A Joint Neural Model for Information Extraction with Global Features论文解读
A Joint Neural Model for Information Extraction with Global Features

code:BLENDER Lab | Software (illinois.edu)或者GerlinGreen/OneIE: Forked from OneIE: A Joint Neural Model for Information Extraction with Global Features (github.com)
paper:A Joint Neural Model for Information Extraction with Global Features (aclanthology.org)
期刊/会议:ACL 2020
摘要
大多数现有的用于信息提取(IE)的联合神经网络模型使用局部任务特定的分类器来预测单个实例(例如,触发词,关系)的标签,而不管它们之间的交互。例如,在同一句话中,死亡事件(die event)的受害者(victim)可能是攻击事件(attack event)的受害者(victim)。为了捕获这种跨子任务和跨实例的相互依赖关系,我们提出了一个联合神经网络框架ONEIE,旨在从输入语句中提取全局最优IE结果作为图。ONEIE执行端到端IE分为四个阶段:**(1)将给定的句子编码为上下文化的单词表示;(2)识别实体提及和事件触发词节点;(3)利用局部分类器计算所有节点及其成对链路的标签得分;(4)利用波束解码器(beam decoder)搜索全局最优图。**在解码阶段,我们结合全局特征来捕获跨子任务和跨实例的交互。实验表明,添加全局特征提高了我们的模型的性能,并在所有子任务上达到了SOTA。由于ONEIE没有使用任何特定的语言特性,我们证明了它可以很容易地应用于新语言或以多语言方式进行训练。我们的英语、西班牙语和中文代码和模型均可公开用于研究目的。
1、简介
信息提取(Information Extraction, IE)旨在从非结构化文本中提取结构化信息。这是一项复杂的任务,由许多子任务组成,如命名命题识别、实体提及抽取、实体链接、实体共指消解、关系提取、事件提取和事件共指消解。早期的工作通常以pipline的方式执行IE,这会导致错误传播问题,并禁止pipline中组件之间的交互。为此,一些研究者提出了联合推理和联合建模的方法来改善局部预测。由于深度学习成功的案例,神经网络广泛地被应用到大量信息抽取子任务中。最近,一些研究者重新审视了全局推理方法,通过设计具有嵌入特征的神经网络来联合建模多个子任务。但是,这些方法在最后一层使用单独的局部特定于任务的分类器,并且没有显式地建模任务和实例之间的相互依赖关系。图1显示了一个真实的示例,其中局部论元角色分类器预测了冗余的 person 边。如果模型能够学习并利用一个Elect事件有两个 person 论元是不寻常的这一事实,那么它应该能够避免这样的错误。

为了解决这个问题,我们提出了一个联合神经网络框架ONEIE,执行全局约束的端到端信息抽取。

如图2所示,ONEIE的目标不是使用局部分类器预测单独的知识元素,而是为输入句子提取全局最优信息网络。在解码过程中比较候选信息网络时,我们不仅考虑每个知识元素的单个标签得分,还考虑网络中的跨子任务和跨实例交互。在本例中,INJURE-VICTIM-ORG(伤害事件(injure event)的受害者(victim)是一个ORG实体)结构的图被降级。实验表明,与最先进的端到端架构相比,我们的框架实现了相当或更好的结果。
2、任务
给出一个句子,我们的ONEIE框架旨在提取一个信息网络表示,其中实体提及和事件触发词表示为节点,关系和事件论元链接表示为边。换句话说,我们在统一的框架内执行实体、关系和事件抽取。在这一节中,我们将详细阐述这些任务和相关的术语。
实体抽取:旨在识别文本中提到的实体,并将其分类为预定义的实体类型。mention可以是名字、名词或代词。例如,“Kashmir region”应该被识别为图2中提到的一个位置(LOC)命名实体。
关系抽取:是将关系类型分配给有序的实体提及对的任务。例如,“Kashmir”与“India”是一种“part-whole”关系。
事件抽取:需要在非结构化文本中识别事件触发词(最清楚地表达事件发生的单词或短语)及其论元(这些事件的参与者的单词或短语),并根据它们的类型和角色分别对这些短语进行分类。论元可以是实体、时间表达或值(例如,金钱、职位、犯罪)。例如,在图2中,单词“injured”触发了INJURE事件(injure event),而“300”是VICTIM论元。
我们将信息网络的抽取任务表述如下。给定一个输入句子,我们的目标是预测一个图 G = ( V , E ) G = (V, E) G=(V,E),其中 V V V和 E E E分别是节点集和边集。每个节点 v i = < a i , b i , l i > ∈ V v_i =
3、方法
如图2所示,我们的ONEIE框架分四个步骤从给定的句子中提取信息网络:编码、识别、分类和解码。我们使用预训练的BERT编码器对输入句子进行编码,并识别句子中的实体提及和事件触发词。之后,我们计算所有节点和其中的成对边的类型标签分数。在解码过程中,我们使用波束搜索(beam search)为输入句子探索可能的信息网络,并返回全局得分最高的信息网络。
3.1 编码
给定一个输入句子有 N N N个单词,我们使用预训练语言模型BERT编码器去获得每一个单词的是上下文表征 x i x_i xi。如果一个单词被分成多个单词片段(例如, M o n d r i a n → M o n , # # d r , # # i a n Mondrian \to Mon,\#\#dr,\#\#ian Mondrian→Mon,##dr,##ian),我们使用所有片段向量的平均值作为它的单词表示。虽然以前的方法通常使用BERT的最后一层输出,但我们的初步研究表明,使用BERT的最后倒数第三层输出来丰富单词表示可以大大提高大多数子任务的性能。
3.2 识别
在这一阶段,我们识别句子中的实体提及和事件触发,它们将作为信息网络中的节点。我们使用前馈网络FFN为每个单词计算得分向量 y ^ i = F F N ( x i ) \hat y_i = FFN(x_i) y^i=FFN(xi),其中 y ^ i \hat y_i y^i中的每个值表示目标标记集合中该标记的得分。在此之后,我们使用条件随机场(CRFs)层来捕获预测标签之间的依赖关系(例如,I-PER标签不应该跟随B-GPE标签)。与Chiu和Nichols类似,我们计算标记路径 z ^ = { z ^ 1 , . . . , z ^ L } \hat z =\{ \hat z_1,...,\hat z_L\} z^={z^1,...,z^L}:
s ( X , z ^ ) = ∑ i = 1 L y ^ i , z ^ i + ∑ i = 1 L + 1 A z ^ i − 1 , z ^ i s(X,\hat z)=\sum_{i=1}^{L} \hat y_{i,\hat z_i} + \sum_{i=1}^{L+1}A_{\hat z_{i-1},\hat z_i} s(X,z^)=i=1∑Ly^i,z^i+i=1∑L+1Az^i−1,z^i
X = { x 1 , . . . , x L } X=\{ x_1,...,x_L\} X={x1,...,xL}是输入句子的上下文表征, y ^ i , z ^ i \hat y_{i,\hat z_i} y^i,z^i是得分向量 y ^ i \hat y_i y^i第 z ^ i \hat z_i z^i部分的得分, A z ^ i − 1 , z ^ i A_{\hat z_{i-1},\hat z_i} Az^i−1,z^i是实体 z ^ i − 1 , z ^ i \hat z_{i-1},\hat z_i z^i−1,z^i在矩阵A中标签 z ^ i − 1 \hat z_{i-1} z^i−1到 z ^ i \hat z_i z^i的迁移得分。我们添加了两个特殊标记到标记路径上,分别表示 z ^ 0 \hat z_0 z^0和 z ^ L + 1 \hat z_{L+1} z^L+1,以表示 < s t a r t >
l o g p ( z ∣ X ) = s ( X , z ) − l o g ∑ z ^ ∈ Z e s ( X , z ^ ) log\ p(z|X)=s(X,z)-log \sum_{\hat z \in Z} e^{s(X,\hat z)} log p(z∣X)=s(X,z)−logz^∈Z∑es(X,z^)
其中 Z Z Z是给定句子中所有可能的标记路径的集合。因此,我们定义识别损失为 L 1 = − l o g p ( z ∣ X ) L_1 =−log \ p(z|X) L1=−log p(z∣X)。
在我们的实现中,我们使用单独的标记器来抽取实体提及和事件触发词。注意,我们不使用标记器预测的类型。相反,我们在解码阶段对所有知识元素进行联合决策,以防止错误传播,并利用它们之间的相互作用来提高节点类型的预测。
3.3 分类
我们通过平均每个已标识的节点的单词表示来将其表示为 v i v_i vi。在此之后,我们使用单独的任务特定前馈网络来计算每个节点的标签得分,表达式为 y ^ i t = F F N t ( v i ) \hat y_i^t=FFN^t(v_i) y^it=FFNt(vi),其中 t t t表示特定的任务。为了获得第 i i i个和第 j j j个节点之间边缘的标签得分向量,我们将它们的span表示连接起来,并将该向量计算为 y ^ k t = F F N t ( v i , v j ) \hat y_k^t=FFN^t(v_i,v_j) y^kt=FFNt(vi,vj)。
对于每一个任务,这个训练的目标都是最小化交叉熵损失:
L t = − 1 N t y i t l o g y ^ i t L^t=-\frac{1}{N^t} y_i^t log\ \hat y_i^t Lt=−Nt1yitlog y^it
y i t y_i^t yit是正确的标签向量, N t N^t Nt是第 t t t个任务的实例数。
如果我们忽略了节点和边之间的相互依赖关系,我们可以简单地预测每个知识元素得分最高的标签,从而生成局部最优图 G ^ \hat G G^。 G ^ \hat G G^的分数可以计算为
s ′ ( G ^ ) = ∑ t ∈ T ∑ i = 1 N t m a x y ^ i t s'(\hat G)=\sum_{t \in T} \sum_{i=1}^{N^t}max\ \hat y_i^t s′(G^)=t∈T∑i=1∑Ntmax y^it
其中 T T T是总的任务数。我们参考 s ′ ( G ^ ) s'(\hat G) s′(G^)作为 G ^ \hat G G^的局部分数。
3.4 全局特征
局部分类器的一个局限性是它们不能捕获信息网络中知识元素之间的相互依赖关系。我们在框架中考虑了两种类型的相互依赖。
第一种类型的相互依赖是实体、关系和事件之间的跨子任务交互。考虑下面的句子。“A civilian aid worker from San Francisco was killed in an attack in Afghanistan”局部分类器可能将“San Francisco”预测为受害者(victim)论元,因为在“was killed”之前提到的实体通常是受害者(victim),尽管GPE不太可能是受害者(victim)。为了施加这样的约束,我们设计了如图3(a)所示的全局特征来评估结构DIE-VICTIM-GPE是否存在于候选图中。
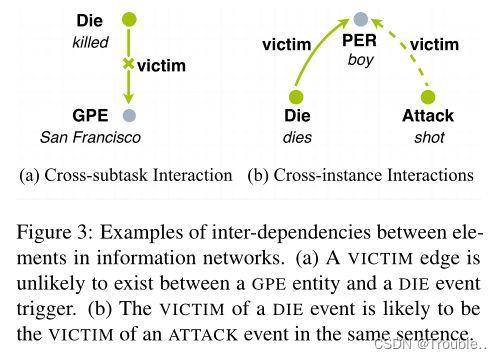
另一种类型的相互依赖是句子中多个事件或关系实例之间的跨实例交互。以下面的句子为例。“South Carolina boy, 9, dies during hunting trip after his father accidentally shot him on Thanksgiving Day.” 对于局部分类器来说,由于“shot”和“boy”之间的距离较远,因此很难预测“boy”是由“shot”触发的ATTACK事件的受害者(victim)。然而,如图3(b)所示,如果一个实体是DIE事件的受害者(victim),那么在同一句话中,它也可能是ATTACK事件的受害者(victim)。

在这些观察的激励下,我们设计了一组全局特征模板(事件模式),如表1所示,以捕获跨子任务和跨实例的交互,同时模型填充所有可能的类型以生成特征,并且在训练中学习每一个特征的权重。给出一个图 G G G,我们呈现出他额全局特征向量 f G = { f 1 ( G ) , . . . , f M ( G ) } f_G=\{ f_1(G),...,f_M (G)\} fG={f1(G),...,fM(G)}, M M M是全局特征的数量, f i ( ⋅ ) f_i (\cdot) fi(⋅)是一个计算某个特性并返回标量的函数:
f i ( G ) = { 1 , G has multiple ATTACK events 0 , otherwise f_{i}(G)=\left\{\begin{array}{l} 1, G \text { has multiple ATTACK events } \\ 0, \text { otherwise } \end{array}\right. fi(G)={1,G has multiple ATTACK events 0, otherwise
接下来,ONEIE学习了一个权重向量 u ∈ R M u \in \R^M u∈RM,将 G G G的全局特征得分计算为 f G f_G fG与 u u u的点积。我们将 G G G的全局得分定义为其局部得分与全局特征得分之和,即
s ( G ) = s ′ ( G ) + u f G s(G)=s'(G)+u f_G s(G)=s′(G)+ufG
我们假设一个句子的正确标准图应该达到最高的全局得分。因此,我们最小化下面的损失函数
L G = s ( G ^ ) − s ( G ) L^G=s(\hat G) - s(G) LG=s(G^)−s(G)
G ^ \hat G G^是通过局部分类器得出的预测图, G G G是正确的标准图。
最后,我们优化训练过程中这个联合的目标函数:
L = L I + ∑ t ∈ T L t + L G L=L^I + \sum_{t \in T} L^t +L^G L=LI+t∈T∑Lt+LG
3.5 解码
正如我们已经讨论过的,由于局部分类器忽略了信息网络中元素之间的相互作用,它们可能会预测相互矛盾的结果,或者无法预测需要来自其他元素的信息的困难边。为了解决这些问题,ONEIE对所有节点及其成对边进行联合决策,以获得全局最优图。基本思想是计算每个候选图的全局得分,并选择得分最高的一个。然而,穷举搜索在很多情况下是不可行的,因为搜索空间的大小会随着节点的数量呈指数增长。因此,我们设计了一个基于波束搜索(beam search)的解码器,如图4所示。

给定一组已识别的节点 V V V和所有节点及其成对链接的标签分数,我们使用初始beam set B = { K 0 } B = \{K_0\} B={K0}执行解码,其中 K 0 K_0 K0是一个零序图。在每一步 i i i,我们在Node step和Edge step中展开 B B B中的每个候选,如下所示。
Node step:我们选择 v i ∈ V v_i \in V vi∈V,定义它的候选集合为 V i = { < a i , b i , l i ( k ) > ∣ 1 ≤ k ≤ β v } V_i = \{
B ← { G + v ∣ ( G , v ) ∈ B × V i } B \leftarrow \{ G+v |(G,v) \in B \times V_i \} B←{G+v∣(G,v)∈B×Vi}
Edge step:我们迭代先前选择的结点 v j ∈ V v_j \in V vj∈V, j < i j j<i并且在结点 v j v_j vj和 v i v_i vi之间添加可能的边。注意到,如果 v i v_i vi是一个触发词,我们将跳过 v j v_j vj,如果 v j v_j vj也是一个触发词。在意每一次迭代之后,我们构建了一个侯选边的集合 E i , j = { < j , i , l i , j ( k ) ∣ 1 ≤ k ≤ β e } E_{i,j}=\{
B ← { G + e ∣ ( G , e ) ∈ B × E i , j } B \leftarrow \{ G+e | (G,e) \in B \times E_{i,j} \} B←{G+e∣(G,e)∈B×Ei,j}
在每个边缘步骤结束时,如果 ∣ B ∣ |B| ∣B∣大于beam宽度 θ \theta θ,我们将所有候选按全局分数降序排列,并保留前 θ \theta θ。在最后一步之后,我们返回全局得分最高的图作为输入句子的信息网络。
4、 实验
4.1 数据

我们在自动内容提取(ACE) 2005 dataset上进行了实验,它为英语、中文和阿拉伯语提供了实体、值、时间、关系和事件标注。在Wadden等人的预处理之后,我们在两个数据集上进行了实验,其中包括命名实体和关系标注的ACE05-R,以及包括实体、关系和事件标注的ACE05-E。我们保留了7种实体类型、6种粗粒度关系类型、33种事件类型和22种论元角色。
为了恢复ACE05-R和ACE05-E中缺少的一些重要元素,我们通过添加关系论元、代词和多token事件触发词的顺序创建了一个新的数据集ACE05-E+,这些元素在以前的工作中基本上被忽略了。我们还跳过
除了ACE之外,我们还从Deep Exploration and Filtering of Test (DEFT)程序下创建的实体、关系和事件(ERE)标注任务中派生出另一个数据集ERE-EN,因为它涵盖了更多最近的文章。具体来说,我们从三个ERE数据集LDC2015E29、LDC2015E68和LDC2015E78中提取了458篇文献和16516句句子。对于ERE-EN,我们保留了7种实体类型、5种关系类型、38种事件类型和20个论元角色。
为了评估模型的可移植性,我们还开发了来自ACE2005的中文数据集和来自ERE (LDC2015E107)的西班牙语数据集。我们将这些数据集分别称为ACE05-CN和ERE-ES。
4.2 实验设置
我们用BertAdam对我们的模型进行了80个epoch的优化,BERT的学习率为5e-5,权重衰减为1e-5,其他参数的学习率为1e-3,权重衰减为1e-3。我们使用bert-base-multilingual-cased模型在ACE05-CN和ERE-ES上进行训练,使用bert-large-cased模型在其他训练数据集上。在Wadden等人之后,我们使用两层FFN,局部分类器的dropout rate为0.4。我们使用150个hidden units进行实体和关系提取,使用600个hidden units进行事件抽取。对于全局特征,我们将 β v \beta_v βv和 β e \beta_e βe设为2, θ \theta θ设为10。在我们的实验中,我们使用随机种子并报告整个运行的平均分数。我们使用Zhang等人和Wadden等人相同的标准进行评估。
实体:如果实体的偏移量和类型与引用实体匹配,则实体的提及是正确的。
关系:如果关系类型和关系尸体体积的偏移量是正确的,则关系是正确的。
触发器:如果触发词的偏移量与引用触发词匹配,则该触发器将被正确标识(Trig-I)。如果它的事件类型也与引用触发词匹配,则它被正确分类(Trig-C)。
参数:如果论元的偏移量和事件类型与引用论元匹配,则论元被正确识别(Arg-I)。如果它的角色标签也匹配引用论元,那么它就被正确分类(Arg-C)。
4.3 总体的效果

在表3中,我们对比了两个模型:DYGIE++(最先进的端到端IE模型,利用多句子BERT编码和跨度图传播);Baseline遵循ONEIE的体系结构,但只使用BERT的最后一层和局部分类器的输出。我们可以看到,我们的模型在ACE05-R和ACE05-E上的表现始终优于DYGIE++和Baseline。
在Wadden等人中,作者表明,结合触发词检测优化的四个模型集成预测的触发词可以提高事件抽取的性能。虽然我们也在表4中使用四个模型集合来报告我们的结果,以进行公平的比较,但我们认为表3中的单模型分数更好地反映了ONEIE的实际性能,应该用于未来的比较。
表5显示了ONEIE在两个新数据集(ACE05-E+和ERE-EN)上的性能。

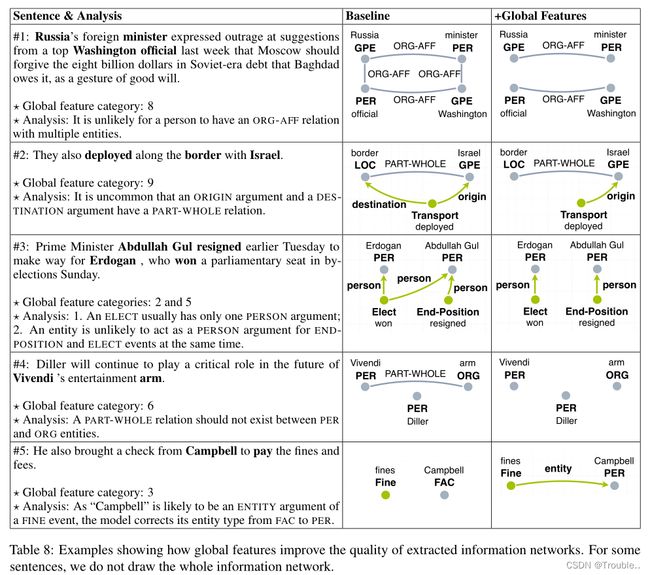
在表6中,我们列出了模型学习到的显著全局特征。以特性9为例,如果一个候选图包含多个ORG-AFF边,该模型将通过在其全局评分中添加一个负值来降级该图。我们还观察到,约9%的全局特征的权重几乎没有更新,这表明它们在正确标准图和预测图中都很少出现。在表8中,我们对具体例子进行定性分析。
4.4 移植到其他语言
如表7所示,我们在ACE05-CN和ERE-ES上评估了所提出的框架。结果表明,ONEIE可以很好地处理中文和西班牙语数据,而无需为新语言进行任何特殊设计。我们还观察到,添加英语训练数据可以提高在汉语和西班牙语的表现。

4.5 存在的挑战
我们分析了剩下的75个错误,在图5中,我们展示了各种错误类型的分布,这些错误类型在未来需要更多的特征和知识获取来解决。在本节中,我们将通过示例讨论一些主要类别。

需要背景知识:目前大多数IE方法忽略了实体属性和场景模型等外部知识。例如以下句子“And Putin’s media aide, Sergei Yastrzhembsky, told Kommersant Russia would not forgive the Iraqi debt”,我们的模型错误地将“Kommersan”识别为个人,而不是组织。在实体连接上,我们根据维基百科页面上的第一句话“Kommersant is a nationally distributed daily newspaper published in Russia mostly devoted to politics and business”来纠正这个错误。
罕见的词:第二个挑战是著名的长尾问题:测试数据中的许多触发词、实体提及(例如“caretaker”、“Gazeta.ru”)和上下文短语很少出现在训练数据中。虽然大多数事件触发词是动词或名词,但一些副词和多词表达也可以作为触发词。
触发词具有多个类型:一些触发词可能同时表示操作的过程和结果状态。例如,“named”可以同时表示NOMINATE和START-POSITION事件;" killed “和” eliminate "可能同时表示ATTACK和DIE事件。在这些情况下,人类基本事实通常只标注过程类型,而我们的系统产生结果事件类型。
需要句法结构:我们的模型可以从更深层次的句法分析中受益。例如,在下面这句话中“As well as previously holding senior positions at Barclays Bank, BZW and Kleinwort Benson, McCarthy was formerly a top civil servant at the Department of Trade and Industry”,我们的模型漏掉了“麦McCarthy”的所有雇主“Barclays Bank”、“BZW”和“Kleinwort Benson”,这可能是因为它们出现在前面的子句中。
不确定事件和隐喻:由于缺乏时态预测和隐喻识别能力,我们的模型错误地将一些未来计划事件标记为具体事件。例如,由“组建”引发的START-ORG并没有出现在下面这句话中:“The statement did not give any reason for the move, but said Lahoud would begin consultations Wednesday aimed at the formation of a new government”。我们的模型还错误地将“camp(营地)”识别为facility(设施),并在下一句“Russia hints ‘peace camp’ alliance with Germany and France is dying by Dmitry Zaks.”中由“dying(死亡)”引发了DIE事件。
IE社区缺少新的带有端到端标注的数据集。遗憾的是,由于长期以来对标注准则的争论,ACE数据集的标注质量并不完美;例如,“goverment(政府)”应该被标记为GPE还是ORG?“dead (死亡)”应该既是实体又是事件触发词吗?我们是否应该将指示词视为提及实体的一部分?
5、相关工作
以前的工作将知识元素之间的相互依赖性编码为整数线性规划框架中的全局约束,以有效地去除抽取误差。这样的完整性验证结果可用于查找违反约束的知识元素,并识别检测器错误或失败的可能实例。受这些先前工作的启发,我们提出了一个具有全局特征的联合神经网络框架,其中在训练过程中学习权重。与Li等人的方法类似,ONEIE也使用全局特征来捕获跨子任务和跨实例的相互依赖关系,而我们的特征是独立于语言的,不依赖于其他NLP工具,如依赖项解析器。我们的方法在局部特征、优化方法和解码过程上也有所不同。
最近的一些研究开发了联合神经网络模型来执行两个IE子任务的抽取,例如实体和关系抽取以及事件和时间关系抽取。Wadden等人设计了一个基于BERT和动态跨度图抽取实体、关系和事件的联合模型。我们的框架通过结合基于跨子任务和跨实例约束的全局特征进行扩展。与Wadden等人使用基于跨度的方法抽取提及不同,我们在框架中采用了基于CRF的标记器,因为它可以抽取任何长度的提及,不受最大跨度宽度的限制。
6、总结和未来工作
我们提出了一个联合的端到端IE框架,它结合了全局特征来捕获知识元素之间的相互依赖关系。实验表明,我们的框架与目前的技术水平获得了更好或相当的性能,并证明了全局特征的有效性。我们的框架也被证明是语言独立的,可以应用于其他语言,它可以从多语言训练中受益。
在未来,我们计划加入更全面的事件模式,从多语言多媒体数据和外部知识自动诱导,以进一步提高IE的质量。我们还计划将我们的框架扩展到更多的IE子任务,如文档级实体共指消解和事件共指消解。