2D CNN
1. 二维卷积模型
1.1. Basic Convolution
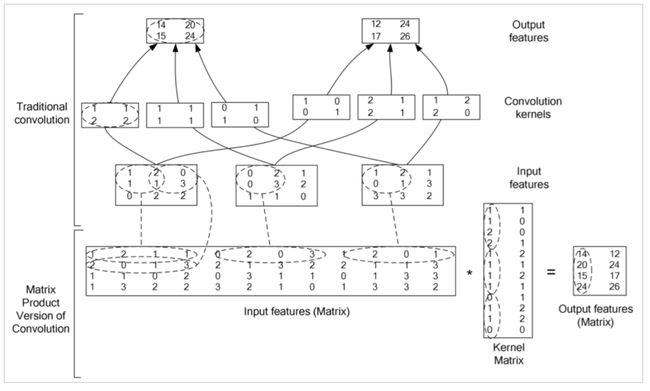
具体到计算中使用cublas的gemm方法。
设输入为nclhw,卷积核为c”cl’h’w’,输出为c”l”h”w”,步长s,补偿p。
输出与输入的关系:L”=(l+2p-l’)/s+1
输入与输出相等时:p=[s(l-1)+l’-l]/2
矩阵相乘:c”*cl’h’w’ 与 nl”h”w”*cl’h’w’ 相乘
1.2. Resnet10

残差结构有利于学习Identify map,bottleneck在中间降维有利于减少参数量。
例:256*3*3*256 à 256*1*1*64 + 64*3*3*64 + 64*1*1*256 = 896*64
1.3. Inception
1.3.1. V111
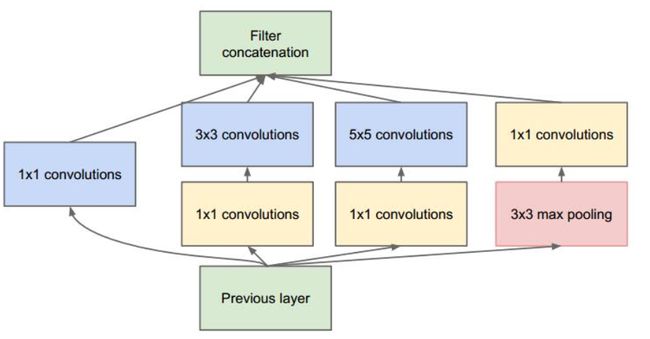
增加了网络宽度,1*1减少了参数量

Global average pooling
1.3.2. V212
使用了batch normalization,5*5 à 3*3 + 3*3

γ和β是scale和shift操作,为了让因训练所需而加入的BN能有可能还原最初的输入。整个操作是为了防止梯度弥散,训练时是按照channel来的,而且在做test时为了使一个样本也可以用BN,往往会记录训练时的均值和方差的统计平均供这里使用。
1.3.3. V313

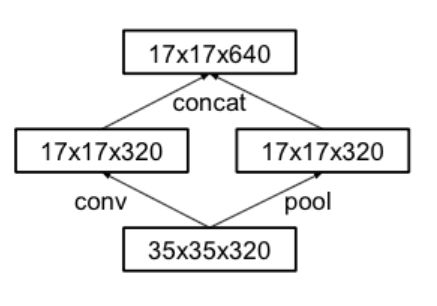
3*3 à 1*3 +3*1
Pool与conv分离
发现辅助分类器无用
1.3.4. V414
增加了残差链接
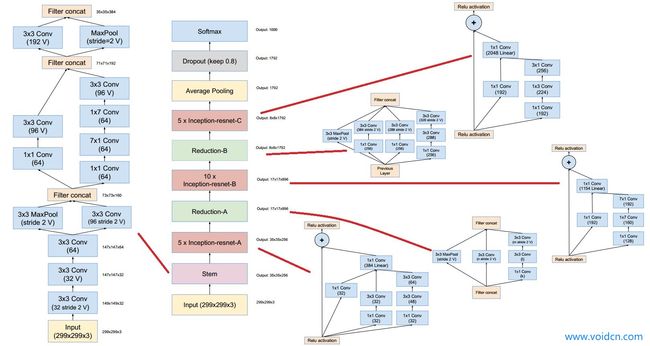
1.3.5. Xception15
将深度的卷积与空间卷积分离
128*3*3*256 à128*3*3*4 + 128*4*1*1*256

Reference:
10. He,K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for imagerecognition. in 770–778 (2016).
11. Herath,S., Harandi, M. & Porikli, F. Going deeper into action recognition: Asurvey.Image Vis. Comput.60, 4–21 (2017).
12. Ioffe,S. & Szegedy, C. Batch normalization: Accelerating deep network training byreducing internal covariate shift.ArXiv Prepr. ArXiv150203167 (2015).
13. Szegedy,C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking theinception architecture for computer vision. in 2818–2826 (2016).
14. Szegedy,C., Ioffe, S., Vanhoucke, V. & Alemi, A. A. Inception-v4, Inception-ResNetand the Impact of Residual Connections on Learning. inAAAI 4278–4284(2017).
15. Chollet,F. Xception: Deep Learning with Depthwise Separable Convolutions.ArXiv161002357Cs (2016).