ASCII码对照表(C++17 实现ANSI、UTF8、Unicode字符编码互转)
ASCII相关文章汇总如下:
- ASCII码对照表(255个ascii字符汇总)
- ASCII码对照表(Unicode 字符集列表)
- ASCII码对照表(emoji表情符号)
- ASCII码对照表(Python代码实现打印)
- ASCII码对照表(C++17 实现ANSI、UTF8、Unicode编码互转)
文章目录
- 1、简介
-
- 1.1 ANSI
- 1.2 Unicode
- 1.3 UTF8
- 1.4 Little endian / Big endian
- 2、C++标准库
-
- 2.1 MultiByteToWideChar / WideCharToMultiByte
- 2.2 wcsrtombs / mbsrtowcs
- 2.3 codecvt
- 3、iconv库
-
- 3.1 命令行
- 3.2 C++代码实现一
- 3.3 C++代码实现二
- 3.4 C++代码实现三
- 结语
1、简介
1.1 ANSI
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。
ASCII在内的1字节字符128个,即char型的正数,汉字2字节,第一个字节是0X80以上,即char型负数第一字节,文件开头没有标志,直接是内容。直接读取,计算机会结合本地的编码(如GBK进行显示)。
1.2 Unicode
对于英文来讲,ASCII码就足以编码所有字符,但对于中文,则必须使用两个字节来代表一个汉字,这种表示汉字的方式习惯上称为双字节。虽然双字节可以解决中英文字符混合使用的情况,但对于不同字符系统而言,就要经过字符码转换,非常麻烦,如中英、中日、日韩混合的情况。为解决这一问题,很多公司联合起来制定了一套可以适用于全世界所有国家的字符码,不管是东方文字还是西方文字,一律用两个字节来表示,这就是UNICODE。
- Unicode字符集可以简写为UCS(Unicode Character Set)。
- Unicode开始启用2个字节表示。衍生出USC-2LE 、USC-2BE、UTF8等。
- 这个就是固定的2字节表示字符,包括英文字符也是2字节。开头有特征:以0xFFEF(小端)和0xEFFF(大端)开头为标志。
Unicode编码系统可分为编码方式和实现方式两个层次。
- 编码方式
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。 - 实现方式
在Unicode中:汉字“字”对应的数字是23383。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。
例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16编码
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32编码
1.3 UTF8
UTF-8以字节为单位对Unicode进行编码。
UTF8是变长的编码,英文字符还有1字节,汉字和其他各国字符用2字节或者3字节。
UTF8编码的分为带BOM和不带BOM的,BOM(Byte Order Mark)就是文件开头的标志了。
- 带BOM的UTF-8文件是:开头三字节,EE BB EF
- 不带BOM的UTF-8,开头为特征,直接是内容,造成和ANSI的一样。

“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个WORD,大小是4个字节。“汉字”的UTF-32编码需要两个DWORD,大小是8个字节。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。
1.4 Little endian / Big endian
以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
2、C++标准库
2.1 MultiByteToWideChar / WideCharToMultiByte
MultiByteToWideChar:是一种windows API 函数,该函数映射一个字符串到一个宽字符(unicode)的字符串。由该函数映射的字符串没必要是多字节字符组。
int MultiByteToWideChar(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cbMultiByte)LPCCH lpMultiByteStr,
[in] int cbMultiByte,
[out, optional] LPWSTR lpWideCharStr,
[in] int cchWideChar
);
- 测试代码:
catch (std::exception e)
{
// Save in-memory logging buffer to a log file on error.
::std::wstring wideWhat;
if (e.what() != nullptr)
{
int convertResult = MultiByteToWideChar(CP_UTF8, 0, e.what(), (int)strlen(e.what()), NULL, 0);
if (convertResult <= 0)
{
wideWhat = L"Exception occurred: Failure to convert its message text using MultiByteToWideChar: convertResult=";
wideWhat += convertResult.ToString()->Data();
wideWhat += L" GetLastError()=";
wideWhat += GetLastError().ToString()->Data();
}
else
{
wideWhat.resize(convertResult + 10);
convertResult = MultiByteToWideChar(CP_UTF8, 0, e.what(), (int)strlen(e.what()), &wideWhat[0], (int)wideWhat.size());
if (convertResult <= 0)
{
wideWhat = L"Exception occurred: Failure to convert its message text using MultiByteToWideChar: convertResult=";
wideWhat += convertResult.ToString()->Data();
wideWhat += L" GetLastError()=";
wideWhat += GetLastError().ToString()->Data();
}
else
{
wideWhat.insert(0, L"Exception occurred: ");
}
}
}
else
{
wideWhat = L"Exception occurred: Unknown.";
}
Platform::String^ errorMessage = ref new Platform::String(wideWhat.c_str());
// The session added the channel at level Warning. Log the message at
// level Error which is above (more critical than) Warning, which
// means it will actually get logged.
_channel->LogMessage(errorMessage, LoggingLevel::Error);
SaveLogInMemoryToFileAsync().then([=](StorageFile^ logFile) {
_logFileGeneratedCount++;
StatusChanged(this, ref new LoggingScenarioEventArgs(LoggingScenarioEventType::LogFileGenerated, logFile->Path->Data()));
}).wait();
}
WideCharToMultiByte:是一个函数,该函数可以映射一个unicode字符串到一个多字节字符串,执行转换的代码页、接收转换字符串、允许额外的控制等操作。
int WideCharToMultiByte(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cchWideChar)LPCWCH lpWideCharStr,
[in] int cchWideChar,
[out, optional] LPSTR lpMultiByteStr,
[in] int cbMultiByte,
[in, optional] LPCCH lpDefaultChar,
[out, optional] LPBOOL lpUsedDefaultChar
);
- 测试代码:
ISDSC_STATUS DiscpUnicodeToAnsiSize(
IN __in PWCHAR UnicodeString,
OUT ULONG *AnsiSizeInBytes
)
/*++
Routine Description:
This routine will return the length needed to represent the unicode
string as ANSI
Arguments:
UnicodeString is the unicode string whose ansi length is returned
*AnsiSizeInBytes is number of bytes needed to represent unicode
string as ANSI
Return Value:
ERROR_SUCCESS or error code
--*/
{
_try
{
*AnsiSizeInBytes = WideCharToMultiByte(CP_ACP,
0,
UnicodeString,
-1,
NULL,
0, NULL, NULL);
} _except(EXCEPTION_EXECUTE_HANDLER) {
return(ERROR_NOACCESS);
}
return((*AnsiSizeInBytes == 0) ? GetLastError() : ERROR_SUCCESS);
}
2.2 wcsrtombs / mbsrtowcs
wcsrtombs :将宽字符字符串转换为多字节字符串表示形式。 此函数有一个更安全的版本;请参阅 wcsrtombs_s。
size_t wcsrtombs(
char *mbstr,
const wchar_t **wcstr,
sizeof count,
mbstate_t *mbstate
);
template <size_t size>
size_t wcsrtombs(
char (&mbstr)[size],
const wchar_t **wcstr,
sizeof count,
mbstate_t *mbstate
); // C++ only
- 测试代码如下:
// crt_wcsrtombs.cpp
// compile with: /W3
// This code example converts a wide
// character string into a multibyte
// character string.
#include mbsrtowcs:将当前区域设置中的多字节字符字符串转换为相应的宽字符字符串,其中重启功能位于多字节字符的中间。 提供此函数的一个更安全的版本;请参阅 mbsrtowcs_s。
size_t mbsrtowcs(
wchar_t *wcstr,
const char **mbstr,
sizeof count,
mbstate_t *mbstate
);
template <size_t size>
size_t mbsrtowcs(
wchar_t (&wcstr)[size],
const char **mbstr,
sizeof count,
mbstate_t *mbstate
); // C++ only
2.3 codecvt
https://docs.microsoft.com/zh-cn/cpp/standard-library/codecvt-class?view=msvc-170
codecvt类:描述可用作区域设置方面的对象的类模板。 它可以控制用于在程序中对字符进行编码的值序列和用于对程序外部字符进行编码的值序列之间的转换。
std:codecvt的特化,std::codecvt
template <class CharType, class Byte, class StateType>
class codecvt : public locale::facet, codecvt_base;

- 例子1:
#include - 例子2:
// codecvt_out.cpp
// compile with: /EHsc
#define _INTL
#include C++17中codecvt的几个派生类弃用了,但std::codecvt 本身还可以用。

- 例子4:
//C++11中ANSI、Unicode、UTF-8字符串之间的互转
namespace StrConvert {
// string的编码方式为utf8,则采用:
std::string wstring2utf8string(const std::wstring& str)
{
static std::wstring_convert<std::codecvt_utf8<wchar_t> > strCnv;
return strCnv.to_bytes(str);
}
std::wstring utf8string2wstring(const std::string& str)
{
static std::wstring_convert< std::codecvt_utf8<wchar_t> > strCnv;
return strCnv.from_bytes(str);
}
// string的编码方式为除utf8外的其它编码方式,可采用:其中locale = "chs", "CHS", "zh-cn",或.936
std::string wstring2string(const std::wstring& str, const std::string& locale)
{
typedef std::codecvt_byname<wchar_t, char, std::mbstate_t> F;
static std::wstring_convert<F> strCnv(new F(locale));
return strCnv.to_bytes(str);
}
std::wstring string2wstring(const std::string& str, const std::string& locale)
{
typedef std::codecvt_byname<wchar_t, char, std::mbstate_t> F;
static std::wstring_convert<F> strCnv(new F(locale));
return strCnv.from_bytes(str);
}
}
- 例子5:
using fs = filesystem;
string gbk_str;
fs::path path{gbk_str, locale("zh_CN.gbk")};
u8string utf_str = path.u8string();
- 例子6:
- FxEncodeUtil.h:
/***************************************************************
* @file FxEncodeUtil.h
* @brief C++实现GB2312(ANSI)、UTF8、Unicode字符编码互转
* @author 爱看书的小沐
* @version 1.0
* @date 2022-5-18
* @platform Visual Studio 2017 / Win10 win64
* @languages C++
**************************************************************/
#pragma once
#include - FxEncodeUtil.cpp:
/***************************************************************
* @file FxEncodeUtil.cpp
* @brief C++实现GB2312(ANSI)、UTF8、Unicode字符编码互转
* @author 爱看书的小沐
* @version 1.0
* @date 2022-5-18
* @platform Visual Studio 2017 / Win10 win64
* @languages C++
**************************************************************/
#include "FxEncodeUtil.h"
#include "gtest/gtest.h"
#include "FxUnicode.h"
#define _AMD64_
#include 3、iconv库
http://gnuwin32.sourceforge.net/packages/libiconv.htm
iconv是linux下的编码转换的工具,它提供命令行的使用和函数接口支持。
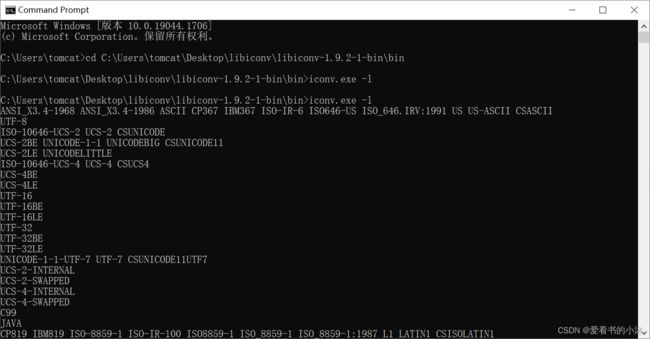
3.1 命令行
-f, --from-code=名称 原始文本编码
-t, --to-code=名称 输出编码
-l, --list 列举所有已知的字符集
-c 从输出中忽略无效的字符
-o, --output=FILE 输出文件
-s, --silent 关闭警告
--verbose 打印进度信息
iconv -f encoding -t encoding inputfile
iconv -f utf-8 -t unicode utf8file.txt> unicodefile.txt
iconv -f utf-8 -t gb2312 /server_test/reports/t1.txt > /server_test/reports/t2.txt
iconv -f utf8 -t gb18030 -oresult.xls result_tmp.xls
iconv -f utf8 -t gb18030 result_tmp.xls> result.xls
iconv -f utf8 -t gb2312 result_tmp.xls> result.xls
iconv -f latin1 -t ascii//TRANSLIT file
iconv -f UTF-8 -t ascii//TRANSLIT file
iconv -f "ISO_8859-1" -t "GBK" ./test
cmake -G "Visual Studio 15 2017 Win64" ..
https://www.gnu.org/software/libiconv/
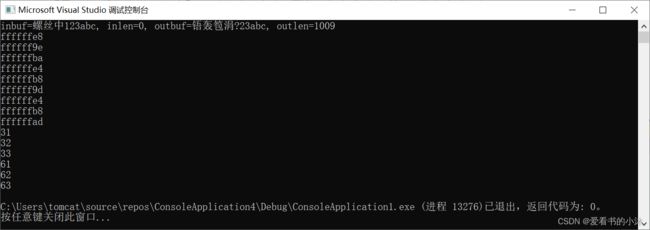
3.2 C++代码实现一
//***********************************************************************
// Purpose: 基于libiconv库的C++实现字符编码互转(测试用例1)
// Author: 爱看书的小沐
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include 运行结果如下:
3.3 C++代码实现二
//***********************************************************************
// Purpose: 基于libiconv库的C++实现字符编码互转(测试用例2)
// Author: 爱看书的小沐
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include 运行结果如下:

3.4 C++代码实现三
//***********************************************************************
// Purpose: 基于libiconv库的C++实现字符编码互转(测试用例3)
// Author: 爱看书的小沐
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include 测试代码如下:
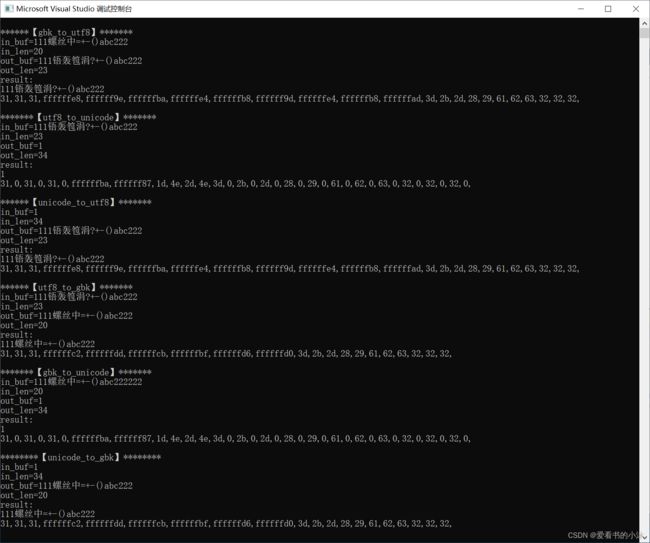
int main()
{
// gbk_to_utf8
printf("\n******【gbk_to_utf8】*******\n");
char inbuf[1024] = "111螺丝中=+-()abc222";
size_t inlen = strlen(inbuf);
char outbuf[1024] = {};
size_t outlen = sizeof(outbuf);
gbk_to_utf8(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// utf8_to_unicode
printf("\n*******【utf8_to_unicode】*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
utf8_to_unicode(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// unicode_to_utf8
printf("\n******【unicode_to_utf8】*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
unicode_to_utf8(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// utf8_to_gbk
printf("\n******【utf8_to_gbk】*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf,0, outlen);
utf8_to_gbk(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// gbk_to_unicode
printf("\n*******【gbk_to_unicode】*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
gbk_to_unicode(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// unicode_to_gbk
printf("\n********【unicode_to_gbk】********\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
unicode_to_gbk(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
}
libiconv的相关测试源码见如下链接:
https://download.csdn.net/download/hhy321/85419981
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进。o_O???
如果您需要相关功能的代码定制化开发,可以留言私聊作者。(✿◡‿◡)
感谢各位童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
