机器学习100天学习计划 — 第2天 线性回归
AI派在读学生小姐姐Beyonce
Java实战项目练习群
长按识别下方二维码,按需求添加
.jpg")
扫码添加Beyonce小姐姐

扫码关注
进Java学习大礼包
今天是机器学习100天学习计划的第2天,我们将实现一个简单的线性回归模型。
线性回归模型就是基于单一特征(X)来预测结果(Y),回归任务的难点在于找到最佳的拟合线,而我们使用机器学习训练模型的目的就是为了找到这条最佳的拟合线。
构建模型的整个流程如下:
第零步:准备
开始之前,你要确保Python和pip已经成功安装在电脑上。
如果你用Python的目的是数据分析,可以直接安装Anaconda。
准备输入命令安装依赖,如果你没有VSCode编辑器,Windows环境下打开 Cmd (开始-运行-CMD),苹果系统环境下请打开 Terminal (command+空格输入Terminal),如果你用的是VSCode编辑器或Pycharm,可以直接在下方的Terminal中输入命令:
pip install pandas
pip install numpy
pip install matplotlib
pip install scikit-learn第一步:数据预处理
按照第一天学习的数据预处理知识,这一步我们将执行以下步骤:
1.导入库
2.导入数据集
3.检查缺失数据
4.划分数据集
5.特征归一化(缩放)
代码如下,studentscores.csv 和本文完整源代码,可在文章末尾加Beyonce小姐姐索要哦~
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[:, : 1].values
Y = dataset.iloc[:, 1].values
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=1/4, random_state=0)第二步:训练模型
使用 sklearn 的 LinearRegression 能够很轻易地实现一个线性模型的训练。
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)第三步:预测结果
基于 sklearn 优秀的代码封装能力,预测测试集的结果仅需要一行代码:
Y_pred = regressor.predict(X_test)第四步:可视化
单纯看数据不是很直观,我们可以使用 matplotlib 将数据可视化。
在真正的实际生活应用中,使用 matplotlib 进行数据可视化这一步往往是在训练模型之前做的,因为我们拿到数据后该做的第一步是探索性数据分析,也叫EDA分析。
不过因为这是一篇教程似的文章,并没有需要进行探索性数据分析的必要,因此我们略过了EDA分析。
训练集可视化:
plt.scatter(X_train, Y_train, color='red')
plt.plot(X_train, regressor.predict(X_train), color='blue')
plt.show()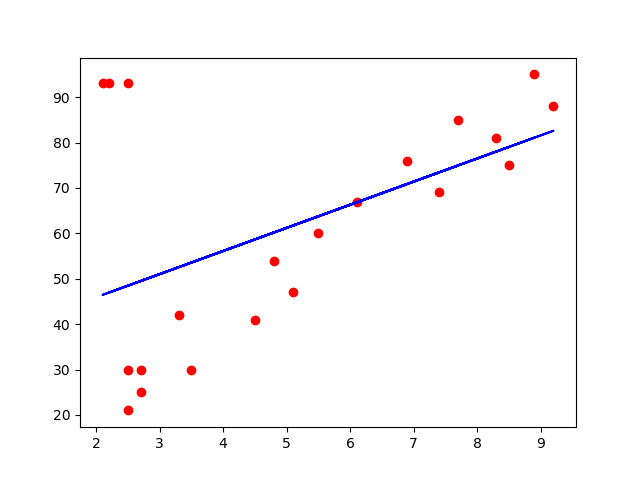
测试集可视化:
plt.scatter(X_test, Y_test, color='red')
plt.plot(X_test, regressor.predict(X_test), color='blue')
plt.show()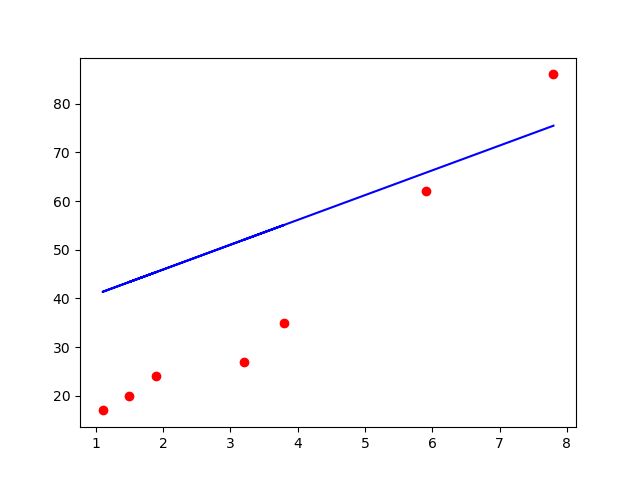
这样,我们便完成了一次简单线性回归模型的训练和测试,还是比较简单的。
文末福利
各位猿们,还在为记不住API发愁吗,哈哈哈,最近发现了国外大师整理了一份Python代码速查表和Pycharm快捷键sheet,火爆国外,这里分享给大家。
这个是一份Python代码速查表

下面的宝藏图片是2张(windows && Mac)高清的PyCharm快捷键一览图

怎样获取呢?可以添加我们的AI派团队的Beyonce小姐姐
一定要备注【高清图】哦
????????????????????

➕我们的Beyonce小姐姐微信要记得备注【高清图】哦
来都来了,喜欢的话就请分享、点赞、在看三连再走吧~~~
