sklearn笔记19 随机森林和决策树的比较
完整代码 sklearn代码13 3-随机森林
sklearn.ensemble
集成模块包括两种基于随机决策树的平均算法:RandomForest算法和Extra-Trees算法。这两种算法都是专门为树设计的扰动和组合技术(perturb-and-combine techniques)[B1998]。这意味着在分类器构造过程中引入随机性来创建一组不同的分类器的集合。集成之后的预测是每个分类器的平均。
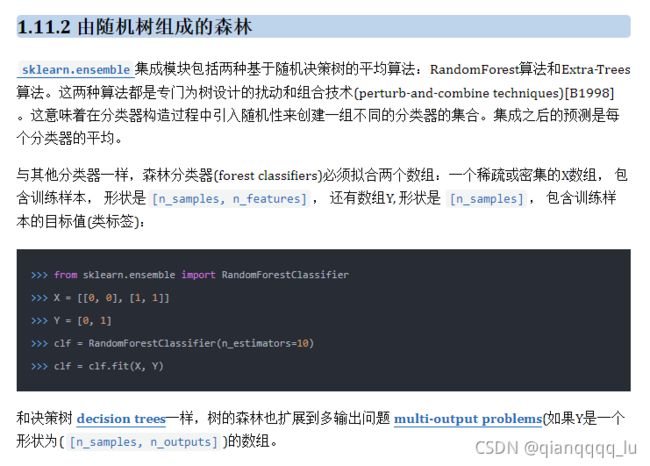
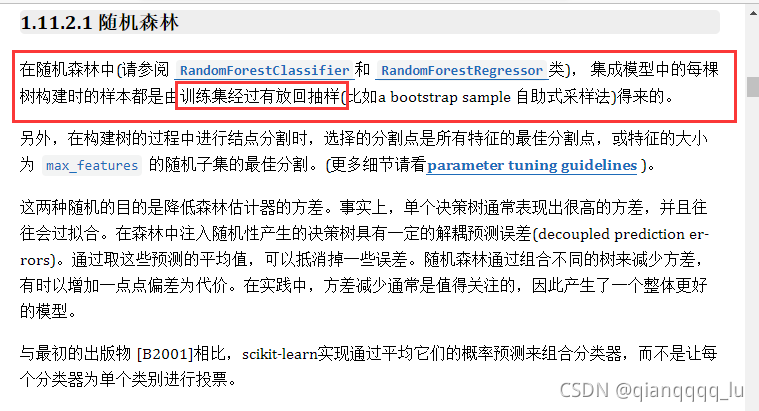
在随机森林中(请参阅RandomForestClassifier和_RandomForestRegressor类),集成模型中的每棵树构建时的样本都是由训练集经过有放回抽样(比如abootstrap sample自助式采样法)得来的。另外,在构建树的过程中进行结点分割时,选择的分割点是所有特征的最佳分割点,或特征的大小为max_features的随机子集的最佳分割。(更多细节请看paramete tuning guidelines )。
这两种随机的目的是降低森林估计器的方差。事实上,单个决策树通常表现出很高的方差,并且往往会过拟合。在森林中注入随机性产生的决策树具有一定的解耦预测误差(decoupled prediction er-rors)。通过取这些预测的平均值,可以抵消掉一些误差。随机森林通过组合不同的树来减少方差,有时以增加一点点偏差为代价。在实践中,方差减少通常是值得关注的,因此产生了一个整体更好的模型。
与最初的出版物[B2001]相比, scikit-learn实现通过平均它们的概率预测来组合分类器,而不是让每个分类器为单个类别进行投票。
X------>y 拟合 对新数据进行预测 过拟合 就相当于走火入魔
需要找到一个普适的关系
import numpy as np
import matplotlib. pyplot as plt
%matplotlib inline
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier
from sklearn import datasets
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
wine = datasets.load_wine()
wine

X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) #划分数据
clf = RandomForestClassifier()
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_)

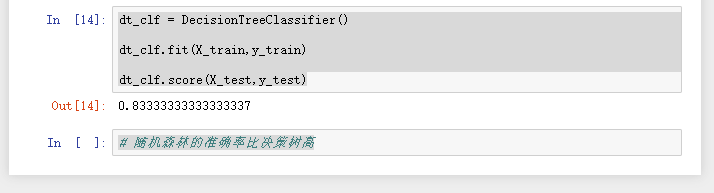
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train,y_train)
dt_clf.score(X_test,y_test)
# 随机森林的准确率比决策树高
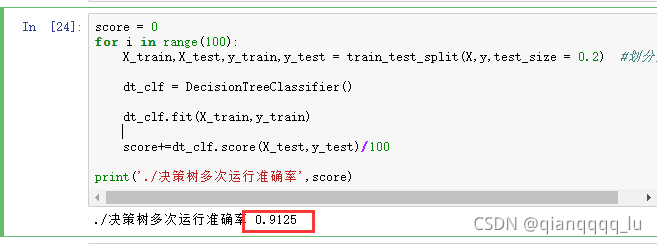
均执行100次来进行比较
score = 0
for i in range(100):
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) #划分数据
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train,y_train)
score+=dt_clf.score(X_test,y_test)/100
print('./决策树多次运行准确率',score)
score = 0
for i in range(100):
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) #划分数据
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
score+=clf.score(X_test,y_test)/100
print('随机森林多次运行准确率',score)
