Paddlenlp 修改example里的text_classification对自己的文本分类,基于ernie-tiny
目录
- 一、项目背景
- 二、项目环境
- 三、思路
-
- 3.1 输入训练数据
-
- 三级目录
一、项目背景
之前的短文本分类的项目是基于paddlepaddle1的,但我现在的机器的cuda版本为11.2,不能装paddle1了,我对paddlepaddle不是很了解,也不想重写代码(成本太高了),故想着改一改paddlenlp给的example,来达到文本分类的目的。
二、项目环境
| 版本 | |
|---|---|
| ubuntu | 5.4.0 |
| cuda | 11.2 |
| paddlepaddle | 2.0.2 |
三、思路
当我决定用examples里的代码时,我需要考虑的东西就少了很多,我的问题主要有以下四个:
- 如何输入训练数据
- 如何保存模型
- 如何将预测数据输入到保存的模型中
- 如何保存预测结果
3.1 输入训练数据
首先在examples/text_classification/pretrained_models目录下看到了train.py和predict.py两个文件,这两个文件应该就是训练和预测的代码了,官方的readme里说是以chnsenticorp 为示例数据集:
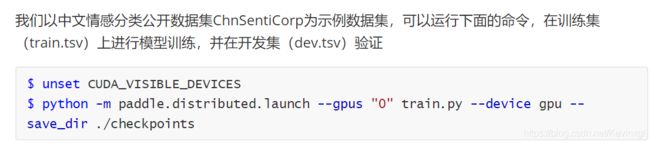
于是在predict.py中,我找到了这一行:
![]()
之后的模型输入都是用train_ds和dev_ds,因此猜测这里是数据入口,并且数据的输入以数据集的名称chnsenticorp 相关联。

在paddlenlp/datasets文件夹下,我找到了chnsenticorp.py,以及其它的数据集。通过对这些代码的研究,发现只要按固定格式写,就能用paddle的内置函数读取数据集。
首先是一个以数据集名称命名的class,并将数据的路径以及MD5信息作为变量:
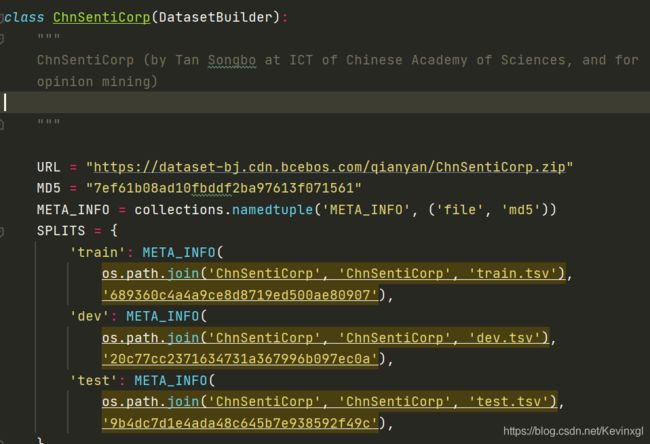
然后是get_data 函数,这个函数返回的是数据集的路径,mode代表模式,共有train, test和dev三个模式,这意味着我们的数据需要以train.tsv, test.tsv和dev.tsv存放在同一个文件夹下。
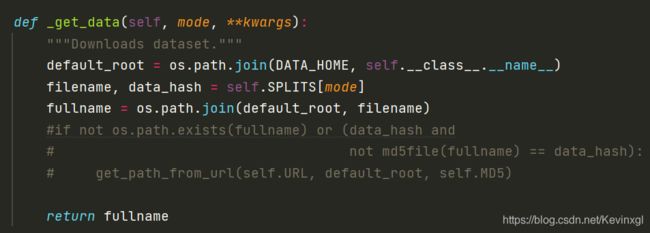
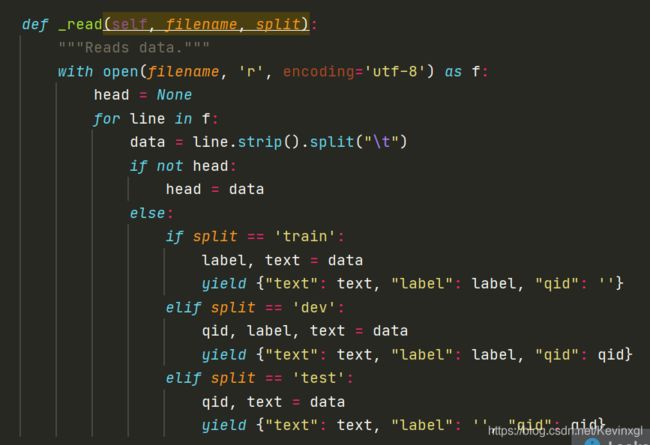
read函数,读取tsv文件并将文本和标签分隔开:
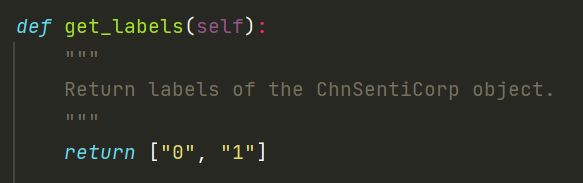
get_labels函数,返回数据集的所有标签:
于是我们照葫芦画瓢,创建了一个aspext数据集,并按照上述方法定义了相关变量和函数:
# 我将三个tsv文件存在了/home/ubuntu/Xigongli/train_data文件夹下,因此将DATA_HOME定义为这个文件夹
DATA_HOME = '/home/ubuntu/Xigongli/train_data'
__all__ = ['AspExt']
# 我们不需要从网上下载数据,因此也不需要数据的md5值,因此简单的把SPLIT列表定义为{模式:路径}的键值对。
class AspExt(DatasetBuilder):
SPLITS = {
'train':
os.path.join('train.tsv'),
'dev':
os.path.join('dev.tsv'),
'test':
os.path.join('test.tsv'),
}
# 不需要下载,直接返回路径名
def _get_data(self, mode, **kwargs):
default_root = os.path.join(DATA_HOME)
filename = self.SPLITS[mode]
fullname = os.path.join(default_root, filename)
#if not os.path.exists(fullname) or (data_hash and
# not md5file(fullname) == data_hash):
# get_path_from_url(self.URL, default_root, self.MD5)
return fullname
# 源代码对应的tsv中,第0列和第1列分别为label和text,我这里是反的,因此text, label = data
def _read(self, filename, split):
"""Reads data."""
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t")
if not head:
head = data
else:
if split == 'train':
text, label = data
yield {"text": text, "label": label, "qid": ''}
elif split == 'dev':
text, label = data
yield {"text": text, "label": label, "qid": ''}
elif split == 'test':
text, label = data
yield {"text": text, "label": '', "qid": ''}
# 我的目标不是情感分析,文本共有20+个分类,我将它们存在aspect.tsv中。
def get_labels(self):
"""
Return labels of the ChnSentiCorp object.
"""
return list(pd.read_csv('/home/ubuntu/Xigongli/train_data/aspect.tsv',header = None)[1].astype('str'))
写好aspext.py后,我将train.py里获取的数据集名称改为aspext:
![]()
之后以为可以正常预测了,但运行predict.py时,报了如下错误:

找到对应报错的目录,ls以下,发现还需要把刚写好的aspext.py传到python中paddlenlp所在的位置,把它cp过去就ok了。
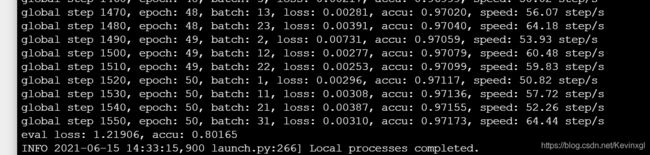
predict.py运行结果: