual+LayerNorm
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2上面为LayerNorm模块,Layer Normalization的作用是把神经网络中隐藏层归一为标准正态分布,以起到加快训练速度,加速收敛的作用。
1.2 Residual
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))上面为Residual模块,目的是在网络深度加深的情况下解决梯度消失的问题。
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
如上所示,便是由上面两个模块构成了EncoderLayer。
2.Decoder

class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)从结构图和代码中可以看出,Decoder与Encoder结构极为相似,唯一的不同便是它多了一层注意力子层。
2.1 Mask

可以看出,Decoder的第一个注意力子层多了个masked,具体代码如下:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0 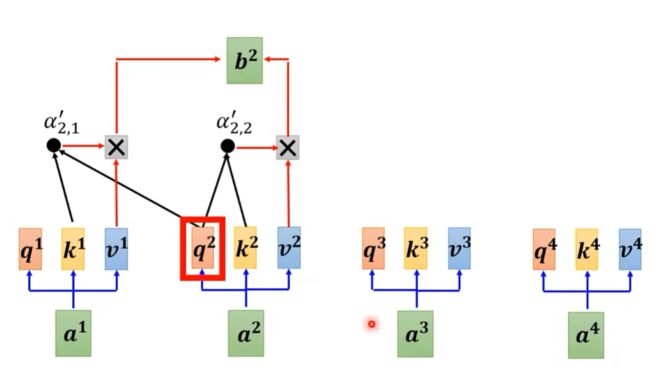
举例如上图所示,当你计算b2时,将a3、a4忽略,只考虑a1与a2,这就是所谓的mask机制。
3.多头注意力机制
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
如上图举例所示,qi1在算attention分数时忽略qi2,只计算qi1的attention,qi2也是同样的操作,这即是两头时的操作,多头操作亦如此。
4. 位置编码
由于Transformer模型没有循环神经网络的迭代操作,所有必须提供每个字的位置信息给Transformer,这样它才能识别出语言中的顺序关系。

如上图所示,在transformer的结构图中,有一个“Positional Encoding”,即位置编码,代码实现如下:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
在transformer中的位置编码中,其编码公式如下:

pos表示当前字符在输入字符中的位置
i为该字符的维度下标对2求模
dmodel表示该字符的维度
5.FeedForward

FeedForward可以细分为有两层,第一层是一个线性激活函数,第二层是激活函数是ReLu。
代码实现如下:
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))VisionTransformer的代码实现
1.图片预处理
transform = Compose([
Resize((224, 224)),
ToTensor(),
])
x = transform(img)
x = x.unsqueeze(0)
#添加一个维度?
print(x.shape)
处理后,图片输入大小为[3*224*224]
2.卷积处理
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
) # this breaks down the image in s1xs2 patches, and then flat them
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return xnn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size)输入图片为 [3*224*224],经过上面所示卷积,卷积核大小为16*16,步长为16,卷积核个数为768,得到输出[768*14*14]
(论文中是将输入图片按照16*16的大小划分为196个patch,每个patch大小为16*16*3,通过映射得到一个长度768的向量,而代码中则是通过一个卷积层实现。)
Rearrange('b e (h) (w) -> b (h w) e')再将h和w维度展平,得到输出[768*196]
3.添加class token
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
x = torch.cat([cls_tokens, x], dim=1)添加class token,class token是一个长度768的向量,与图片的token拼接,得到输出[768*197]。
4.添加位置编码
self.positions = nn.Parameter(torch.randn((224 // patch_size) ** 2 + 1, emb_size))
x += self.positions位置编码是一个[197*768]的向量,直接叠加在token上,故输出仍是[197*768]
以上生成的向量即为编码器的输入
5.Transformer编码器
(未完成)