OpenCV算法加速(4)官方源码v4.5.5的默认并行和优化加速的编译选项是什么?请重点关注函数cv::getBuildInformation()的返回值
举例opencv v4.5.5版本源码,Windows x64,VS2019,CMake
https://github.com/opencv/opencv/tree/4.5.5
https://sourceforge.net/projects/opencvlibrary/files/4.5.5/
下载安装opencv-4.5.5-vc14_vc15.exe,得到官方编译的动态库opencv_world455.dll
1、多线程并行库的使用情况
PPL
\opencv\sources\modules\core\src\parallel.cpp,里面默认使用的是微软PPL加速方式,
#if defined _MSC_VER && _MSC_VER >= 1600
#define HAVE_CONCURRENCY
#endifcmake里面的编译选项,其他方式如TBB,HPX,OPENMP默认是关闭的。

![]()
\opencv\sources\x64\cvconfig.h,里面有宏定义的。
/* Halide support */
/* #undef HAVE_HALIDE */
/* Intel Integrated Performance Primitives */
/* #undef HAVE_IPP */
/* #undef HAVE_IPP_ICV */
/* #undef HAVE_IPP_IW */
/* #undef HAVE_IPP_IW_LL */
/* Intel Threading Building Blocks */
/* #undef HAVE_TBB */
/* Ste||ar Group High Performance ParallelX */
/* #undef HAVE_HPX */
/* OpenVX */
/* #undef HAVE_OPENVX */2、GPU之OpenCL
cmake里面的编译选项,默认是开启OpenCL的。
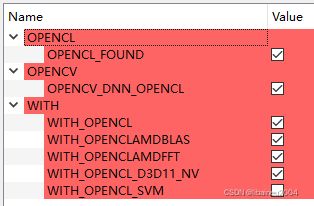
\opencv\sources\x64\cvconfig.h
/* OpenCL Support */
#define HAVE_OPENCL
/* #undef HAVE_OPENCL_STATIC */
/* #undef HAVE_OPENCL_SVM */
/* NVIDIA OpenCL D3D Extensions support */
#define HAVE_OPENCL_D3D11_NVGPU之CUDA
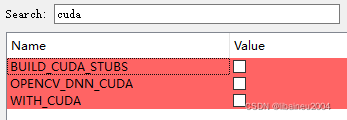
cmake里面的编译选项,默认是禁用CUDA的。需要用户自己勾选,并下载库编译。
3、SIMD指令集优化选项

cmake编译选项,\opencv\sources\x64\cvconfig.h,宏定义CV_ENABLE_INTRINSICS默认是开启的
#ifndef OPENCV_CVCONFIG_H_INCLUDED
#define OPENCV_CVCONFIG_H_INCLUDED
/* OpenCV compiled as static or dynamic libs */
#define BUILD_SHARED_LIBS
/* OpenCV intrinsics optimized code */
#define CV_ENABLE_INTRINSICS
/* OpenCV additional optimized code */
/* #undef CV_DISABLE_OPTIMIZATION */
cmake编译选项,\opencv\sources\x64\cv_cpu_config.h
// OpenCV CPU baseline features
#define CV_CPU_COMPILE_SSE 1
#define CV_CPU_BASELINE_COMPILE_SSE 1
#define CV_CPU_COMPILE_SSE2 1
#define CV_CPU_BASELINE_COMPILE_SSE2 1
#define CV_CPU_COMPILE_SSE3 1
#define CV_CPU_BASELINE_COMPILE_SSE3 1
#define CV_CPU_BASELINE_FEATURES 0 \
, CV_CPU_SSE \
, CV_CPU_SSE2 \
, CV_CPU_SSE3 \
// OpenCV supported CPU dispatched features
#define CV_CPU_DISPATCH_COMPILE_SSE4_1 1
#define CV_CPU_DISPATCH_COMPILE_SSE4_2 1
#define CV_CPU_DISPATCH_COMPILE_FP16 1
#define CV_CPU_DISPATCH_COMPILE_AVX 1
#define CV_CPU_DISPATCH_COMPILE_AVX2 1
#define CV_CPU_DISPATCH_COMPILE_AVX512_SKX 1
#define CV_CPU_DISPATCH_FEATURES 0 \
, CV_CPU_SSE4_1 \
, CV_CPU_SSE4_2 \
, CV_CPU_FP16 \
, CV_CPU_AVX \
, CV_CPU_AVX2 \
, CV_CPU_AVX512_SKX \关于OpenCV硬件加速,OpenCV Hardware Acceleration Layer(HAL),请参考博文:
OpenCV中的HAL方法调用流程分析 - willhua - 博客园OpenCV中的HAL方法调用流程分析 在OpenCV中有一些所谓HAL(Hardware Acceleration Layer)实现,看名字好像和硬件相关,其实也不尽然,可以理解为比常规的OCV实现https://www.cnblogs.com/willhua/p/12521581.html
4、IPP加速
Intel® Integrated Performance Primitives (简称Intel® IPP)是一个软件库,提供了大量的函数。包括信号处理、图像处理、计算机视觉、数据压缩和字符串操作。通过对函数的优化,比如适配指令集操作等来提升运行效率。
完整版的IPP下载地址:
https://www.intel.com/content/www/us/en/developer/tools/oneapi/ipp.html
在 Learning OpenCV 这本书中,作者提到OpenCV可以利用Intel的IPP性能库来提升程序的运行速度,而这个IPP库是要另外进行购买的。实际上,Intel为当前的OpenCV免费提供了IPP加速库的一部分,在此我们称之为ippicv。ippicv会在cmake的时候自动从github上下载,但是在网络状况不佳的情况下会下载失败。这时候我们只能采用手动安装的方式。ippicv的下载地址其实就藏在ippicv.cmake文件中。
https://github.com/opencv/opencv/blob/4.5.5/3rdparty/ippicv/ippicv.cmake
里面的变量组合起来就是ippicv的下载网址:
https://raw.githubusercontent.com/opencv/opencv_3rdparty/a56b6ac6f030c312b2dce17430eef13aed9af274/ippicv/ippicv_2020_win_intel64_20191018_general.zip
或者直接访问这个网址也可以获得:
https://github.com/opencv/opencv_3rdparty/tree/ippicv/master_20191018/ippicv
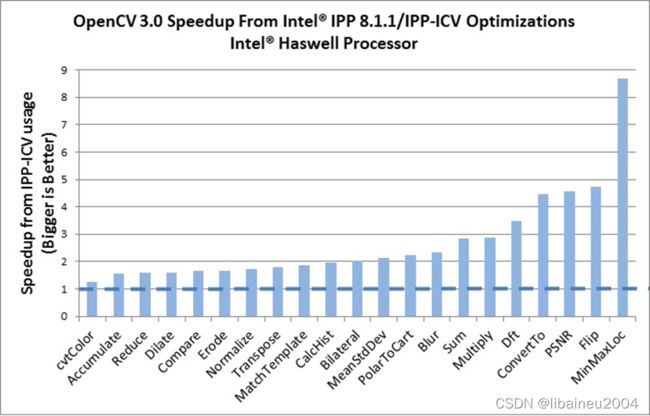
如果在英特尔的处理器上使用,OpenCV就会自动使用一种免费的英特尔集成性能原语库(IPP)的子集,IPP 8.x(IPPICV)。IPPICV可以在编译阶段链接到OpenCV,这样一来,会替代相应的低级优化的C语言代码(在cmake中设置WITH_IPP=ON/OFF开启或者关闭这一功能,默认情况为开启)。使用IPP获得的速度提升非常可观,如下图显示了使用IPP之后得到的加速效果。

5、怎么知道当前OpenCV开启了哪些加速模式?
源码\opencv\sources\modules\core\src\system.cpp,有专门的函数设置和查看优化的情况:
volatile bool useOptimizedFlag = true;
void setUseOptimized( bool flag )
{
useOptimizedFlag = flag;
currentFeatures = flag ? &featuresEnabled : &featuresDisabled;
ipp::setUseIPP(flag);
#ifdef HAVE_OPENCL
ocl::setUseOpenCL(flag);
#endif
}
bool useOptimized(void)
{
return useOptimizedFlag;
}
void setUseIPP(bool flag)
{
CoreTLSData& data = getCoreTlsData();
#ifdef HAVE_IPP
data.useIPP = (getIPPSingleton().useIPP)?flag:false;
#else
CV_UNUSED(flag);
data.useIPP = false;
#endif
}\opencv\sources\modules\core\src\ocl.cpp
void setUseOpenCL(bool flag)
{
if (!flag)
useOpenCL_ = 0;
else
useOpenCL_ = -1;
}已知宏HAVE_OPENCL是已定义的,HAVE_IPP也是已定义的。所以OpenCL和IPP的功能默认是启动的。
可以通过以下测试用例,来查询当前的opencv是否开启了OPENCL和IPP
#include
#include
#include
#include
#include
#include
#include
void checkIPP()
{
bool use = cv::ipp::useIPP();
bool useNE = cv::ipp::useIPP_NotExact();
int status = cv::ipp::getIppStatus();
cv::String ver = cv::ipp::getIppVersion();
cv::String loc = cv::ipp::getIppErrorLocation();
std::cout << "IPP use:" << use << std::endl;
std::cout << "IPP useNE:" << useNE << std::endl;
std::cout << "IPP status:" << status << std::endl;
std::cout << "IPP ver:" << ver << std::endl;
std::cout << "IPP loc:" << loc << std::endl;
}
void checkOCL()
{
//查询opencv当前是否开启了OpenCL功能
bool ret1 = cv::ocl::haveOpenCL();
bool ret2 = cv::ocl::useOpenCL();
std::cout << "default haveOpenCL:" << ret1 << std::endl;
std::cout << "default useOpenCL:" << ret2 << std::endl;
} 6、最后,举例来看看canny算子的优化情况是什么?
\opencv\sources\modules\imgproc\src\canny.cpp,源码有宏定义#if CV_SIMD,
如果使能了宏定义CV_SIMD,就会开启指令集的优化源码。CV_SIMD默认是开启的,在头文件
\opencv\sources\modules\core\include\opencv2\core\hal\intrin.hpp,有定义
#if (CV_SSE2 || CV_NEON || CV_VSX || CV_MSA || CV_WASM_SIMD || CV_RVV071 || CV_RVV) && !defined(CV_FORCE_SIMD128_CPP)
#define CV__SIMD_FORWARD 128
#include "opencv2/core/hal/intrin_forward.hpp"
#endif
#if CV_SSE2 && !defined(CV_FORCE_SIMD128_CPP)
#include "opencv2/core/hal/intrin_sse_em.hpp"
#include "opencv2/core/hal/intrin_sse.hpp"
namespace CV__SIMD_NAMESPACE {
#define CV_SIMD CV_SIMD128另外,canny算子默认是开启了PPL并行计算的,并且也默认开启了对OpenCL和IPP的支持,一起来看看源码\opencv\sources\modules\imgproc\src\canny.cpp,
void Canny( InputArray _src, OutputArray _dst,
double low_thresh, double high_thresh,
int aperture_size, bool L2gradient )
{
......
CV_OCL_RUN(_dst.isUMat() && (_src.channels() == 1 || _src.channels() == 3),
ocl_Canny(_src, UMat(), UMat(), _dst, (float)low_thresh, (float)high_thresh, aperture_size, L2gradient, _src.channels(), size))
......
CALL_HAL(canny, cv_hal_canny, src.data, src.step, dst.data, dst.step, src.cols, src.rows, src.channels(),
low_thresh, high_thresh, aperture_size, L2gradient);
......
CV_IPP_RUN_FAST(ipp_Canny(src, Mat(), Mat(), dst, (float)low_thresh, (float)high_thresh, L2gradient, aperture_size))
......
parallel_for_(Range(0, src.rows), parallelCanny(src, map, stack, low, high, aperture_size, L2gradient), numOfThreads);
......
}
void Canny( InputArray _dx, InputArray _dy, OutputArray _dst,
double low_thresh, double high_thresh,
bool L2gradient )
{
......
CV_OCL_RUN(_dst.isUMat(),
ocl_Canny(UMat(), _dx.getUMat(), _dy.getUMat(), _dst, (float)low_thresh, (float)high_thresh, 0, L2gradient, _dx.channels(), size))
......
CV_IPP_RUN_FAST(ipp_Canny(Mat(), dx, dy, dst, (float)low_thresh, (float)high_thresh, L2gradient, 0))
......
parallel_for_(Range(0, dx.rows), parallelCanny(dx, dy, map, stack, low, high, L2gradient), numOfThreads);
......
} \opencv\sources\modules\imgproc\src\hal_replacement.hpp
inline int hal_ni_canny(const uchar* src_data, size_t src_step, uchar* dst_data, size_t dst_step,
int width, int height, int cn, double lowThreshold, double highThreshold, int ksize, bool L2gradient)
{ return CV_HAL_ERROR_NOT_IMPLEMENTED; }
//! @cond IGNORED
#define cv_hal_canny hal_ni_canny
//! @endcond注意:
(1)CV_OCL_RUN有参数_dst.isUMat(),表明OpenCL需要使用UMat作为图像格式的输入,否则会失效;
(2)CALL_HAL是硬件加速,但是深入源码却发现返回值是CV_HAL_ERROR_NOT_IMPLEMENTED,表明该功能官方暂时未实现。
(3)以上两个如果都不执行,那么就执行CV_IPP_RUN_FAST(ipp_Canny...
\opencv\sources\modules\core\include\opencv2\core\private.hpp
#define CV_IPP_RUN_(condition, func, ...) \
{ \
if (cv::ipp::useIPP() && (condition)) \
{ \
CV__TRACE_REGION_("IPP:" #func, CV_TRACE_NS::details::REGION_FLAG_IMPL_IPP) \
if(func) \
{ \
CV_IMPL_ADD(CV_IMPL_IPP); \
} \
else \
{ \
setIppErrorStatus(); \
CV_Error(cv::Error::StsAssert, #func); \
} \
return __VA_ARGS__; \
} \
}
#else
#define CV_IPP_RUN_(condition, func, ...) \
if (cv::ipp::useIPP() && (condition)) \
{ \
CV__TRACE_REGION_("IPP:" #func, CV_TRACE_NS::details::REGION_FLAG_IMPL_IPP) \
if(func) \
{ \
CV_IMPL_ADD(CV_IMPL_IPP); \
return __VA_ARGS__; \
} \
}
#endif
#else
#define CV_IPP_RUN_(condition, func, ...)
#endif
#define CV_IPP_RUN_FAST(func, ...) CV_IPP_RUN_(true, func, __VA_ARGS__)
#define CV_IPP_RUN(condition, func, ...) CV_IPP_RUN_((condition), (func), __VA_ARGS__)x、写个测试用例,请重点关注函数cv::getBuildInformation()
#include
#include
#include
#include
#include
#include
#include
#define IMAGE_PATHNAME "D:\\allike\\Image_20210707220543807.jpg"
void checkBuild()
{
//查询opencv编译时配置
std::cout << cv::getBuildInformation() << std::endl;
}
void checkIPP()
{
bool use = cv::ipp::useIPP();
bool useNE = cv::ipp::useIPP_NotExact();
int status = cv::ipp::getIppStatus();
cv::String ver = cv::ipp::getIppVersion();
cv::String loc = cv::ipp::getIppErrorLocation();
std::cout << "IPP use:" << use << std::endl;
std::cout << "IPP useNE:" << useNE << std::endl;
std::cout << "IPP status:" << status << std::endl;
std::cout << "IPP ver:" << ver << std::endl;
std::cout << "IPP loc:" << loc << std::endl;
}
void checkSimd()
{
//查询opencv线程
int numTh = cv::getNumThreads(); //默认值是cpu的逻辑线程数
int numCore = cv::getNumberOfCPUs();
std::cout << "getNumThreads=" << numTh << std::endl;
std::cout << "getNumberOfCPUs=" << numCore << std::endl;
//查询opencv当前是否开启了并行优化功能
bool opt = cv::useOptimized(); //默认值是true
std::cout << "useOptimized=" << opt << std::endl;
//查询opencv当前是否开启了OpenCL功能
bool ret1 = cv::ocl::haveOpenCL();
bool ret2 = cv::ocl::useOpenCL();
std::cout << "default haveOpenCL:" << ret1 << std::endl;
std::cout << "default useOpenCL:" << ret2 << std::endl;
//查询opencv当前是否支持具体的CPU指令集
bool check1 = cv::checkHardwareSupport(CV_CPU_SSE4_1);
bool check2 = cv::checkHardwareSupport(CV_CPU_SSE4_2);
bool check3 = cv::checkHardwareSupport(CV_CPU_AVX2);
std::cout << "CV_CPU_SSE4_1=" << check1 << std::endl;
std::cout << "CV_CPU_SSE4_2=" << check2 << std::endl;
std::cout << "CV_CPU_AVX2=" << check3 << std::endl;
//查询完整的硬件支持清单
std::cout << "HardwareSupport:" << std::endl;
std::cout << "CV_CPU_MMX: " << cv::checkHardwareSupport(CV_CPU_MMX) << std::endl;
std::cout << "CV_CPU_SSE: " << cv::checkHardwareSupport(CV_CPU_SSE) << std::endl;
std::cout << "CV_CPU_SSE2: " << cv::checkHardwareSupport(CV_CPU_SSE2) << std::endl;
std::cout << "CV_CPU_SSE3: " << cv::checkHardwareSupport(CV_CPU_SSE3) << std::endl;
std::cout << "CV_CPU_SSSE3: " << cv::checkHardwareSupport(CV_CPU_SSSE3) << std::endl;
std::cout << "CV_CPU_SSE4_1: " << cv::checkHardwareSupport(CV_CPU_SSE4_1) << std::endl;
std::cout << "CV_CPU_SSE4_2: " << cv::checkHardwareSupport(CV_CPU_SSE4_2) << std::endl;
std::cout << "CV_CPU_POPCNT: " << cv::checkHardwareSupport(CV_CPU_POPCNT) << std::endl;
std::cout << "CV_CPU_FP16: " << cv::checkHardwareSupport(CV_CPU_FP16) << std::endl;
std::cout << "CV_CPU_AVX: " << cv::checkHardwareSupport(CV_CPU_AVX) << std::endl;
std::cout << "CV_CPU_AVX2: " << cv::checkHardwareSupport(CV_CPU_AVX2) << std::endl;
std::cout << "CV_CPU_FMA3: " << cv::checkHardwareSupport(CV_CPU_FMA3) << std::endl;
std::cout << "CV_CPU_AVX_512F: " << cv::checkHardwareSupport(CV_CPU_AVX_512F) << std::endl;
std::cout << "CV_CPU_AVX_512BW: " << cv::checkHardwareSupport(CV_CPU_AVX_512BW) << std::endl;
std::cout << "CV_CPU_AVX_512CD: " << cv::checkHardwareSupport(CV_CPU_AVX_512CD) << std::endl;
std::cout << "CV_CPU_AVX_512DQ: " << cv::checkHardwareSupport(CV_CPU_AVX_512DQ) << std::endl;
std::cout << "CV_CPU_AVX_512ER: " << cv::checkHardwareSupport(CV_CPU_AVX_512ER) << std::endl;
std::cout << "CV_CPU_AVX_512IFMA512: " << cv::checkHardwareSupport(CV_CPU_AVX_512IFMA512) << std::endl;
std::cout << "CV_CPU_AVX_512IFMA: " << cv::checkHardwareSupport(CV_CPU_AVX_512IFMA) << std::endl;
std::cout << "CV_CPU_AVX_512PF: " << cv::checkHardwareSupport(CV_CPU_AVX_512PF) << std::endl;
std::cout << "CV_CPU_AVX_512VBMI: " << cv::checkHardwareSupport(CV_CPU_AVX_512VBMI) << std::endl;
std::cout << "CV_CPU_AVX_512VL: " << cv::checkHardwareSupport(CV_CPU_AVX_512VL) << std::endl;
std::cout << "CV_CPU_NEON: " << cv::checkHardwareSupport(CV_CPU_NEON) << std::endl;
std::cout << "CV_CPU_VSX: " << cv::checkHardwareSupport(CV_CPU_VSX) << std::endl;
std::cout << "CV_CPU_AVX512_SKX: " << cv::checkHardwareSupport(CV_CPU_AVX512_SKX) << std::endl;
std::cout << "CV_HARDWARE_MAX_FEATURE: " << cv::checkHardwareSupport(CV_HARDWARE_MAX_FEATURE) << std::endl;
std::cout << std::endl;
//cv::setUseOptimized(false);
//cv::setNumThreads(1);
}
void checkCuda() //旧版本的是cv::gpu,#include ,已弃用
{
int64 begintime, endtime;
int num_devices = cv::cuda::getCudaEnabledDeviceCount();
if (num_devices <= 0)
{
std::cerr << "There is no cuda device" << std::endl;
return;
}
int enable_device_id = -1;
for (int i = 0; i < num_devices; i++)
{
cv::cuda::DeviceInfo dev_info(i);
if (dev_info.isCompatible())
{
enable_device_id = i;
}
}
if (enable_device_id < 0)
{
std::cerr << "GPU module isn't built for GPU" << std::endl;
return;
}
cv::cuda::setDevice(enable_device_id); //指定显卡
//有一个问题是,一般使用GPU加速的话,第一次调用GPU,会很慢很慢,一条简单的语句都用了10多秒左右。
//治标不治本的解决方法是在程序的开头加上一句cv::gpu::GpuMata(10, 10, CV_8U);
//这样会令耗时的操作放在一开头,不那么影响后面的操作时间
cv::cuda::GpuMat(10, 10, CV_8U);
//测试用例
cv::Mat src_image = cv::imread(IMAGE_PATHNAME);
cv::Mat dst_image;
cv::cuda::GpuMat d_src_img(src_image); //upload src image to gpu
cv::cuda::GpuMat d_dst_img;
begintime = cv::getTickCount();
cv::cvtColor(d_src_img, d_dst_img, cv::COLOR_BGR2GRAY); //canny
d_dst_img.download(dst_image); //download dst image to cpu
endtime = cv::getTickCount();
std::cerr << 1000 * (endtime - begintime) / cv::getTickFrequency() << std::endl;
cv::imshow("test", dst_image);
cv::waitKey(0);
}
void checkOpenCL() //Open Computing Language:开放计算语言,可以附加在主机处理器的CPU或GPU上执行
{
std::vector info;
cv::ocl::getPlatfomsInfo(info);
cv::ocl::PlatformInfo sdk = info.at(0);
int number = sdk.deviceNumber();
if (number < 1)
{
std::cout << "Number of devices:" << number << std::endl;
return;
}
std::cout << "***********SDK************" << std::endl;
std::cout << "Name:" << sdk.name() << std::endl;
std::cout << "Vendor:" << sdk.vendor() << std::endl;
std::cout << "Version:" << sdk.version() << std::endl;
std::cout << "Version:" << sdk.version() << std::endl;
std::cout << "Number of devices:" << number << std::endl;
for (int i = 0; i < number; i++)
{
std::cout << std::endl;
cv::ocl::Device device;
sdk.getDevice(device, i);
std::cout << "***********Device " << i + 1 << "***********" << std::endl;
std::cout << "Vendor Id:" << device.vendorID() << std::endl;
std::cout << "Vendor name:" << device.vendorName() << std::endl;
std::cout << "Name:" << device.name() << std::endl;
std::cout << "Driver version:" << device.vendorID() << std::endl;
if (device.isAMD())
std::cout << "Is AMD device" << std::endl;
if (device.isIntel())
std::cout << "Is Intel device" << std::endl;
if (device.isNVidia())
std::cout << "Is NVidia device" << std::endl;
std::cout << "Global Memory size:" << device.globalMemSize() << std::endl;
std::cout << "Memory cache size:" << device.globalMemCacheSize() << std::endl;
std::cout << "Memory cache type:" << device.globalMemCacheType() << std::endl;
std::cout << "Local Memory size:" << device.localMemSize() << std::endl;
std::cout << "Local Memory type:" << device.localMemType() << std::endl;
std::cout << "Max Clock frequency:" << device.maxClockFrequency() << std::endl;
}
}
void calcEdgesCPU()
{
cv::ocl::setUseOpenCL(false);
bool ret1 = cv::ocl::haveOpenCL();
bool ret2 = cv::ocl::useOpenCL();
std::cout << "haveOpenCL:" << ret1 << std::endl;
std::cout << "useOpenCL:" << ret2 << std::endl;
double start = cv::getTickCount();
cv::Mat cpuGray, cpuBlur, cpuEdges;
cv::Mat cpuFrame = cv::imread(IMAGE_PATHNAME);
cvtColor(cpuFrame, cpuGray, cv::COLOR_BGR2GRAY);
cv::GaussianBlur(cpuGray, cpuBlur, cv::Size(3, 3), 15, 15);
cv::Canny(cpuBlur, cpuEdges, 50, 100, 3);
std::vector cir;
//cv::HoughCircles(cpuBlur, cir, cv::HOUGH_GRADIENT_ALT, 1.5, 15, 300, 0.8, 1, 100);
//cv::HoughCircles(cpuBlur, cir, cv::HOUGH_GRADIENT, 1, 15, 100, 30, 1, 100);
std::cout << "CPU cost time:(s)" << ((cv::getTickCount() - start) / cv::getTickFrequency()) << std::endl;
cv::namedWindow("Canny Edges CPU", cv::WINDOW_NORMAL);
cv::imshow("Canny Edges CPU", cpuEdges);
}
void calcEdgesGPU()
{
cv::ocl::setUseOpenCL(true);
bool ret1 = cv::ocl::haveOpenCL();
bool ret2 = cv::ocl::useOpenCL();
std::cout << "haveOpenCL:" << ret1 << std::endl;
std::cout << "useOpenCL:" << ret2 << std::endl;
//通过使用UMat对象,OpenCV会自动在支持OpenCL的设备上使用GPU运算,在不支持OpenCL的设备仍然使用CPU运算,这样就避免了程序运行失败,而且统一了接口。
double start = cv::getTickCount();
cv::UMat gpuFrame, gpuGray, gpuBlur, gpuEdges;
cv::Mat cpuFrame = cv::imread(IMAGE_PATHNAME);
cpuFrame.copyTo(gpuFrame); //Mat与UMat相互转换
cvtColor(gpuFrame, gpuGray, cv::COLOR_BGR2GRAY);
cv::GaussianBlur(gpuGray, gpuBlur, cv::Size(3, 3), 15, 15);
cv::Canny(gpuBlur, gpuEdges, 50, 100, 3);
std::vector cir;
//cv::HoughCircles(gpuBlur, cir, cv::HOUGH_GRADIENT_ALT, 1.5, 15, 300, 0.8, 1, 100);
//cv::HoughCircles(gpuBlur, cir, cv::HOUGH_GRADIENT, 1, 15, 100, 30, 1, 100);
std::cout << "GPU cost time:(s)" << ((cv::getTickCount() - start) / cv::getTickFrequency()) << std::endl;
cv::Mat matResult = gpuEdges.getMat(cv::ACCESS_READ); //Mat与UMat相互转换
cv::namedWindow("Canny Edges GPU1", cv::WINDOW_NORMAL);
cv::imshow("Canny Edges GPU1", matResult);
cv::namedWindow("Canny Edges GPU2", cv::WINDOW_NORMAL);
cv::imshow("Canny Edges GPU2", gpuEdges);
}
int main(int argc, char *argv[])
{
checkBuild();
checkIPP();
checkSimd();
checkCuda();
checkOpenCL();
calcEdgesCPU();
calcEdgesGPU();
cv::waitKey(0);
return 0;
} cv::getBuildInformation()得到的结果是:
General configuration for OpenCV 4.5.5 =====================================
Version control: 4.5.5
Platform:
Timestamp: 2021-12-25T04:33:15Z
Host: Windows 10.0.19041 AMD64
CMake: 3.16.4
CMake generator: Visual Studio 15 2017
CMake build tool: C:/Program Files (x86)/Microsoft Visual Studio/2017/Professional/MSBuild/15.0/Bin/MSBuild.exe
MSVC: 1916
Configuration: Debug Release
CPU/HW features:
Baseline: SSE SSE2 SSE3
requested: SSE3
Dispatched code generation: SSE4_1 SSE4_2 FP16 AVX AVX2 AVX512_SKX
requested: SSE4_1 SSE4_2 AVX FP16 AVX2 AVX512_SKX
SSE4_1 (16 files): + SSSE3 SSE4_1
SSE4_2 (1 files): + SSSE3 SSE4_1 POPCNT SSE4_2
FP16 (0 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 AVX
AVX (4 files): + SSSE3 SSE4_1 POPCNT SSE4_2 AVX
AVX2 (31 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 FMA3 AVX AVX2
AVX512_SKX (5 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 FMA3 AVX AVX2 AVX_512F AVX512_COMMON AVX512_SKX
C/C++:
Built as dynamic libs?: YES
C++ standard: 11
C++ Compiler: C:/Program Files (x86)/Microsoft Visual Studio/2017/Professional/VC/Tools/MSVC/14.16.27023/bin/Hostx86/x64/cl.exe (ver 19.16.27042.0)
C++ flags (Release): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /MP2 /MD /O2 /Ob2 /DNDEBUG
C++ flags (Debug): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /MP2 /MDd /Zi /Ob0 /Od /RTC1
C Compiler: C:/Program Files (x86)/Microsoft Visual Studio/2017/Professional/VC/Tools/MSVC/14.16.27023/bin/Hostx86/x64/cl.exe
C flags (Release): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /MP2 /MD /O2 /Ob2 /DNDEBUG
C flags (Debug): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /MP2 /MDd /Zi /Ob0 /Od /RTC1
Linker flags (Release): /machine:x64 /INCREMENTAL:NO
Linker flags (Debug): /machine:x64 /debug /INCREMENTAL
ccache: NO
Precompiled headers: NO
Extra dependencies:
3rdparty dependencies:
OpenCV modules:
To be built: calib3d core dnn features2d flann gapi highgui imgcodecs imgproc ml objdetect photo stitching video videoio world
Disabled: python2 python3
Disabled by dependency: -
Unavailable: java ts
Applications: apps
Documentation: NO
Non-free algorithms: NO
Windows RT support: NO
GUI:
Win32 UI: YES
VTK support: NO
Media I/O:
ZLib: build (ver 1.2.11)
JPEG: build-libjpeg-turbo (ver 2.1.2-62)
WEBP: build (ver encoder: 0x020f)
PNG: build (ver 1.6.37)
TIFF: build (ver 42 - 4.2.0)
JPEG 2000: build (ver 2.4.0)
OpenEXR: build (ver 2.3.0)
HDR: YES
SUNRASTER: YES
PXM: YES
PFM: YES
Video I/O:
DC1394: NO
FFMPEG: YES (prebuilt binaries)
avcodec: YES (58.134.100)
avformat: YES (58.76.100)
avutil: YES (56.70.100)
swscale: YES (5.9.100)
avresample: YES (4.0.0)
GStreamer: NO
DirectShow: YES
Media Foundation: YES
DXVA: YES
Parallel framework: Concurrency
Trace: YES (with Intel ITT)
Other third-party libraries:
Intel IPP: 2020.0.0 Gold [2020.0.0]
at: C:/build/master_winpack-build-win64-vc15/build/3rdparty/ippicv/ippicv_win/icv
Intel IPP IW: sources (2020.0.0)
at: C:/build/master_winpack-build-win64-vc15/build/3rdparty/ippicv/ippicv_win/iw
Eigen: NO
Custom HAL: NO
Protobuf: build (3.19.1)
OpenCL: YES (NVD3D11)
Include path: C:/build/master_winpack-build-win64-vc15/opencv/3rdparty/include/opencl/1.2
Link libraries: Dynamic load
Python (for build): C:/utils/soft/python27-x64/python.exe
Java:
ant: C:/utils/soft/apache-ant-1.9.7/bin/ant.bat (ver 1.9.7)
JNI: C:/Program Files/Java/jdk1.8.0_112/include C:/Program Files/Java/jdk1.8.0_112/include/win32 C:/Program Files/Java/jdk1.8.0_112/include
Java wrappers: NO
Java tests: NO
Install to: C:/build/master_winpack-build-win64-vc15/install
-----------------------------------------------------------------