【Python机器学习】卷积神经网络卷积层、池化层、Flatten层、批标准化层的讲解(图文解释)
卷积神经网络
卷积神经网络(convolutional neural network, CNN)在提出之初被成功应用于手写字符图像识别,2012年的AlexNet网络在图像分类任务中取得成功,此后,卷积神经网络发展迅速,现在已经被广泛应用于图形、图像、语音识别等领域。
图片的像素数往往非常大,如果用多层全连接网络来处理,则参数数量将大到难以有效训练的地步。受猫脑研究的启发,卷积神经网络在多层全连接网络的基础上进行了改进,它在不减少层数的前提下有效提升了训练速度。卷积神经网络在多个研究领域都取得了成功,特别是在与图形有关的分类任务中。
卷积层和池化层是卷积神经网络的核心组成,它们和全连接层可以组合成很深层次的网络。卷积神经网络还可以按需要添加用来抑制过拟合的Dropout层、拉平多维数据的Flatten层、加快收敛和抑制梯度消散的BatchNormalization层等等。
卷积层
二维卷积层Conv2d的输入是:input_shape=(28,28,1)。这与前文讨论的所有机器学习模型的输入都不同,前文模型的输入是一维向量,该一维向量要么是经特征工程提取出来的特征,要么是被拉成一维的图像数据。而这里卷积层的输入是图片数据组成的多维数据。
MNIST图片中,只有一种颜色,通常称灰色亮度。MNIST图片的维度是(28,28,1),前面两维存储28×28个像素点的坐标位置,后面1维表示像素点的灰色亮度值,因此它是28×28的单通道数据。
从数学上来讲,卷积是一种积分变换。在深度学习中,它用来做数据的卷积运算,在图像处理领域取得了非常好的效果。
单通道数据上的卷积运算包括待处理张量I、卷积核K和输出张量S三个组成部分,它们的大小分别为4×4、3×3和2×2。
记待处理的张量为I,卷积核为K,每一次卷积运算可表述为:
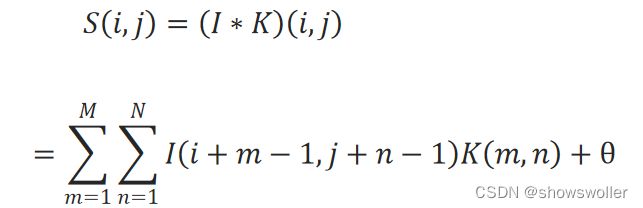
式中,I∗K表示卷积运算,M和N分别表示卷积核的长度和宽度。i,j是待处理张量I的坐标位置,也是卷积核左上角对齐的位置
记待处理张量I的长度和宽度为P和Q,则输出张量S的长度P^′和Q^′宽度分别为:

虽然要扫描整个输入层,但一个通道只有一个卷积核,因此,对于整个输入层来说,前向传递计算时的参数是一样的,这称为参数共享(parameter sharing)。参数共享大大减少了需要学习的参数的数量。
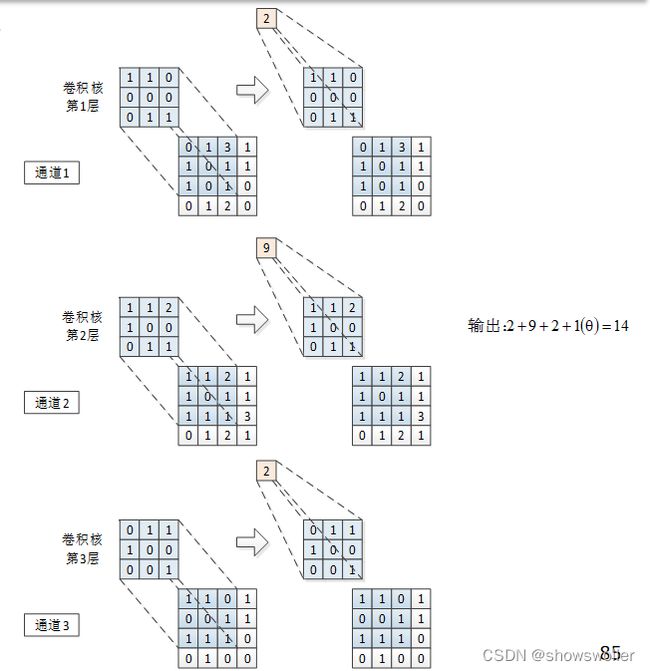
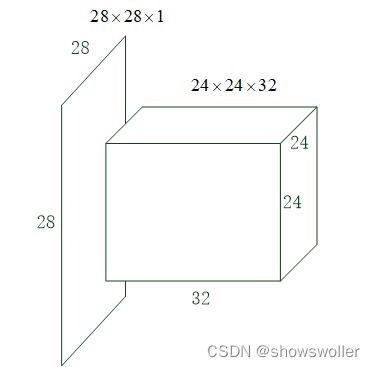
在卷积运算中,一般会设置多个卷积核。示例中设置了32个卷积核(TensorFlow中称为过滤器filters),因此该卷积层的输出为24×24×32,也就是说将28×28×1的数据变成了24×24×32的,在画神经网络结构图时,一般用下图中的长方体来表示上述卷积运算,水平方向长度示意卷积核的数量。
因为输入是单通道的,因此每卷积核只有一层,它的参数为5×5+1=26,共32个卷积核,因此训练参数为26×32=832个。
如果待处理张量规模很大,可以将卷积核由依次移动改为跳跃移动,即加大步长(strides),减少计算量,加快训练速度。
为了提取到边缘的特征,可以在待处理张量的边缘填充0再进行卷积运算,称为零填充(zero-padding)。填充也可以根据就近的值进行填充。边缘填充的另一个用途是在张量与卷积核不匹配时,通过填充使之匹配,从而卷积核能扫描到所有数据。
卷积层代码如下
### MindSpore
class mindspore.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, pad_mode='same', padding=0, dilation=1, group=1, has_bias=False, weight_init='normal', bias_init='zeros', data_format='NCHW')
### TensorFlow2
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), groups=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs
)
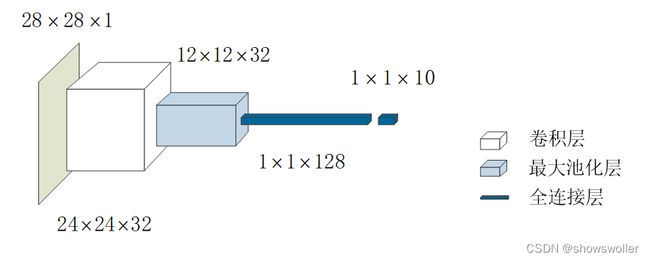
池化层和Flatten层
池化(pooling)层一般跟在卷积层之后,用于压缩数据和参数的数量。
池化操作也叫下采样(sub-sampling),具体过程与卷积层基本相同,只不过卷积核只取对应位置的最大值或平均值,分别称为最大池化或平均池化。
池化层的移动方式与卷积层不同,它是不重叠地移动。
Flatten层很简单,只是将输入的多维数据拉成一维的,直观上可理解为将数据“压平”。
除卷积层、池化层和全连接层(输入之前隐含Flatten层)之外的层,不改变网络结构,因此,一般只用这三层来表示神经网络的结构。
批标准化层
针对误差难继续传递问题,批标准化对每一层的批量输入数据x进行标准化,使之尽量避免落入饱和区,具体来讲就是使之均值为0,方差为1。对每一批输入数据B={x_1,x_2,…,x_m}:

其中,ϵ为防止除0的很小的常数。前三步分别为计算均值、计算方差、标准化,最后一步是对归一化后的结果进行缩放和平移,其中的γ和β是要学习的参数。
创作不易 觉得有帮助请点赞关注收藏~~~