支持16条指令的 多周期CPU设计
支持16条指令的 多周期CPU设计
- CPU概述
- CPU指令集
- CPU软件开发流程
- CPU电路结构及实现
-
- 整体架构
- RegFile模块
- ALU模块
- CalPart模块
- MemoryPart模块
- cpu模块(top)
- CPU执行指令的流程
- 仿真测试
-
- 机器指令程序
- Testbench
- 运行结果
CPU概述
电子计算机三大核心部件就是CPU、内部存储器、输入/输出设备。
中央处理器(CPU,Central Processing Unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。其功能主要是解释计算机指令以及处理计算机软件中的数据:负责读取指令,对指令译码并执行指令。
中央处理器主要包括两个部分,即控制器、运算器,其中还包括高速缓冲存储器及实现它们之间联系的数据、控制的总线。
在计算机体系结构中,CPU 是对计算机的所有硬件资源(如存储器、输入输出单元) 进行控制调配、执行通用运算的核心硬件单元。计算机系统中所有软件层的操作,最终都将通过指令集映射为CPU的操作。
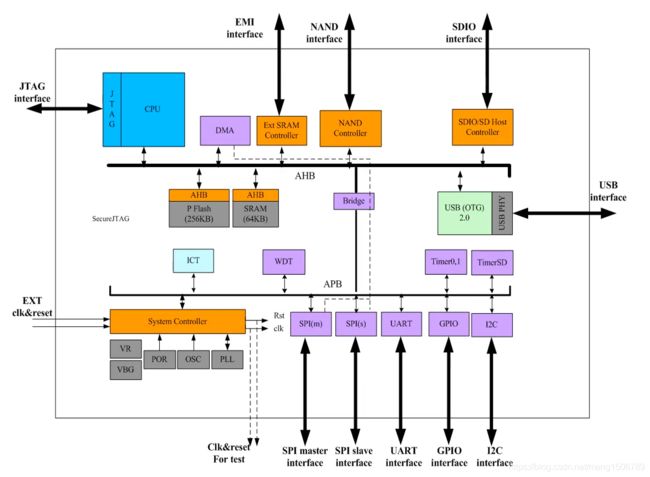
一种SoC的结构如下图所示,CPU外部通过总线结构来连接存储器和IO设备,其中只有CPU和DMA是master设备,其他都是slave设备。
CPU指令集
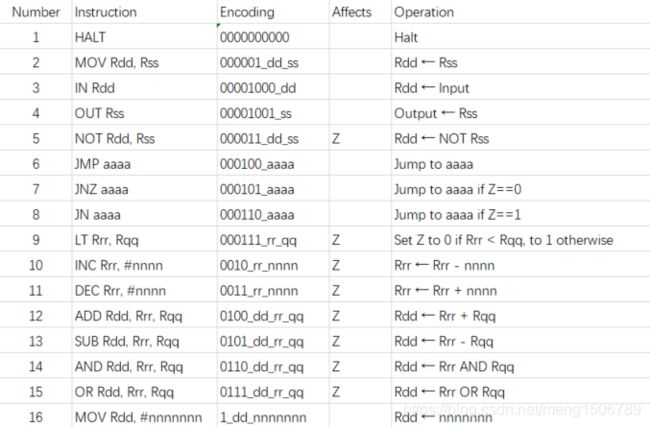
下面是要实现的一个简易CPU的指令集,如下表所示,一共16条指令,使用这些指令就可以实现一些复杂的功能。
CPU软件开发流程
一般来说,从高级语言程序设计到将程序下载进入CPU运行的流程是:
(1)编写高级语言程序(如C语言程序);
(2)使用编译器编译高级语言程序,生成汇编程序.s文件;
(3)将汇编程序转换为相应的机器指令程序,并将机器码指令存入.bin或.hex文件中;
(4)将文件通过JTAG接口下载进入CPU的“程序存储器”(ROM或FLASH)中的用户地址段,CPU上电后即可读取其中的程序来执行每条指令。
// 以上为嵌入式程序的开发流程,开发PC端程序在最后两步不同:
// (3)将.s为后缀的汇编语言源代码文件生成以.o为后缀的目标文件;
// (4)当所有的目标文件都生成之后,编译器会完成最后的链接过程,生成可执行文件。(实际上最后也是执行机器指令)
CPU上电后一般的指令执行流程为:
(1)读取“程序存储器”中固定地址段的起始程序,用于初始化CPU的一些基本配置;
(2)读取用户写入“程序存储器”中的用户地址段的程序,完成用户需要实现的功能(运行main函数中的程序)。
CPU电路结构及实现
整体架构
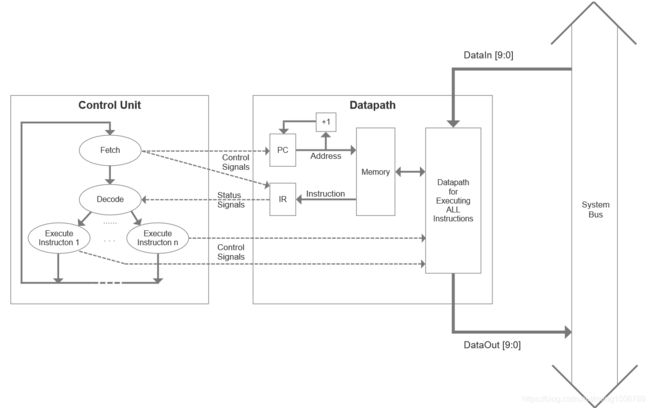
简易CPU的整体结构如下图所示。
其中:
(1)ControlUnit的功能在cpu模块(top)中实现;
(2)PC、IR、Memory在MemoryPart模块实现;
(3)Datapath for Executing ALL Instructions在CalPart模块(包含RegFile和ALU)实现。
这个CPU是一个多周期处理器,与单周期处理器相比,多周期处理器使用多个周期完成一条指令,将指令拆分成各个环节,这样可以使系统运行的时钟频率更高,使系统整体达到更好的效果。在多周期CPU设计的基础上,利用各阶段电路间可并行执行的特点,让各个阶段的执行在时间上重叠起来,这样就实现了流水线CPU。
RegFile模块
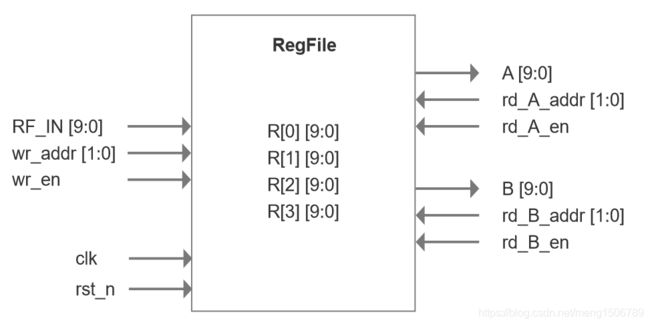
模块定义了4个寄存器:R0、R1、R2、R3,宽度均为10bit。可以通过wr_en + wr_addr将RF_IN的数据写入相应地址;也可以通过rd_en + rd_addr将相应地址的数据读出到A或B。
RegFile.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/25
// Author Name: Sniper
// Module Name: RegFile
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module RegFile
#(
parameter REGISTER_LEN = 10
)
(
input clk,
input rst_n,
input [REGISTER_LEN-1:0] RF_IN,
input wr_en,
input [1:0] wr_addr,
input rd_A_en,
input [1:0] rd_A_addr,
input rd_B_en,
input [1:0] rd_B_addr,
output reg [REGISTER_LEN-1:0] A,
output reg [REGISTER_LEN-1:0] B
);
reg [REGISTER_LEN-1:0] register [3:0];
//write
always@(posedge clk or negedge rst_n)
if(wr_en)
register[wr_addr] <= RF_IN;
//read
always@(posedge clk or negedge rst_n)
if(!rst_n)
A <= 0;
else if(rd_A_en)
A <= register[rd_A_addr];
always@(posedge clk or negedge rst_n)
if(!rst_n)
B <= 0;
else if(rd_B_en)
B <= register[rd_B_addr];
`define SIM
`ifdef SIM
wire [REGISTER_LEN-1:0] R0 = register[0];
wire [REGISTER_LEN-1:0] R1 = register[1];
wire [REGISTER_LEN-1:0] R2 = register[2];
wire [REGISTER_LEN-1:0] R3 = register[3];
`endif
endmodule
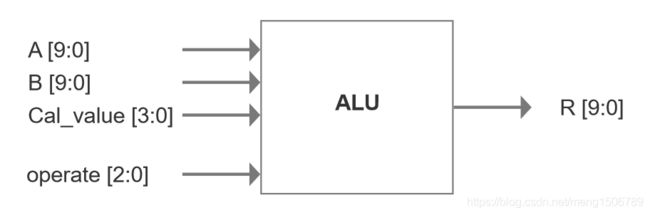
ALU模块
ALU模块实现基本的运算功能,包括算术运算和逻辑运算,是纯组合逻辑(也可改进为pipeline结构)。通过operate来选择计算类型,A、B、Cal_value是输入数据,R是输出的结果。
ALU.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/25
// Author Name: Sniper
// Module Name: ALU
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module ALU
#(
parameter REGISTER_LEN = 10
)
(
input [3:0] Cal_value,
input [2:0] operate,
input [REGISTER_LEN-1:0] A,
input [REGISTER_LEN-1:0] B,
output reg [REGISTER_LEN:0] R
);
always@(*)
case(operate)
3'b000: R = A;
3'b001: R = A < B ? 1 : 0;
3'b010: R = A + Cal_value;
3'b011: R = A - Cal_value;
3'b100: R = A + B;
3'b101: R = A - B;
3'b110: R = A & B;
3'b111: R = A | B;
default: R = A;
endcase
endmodule
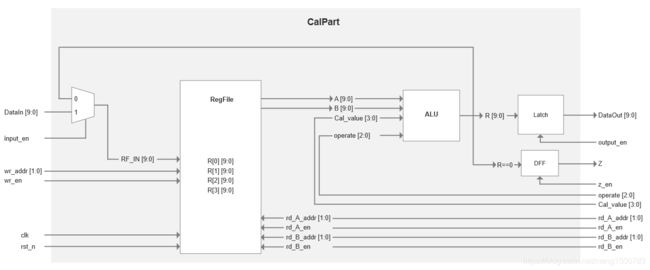
CalPart模块
CalPart模块将以上两个模块整合在一起,构成计算part。其中,input_en用于选择输入数据是否来自外部还是ALU的计算结果;Z信号当ALU的计算结果为0时置位,可以用于CPU实现判断功能(if、for、while本质上都是需要判断的)。
CalPart.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/25
// Author Name: Sniper
// Module Name: CalPart
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module CalPart
#(
parameter REGISTER_LEN = 10
)
(
input clk,
input rst_n,
input input_en,
input z_en,
input output_en,
output reg Z,
output reg [REGISTER_LEN-1:0] DataOut,
input [REGISTER_LEN-1:0] DataIn,
input wr_en,
input [1:0] wr_addr,
input rd_A_en,
input [1:0] rd_A_addr,
input rd_B_en,
input [1:0] rd_B_addr,
input [2:0] operate,
input [3:0] Cal_value
);
wire [REGISTER_LEN-1:0] RF;
wire [REGISTER_LEN-1:0] A;
wire [REGISTER_LEN-1:0] B;
wire [REGISTER_LEN :0] R;
assign RF = input_en ? DataIn : R[REGISTER_LEN-1:0];
RegFile
#(
.REGISTER_LEN(REGISTER_LEN)
)
u_RegFile
(
.clk(clk),
.rst_n(rst_n),
.RF_IN(RF),
.wr_en(wr_en),
.wr_addr(wr_addr),
.rd_A_en(rd_A_en),
.rd_A_addr(rd_A_addr),
.rd_B_en(rd_B_en),
.rd_B_addr(rd_B_addr),
.A(A),
.B(B)
);
ALU
#(
.REGISTER_LEN(REGISTER_LEN)
)
u_ALU
(
.Cal_value(Cal_value),
.operate(operate),
.A(A),
.B(B),
.R(R)
);
always@(posedge clk or negedge rst_n)
if(!rst_n)
Z <= 0;
else if(z_en)
Z <= R == 0;
always@(*)
if(output_en)
DataOut = R[REGISTER_LEN-1:0];
endmodule
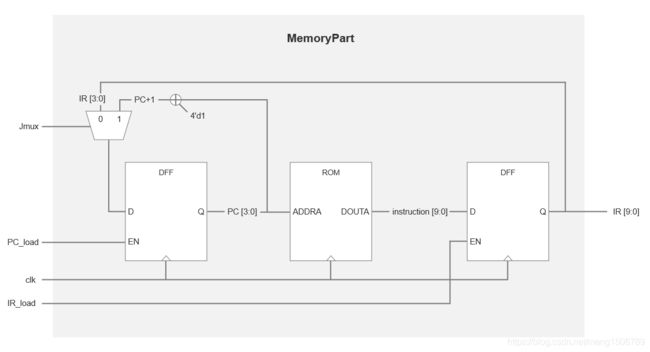
MemoryPart模块
MemoryPart模块实现PC的跳转与指令IR的读取。PC_load和IR_load分别标志的更新PC和更新IR (PC是IR的地址)。其中,当Jmux==1时,PC=PC+1;否则,PC=IR[ADDR_LEN-1:0]进行指令的跳转,跳转到当前的IR[ADDR_LEN-1:0]标志的指令地址。
模块中,所有指令都存储在ROM中,PC(作为ROM的地址)从0开始自增,逐条提取指令。
MemoryPart.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/25
// Author Name: Sniper
// Module Name: MemoryPart
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module MemoryPart
#(
parameter ADDR_LEN = 4,
parameter INSTRUCTION_LEN = 10
)
(
input clk,
input rst_n,
input PC_load,
input IR_load,
input Jmux,
output reg [INSTRUCTION_LEN-1:0] IR
);
wire [INSTRUCTION_LEN-1:0] instruction;
reg [ADDR_LEN-1:0] PC;
wire [ADDR_LEN-1:0] PC_INC;
wire [ADDR_LEN-1:0] PC_JMP;
wire [ADDR_LEN-1:0] PC_NXT;
assign PC_INC = PC + 1;
assign PC_JMP = IR[ADDR_LEN-1:0];
assign PC_NXT = Jmux ? PC_INC : PC_JMP;
always@(posedge clk or negedge rst_n)
if(!rst_n)
IR <= instruction;
else if(IR_load)
IR <= instruction;
always@(posedge clk or negedge rst_n)
if(!rst_n)
PC <= 0;
else if(PC_load)
PC <= PC_NXT;
//memory stores all the instructions
`ifdef ROM
rom u_ProgramMemory
(
.clka(clk),
.addra(PC),
.douta(instruction)
);
`else
reg [INSTRUCTION_LEN-1:0] rom[15:0];
reg [INSTRUCTION_LEN-1:0] rom_rd_data;
integer program = 2;
initial
begin
if(program == 1)
begin
//given a natural number N (!=0), calculate the sum of i
//int sum=0;for(int i=1;i
rom[0] = 'b0000100011;//0// READ INPUT TO R3
rom[1] = 'b1000000001;//1// INIT R0 = 1
rom[2] = 'b1010000000;//2// INIT R1 = 0
rom[3] = 'b0100010100;//3// R1 = R0 + R1
rom[4] = 'b0010000001;//4// R0 = R0 + 1
rom[5] = 'b0001110011;//5// IF R0 < R3 THEN Z = 0 ELSE Z = 1
rom[6] = 'b0001010011;//6// IF Z == 0 THEN GO ADDR 03 ELSE GO NEXT ADDR
rom[7] = 'b0000100101;//7// OUTPUT R1
rom[8] = 'b0000000000;//8// OVER
end
else if(program == 2)
begin
//given a natural number N , calculate N % 11
//while(N>=11) N -= 11;
rom[0] = 'b0000100011;//0// READ INPUT TO R3
rom[1] = 'b1000001011;//1// INIT R0 = 11
rom[2] = 'b0001110011;//2// IF R0 < R3 THEN Z = 0 ELSE Z = 1
rom[3] = 'b0001100110;//3// IF Z == 1 THEN GO ADDR 06 ELSE GO NEXT ADDR
rom[4] = 'b0011111011;//4// R3 = R3 - 11
rom[5] = 'b0001000010;//5// GO TO ADDR 02
rom[6] = 'b0101011100;//6// R1 = R3 - 11
rom[7] = 'b0001101010;//7// IF Z == 1 THEN GO ADDR 10 ELSE GO NEXT ADDR
rom[8] = 'b0000100111;//8// OUTPUT R3
rom[9] = 'b0000000000;//9// OVER
rom[10]= 'b0000100101;//10// OUTPUT R2
rom[11]= 'b0000000000;//11// OVER
end
end
always@(posedge clk)
rom_rd_data <= rom[PC];
assign instruction = rom_rd_data;
`endif
endmodule
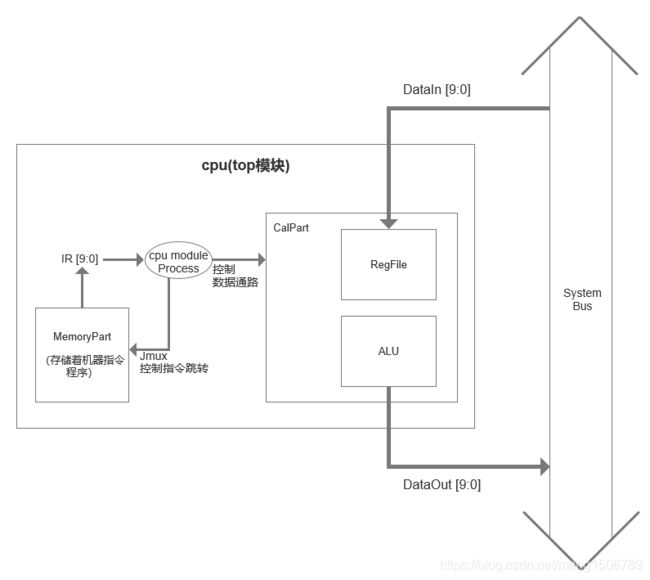
cpu模块(top)
Top模块将MemoryPart模块和CalPart模块包含起来,根据PC读取到的不同的IR指令对两个模块的输入输出信号进行控制。
不同的指令会导致不同的Jmux、input_en、rd_A_en、rd_A_addr、rd_B_en、rd_B_addr、operate、Cal_value、wr_en、wr_addr、z_en、output_en。只有IR_load和PC_load是只受phase控制,其他信号都需要受phase和IR同时控制。
Top模块中的phase[2:0]表示CPU的相位状态,共有8个状态:0,1,2,…,7。这些状态不断循环,使CPU一直运转,实现多周期处理,即每条指令在8个时钟周期执行完毕。
当CPU读取到的指令为10’b00_0000_0000时,标志着机器指令程序的执行结束,sub_rst_n有效,内部的模块复位,重新从第0条指令运行。
cpu.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/25
// Author Name: Sniper
// Module Name: cpu
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module cpu
#(
parameter REGISTER_LEN = 10,
parameter ADDR_LEN = 4,
parameter INSTRUCTION_LEN = 10
)
(
input clk,
input rst_n,
output reg sub_rst_n,
input [REGISTER_LEN-1:0] DataIn,
output DataIn_en,
output [REGISTER_LEN-1:0] DataOut,
output DataOut_valid
);
//ports of sub-modules
wire [INSTRUCTION_LEN-1:0] IR;
wire Z;
wire [REGISTER_LEN-1:0] DataIn_tmp;
assign DataIn_tmp = IR[9] ? {3'b000,IR[6:0]} : DataIn;
reg Jmux;
reg IR_load;
reg PC_load;
reg input_en;
reg z_en;
reg output_en;
reg wr_en;
reg rd_A_en;
reg rd_B_en;
reg [1:0] wr_addr;
reg [1:0] rd_A_addr;
reg [1:0] rd_B_addr;
reg [3:0] Cal_value;
reg [2:0] operate;
//last Instruction , end
reg [INSTRUCTION_LEN-1:0] IR_buff;
always@(posedge clk or negedge rst_n)
if(!rst_n)
IR_buff <= 0;
else
IR_buff <= IR;
always@(posedge clk or negedge rst_n)
if(!rst_n)
sub_rst_n <= 0;
else if(IR_buff!=0 && IR == 0)
sub_rst_n <= 0;
else
sub_rst_n <= 1;
//------------------------------------------------------
//loop pipeline
reg [2:0] phase;
always@(posedge clk or negedge sub_rst_n)
if(!sub_rst_n)
phase <= 0;
else
phase <= phase + 1;
always@(posedge clk or negedge sub_rst_n)
if(!sub_rst_n)
IR_load <= 0;
else if(phase == 1)//load Instruction
IR_load <= 1;
else
IR_load <= 0;
always@(posedge clk or negedge sub_rst_n)
if(!sub_rst_n)
input_en <= 0;
else if(phase == 3)//judge if use DataIn_tmp or ALU result
//IN //MOV
if(IR[9:2] == 'b00_0010_00 || IR[9])
input_en <= 1;
else
input_en <= 0;
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
begin
rd_A_addr <= 0;
rd_A_en <= 0;
end
else
begin
if(phase == 4)//read operand A from RegFile
begin
casex (IR)
//ADD SUB AND OR LT
'b01_XXXX_XXXX,'b00_0111_XXXX:
begin
rd_A_addr <= IR[3:2];
rd_A_en <= 1;
end
//INC DEC
'b00_1XXX_XXXX:
begin
rd_A_addr <= IR[5:4];
rd_A_en <= 1;
end
//MOV OUT NOT
'b00_0001_XXXX,'b00_0010_01XX,'b00_0011_XXXX:
begin
rd_A_addr <= IR[1:0];
rd_A_en <= 1;
end
default: rd_A_en <= 0;
endcase
end
else
rd_A_en <= 0;
end
end
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
begin
rd_B_addr <= 0;
rd_B_en <= 0;
end
else
begin
if(phase == 4)//read operand B from RegFile
begin
casex (IR)
//ADD SUB AND OR LT
'b01_XXXX_XXXX,'b00_0111_XXXX:
begin
rd_B_addr <= IR[1:0];
rd_B_en <= 1;
end
default: rd_B_en <= 0;
endcase
end
else
rd_B_en <= 0;
end
end
always@(posedge clk or negedge sub_rst_n)
if(!sub_rst_n)
begin
operate <= 0;
Cal_value <= 0;
end
else if(phase == 4)
begin
operate <= IR[8:6];//get operate from IR
Cal_value <= IR[3:0];//get Cal_value from IR
end
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
z_en <= 0;
else
begin
if(phase == 5)//judge z out_en, whether need Z
casex (IR)
//ADD SUB AND OR //INC DEC //LT //NOT
'b01_XXXX_XXXX,'b00_1XXX_XXXX,'b00_0111_xxxx,'b00_0011_XXXX: z_en <= 1;
default: z_en <= 0;
endcase
else
z_en <= 0;
end
end
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
Jmux <= 0;
else if(phase == 7)//judge jump conditions after Z is gen
begin
casex(IR)
'b00_0100_xxxx: Jmux <= 0; //Jump to aaaa
'b00_0101_xxxx: Jmux <= Z; //Jump to aaaa if Z status flag == 0
'b00_0110_xxxx: Jmux <= !Z; //Jump to aaaa if Z status flag == 1
default: Jmux <= 1;//do not jump
endcase
end
end
always@(posedge clk or negedge sub_rst_n)
if(!sub_rst_n)
PC_load <= 0;
else if(phase == 7)//PC can be load after Jmux is gen
PC_load <= 1;
else
PC_load <= 0;
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
output_en <= 0;
else
begin
if(phase == 7)//judge Data out_en, whether data need to be output
//OUT
if(IR[9:2] == 'b00_0010_01)
output_en <= 1;
else
output_en <= 0;
else
output_en <= 0;
end
end
always@(posedge clk or negedge sub_rst_n)
begin
if(!sub_rst_n)
begin
wr_addr <= 0;
wr_en <= 0;
end
else
begin
if(phase == 7)//write data into RegFile
casex(IR)
//MOV Rdd, #nnnnnnn
'b1x_xxxx_xxxx:
begin
wr_addr <= IR[8:7];
wr_en <= 1;
end
//INC DEC ADD SUB AND OR
'b00_1xxx_xxxx,'b01_0xxx_xxxx,'b01_1xxx_xxxx:
begin
wr_addr <= IR[5:4];
wr_en <= 1;
end
//MOV Rdd, Rss
'b00_0001_xxxx:
begin
wr_addr <= IR[3:2];
wr_en <= 1;
end
//IN Rdd
'b00_0010_00xx:
begin
wr_addr <= IR[1:0];
wr_en <= 1;
end
//NOT Rdd, Rss
'b00_0011_xxxx:
begin
wr_addr <= IR[3:2];
wr_en <= 1;
end
default: wr_en <= 0;
endcase
else
wr_en <= 0;
end
end
assign DataIn_en = (IR[9:2] == 'b00_0010_00) && input_en;
assign DataOut_valid = output_en;
MemoryPart
#(
.REGISTER_LEN(REGISTER_LEN)
)
u_MemoryPart
(
.clk(clk),
.rst_n(sub_rst_n),
.PC_load(PC_load),
.IR_load(IR_load),
.Jmux(Jmux),
.IR(IR)
);
CalPart
#(
.REGISTER_LEN(REGISTER_LEN)
)
u_CalPart
(
.clk(clk),
.rst_n(sub_rst_n),
.input_en(input_en),
.z_en(z_en),
.output_en(output_en),
.Z(Z),
.DataOut(DataOut),
.DataIn(DataIn_tmp),
.wr_en(wr_en),
.wr_addr(wr_addr),
.rd_A_en(rd_A_en),
.rd_A_addr(rd_A_addr),
.rd_B_en(rd_B_en),
.rd_B_addr(rd_B_addr),
.operate(operate),
.Cal_value(Cal_value)
);
endmodule
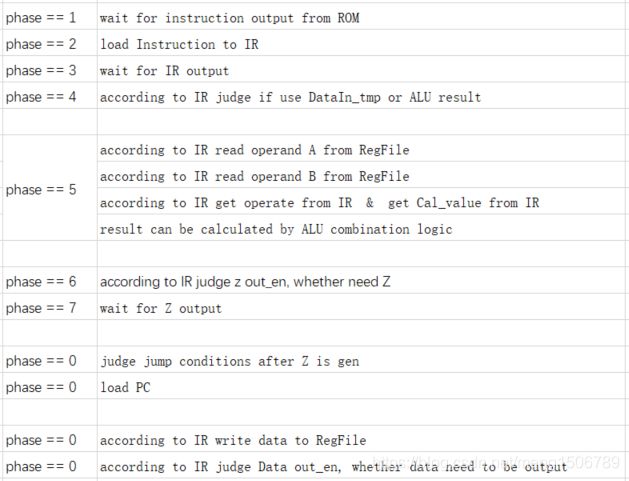
CPU执行指令的流程
CPU执行指令的流程如下所示。(其实在top模块中就是按phase顺序写的程序)
仿真测试
机器指令程序
将机器指令程序放在了前面的MemoryPart.v中的initial块进行仿真(如果在FPGA中实现,可以将机器指令程序生成.coe文件放在ROM中)。
一共编写了两个程序,通过改变变量program的值可以选择执行哪一段程序。
第一段程序的功能是计算小于自然数N的所有自然数的和。
第二段程序的功能是计算自然数N除以11的余数。
Testbench
testbench为cpu提供时钟和输入数据。
tb_cpu.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/26
// Author Name: Sniper
// Module Name: tb_cpu
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module tb_cpu;
//parameter
parameter REGISTER_LEN = 10;
parameter ADDR_LEN = 4;
parameter INSTRUCTION_LEN = 10;
//input
reg clk;
reg rst_n;
reg [REGISTER_LEN-1:0] DataIn;
//output
wire sub_rst_n;
wire DataIn_en;
wire [REGISTER_LEN-1:0] DataOut;
wire DataOut_valid;
initial
begin
clk = 0;
rst_n = 0;
DataIn[REGISTER_LEN-1:0] = 0;
#100;
@(posedge clk);
rst_n <= 1;
@(posedge clk);
DataIn <= 13;
forever @(posedge sub_rst_n) DataIn <= DataIn + 1;
end
//clock
always #5 clk = ~clk;
//DUT
cpu
#(
.REGISTER_LEN(REGISTER_LEN),
.ADDR_LEN(ADDR_LEN),
.INSTRUCTION_LEN(INSTRUCTION_LEN)
)
u_cpu
(
.clk(clk),
.rst_n(rst_n),
.sub_rst_n(sub_rst_n),
.DataIn(DataIn),
.DataIn_en(DataIn_en),
.DataOut(DataOut),
.DataOut_valid(DataOut_valid)
);
initial
begin
$dumpfile("tb_cpu.vcd");
$dumpvars(0,tb_cpu);
end
initial #10_000 $finish;
endmodule
运行结果
vcs -R MemoryPart.v RegFile.v ALU.v CalPart.v cpu.v tb_cpu.v
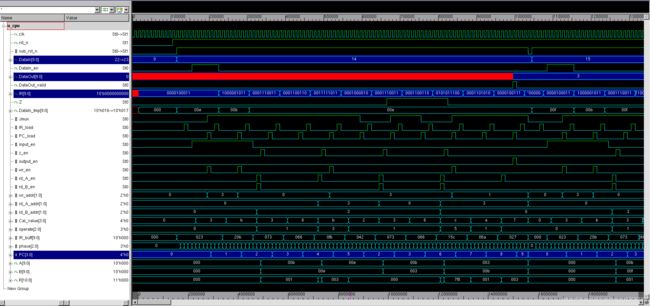
以第二段程序为例,使用减法和跳转指令计算14%11,15%11,16%11,…
从结果中可以看到,PC的跳转状态是012345236789,标志着指令的执行顺序。
当程序运行到N=23时,由于testbench中设计的DataIn不断增加,且CPU是使用减法和跳转指令计算来计算N%11,因此需要更多的循环周期才能完成N%11的运算。
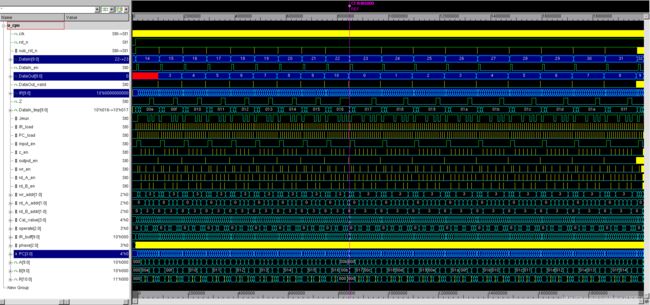
从仿真中可以看出,对于高级语言来说只用1、2行代码就可以实现的程序,CPU在电路逻辑中也做了很多复杂的工作~