检测系列--YOLO系列
开头语:RCNN系列,需要区域候选框,即便最后是多任务损失函数,但回归和分类各是一块是很明显的,而yolo要把分类问题转换成回归,这样的話就全是回归。
一.yolo v1
1,介绍,此时输入size要一致448*448

2,框架,googlenet作为主干网络,但注意经过了一些改进,并没有用到多通路做法


3,红色箭头是经改进的googlenet出来的,改进地方在于没有用googlenet多通路做法,而是1x1降维,3x3卷积提取,1x1升维

其中7x7是网格的划分,通道数30=(B*5+C),B是每个网格负责预测的目标个数,5是坐标+置信度,C是类别,每个bound box对应5个参数,B是用来确认是目标还是背景,与C的 每一类概率相乘来确认是哪一类,这里要注意的就是每个box共享一个分类的score.候选框筛选到7*7*B,大大减少了候选框,同时也减少与gt试错的机会.
4,一个格子只预测两个bounding box

5,x,y,w,h要归一化到1

这里的回归四个值主要是中心点x,y(注意相对于格点)和 长宽

图片宽为wi,高为hi,box中心点(相对于格点)为(x,y),宽高比例为(wb,hb),col,row代表格点的列数和行数,S代表划分的行列数,预测的box中心点(相对于大图)为(xc,yc)
先看预测阶段,在逆推回训练阶段就好理解了:
预测阶段:
box相对于格点的中心点为:(wi/S)*x,(hi/S)*y
格点相对于大图的坐标为col*(wi/S),row*(hi/S)
故box相对于大图的中心点为:xc= (wi/S)*x+col*(wi/S), yc = (hi/S)*y+row*(hi/S)
训练阶段,也就是要回归box相对于格点的偏移量也就是求x,y
故x =xc*(S/wi) - col,y =yc*(S/hi) - row,
回归宽高就好理解了,回归w= wb/wi,h = hb/hi.
6.目标×属于每一类的概率得到最大可能性是哪一类

7.loss函数
此时还是比较粗暴,全部采用l2 loss.

上面做法存在的问题是:
1.8维的定位Loss和20维的分类Loss同等重要是不合理的;
2.如果一个网络没有物体,那么loss就由没有物体占主导,会将网络的box置信度push到0,导致网络不稳定。
解决办法:
1.对8维的定位Loss给予更大的权重;
2.对没有物体的box的置信度loss给更小的权重;
为了解决不同大小box造成的偏移loss是一样的,将box的width和height取平方根代替原本的height和width。小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。

8,NMS踢掉剩余的框

9,yolo策略

10,yolo v1效果,因为用到全连接,丢失空间信息故容易产生定位错误

二.yolo v2
其也称为yolo9000.
1,加入bn。

2,取5个anchor boxes

3.每个box都有预测的坐标和类别

4.多尺度训练
每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320*320,最大608*608,网络会自动改变尺寸,并继续训练的过程。
三.yolo v3

backbone采用去除全连接的darknet53,经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
每个ResX包含1+2*x个卷积层,故包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,
1.anchor由yolov2的5个变为9个;
2.不再使用Softmax进行分类,对每一类使用二分类,分类损失也使用二值交叉熵;
3.采用FPN, 其中包含三个特征图尺度,分别下采样32x,16x,8x,每个特征图上设置三种大小的anchors,对应大、中、小,每一个尺度的特征图上可以得到 N × N × [3 ∗ (4 + 1 + 80)] 的结果,分别是N x N个 gird cell ,3种尺度的anchors,x、y、w、h、confidence、80类;
4.由yolov2的darknet-19升级为darknet-53.
四.yolov4
这篇文章写的很详细很全。

- Backbone:CSPDarknet53
- Neck:SPP,PAN
- Head:YOLOv3
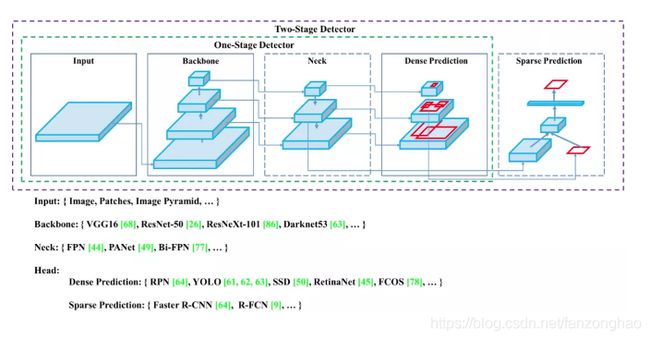

与yolov3差异:
1.CBM:采用的而是Mish激活函数,可看出分类上还是会涨点;
f(x) = x・tanh(ς(x)),ς(x) = ln(1+e^x)

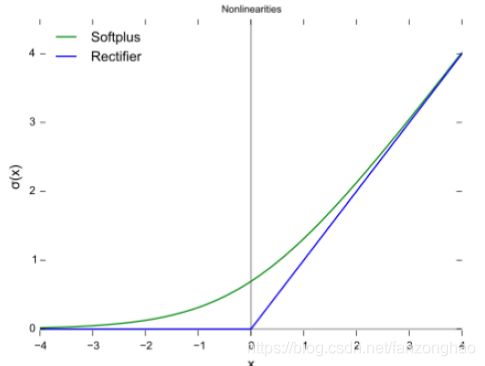
mish ς(x)与relu

2.CSPX:由卷积和X个Res unit模块concate组成,其借鉴的是CSPNet的思想,主要是从网络结构设计的角度解决推理中计算量大的问题,采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率,每个CSPX包括5+2*x个卷积层;
3.SPP:多尺度最大池化;
4.卷积层采用dropblock,类似cutout,只不过cutout作用于输入层数据,而dropblock作用于网络的每一个特征图,将某个局部区域删除丢弃,比dropout力度大;

5.采用PAN结构
其实就是在FPN输出在增加下采样。融合FPN的语义特征和特征金字塔的位置特征。

6.ciou loss
参考我之前写的这篇文章
参考:
https://zhuanlan.zhihu.com/p/136382095
https://zhuanlan.zhihu.com/p/143747206