机器学习:鸢尾花数据集8:2划分训练集和测试集,并进行决策树分类算法练习
鸢尾花数据集8:2划分训练集和测试集,并进行决策树分类算法练习
-
- Graphviz的安装
- 训练集、测试集的划分
- 输出训练模型可视化树状图
- 训练模型的精度F1-Score
- 测试集的精度F1-Score
- 遇到的问题
针对鸢尾花数据集,按照80%训练集、20%测试集的划分,进行决策树分类算法的训练(在训练集上)和预测(测试集上)。要求:1)输出训练模型的可视化树状图 ;2)输出训练模型的精度 F1-score;3)输出测试集的精度 F1-score;
Graphviz的安装
决策树要用到Graphviz,所以要先安装。
首先在Graphviz官网上下载Graphviz-2.38.msi
然后进行安装,双击后,一直next就行,默认安装在C:\Program Files (x86)\Graphviz2.38\,可以进入目录查看
进入cmd输入dot -version 命令查看是否安装完成,成功则会显示下面的信息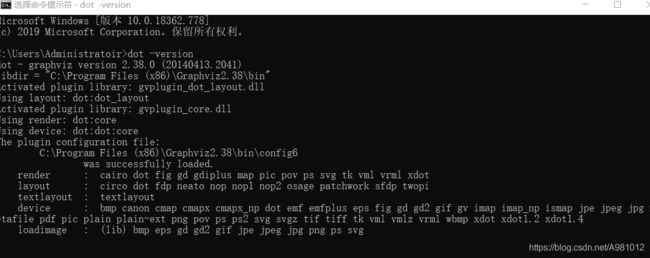
右键此电脑,选择属性
进入属性后,选择高级系统设置
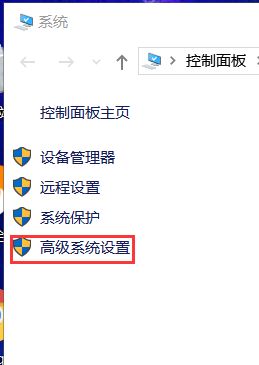
点击进入之后,点击环境变量

找到系统变量,并点击path

然后编辑path,点击新建

将C:\Program Files (x86)\Graphviz2.38\bin添加进去,我当时是默认路径,如果你是其他路径要作相应的更改。然后一直点击确定就可以了,环境的配置就完成了
然后进入Anaconda prompt,使用pip install graphviz下载Graphviz
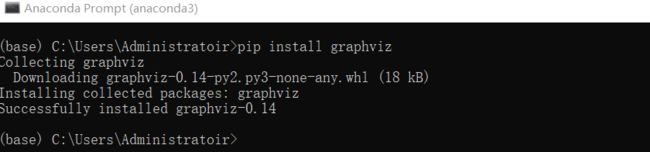
参考博客:https://blog.csdn.net/lizzy05/article/details/88529483.
这个时候开启jupyter进行代码运行,就能看到决策树的显示了。
训练集、测试集的划分
首先读取鸢尾花数据集,并进行训练集和测试集的划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data
y = iris.target
#以8:2划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
然后初始化决策树模型,然后训练模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#初始化决策树模型
dt = DecisionTreeClassifier()
#训练模型
dt.fit(X_train, y_train)
得到的结果为:

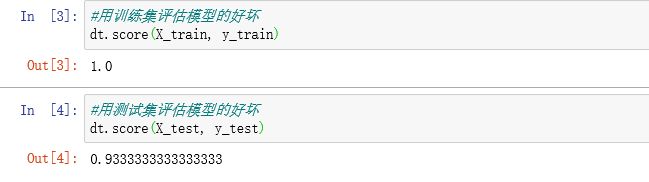
用训练集和测试集来评估模型的好坏
#用训练集评估模型的好坏
dt.score(X_train, y_train)
#用测试集评估模型的好坏
dt.score(X_test, y_test)
得到的结果为:
输出训练模型可视化树状图
已经初始化并训练了决策树模型,现在将决策树可视化
在可视化之前进行一些保存文件路径的准备
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 为了显示中文
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "decision_trees"
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
def save_fig(fig_id, tight_layout=True):
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(image_path(fig_id) + ".png", format='png', dpi=300)
保存文件的路径,要相应的修改为你自己想要保存的路径,但是后面的*.dot这个不能变dot文件的名称是你自己取的,没有这个文件他会自动创建一个dot文件
# 可视化决策树
from sklearn.tree import export_graphviz
export_graphviz(
# 决策树
dt,
# 保存文件路径
out_file=image_path("F:\Anaconda\jupyter-notebook\机器学习Image\df_Iris_tree.dot"),
# 特征名字
feature_names=iris.feature_names[:],
# 类别名
class_names=iris.target_names,
# 绘制带有圆角的框
rounded=True,
# 当设置为“true”时,绘制节点以指示分类、回归极值或节点纯度用于多输出。
filled=True
)
import graphviz
import os
with open(image_path("F:\Anaconda\jupyter-notebook\机器学习Image\df_Iris_tree.dot")) as f:
dot_graph = f.read()
dot=graphviz.Source(dot_graph)
dot.view()
dot
得到的结果为
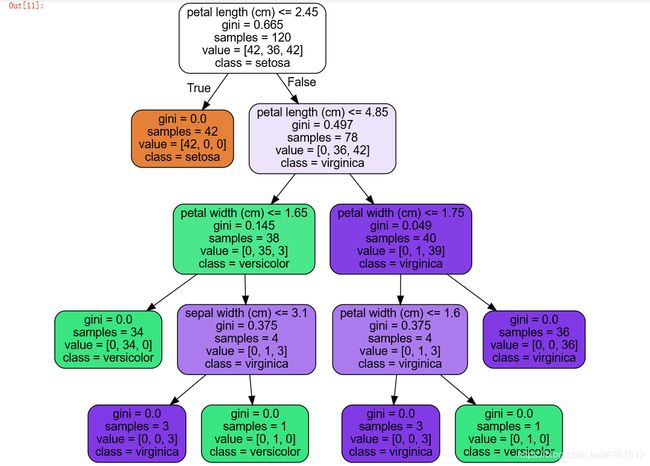
训练模型的精度F1-Score
y_train_pred= dt.predict(X_train) # 获取预测的答案
y_train_pred
#训练结果后的答案
y_train
可以直观的看出预测前后的分类情况

进行训练集精度F1-Score求解
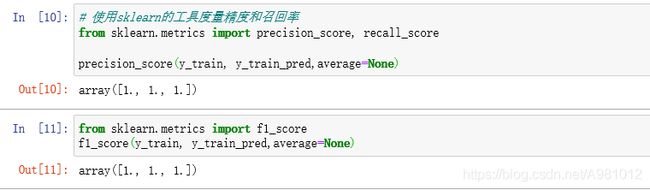
# 使用sklearn的工具度量精度和召回率
from sklearn.metrics import precision_score, recall_score
precision_score(y_train, y_train_pred,average=None)
from sklearn.metrics import f1_score
f1_score(y_train, y_train_pred,average=None)
测试集的精度F1-Score
步骤和代码和训练模型都是差不多的,就是换为了测试集而已
y_test_pred= dt.predict(X_test) # 获取预测的答案
y_test_pred
y_test
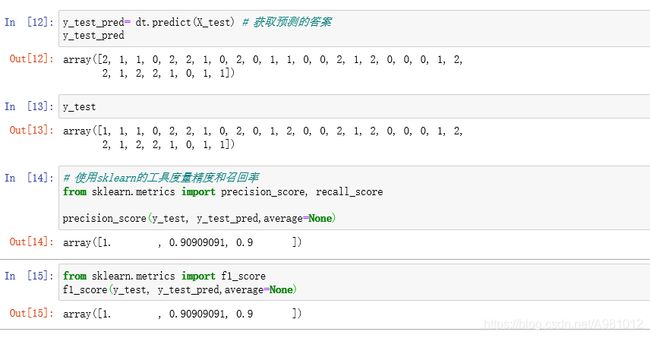
# 使用sklearn的工具度量精度和召回率
from sklearn.metrics import precision_score, recall_score
precision_score(y_test, y_test_pred,average=None)
from sklearn.metrics import f1_score
f1_score(y_test, y_test_pred,average=None)
得到的结果为:
本来还想绘制出ROS曲线,但是最后出现了问题,百度了之后才发现ROS曲线智能在二分类的情况下绘制,鸢尾花的数据集是三类的,所以不能绘制

遇到的问题
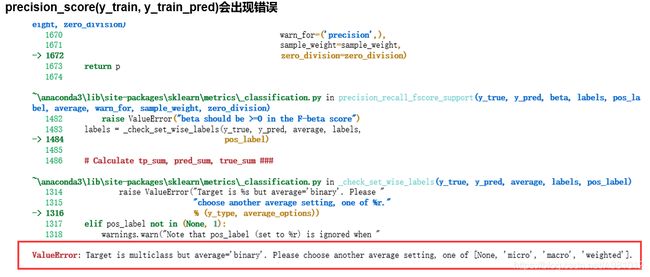
解决方法:就是precision_score(y_train, y_train_pred)将改为precision_score(y_train, y_train_pred,average=None)
https://stackoverflow.com/questions/45890328/sklearn-metrics-for-multiclass-classification
参考:第一部分-机器学习基础 第六章 决策树.ipynb
如有错误请指正!