知识蒸馏概述
知识蒸馏(knowledge distillation)是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。最早是由Hinton在2015年首次提出(Distilling the Knowledge in a Neural Network)并应用在分类任务上面,这个大模型称之为Teacher(教师模型),小模型称之为Student(学生模型)。来自Teacher模型输出的监督信息称之为knowledge(知识),而student学习迁移来自teacher的监督信息的过程称之为Distillation(蒸馏)。
目前知识蒸馏的算法已经广泛应用到图像语义识别,目标检测等场景中,并且针对不同的研究场景,蒸馏方法都做了部分的定制化修改,同时,在行人检测,人脸识别,姿态检测,图像域迁移,视频检测等方面,知识蒸馏也是作为一种提升模型性能和精度的重要方法,随着深度学习的发展,这种技术也会更加的成熟和稳定。
注:Hinton开篇指出,所提方法是为了'压缩模型',KD能够让Student model获取Teacher model的泛化能力,也即让小模型能够干大事情。但KD仍然要训练Teacher model,并且Student model需要依靠Teacher model得到的soft targets,意味着Teacher model是不可或缺,那这样的话,'压缩模型'目的是否真的达到了呢?
压缩模型的对象一般是指的部署上线的模型,而Teacher model只在训练的过程中用到。并且同一个Teacher model可以用于蒸馏多个student model。
1. 知识蒸馏作用
①提升模型精度
用户如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的模型。
②降低模型时延,压缩网络参数
用户如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
③图片标签之间的域迁移
用户使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗,猫,香蕉以及苹果的模型,将两个不同与的数据集进行集成和迁移。
④降低标注量
可以通过半监督的蒸馏方式来实现,用户利用训练好的teacher网络模型来对未标注的数据集进行蒸馏,达到降低标注量的目的。
2. 知识蒸馏原理
KD的训练过程和传统的训练过程的对比:
- 传统training过程(hard targets): 对ground truth求极大似然
- KD的training过程(soft targets): 用large model的class probabilities作为soft targets
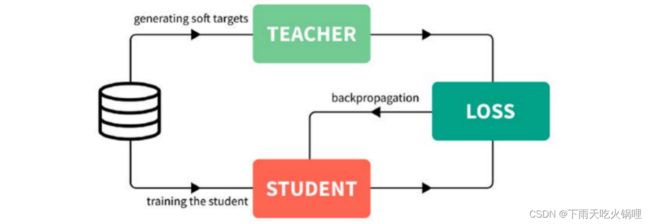
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
例如,在手写体数字识别任务MNIST中,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。
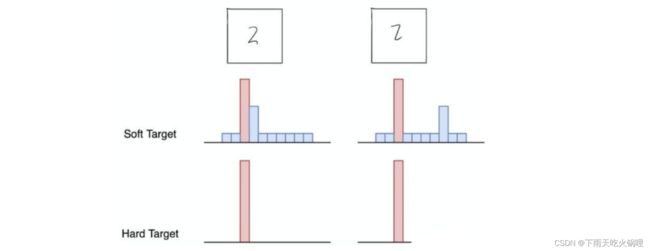
所以,通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型拥有更好的泛化能力。
softmax函数加了温度这个变量:
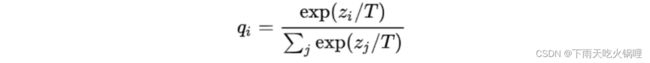
原始的softmax函数是T = 1时的特例, T < 1时,概率分布比原始更“陡峭”, T > 1时,概率分布比原始更“平缓”。温度越高,softmax上各个值的分布就越平均。
温度的高低改变的是Net-S训练过程中对负标签的关注程度: 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Net-S会相对多地关注到负标签。

知识蒸馏第一步是训练Net-T;第二步是在高温T下,蒸馏Net-T的知识到Net-S。
主要是第二步:高温蒸馏的过程
![]() 目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
①Net-S在相同温度T条件下的softmax输出和soft target的cross entropy就是Loss函数的第一部:

②Net-S在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分: