NN对图像数据进行预测;DNN对文本数据进行预测;CNN对文本数据进行分类
1. NN对图像数据进行预测
1.1 代码
def cv_test():
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
#导入数据集
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
print(test_images)
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
#反转图像颜色
train_images = train_images / 255.0
test_images = test_images / 255.0
#显示前25个图像
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
#构建神经网络
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),#将二维数组转化为一维数组,将参数展开
tf.keras.layers.Dense(128, activation='relu'),#128个神经元,激活函数为relu
tf.keras.layers.Dense(10)#返回10个数组
])
#编译模型
model.compile(optimizer='adam',#优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),#损失函数
metrics=['accuracy'])#度量
#模型训练和拟合
history = model.fit(train_images, train_labels, epochs=10)
plt.figure()
plt.plot(history.history['loss'],'b',label = "loss")
plt.plot(history.history['acc'],'r',label = "acc")
plt.title("Loss and Acc")
plt.xlabel("迭代次数")
plt.ylabel("准确率和损失率")
plt.legend()
plt.show()
print("---------------------------------------------------------------------------")
#模型评估(得到模型损失和模型准确率)
test_loss, test_acc = model.evaluate(test_images,test_labels,verbose=2)
print('\nTest accuracy:', test_acc)
#模型预测
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])#添加softmax层,使模型概率更容易被理解
#模型预测
predictions = probability_model.predict(test_images)
#查看第一个预测结果及其置信度
print("预测值为:",class_names[np.argmax(predictions[0])])
print("真实值为:",class_names[test_labels[0]])
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
if __name__ == '__main__':
import tensorflow as tf
import keras
import numpy as np
import matplotlib.pyplot as plt
import time
import pandas as pd
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif']=['SimHei']#中文显示
plt.rcParams['axes.unicode_minus'] = False #显示负号
cv_test()
1.2 运行结果
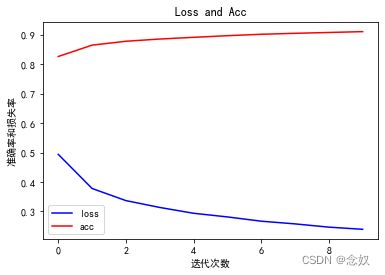

Test accuracy: 0.8801
预测值为: Ankle boot
真实值为: Ankle boot
2. DNN对文本数据进行预测
2.1 代码
def dnn_test():
test = pd.read_excel(r"..\test.xlsx")
train = pd.read_excel(r"..\train.xlsx")
#设置NN的层数为三层
#print("皮尔逊相关系数:",test.corr())
model = keras.models.Sequential()
model.add(keras.layers.Dense(5,activation='sigmoid',input_shape=(8,)))
model.add(keras.layers.Dense(3,activation="relu"))
model.add(keras.layers.Dense(1))
model.compile(optimizer='sgd',
loss='mean_squared_error', # 等价于loss = losses.binary_crossentropy
metrics=['mae']) # 等价于metrics = [metircs.binary_accuracy]
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(test,train,test_size=0.25,random_state=23)
print(X_train.shape)
#数据拟合
model.fit(X_train,y_train,epochs=50)
#绘制loss-mae图
plt.figure()
plt.plot(model.history.history["loss"],'r',label="loss")
plt.plot(model.history.history["mae"],'b',label="mae")
plt.title("Loss and Mae")
plt.xlabel("迭代次数")
plt.ylabel("准确率和损失率")
plt.legend()
plt.show()
#结果预测
test1 = np.array([2040.5,2359.50,7309.38,17773.96,65.89,352.59,50.56,1252.63]).reshape(1,8)
print(model.predict(test1))
if __name__ == '__main__':
import tensorflow as tf
import keras
import numpy as np
import matplotlib.pyplot as plt
import time
import pandas as pd
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif']=['SimHei']#中文显示
plt.rcParams['axes.unicode_minus'] = False #显示负号
dnn_test()
2.2 运行结果
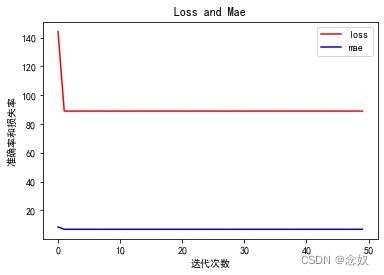
[[46.966255]]
3. CNN对文本数据进行分类
3.1 代码
def cnn_test():
"""CNN主要包含卷积层、池化层、全连接层
另外需要注意的是,CNN主要用来分类,尤其是做时间序列的分类
本代码中的train为0和1,主要是做二分类"""
test = pd.read_excel(r"..\test.xlsx")
train = pd.read_excel(r"..\train.xlsx")
#设置模型
model = keras.models.Sequential()
#添加激活函数
model.add(keras.layers.Activation("relu"))
#设置卷积层
model.add(keras.layers.Conv2D(
nb_filter = 32,#卷积层有多少个通道
nb_row = 5,#卷积大小为(5,5)
nb_col = 5,
border_mode = 'same',#same表示图像卷积前后的shape不变
input_shape = (-1,1,9,1)))#输入维度大小
#添加激活函数
model.add(keras.layers.Activation("sigmoid"))
#设置池化层
model.add(keras.layers.MaxPooling2D(pool_size = (2,2),#池化大小
strides = (2,2),#池化步长
border_mode = 'same'))
#将池化层输出专变为一维输出
model.add(keras.layers.Flatten())
#将输出全连接
model.add(keras.layers.Dense(248,activation="sigmoid"))
model.add(keras.layers.Dense(128,activation="relu"))
model.add(keras.layers.Dense(128,activation="relu"))
model.add(keras.layers.Dense(1,activation="softmax"))
#用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
#loss可用sparse_categorical_crossentropy
model.compile(loss = 'binary_crossentropy',optimizer = 'sgd',metrics = ['accuracy'])
#数据导入
X_train, X_test, y_train, y_test = train_test_split(test,train,test_size=0.25,random_state=23)
print("导入维度:X_train:{},X_test:{},y_train:{},y_test:{}".format(X_train.shape,X_test.shape,y_train.shape,y_test.shape))
print("-------------------------------------------------------------------")
#数据处理,维度相同
X_train = np.array(X_train).reshape(32015,1,9,1)
X_test = np.array(X_test).reshape(10672,1,9,1)
y_train = np.array(y_train).reshape(y_train.shape[0])
y_test = np.array(y_test).reshape(y_test.shape[0])
print("处理后维度:X_train:{},X_test:{},y_train:{},y_test:{}".format(X_train.shape,X_test.shape,y_train.shape,y_test.shape))
#模型训练
model.fit(X_train.astype(float),y_train.astype(float),validation_data=(X_test.astype(float), y_test.astype(float)),epochs=5)
#绘制loss-acc图
plt.figure()
#fit函数中有各种损失值可以选择
plt.plot(model.history.history["loss"],'r',label="loss")
plt.plot(model.history.history["accuracy"],'b',label="acc")
plt.title("Loss and Acc")
plt.xlabel("迭代次数")
plt.ylabel("准确率和损失率")
plt.legend()
plt.show()
#模型预测
test1 = np.array([2040.5,2359.50,7309.38,17773.96,65.89,352.59,50.56,1252.63,54]).reshape(1,1,9,1)
print("分类结果为:",model.predict(test1))
if __name__ == '__main__':
import tensorflow as tf
import keras
import numpy as np
import matplotlib.pyplot as plt
import time
import pandas as pd
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif']=['SimHei']#中文显示
plt.rcParams['axes.unicode_minus'] = False #显示负号
cnn_test()
3.2 运行结果
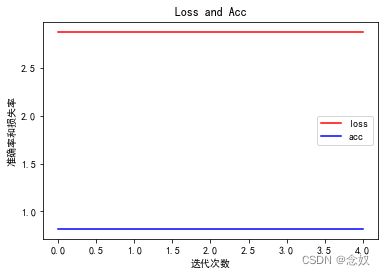
分类结果为: [[1.]]
4. 遇到的一些问题即解决方法
4.1 数据维度的设置
在机器学习中最容易出错的就是数据维度(shape)的问题。我们在设置输入和输出shape时要充分考虑到数据本身的shape,让输入shape和我们输入数据的shape保持一致,才可以避免一些列问题的出现。当我们想要改变我们输入的shape时,可以引用numpy中的reshape方法进行修改。
4.2 选择合适的机器学习模型
当我们在研究机器学习方法的时候,要充分了解模型的特性。要知道什么模型是做分类的,什么模型是做预测的。虽然说神经网络很强大,当时选择合适的机器学习模型可以使我们事半功倍。