NLP学习笔记(一)
这是一个学习笔记,会有一些学习记录和自己的规划、一些想法......
一、贪心学院第十期豆瓣电影预测评分项目
1.文本转化成向量,将使用三种方式,分别为tf-idf, word2vec以及BERT向量
2.训练逻辑回归和朴素贝叶斯模型,并做交叉验证
3.评估模型的准确率
代码https://github.com/blockpanda/douban
二、代码实现简单SkipGram
理解 Word2Vec 之 Skip-Gram 模型 - 知乎
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
简单说,输入的是中心词,输出的是中心词附近的词,计算每个结果的概率,概率最大的就是最终结果。
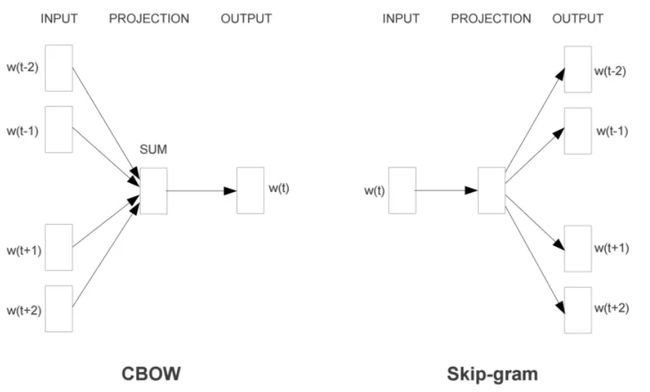
第一部分为建立模型,第二部分是通过模型获取嵌入词向量
1.简历字典 2.独热编码 3.训练 4.输出
输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
代码:GitHub - blockpanda/skipgram
准备学习Prompt
三、prompt
问题:如何用较小的预训练模型充分发挥预训练语言模型作为语言模型的作用,做下游任务。
2017-2019年间,研究者们的重心逐渐从传统task-specific的有监督模式转移到预训练上。基于预训练语言模型的研究思路通常是“pre-train, fine-tune”,即将PLM应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对PLM本体进行调整。
融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 "I love this movie." 这句输入,可以在后面加上prompt "The movie is ___" 这样的形式,然后让PLM用表示情感的答案填空如 "great"、"fantastic" 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
prompt能够帮助PLM“回忆”起自己在预训练时“学习”到的东西,后来慢慢地被叫做Prompt。
具体“Prompt”的做法是,将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,以便更好地利用预训练模型。
prompting 更加依赖先验,而 fine-tuning 更加依赖后验。
openprompt
一般步骤:
1.定义任务
2.选择合适的预训练语言模型
3.定义模板
4.定义映射
5.数据加载与训练
二、相关文献
(1)Schick T, Schütze H. Exploiting cloze questions for few shot text classification and natural language inference[J]. arXiv preprint arXiv:2001.07676, 2020.
这篇没仔细读..........
代码https://github.com/timoschick/pet#/
(2)p-tuning
精髓一:自动化地寻找连续空间中的知识模板;
精髓二:训练知识模板,但不fine-tune语言模型。
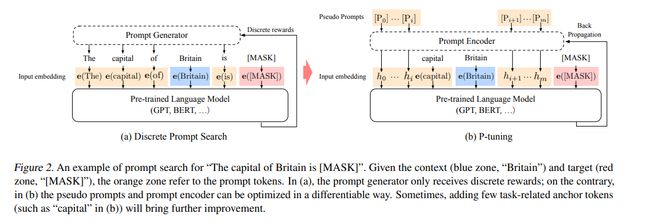
左边:蓝色的Britain是上下文context,红色的[MASK]是目标target;而橙色的the capital of ... is ...是prompt tokens。
右边:把一部分token替换为可以被训练的一个个的稠密向量(dense vectors),相当于在连续空间中去学习一个prompt,给定小量的训练样本,看其是否可以更好地预测。
细化描述:
- 给定一个预训练语言模型: M ;
- 一个离散的输入序列: x1:n={x0,x1,...,xn} ,以及这个序列的经历了嵌入层 e∈M 的输出{e(x0),e(x1),...,e(xn)} ;
- 一个“处理后”的tokens序列, y ,并且它会被用来“参与”下游任务的处理。例如,在BERT预训练里面, x 代表的是未被mask的原始的输入序列, y 代表的是那些被mask掉的词(注意,不包括没有被mask掉的词)。再如,在句子分类里面, x 代表的是原始的句子输入, y 代表的是[CLS];
- 一个prompt p 的功能是组织上下文 x ,目标序列 y ,以及prompt 自己,到一个模板T。例如,在一个预测一个国家的首都的例子中:一个模板T的例子为:“The capital of Britain is [MASK]",这里面,”The capital of ... is ...“是prompt,”Britain“是context,以及[MASK]是目标。
- V 是预训练语言模型 M 的词表;
- [Pi]是模板T中的第i个prompt token;
- 正式地,一个模板T被表示为: T={[P0:i],x,[Pi+1:m],y} ,这里面的每个元素都是一个”token“。
- 经过embedding层之后,上面的模板T可以被表示为: {e([P0:i]),e(x),e([Pi+1:m]),e(y)} 。
- 与上面对应的是,在P-tuning里面,不是使用的一个个离散的prompt tokens,而是把每个[Pi]看成一个pseudo token,并把模板T映射成: {h0,...,hi,e(x),hi+1,...,hm,e(y)} ,这里面, hi(0≤i
- 最后,基于下游的损失函数 L (根据任务的不同,损失函数的具体的计算公式也会不一样),我们可以通过微分操作来最优化连续的prompt hi(0≤i
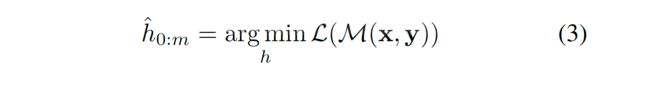
文献:GPT Understands, Too
开源代码: https://github.com/THUDM/ P-tuning
(3)P-tuning v2——全vector prompt
全vecotor可以直接拼接在预训练模型的layer里面,而且这个模型可以做序列tagging任务(给输入序列中每个token打标签)
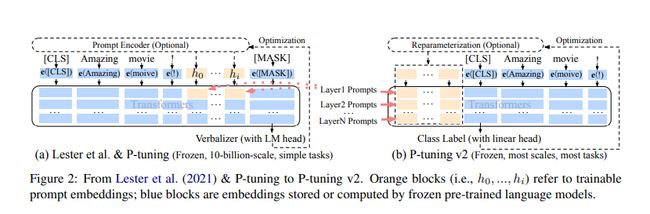
文献: https://arxiv.org/pdf/2110.07602.pdf
开源代码:https://github.com/THUDM/P-tuni
(4)PPT: Pre-trained Prompt Tuning for Few-shot Learning
以上Prompt采用vector形式之后,在训练集比较大(full-data)的时候效果是好的,但是在few-shot(训练集很小)场景下就不好了,因为数据量小不好学嘛。那怎么办呢?既然NLP任务都有预训练模型,那么prompt是否也可以先进行预训练再微调呢?事于是乎PPT(Pre-trained Prompt Tuning)模型就诞生了,这个模型就是拿大量无标签语料对Prompt先做个预训练,再在下游任务上做微调。
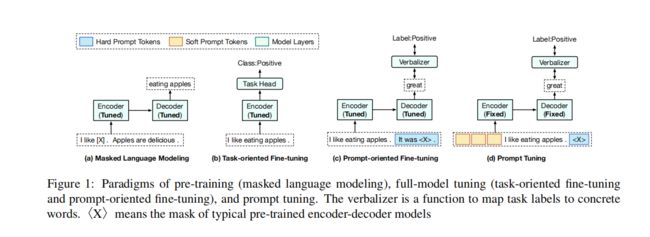
文献:https://arxiv.org/pdf/2109.04332.pdf