pyspark踩坑
1:打印中文出现乱码的问题。
解决方法:添加
reload(sys)
sys.setdefaultencoding('utf-8')2:参数设置。
建议使用新api
from pyspark.sql import SparkSession
conf = SparkConf()
conf.setMaster('yarn')
conf.setAppName('psctwo')参数
conf.set('spark.executor.memory', '1G')
conf.set('spark.executor.cores', '2')
conf.set('spark.executor.instances', '6') # 指定executor的个数
conf.set('spark.driver.memory', '2G')
conf.set('spark.driver.cores', '3')指定executor个数时,使用spark.executor.instances,spark.num.executors不生效!!
3:创建es索引。
create_query = """
curl -XPUT http://192.168.17.111:9200/%s -d '{
"settings": {
"index": {
"number_of_shards": "6",
"number_of_replicas": "1",
"codec": "best_compression",
"refresh_interval": "30s",
"translog.durability": "async",
"translog.sync_interval" :"120s",
"translog.flush_threshold_size": "1024mb"
}
},
"mappings": {
"pyspark_es": {
"_all": {
"enabled": false
},
"properties": {
"uuid": {
"type": "keyword"
},
"metric": {
"type": "keyword"
},
"value": {
"type": "keyword"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
}
}'"""将条目类型设为keyword,日期可以通过||指定多种格式。
4:去重查找。
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"group": {
"terms": {
"field": "uuid"
}
}
}
}5:删除索引。
delete_query = """
curl -XDELETE http://192.168.17.111:9200/%s
"""6:创建dataframe。
sc = SparkSession.builder.config(conf=conf).getOrCreate()
save_df = sc.createDataFrame(data, ['uuid', 'metric', 'timestamp', 'value'])
# print(save_df.show(truncate=False))7:pyspark写入es。
save_df.write \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "192.168.17.111,192.168.17.112,192.168.17.113") \
.option("es.resource", "pyspark_es/data") \
.mode('overwrite') \
.save()8:pyspark读取es。
df = sc.read \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "192.168.17.111,192.168.17.112,192.168.17.113") \
.option("es.port", "9200") \
.option("es.resource", "pyspark_es/data") \
.option("es.mapping.date.rich", False) \
.option("es.query", query) \
.load()
"""es 默认只能自动解析 ISO 8601 日期,增加一条配置 es.mapping.date.rich 为false,
禁止自动解析时间格式字段,只返回字符串"""9:spark分区。
原本的想法是读取数据,将数据根据uuid进行repartition,再针对每个分区进行mapPartition操作,问题是根据uuid进行repartition后,每个分区并不是单独uuid的数据,因为分区函数为hashPartition,不同uuid是可能分到同一个分区的。另mapPartition会进行重新分区,如果不指定numPartition,默认200。因此不要用此方法,建议使用mapreduce。
10:思路。
数据格式如下:
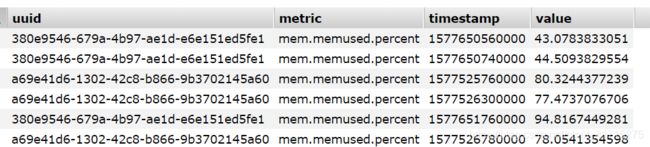
1)进行map操作,将数据变为key-value形式;
dfRDD = df.rdd.map(lambda x: (str(x.metric) + str(x.uuid), (x.timestamp, x.value)))2)按找key进行聚类,将所有相同key数据聚类为一条;
dfRDD = dfRDD.combineByKey(to_list, append, extend, numPartitions=np)# 分区数可以不指定3)针对每条数据使用自定义函数;
df = dfRDD.map(some_function)自定义函数返回格式为:
data.to_dict(orient='records')
"""'records' : list like
[{column -> value}, ... , {column -> value}]"""4)合并为一个list后创建为dataframe;
df = sc.createDataFrame(df.reduce(extend))自定义函数如下:
def to_list(a):
return [a]
def append(a, b):
a.append(b)
return a
def extend(a, b):
a.extend(b)
return a5)写回es。
df.write \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "192.168.17.111,192.168.17.112,192.168.17.113") \
.option("es.resource", "pyspark_es_verify/data") \
.mode('overwrite') \
.save()11)es分片数同执行器的关系。
一个分片对应一个执行器!
刚开始时,我es分片为3,executor数量为9,结果只有3个executor在工作!后来将分片数设为6,executor设为6,运行时间减少一半左右。
另,再从es读数据时自定义分区数可能也有效?未尝试。