决策树算法——拟合优化
一、决策树算法原理
上一篇文章简单、直接、粗暴的使用了决策树算法对鸢尾花数据集进行分类,关于决策树算法的原理,以我的理解:就是用能最大概率的区分不同类别标签的特征值作为分裂节点。
常用的算法是:CART 和 ID3 算法。
CART 算法采用gini系数最小的来决定使用哪种特征来进行分裂;
ID3算法采用信息增益最大的特征来决定使用哪种特征来进行分裂;
二、决策树的最优参数
这次的数据集使用稍微复杂一点的泰坦尼克号预测生死的数据。
重复的代码不啰嗦,直接上
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv(r'data.csv',index_col=0)
data.drop(['Cabin','Name','Ticket','Embarked'],inplace=True,axis=1)
data['Age']=data['Age'].fillna(data['Age'].mean())
data=data.dropna()
data['Sex']=data['Sex'].replace(to_replace=['female','male'],value=[1,0])
初步完成了缺失值的填充和删除处理,以及将性别替换成哑变量。
接下来,将数据集分成特征值和标签值。
x=data.iloc[:,1:]
y=data.iloc[:,0]
切分训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
xtrain,xtest,ytrain,ytest=train_test_split(x,y,test_size=0.3,random_state=25)
这里有两种方式找到最优参数,一种是自己写代码,找到最优参数。
还有一种是调用别人写好的函数。
1、自己写代码找最优参数
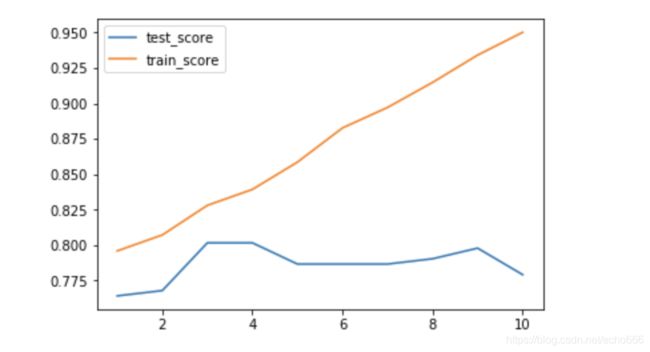
计算不同深度下决策树的训练集和测试集的得分
xs=np.arange(1,11)
depth_no=[]
for x in xs:
clf=DecisionTreeClassifier(max_depth=x,random_state=25)
clf.fit(xtrain,ytrain)
cte=clf.score(xtest,ytest)
ctr=clf.score(xtrain,ytrain)
depth_no.append([x,cte,ctr])
使用matplotlib画出正确率的曲线图
depth_no=pd.DataFrame(data=depth_no)
plt.plot(depth_no[0],depth_no[1],label='test_score')
plt.plot(depth_no[0],depth_no[2],label='train_score')
plt.legend()
plt.show()
决策树最容易出现的就是过拟合问题,随着树的深度越来越深,训练集的正确率越来越高,但是测试集的效果反而下降。
由图可以看出,树的深度在3的时候,拟合效果较好。
2、调用别人写好的函数
导包
from sklearn.model_selection import GridSearchCV
给参数
para={
'max_depth':[*range(1,10)],
'min_samples_leaf':[*range(1,50,5)],
'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
给定决策树算法,填入训练集,自动给出最优参数。
clf=DecisionTreeClassifier(criterion='entropy')
GS=GridSearchCV(clf,para,cv=10)
GS=GS.fit(xtrain,ytrain)
GS.best_params_
这里给出的最优深度是3,和作图得到的结果是一致的。

最后就是将得到的最优参数带入到算法中
clf=DecisionTreeClassifier(max_depth=3,min_impurity_decrease=0,min_samples_leaf=1,random_state=25)
clf.fit(xtrain,ytrain)
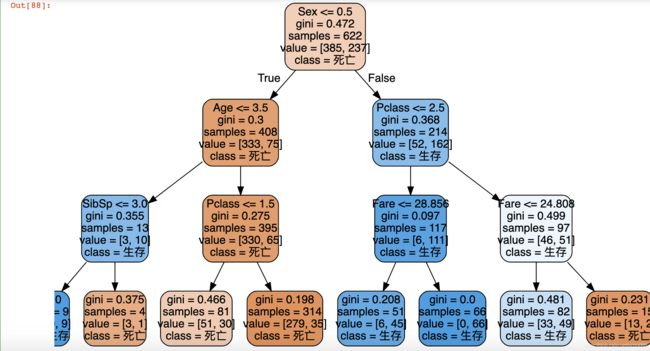
想看决策树的样子,和之前的一样
import graphviz
from sklearn import tree
dot_data=tree.export_graphviz(clf,out_file=None,feature_names=x.columns,class_names=['死亡','生存'],filled=True,rounded=True)
graph=graphviz.Source(dot_data)
graph