面试问题总结——关于YOLO系列(一)
自从刚开始接到的第一个面试开始,到现在为止,陆陆续续也参加了许多场,我像是一个刚从新手村出来的小白,一路的打怪升级刷经验,期间遇到了很多不会的,我都会及时记录总结。

到现在仍然清晰记得,第一次去面试的时候,当时被怼的多惨。。。
说明:本人是非科班出身,本科是机械电子工程专业,硕士期间的研究方向是机器学习和深度学习,因为我的简历上有关于YOLO的项目,所以我着重准备了YOLO系列的面试可能遇到的问题。
决定开启这个面试问题总结的系列,包括YOLO、C++的内容、OpenCV的内容和深度学习方面被提问的问题。

一.YOLOv1
1.简单的背景介绍
在YOLO出来之前,常见的目标检测算法:
①滑窗检测算法
a.将目标检测的问题转化为图像识别的问题
b.物体的位置是根据滑窗的位置确定的
c.缺点:滑窗之间存在着很大部分的重叠,即存在大量的冗余,导致该方法效率低下。
b.滑窗算法最大的问题是只能看到滑窗部分里面的内容,不能看到整个目标。
②区域检测算法:采用某些算法:如分水岭算法。
2.YOLOv1的算法思想
YOLO是基于深度学习和卷积神经网络的单阶段通用目标检测算法,把目标检测问题转化为回归问题,不需要经过提取候选框的冗余问题。
YOLOv1的训练阶段(反向传播)(https://www.bilibili.com/video/BV15w411Z7LG?p=6)
模型是如何训练出来的:在训练集上,我们首先要对图像进行标注,画出检测目标的ground truth,模型就是要将预测结果尽量拟合这个ground truth,使得损失函数最小化。之前将标注好了的图像分成S×S个(v1是7×7)网格(grid cell),对于ground truth的中心点,其中心点落在哪个grid cell中,就由这个grid cell生成的bounding box去负责拟合这个ground truth,因为每一个grid cell都会生成2个bounding box,那么就由这2个中的其中一个去负责拟合ground truth,且每一个grid cell去预测一个物体,则最多预测7×7个物体,这也是YOLOv1预测小目标和密集目标性能较差的原因。每一个grid cell都会生成2个bounding box,那究竟由哪个bounding box去拟合ground gruth呢?就是由bounding box和ground truth交并比IOU较大的那个bounding box决定,较小的bounding box就直接舍弃,较大的留下来通过损失函数来不断进行调整以满足拟合ground truth。
上面是对于ground truth中心点落在某个grid cell中的情况,若对于没有中心落在的grid cell中,其grid cell也会生成2个bounding box,这2个bounding box就会舍去。
补充:关于bounding box的四个参数x、y、w、h,其中心点坐标x和y肯定落在网格中,以这个网格左上角为(0,0),右下角为(1,1),bx和by在0—1之间,而bh和bw可能会大于1,因为一个目标object的尺寸大小可能是几个格子,同时bounding box还要预测位置置信度confidence。因为每个网格预测2个bounding box,所以有2个confidence值(confidence的值就是0或者1乘以交并比的值,即网格与你标注的bounding box的交并比值,0表示未预测到,1表示预测到了),除此之外,每个网格还要预测C个类别的分数(这里的分数就指的是你预测的哪个目标,则这个目标的类别分数就为1,否则为0)。
YOLOv1的预测阶段、后处理(前向推断):
在测试阶段、或者叫预测阶段、或者叫YOLO模型正向推断阶段,就是模型已经训练好了的情况下:
输入一张图像,先把图像分成S×S(7×7)的网格(grid cell),每个grid cell都生成2个预测框(bounding box),每个grid cell都包括2个bounding box和20个类别,每个bounding box又包含4个位置参数(x、y、w、h)和1个置信度参数c,在原论文中bounding box的粗细就表示了置信度c的大小,粗的表示置信度较高,细的表示置信度较低。同时,每个grid cell预测一组条件类别的概率,就是原论文中每个彩色的网格就是代表预测了哪个类别(用颜色代表不同的类别,用粗细来表示每个bounding box的置信度)。以PASCAL VOC数据集为例,有20个类别,则最后我们会得到一个7×7×30(1+4+1+4+20)维度的向量。结合bounding box的信息和grid cell的类别信息,再经过后处理包括置信度过滤和NMS就可以获得最后的预测结果。
对于YOLO而言,后处理就是把预测出来的98个bounding box预测框进行筛选和过滤只保留一个,过程包括去掉低置信度的框和重复的预测框,这个步骤就是NMS(非极大值抑制)。如果想加强NMS,就把阈值设置的低一点,注意,NMS只存在于预测阶段,训练阶段是不需要NMS的,因为在训练阶段每个bounding box都很重要。
3.关于NMS
NMS的过程:
假设98个bounding box,因为有20个类别,设第一个类别是dog,则98个bounding box会有98个置信度,比如0,0.2,0.5,0.1,0…,将它们的置信度从高到底排序,0.5最高,则把剩余的0.2和0.1和0.5进行计算IOU的值,若0.1和0.5的bounding box的IOU的值大于设置的阈值,就判断这两个bounding box是重复的,则去掉置信度0.1的bounding box,若小于阈值,就继续比较其他的,一轮结束后,再从第二名0.2开始,重复上面的操作。视频思路:https://www.bilibili.com/video/BV15w411Z7LG?p=5)
(test = 某个grid cell所属某个类别的概率×预测的目标边界框与真实的bounding box的重合程度。)
为什么需要NMS?
每一个grid cell用一个bounding box预测一个物体,但对于较大的物体和靠近边缘的物体可能会有多个bounding box预测同一个物体,这时候就需要NMS(Non-maximal suppression),来把低置信度的预测框过滤掉,只保留高置信度的框。
4.YOLOv1的网络结构图
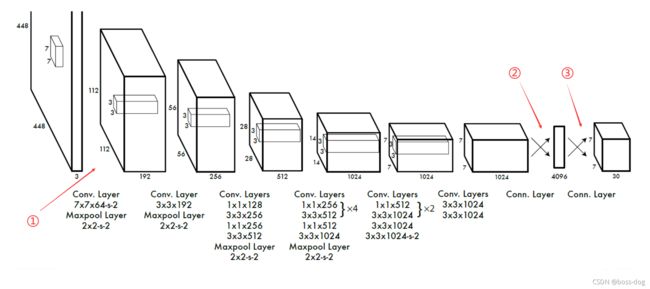
(7×7×64-s-2)表示7×7的卷积核64个,stride步长为2,未标注的表示步长为1。
①.448×448 —— 224×224 ——(最大池化)112×112
448×448 —— 224×224这一步的由来?
先说一下卷积计算的公式:

一般填充P=0或P=1,则OH =(448+2×1-7)/ 2 + 1 = 222,为什么不是224?
查询源码后发现,这里默认填充的方式为SAME,则OH = H/S,向上取整,则OH = 448 / 2 = 224。
②.7×7×1024 —— 4096?
这里的转换需要以下几步:
a.transpose
不一定有,根据你的tensor通道的排序顺序决定,用来调整通道的排序。
b.flatten
进行展平处理,因为要对全连接层进行连接,所以必须要进行展平,通过一个节点个数为4096的全连接层进行全连接,得到一个4096维度的向量。
③.4096 —— 7×7×30?
先将4096通过一个节点数为1470的全连接层,最后reshape成一个7×7×30的特征向量。

如果面试官让你阐述下YOLOv1的网络结构图,可以如下说:(这样比较简短)
YOLOv1网络结构包括24层卷积层用来提取图像的特征,2层全连接层回归得到7×7×30(1+4+1+4+20)的张量。
网络结构大概如下:输入的是448×448×3通道的图像,就是RGB图像,然后用64个卷积核大小是7×7以步长为2进行卷积,然后是2×2最大池化,步长为2,然后是192个3×3卷积核进行卷积,然后再2×2最大池化,步长为2,然后后面就这样以一种级联的方式下去,最后获得一个7×7×1024维的张量,把它拉平喂到一个4096维的全连接层,输出一个4096维的向量,再把这个向量喂到一个1470维度的全连接层,输出一个1470维的向量,再把这个1470维度的向量reshape一下变成7×7×30的张量,所有预测框的坐标和类别都在这个7×7×30的张量里面。
5.YOLOv1的激活函数
YOLOv1中其最后一层使用的是线性激活函数,其他层使用的是LeakyReLU激活函数(x>0,f(x)=x;x<0,f(x)=0.1x),传统的ReLU函数是x<0时f(x)=0。
6.YOLOv1的损失函数

YOLOv1的损失函数 =
bounding box损失+confidence损失+classes损失。
YOLOv1损失函数使用的是平方和误差,是回归问题的损失函数,YOLO是把目标检测问题当成回归问题来解决的,回归问题需要预测连续的值,所以把预测的值和标签的值的差作为损失函数。但这样会带来一个问题,我们知道,一个grid cell生成2个bounding box,一张图像上肯定是目标少,非目标的多,如果都一视同仁的话,非目标的平方和误差肯定会影响目标的结果,所以需要在前面加上权重,就是加强定位误差损失,削弱不包含ground truth的预测框的confidence损失,在YOLOv1原论文中,对于负责检测物体的bounding box权重是5,不负责的权重是0.5。
(计算的主体也是误差平方和,如果面试官问到了根号下的误差平方和,你也可以讲讲,这么做是为了减少大物体边框的影响,画两个函数图像,y=x和y=根号下x)
7.YOLOv1总结
优点:
One stage,确实快。
缺点:
①对拥挤、密集型物体检测不太好;因为YOLOv1的核心理念:只有物体的中心落在了某个格子中,那个格子才会预测那个物体。但如果两个物体离的特别近,两个物体的中心都落在了同一个格子中,如何处理?且只有7×7个grid cell最多预测49个类别,这是YOLO算法的本质缺陷。
②对小物体检测不好;之后版本的YOLO采用了anchor去解决。
③没有Batch Normalize。
④分类正确但定位误差大,对于大物体还好,但对于小物体如果偏差一点都会对IOU有很大的影响,所以这是YOLOv1误差的主要来源。
⑤将所有目标都检出的正确率较低,即recall低,因为7×7个grid cell,最多只能生成98个bounding box,而同时期的Faster RCNN可以有2000个候选框,没法比。