机器学习和联邦学习
该文转载自本人的知乎专栏https://zhuanlan.zhihu.com/p/341837393
我会持续在知乎上发布文章,记得关注我哦~
一、巩固隐私计算的版图
开启本专栏的初心是,为了巩固隐私计算的版图,其实,读过我其它专栏的朋友们应该知道,我所做的方向便是密码学在数据安全中的应用。所以,我的专栏包含了以下内容:
同态加密的数学基础——“近世代数”
同态加密的密码学基础——“格密码理论”
同态加密——“理论与实践”
安全多发计算——”理论与实践“
从下面图中可以看出,我的专栏还只涉及到 ”隐私计算“ 技术类别中的安全多方计算相关密码学知识,对于另外一个版图——”联邦学习“ 还没有涉及,缺少了它,就不符合当今科技领域中的 ”隐私计算“ 了。
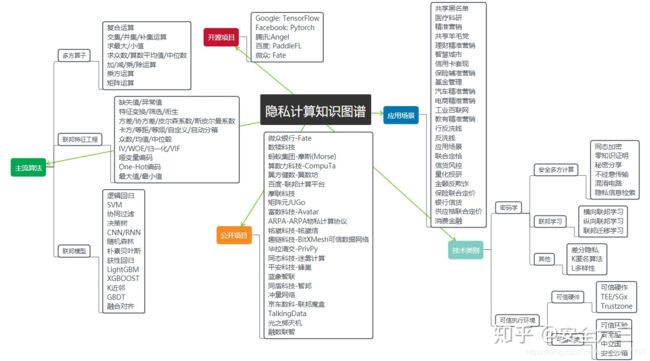
二、联邦学习在隐私计算中的重要性
上图中的公开项目、开源项目和应用场景中可以看出,隐私计算的主要应用基础还是联邦学习。所以,后面我会慢慢添加上联邦学习的内容。那么首先说一下何为联邦学习。
2.1 何为联邦学习
联邦机器学习(Federated machine learning/Federated Learning),又名联邦学习,联合学习,联盟学习。联邦机器学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
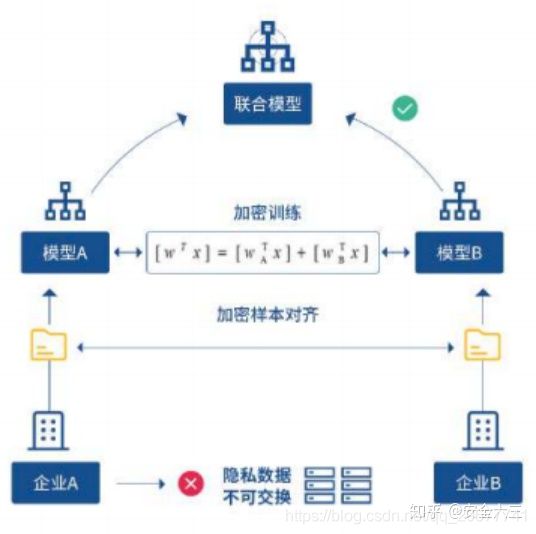
举例来说,假设有两个不同的企业 A 和 B, 它们拥有不同数据。比如, 企业 A 有用户特征数据; 企业 B 有产品特征数据和标注数据。这两个企业按照上述 GDPR 准则是不能粗暴地把双方数据加以合并的, 因为数据的原始提供者, 即他们各自的用户可能不同意这样做。假设双方各自建立一个任务模型, 每个任务可以是分类或预测, 而这些任务也已经在获得数据时有各自用户的认可,那问题是如何在 A 和 B 各端建立高质量的模型。由于数据不完整(例如企业 A 缺少标签数据,企业 B 缺少用户特征数据), 或者数据不充分 (数据量不足以建立好的模型), 那么, 在各端的模型有可能无法建立或效果并不理想。联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而后联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下, 建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候, 数据本身不移动, 也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。 这就是为什么这个体系叫做“联邦学习”。
2.2 联邦学习特点
各方数据都保留在本地,不泄露隐私也不违反法规;
多个参与者联合数据建立虚拟的共有模型,并且共同获益的体系;在联邦学习的体系下,各个参与者的身份和地位平等;
联邦学习的建模效果和将整个数据集放在一处建模的效果相同,或相差不大(在各个数据的用户对齐(user alignment或特征(feature alignment对齐的条件下);
迁移学习是在用户或特征不对齐的情况下,也可以在数据间通过交换加密参数达到知识迁移的效果。
2.3 联邦学习类别
两个数据集的用户特征(X1,X2,…, )重叠部分较大,而用户( U1,U2,…,)重叠部分较小;
两个数据集的用户( U1,U2,…, )重叠部分较大,而用户特征(X1,X2,…, )重叠部分较小;
两个数据集的用户( U1,U2,…, )与用户特征重叠( X1,X2,…, )部分都比较小。
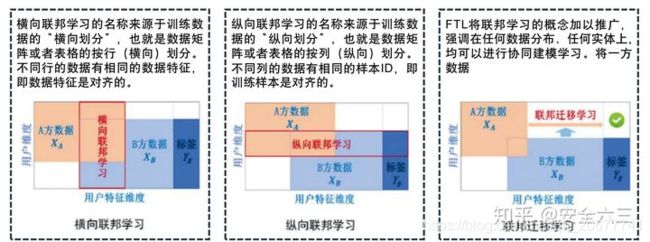
2.4 联邦学习重要性
其实了解到联邦学习的定义,那么其重要性就不言而喻了。
联邦学习作为未来 AI 发展的底层技术,它依靠安全可信的数据保护措施下连接数据孤岛的模式,将不断推动全球 Al技术的创新与飞跃。
随着联邦学习在更大范围和更多行业场景的渗透及应用,它在更高层面上对各类人群、组织、行业和社会都将产生巨大影响,联邦学习的公共价值主要体现在以下几个方面∶
加速人工智能技术创新发展
保障隐私信息及数据安全
促进全社会智能化水平提升
三、机器学习 (深度学习) 是基础
联邦学习我们已经了解了,那么我们如何学习联邦学习呢?首先我们就要掌握机器学习的基础知识,这样我们才能将隐私计算的最后一个版图给填满。

四、总结
最后,大胆的预测一下,未来几年,隐私计算将成为一匹黑马,会得到资本的关注,并快速发展,这一切都是由国内外科技领域和其法律规范的发展导致的必然。
最后容许我打个广告哈,如果想学习隐私计算,则密码学和人工智能缺一不可,所以请同时学习我知乎专栏。专栏中包含了,近世代数、同态加密、安全多方计算、机器学习和联邦学习。
https://www.zhihu.com/people/an-quan-xiao-qi
喜欢我创作的小伙伴们,记得在知乎上给我点下关注、赞同哦,让我有动力持续创作,持续给大家带来干货。