搜索搜索系统中常见的Debais方法与策略
最近由于刚刚入职了新公司,已经很久没有更新博客了。从今天开始,要开始慢慢总结工作与学习了。今天的博客主要参考了2019年华为诺亚方舟实验室在ResSys会议的paper《PAL:APositionbiasAwareLearningFrameworkforCTRPredictioninLiveRecommenderSystems》,微软发表的paper《Modeling and Simultaneously Removing Bias via Adversarial Neural Networks》以及美团NLP&搜索技术部于2020年在DLP-KDD上发表的一篇workshop《Learning-To-Rank with Context-Aware Position Debiasing》。
首先我们要明确一下什么是偏置,以及偏置产生的原因和对整个推荐系统的影响。所谓“偏置”从字面上理解,就是整个搜索推荐系统对于用户兴趣的抽取和建模在某些特定的维度产生了“偏见”,而这些偏见往往和真实的情况是不一致的。这就好比生活中,我们习对一件事情进行判断的时候,往往是按照过去的经验,而如果这些经验是有一些偏见的话,我们对待当前事情的决策就会出现偏置。而搜索推荐系统之所以产生了偏见,往往是因为用于训练的数据本身是有偏导致的。
比方说在训练点击率预估模型时,许多特征属于统计特征,比如搜索关键词和广告的交叉点击率。对于经常展示的关键词、广告对来说,这类特征比较丰富且置信,但是对于不经常展示或者从未展示过的关键词、广告对来说,这类信息非常稀疏且不置信,模型对这些关键词、广告的信息不能充分学习,很难将这些关键词、广告对的展示位置进行提前。
同时,当CTR模型进行更新时,所使用的数据往往是在线上应用前一版模型而收集到的。新的数据和模型更容易学到这些展示位置靠前的关键词、广告对的信息,这种情形文中称为“Feedback Loop”,此时我们的训练所使用的数据,是存在一定偏置信息的。这种偏置信息的存在,大都集中于位置偏置,即不同的展示位置对于CTR的影响不同,越靠前位置展示的广告,点击率会偏高。
如果系统的偏置情况很严重的话,在有些情况下使用有偏置的数据作为验证集,反而会得到 线上线下指标变化不一致的情况,即离线验证集的AUC/NDCG显著提升,而在线的CTR等指标会显著下降。
因此有必要在模型训练的过程中消除这些信息,并使用无偏的数据对模型进行验证。
下面,我就着分享论文的角度,介绍工业界中几种常见的解决偏置的方法。
首先介绍一种baseLine的方法:
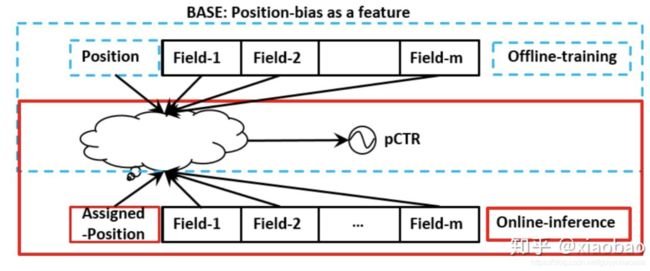
因为数据中的偏置往往是优位置导致的,那就直接在离线训练模型的时候,把位置当做输入特征。在线预测的时候,就使用default值。这种方法在处理上非常粗暴,一方面在线预测的时候,不同的default会导致不同的结果;另一方面,很多包含隐式位置偏置的特征(例如统计某个商品的历史点击次数)依然会对结果产生负向影响。
下面是华为诺亚方舟实验室提出的模型PAL

从图中可以看出,其将用户点击item的概率拆分两部分,用户看到该item的概率 和 看到该item后点击的概率,即 p ( y = 1 ∣ x , p o s ) = p ( s e e n ∣ x , p o s ) ∗ p ( y = 1 ∣ x , p o s , s e e n ) p(y=1| x,pos)=p(seen|x,pos) * p(y=1| x,pos,seen) p(y=1∣x,pos)=p(seen∣x,pos)∗p(y=1∣x,pos,seen)
假设用户是否看到item,只与item的位置有关;用户看到item后,是否点击item,只与item本身有关,与位置无关。那么上述式子可以简化为 p ( y = 1 ∣ x , p o s ) = p ( s e e n ∣ p o s ) ∗ p ( y = 1 ∣ x , s e e n ) p(y=1|x,pos)=p(seen|pos)*p(y=1|x,seen) p(y=1∣x,pos)=p(seen∣pos)∗p(y=1∣x,seen)。
离线训练的损失函数为
L ( θ p s , θ p C T R ) = 1 N ∑ i = 1 N l ( y i , P r o b S e e n i ∗ p C T R i ) L(\theta_{ps},\theta_{pCTR})=\frac{1}{N}\sum_{i=1}^Nl(y_i,ProbSeen_i*pCTR_i) L(θps,θpCTR)=N1∑i=1Nl(yi,ProbSeeni∗pCTRi)。
在线进行预测的时候,只有红框中的模型部分进行预测。
下面介绍美团提出的一种在搜索场景下的debais偏置模型。
首先美团的相关小伙伴发现了,在某些情况下进行模型迭代的时候,离线的指标明明涨了很多,但是模型上线之后反而QV_CTR等指标下降了(这说明整个系统已经在长时间的积累下,产生了较为严重的偏置现象)。而关于这个情况,一种最直观的解释是“由于用于训练和评估的数据都是有偏的,故模型如果把这个偏置信息“认真”掌握的话,对于在线来说就会产生更严重的负向结果。有些商品之所以在训练集的正样本中从来没有出现过,不一定是因为用户不喜欢,可能是一直得不到展示机会,故和点击相关的特征会很弱”。
在搜索场景中,往往优化的目标是NDCG,和pointWise 使用的交叉熵不同的是,NDCG为了使序列的NDCG值最大,使用了被称之为lambda loss的方法,将一个query内的样本两两构造样本对,直接计算lambda loss:
λ i j = ∂ L i j ∂ y i c ∣ ∇ Q i j ∣ = − σ 1 + e x p ( σ ( y i c − y j c ) ) ∣ ∇ Q i j ∣ \lambda_{ij}=\frac{\partial L_{ij}}{\partial y_{ic} }|\nabla Q_{ij}|=-\frac{\sigma}{1+exp(\sigma(y_{ic}-y_{jc}))}|\nabla Q_{ij}| λij=∂yic∂Lij∣∇Qij∣=−1+exp(σ(yic−yjc))σ∣∇Qij∣
λ i = ∑ ( i , j ∈ I ) λ i j − ∑ ( j , i ∈ I ) λ j i \lambda_i=\sum_{(i,j\in I)}\lambda_{ij}-\sum_{(j,i\in I)}\lambda_{ji} λi=∑(i,j∈I)λij−∑(j,i∈I)λji
假设偏置都是由位置产生的,那么假设位置i在正样本中的点击概率为 t i + t_i^+ ti+,在负样本中被点击的概率为 t i − t_i^- ti−,为了消除位置偏置对于模型训练的影响,在构建损失函数的时候,需要将位置偏置的信息抵消掉。由于 P ( c i + ∣ x i ) = t i + P ( r i + ∣ x i ) P(c_i^+|x_i)=t_i^+P(r_i^+|x_i) P(ci+∣xi)=ti+P(ri+∣xi),其中 P ( c i + ∣ x i ) P(c_i^+|x_i) P(ci+∣xi)代表商品i被点击的概率, P ( r i + ∣ x i ) P(r_i^+|x_i) P(ri+∣xi)代表商品i和当前query相关的概率。于是无偏的Lambda loss损失函数形式为:
λ i j ‘ = λ i j w i + w j − \lambda_{ij}^`=\frac{\lambda_{ij}}{w_i^+w_j^-} λij‘=wi+wj−λij, w i + = t i + m a x x i ∈ Q ( t i + ) w_i^+=\frac{t_i^+}{max_{x_i \in Q(t_i^+)}} wi+=maxxi∈Q(ti+)ti+, w i − = t i − m a x x i ∈ Q ( t i − ) w_i^-=\frac{t_i^-}{max_{x_i \in Q(t_i^-)}} wi−=maxxi∈Q(ti−)ti−。//这里的归一化操作是非常重要的
上述公式直观去理解的话,就是说这里计算出的 λ \lambda λ是把点击概率中由位置导致的影响给去掉了。
而关于参数 t i + t_i^+ ti+和 t i − t_i^- ti−的预估则使用了一个在随机流量下的数据为训练集训练产生的模型(因为是随机流量,可以认为某个商品被点击的概率只和商品的展示位置有关系)。使用一个模型对某个query下的所有位置的偏置进行学习,这里以学习 t i + t_i^+ ti+为例构造正负样本,有点击的为正样本,没有点击的则为负样本。使用的特征形式为 ( v ( Q ) , i ) (v(Q),i) (v(Q),i),其中i代表了商品i的展示位置, v ( Q ) = q u e r y 特 征 ( q u e r y 意 图 , q u e r y 长 度 ) + 用 户 特 征 ( 设 备 , 用 户 平 均 点 击 位 置 ) + i t e m 特 征 ( i t e m 展 示 深 度 ) v(Q)=query特征(query意图,query长度) + 用户特征(设备,用户平均点击位置) + item特征(item展示深度) v(Q)=query特征(query意图,query长度)+用户特征(设备,用户平均点击位置)+item特征(item展示深度)。
最终模型使用pairwise的方式进行训练。这样就能够针对每一个具体的query下的每个位置产生一个准确的位置偏置预估值 t i + t_i^+ ti+。对于 t i − t_i^- ti−的预估过程和 t i + t_i^+ ti+非常相似,只是样本构造的时候,使用无点击数据作为正样本,有点击数据作为负样本,训练所使用特征和损失函数和 t i + t_i^+ ti+过程相似。
当该点击位置概率模型训练好之后,对于线上模型流量下的每个query下的每个位置的点击偏置就会有一个预估值,在基于线上真实流量结合weighted lambda loss进行模型的训练,就会得到相对无偏的预估模型。
这里面需要注意的是,随机流量下展示数据的在这里的用法。
1 用来构造离线训练样本,辅助模型对每个query下位置偏置信息进行学习;
2 可以作为无偏的validation data,来验证离线训练出的模型性能 (在无偏数据集上的离线提升往往会带来线上指标的提升。和常规流量下的weighted NDCG评价指标联合使用,一起对模型进行离线条件下的无偏评估)
下面介绍同样是由美团小伙伴在2021年SIGIR会议上发的paper《Deep Position-wise Interaction Network For CTR Prediction》。其提出了一种独特的思路,来对位置偏置进行建模,作者也认为广告系统中,一个用户是否能能看到一个poi和该poi展示位置最相关。首先作者做了数据分析,发现不同广告搜索query词和不用用户在每个位置上天然的点击权重分布式是不一样的:
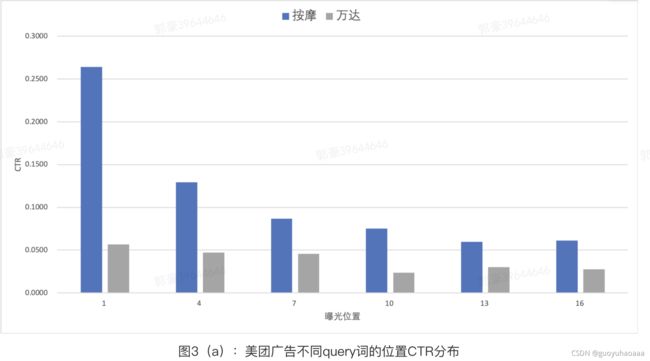
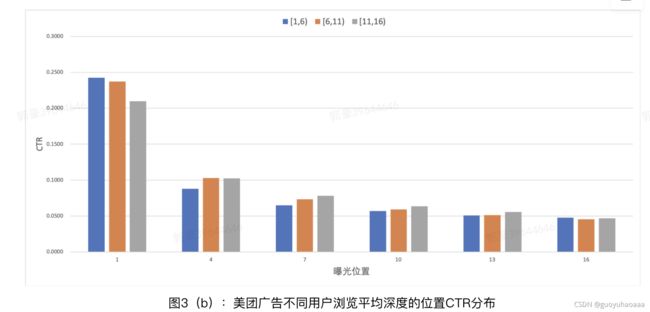
可以看出不同query搜索意图和不同的用户,对每个位置的CTR分布是不一样的(这其实比较符合直觉,以个人的点击偏好为例,有些人就是喜欢货比三家,有些人就是喜欢直接了当。)
为了应对这些问题,作者提出了一个基于深度位置交叉网络,使用多位置预估方法去有效地直接建模 C T R k j = p ( C = 1 ∣ u , c , i , k ) CTR_k^j=p(C=1|u,c,i,k) CTRkj=p(C=1∣u,c,i,k),来提高模型性能,其中是第j个广告在第k个位置的CTR预估值。该模型有效地组合了所有候选广告和位置,以预估每个广告在每个位置的CTR,实现线下线上的一致性。
整体模型结构图如下所示:
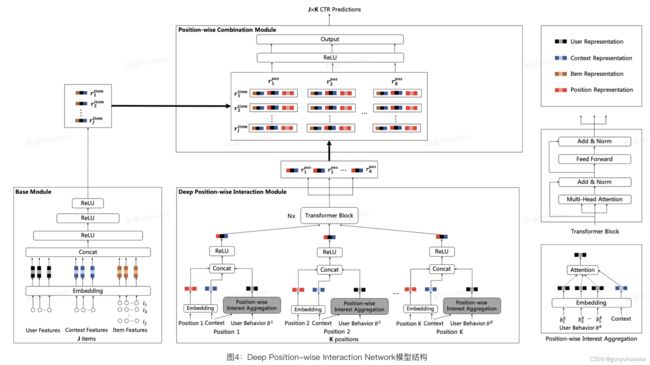
从上图不难看出,DPIN模型由三个模块组成,分别是处理J个候选广告的基础模块(Base Module),处理K个候选位置的深度位置交叉模块(Deep Position-wise Interaction Module)以及组合J个广告和K个位置的位置组合模块(Position-wise Combination Module)。
基础模块
本paper采用Embedding和MLP(多层感知机)的结构作为基础模块。 对于一个特定请求请求,基础模块将用户、上下文和J个候选广告作为输入,将每个特征通过Embedding进行表示,拼接Embedding表示输入多层MLP,采用ReLU作为激活函数,最终可以得到每个广告在该请求下的表示。而且从后续paper的实验部分可以推断出,这里的用户表征只是使用了基础属性和相关的统计属性,用户的历史点击和下单等行为序列转移到了攀比的深度位置交叉模块。
深度位置交叉模块
在深度位置交叉模块中,paper提取用户在每个位置的行为序列,将其用于各位置上的用户兴趣聚合,这样可以消除整个用户行为序列上的位置偏差。接着,我们采用一层非线性全连接层来学习位置、上下文与用户兴趣非线性交叉表示。最后,为了聚合用户在不同位置上的序列信息来保证信息不被丢失,我们采用了Transformer来使得不同位置上的行为序列表示可以进行交互。
位置兴趣聚合(Position-wise Interest Aggregation)。我们令 B k = { b 1 k , b 2 k , . . . . b L k } B_k=\{b_1^k,b_2^k,....b_L^k\} Bk={b1k,b2k,....bLk}为用户在第k个位置的历史行为序列,其中 b l k = [ v l k , c l k ] b_l^k=[v_l^k,c_l^k] blk=[vlk,clk]为用户在第k个位置上的历史第l个行为记录, v l k v_l^k vlk为点击的item特征集合, c l k c_l^k clk为发生该行为时的上下文(包括搜索关键词、请求地理位置、一周中的第几天、一天中的第几个小时等),行为记录的Embedding表示 b l k b_l^k blk可以通过下式得到:
b l k = C o n c a t ( E ( v 1 k l ) , . . . E ( v o k l ) , E ( c 1 k l ) , . . . E ( c n k l ) , E ( d i f k l ) ) b_l^k=Concat(E(v_1^{k_l}),...E(v_o^{k_l}),E(c_1^{k_l}),...E(c_n^{k_l}),E(dif^{k_l})) blk=Concat(E(v1kl),...E(vokl),E(c1kl),...E(cnkl),E(difkl))
其中 d i f k l dif^{k_l} difkl为该行为与当前上下文的时间差。
第k个位置的行为序列的聚合表示 b k b_k bk可以通过attention机制获取:
a l k = C o n c a t ( b l k , c ) W a + b a a_l^k=Concat(b_l^k,c)W_a+b_a alk=Concat(blk,c)Wa+ba
b k = ∑ l = 1 L e x p ( a l k ) ∑ i = 1 L e x p ( a i k ) b l k b_k=\sum_{l=1}^L \frac{exp(a_l^k)}{\sum_{i=1}^Lexp(a_i^k)}b_l^k bk=∑l=1L∑i=1Lexp(aik)exp(alk)blk
位置非线性交叉(Position-wise Non-linear Interaction)。我们采用一层非线性全连接层来学习位置、上下文C与用户兴趣非线性交叉表示,如下式所示:
v k = R e l u ( C o n c a t ( E ( k ) , c , b k ) W v + b v ) v_k=Relu(Concat(E(k),c,b_k)W_v+b_v) vk=Relu(Concat(E(k),c,bk)Wv+bv) 其中 E ( k ) E(k) E(k)代表了位置k的embedding编码信息。
在得到了每个位置k的非线性表征 v k v_k vk之后,引入了多层的Transformer对不位置间的交互关系进行建模。由于这部分针对多层Transformer并没有做很多的创新,具体Transformer就不具体展开说了。
最终,深度位置交叉模块会产出每个位置的深度非线性交叉表示,其中第k个位置被表示为 r k p o s r_k^{pos} rkpos。
位置组合模块
位置组合模块的目的是去组合J个广告和K个位置来预估每个广告在每个位置上的CTR,我们采用一层非线性全连接层来学习广告、位置、上下文和用户的非线性表示,第j个广告在第k个位置上的CTR可以由如下公式得出:
C T R K j = σ ( R e l u ( C o n c a t ( r j i t e m , r k p o s , E ( k ) ) W 1 + b 1 ) W 2 + b 2 ) CTR_K^j=\sigma(Relu(Concat(r_j^{item},r_k^{pos},E(k))W_1+b_1)W_2+b_2) CTRKj=σ(Relu(Concat(rjitem,rkpos,E(k))W1+b1)W2+b2)
其中 r k p o s r_k^{pos} rkpos代表了k位置上的embedding表征信息, r j i t e m r_j^{item} rjitem代表了 i t e m j item_j itemj的embedding信息。
这样就可以得到每一个广告候选集在每一个位置上的点击概率。使用贪心算法,从位置1到位置k,筛选出适合该位置的最佳item。同时作者为了衡量自己的算法针对偏置问题真正解决的效果,提出了PAUC的概念(position wise AUC),即针对每一个位置的曝光点击数据计算AUC的值:
P A U C = ∑ k = 1 K i m p r e s s i o n k P A U C @ K ∑ k = 1 K i m p r e s s i o n k PAUC=\frac{\sum_{k=1}^K impression_kPAUC@K}{\sum_{k=1}^Kimpression_k} PAUC=∑k=1Kimpressionk∑k=1KimpressionkPAUC@K
下面介绍一下微软小伙伴发表的paper《Modeling and Simultaneously Removing Bias via Adversarial Neural Networks》。这批paper利用了对抗网络的思想,尤其是除了显式的position偏置之外,同时消除样本中其他的偏置信息(比如某用户和某个品类的点击率交叉特征,这个特征本身也是存在偏置的,有可能某种品类的展示位置靠前导致了用户对于这种品类的商家点击率特别高)。
整个模型结构还是非常清晰的:
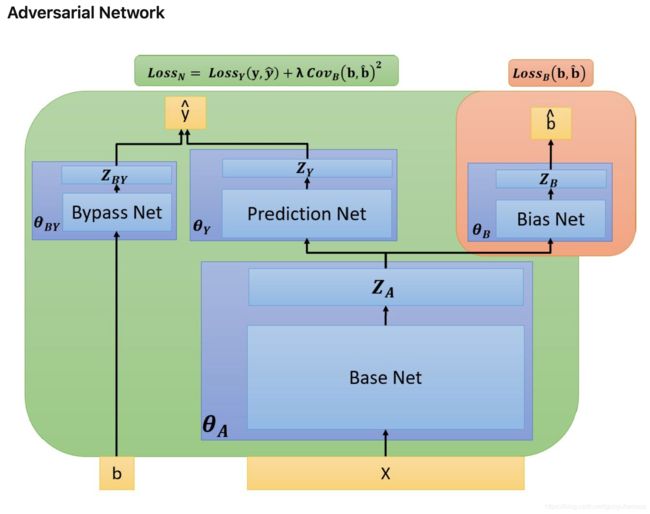
从图中的底色来看,包含了绿色的底色和红色的底色两个部分,这两个部分决定了模型在训练的时候,在一个batch中使用2个阶段进行交替训练。整个模型包含了4个模块:Base Net, Prediction Net, Bypass net 和bias Net。输入的特征x代表了除position之外的其他特征,b代表了position特征。从模型结构来看,这四个部分使用的都是最朴素的MLP+非线性激活函数。
Base Net输出 Z A Z_A ZA会分别输入到bias Net 和 Prediction Net之中,其中Bias Net的训练损失函数是: L o s s b i a s = ∑ i = 0 N ( b i − b i ‘ ) 2 Loss_{bias}=\sum_{i=0}^N (b_i-b_i^`)^2 Lossbias=∑i=0N(bi−bi‘)2,即根据 Z A Z_A ZA的信息去预测偏置信息b,需要注意的是,使用该损失函数的时候 L o s s b i a s Loss_{bias} Lossbias,只对参数 θ B \theta_B θB进行优化;
而最终Bypass Net 和 Prediction Net的结构参照Youtube经典结构的方式,在logits部分进行相加融合,即 y ‘ = s i g m o i d ( l o g i t s ( Z B Y ) + l o g i t s ( Z y ) ) y^`=sigmoid(logits(Z_{BY})+logits(Z_y)) y‘=sigmoid(logits(ZBY)+logits(Zy))
而对抗的概率则体现在最终绿色背景模块的损失函数部分:
L o s s N = L o s s y ( y , y ‘ ) + λ C o v b ( b , b ‘ ) 2 Loss_N=Loss_y(y,y^`)+\lambda Cov_b(b,b^`)^2 LossN=Lossy(y,y‘)+λCovb(b,b‘)2
L o s s y ( y , y ‘ ) = ∑ i = 0 n y i l o g ( y i ‘ ) + ( 1 − y ) l o g ( y i ‘ ) Loss_y(y,y^`)=\sum_{i=0}^ny_ilog(y_i^`)+(1-y)log(y_i^`) Lossy(y,y‘)=∑i=0nyilog(yi‘)+(1−y)log(yi‘)
C o v b ( b , b ‘ ) 2 = ( 1 n − 1 ∑ i = 0 n ( b i − b ‾ ) ( b i ‘ − b ‘ ‾ ) ) 2 Cov_b(b,b^`)^2=(\frac{1}{n-1}\sum_{i=0}^n(b_i-\overline b)(b_i^`-\overline{b^`}))^2 Covb(b,b‘)2=(n−11∑i=0n(bi−b)(bi‘−b‘))2
其中, L o s s y ( y , y ‘ ) Loss_y(y,y^`) Lossy(y,y‘)是用于使分类器准确分类的目标损失函数。 C o v b ( b , b ‘ ) 2 Cov_b(b,b^`)^2 Covb(b,b‘)2则是为了使Base Net 模型将其中和position有相关性的特征弱化的目标损失函数。其也和 L o s s b i a s Loss_{bias} Lossbias形成了对抗的概念。一个是为了尽可能的从 Z A Z_A ZA还原位置信息b,另一个是尽可能的去将位置信息b相关性的特征全部弱化掉。使用该该损失函数 L o s s N Loss_N LossN的时候,对参数 θ Y \theta_Y θY, θ A \theta_A θA, θ B Y \theta_{BY} θBY优化。
当然我们最终也是希望 C o v b ( b , b ‘ ) 2 Cov_b(b,b^`)^2 Covb(b,b‘)2会将 L o s s b i a s Loss_{bias} Lossbias打败,这样Base Net 学习到的特征就不包含位置偏置了。最后在线上进行预测的时候,只使用了Base Net + Prediction Net ,这样的模型具有更好的区偏置能力。