对“基于SVM的人脸识别”一文的解读
参考文章:基于SVM的人脸识别
https://blog.csdn.net/cwlseu/article/details/52356665
概要描述
根据参考文章中使用sklearn中的svc人脸识别任务, 人脸数据集为LFM(Labeled Faces in the Wild)。我整理了一个适合colab平台scikit-learn 0.22.2.post1 环境的版本(原文中应该是scikit-learn 0.20之前的版本),当作是对该文章的一个补充说明,对于该文章的内容就不赘述了。笔者水平有限,疏漏难免,如果发现有错误或是不规范的地方,欢迎与我讨论。
详细说明
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, decomposition, datasets
from sklearn.pipeline import Pipeline
# from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
logistic = linear_model.LogisticRegression()
pca = decomposition.PCA()
pipe = Pipeline(steps=[('pca', pca), ('logistic', logistic)])
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
###############################################################################
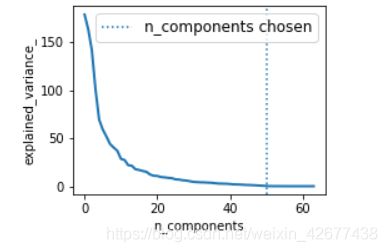
# Plot the PCA spectrum
pca.fit(X_digits)
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.axes([.2, .2, .7, .7])
plt.plot(pca.explained_variance_, linewidth=2)
plt.axis('tight')
plt.xlabel('n_components')
plt.ylabel('explained_variance_')
###############################################################################
# Prediction
n_components = [10, 20, 25, 30, 35, 40, 50, 64]#[i for i in range(1,65)]#
Cs = np.logspace(-4, 4, 3)
estimator = GridSearchCV(pipe,
dict(pca__n_components=n_components,
logistic__C=Cs))
estimator.fit(X_digits, y_digits)
plt.axvline(estimator.best_estimator_.named_steps['pca'].n_components,
linestyle=':', label='n_components chosen')
plt.legend(prop=dict(size=12))
plt.show()
训练代码:
from __future__ import print_function
from time import time
import logging
import matplotlib.pyplot as plt
# from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_lfw_people
# from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.svm import SVC
print(__doc__)
# Display progress logs on stdout
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
###############################################################################
# Download the data, if not already on disk and load it as numpy arrays
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# introspect the images arrays to find the shapes (for plotting)
n_samples, h, w = lfw_people.images.shape
# for machine learning we use the 2 data directly (as relative pixel
# positions info is ignored by this model)
X = lfw_people.data
n_features = X.shape[1]
# the label to predict is the id of the person
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
###############################################################################
# Split into a training set and a test set using a stratified k fold
# split into a training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
###############################################################################
# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled
# dataset): unsupervised feature extraction / dimensionality reduction
n_components = 80
print("Extracting the top %d eigenfaces from %d faces"
% (n_components, X_train.shape[0]))
t0 = time()
pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train)
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in %0.3fs" % (time() - t0))
###############################################################################
# Train a SVM classification model
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1,10, 100, 500, 1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
print(clf.best_estimator_.n_support_)
###############################################################################
# Quantitative evaluation of the model quality on the test set
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
###############################################################################
# Qualitative evaluation of the predictions using matplotlib
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
# Show the feature face
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# plot the result of the prediction on a portion of the test set
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# plot the gallery of the most significative eigenfaces
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
运行结果:
Automatically created module for IPython interactive environment
Total dataset size:
n_samples: 1288
n_features: 1850
n_classes: 7
Extracting the top 80 eigenfaces from 966 faces
done in 0.196s
Projecting the input data on the eigenfaces orthonormal basis
done in 0.010s
Fitting the classifier to the training set
done in 36.495s
Best estimator found by grid search:
SVC(C=1, break_ties=False, cache_size=200, class_weight='balanced', coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.01, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
[ 62 166 90 359 83 56 103]
Predicting people's names on the test set
done in 0.035s
precision recall f1-score support
Ariel Sharon 0.90 0.69 0.78 13
Colin Powell 0.85 0.92 0.88 60
Donald Rumsfeld 0.71 0.63 0.67 27
George W Bush 0.91 0.95 0.93 146
Gerhard Schroeder 0.70 0.76 0.73 25
Hugo Chavez 0.83 0.67 0.74 15
Tony Blair 0.88 0.78 0.82 36
accuracy 0.86 322
macro avg 0.83 0.77 0.79 322
weighted avg 0.86 0.86 0.86 322
[[ 9 1 3 0 0 0 0]
[ 0 55 0 2 1 1 1]
[ 1 3 17 6 0 0 0]
[ 0 3 1 139 1 1 1]
[ 0 0 2 2 19 0 2]
[ 0 2 0 1 2 10 0]
[ 0 1 1 2 4 0 28]]