图的谱图理论
图的谱图理论[Updating]
文章目录
- 图的谱图理论[Updating]
-
- 参考内容
- 概述
- 权重图与图信号
- 图拉普拉斯
- 为什么选择拉普拉斯,什么是图的傅立叶变换
- 图上的频率
- 图的两域
- 图的离散计算-图结构下的信号光滑度
- 其他的图矩阵
- 图上滤波
-
- 谱域滤波
- 空域滤波
- 空域滤波和频域滤波
- 图上卷积
- 图上平移
- 图信号调制与膨胀
参考内容
- 从普通的拉普拉斯算子到图上的拉普拉斯算子L=D-W
- 论文:《The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains》
- 推荐:如何理解拉普拉斯矩阵的特征值表示频率,拉普拉斯矩阵的特征向量作为基和基底 7,7.1,7.2
- Courant-Fischer定理、谱图分析和图的分割
- 拉普拉斯矩阵特征值范围的估算
概述
论文《The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains》(2013)的主要内容:
- 图的概述(图的普适性、作用、意义等),略去
- 描述如何编码图结构,仿照传统的傅立叶理论基础,定义图上的频谱概念,重点
- 介绍经典的信号处理操作如何迁移到图领域,其中包括滤波器设计、平移变换、调制、下采样。次重
- 由上述经典操作构成的图变换操作,各类小波变换方法survey。(当前水平难以下咽,同时也不作为论文重点内容)
- 总结
目的是加深对图、图信号、图的“频谱”的理解,了解图谱信号的计算方法及处理调制,理解传统傅立叶变换和图谱的关系。
A tutorial overview of the analysis of data on graphs from a signal processing perspective.
权重图与图信号
我们仅关注并讨论无向的有权连通图,非连通图则拆分为多个连通图考虑 G = { V , E , W } \mathcal{G}=\{\mathcal{V},\mathcal{E},\bold{W}\} G={V,E,W},其中 ∣ V ∣ = N |\mathcal{V}|=N ∣V∣=N,表示图上有N个节点, E 、 W \mathcal{E}、\bold{W} E、W分别为边的集合以及边连接权重矩阵(对称阵)。
- 边 e = ( i , j ) e=(i,j) e=(i,j),可以通过数据的自然属性构成,也可以认为构造。常用的利用高斯核构造距离的方式如下:
W i , j = { e x p ( − [ d i s t ( i , j ) ] 2 2 θ 2 ) , i f d i s t ( i , j ) < t h r e s h o l d 0 , o t h e r w i s e \bold{W_{i,j}}=\left\{\begin{aligned}exp(-\frac{[dist(i,j)]^2}{2\theta^2}),\ \ \ &if\ \ dist(i,j) - 定义图信号 f : V → R , f ∈ R N f:\mathcal{V}\rightarrow\mathbb{R},f\in\mathbb{R}^N f:V→R,f∈RN,向量 f f f的第i个元素,表示节点集合中第i的节点的信号值

图拉普拉斯
定义未正则化的图拉普拉斯矩阵为 L = D − W L = D-W L=D−W,D是度对角矩阵,W是权重连接矩阵。
- L是一个差分算子,具体表现为,针对任何一个图信号 f ∈ R N f\in \mathbb{R}^N f∈RN:
( L f ) ( i ) = ∑ j ∈ N i W i , j [ f ( i ) − f ( j ) ] (Lf)(i)=\sum_{j\in\mathcal{N_i}}{W_{i,j}[f(i)-f(j)]} (Lf)(i)=∑j∈NiWi,j[f(i)−f(j)] - L是实对称矩阵,于是L具有完备的一套正交的特征向量,我们用 u 0 , u 1 , u 2 , … , u N − 1 u_0,u_1,u_2,\dots,u_{N-1} u0,u1,u2,…,uN−1标注,这些特征向量也有对应的一组特征值,特征值我们用 λ 0 , λ 1 , λ 2 , … , λ N − 1 \lambda_0,\lambda_1,\lambda_2,\dots,\lambda_{N-1} λ0,λ1,λ2,…,λN−1标注。我们将特征值从小到大排序使得 0 = λ 0 ≤ λ 1 ≤ λ 2 ≤ ⋯ ≤ λ N − 1 : = λ m a x 0=\lambda_0\le\lambda_1\le\lambda_2\le\dots\le\lambda_{N-1}:=\lambda_{max} 0=λ0≤λ1≤λ2≤⋯≤λN−1:=λmax
Q:为什么 λ i ≥ 0 \lambda_i\ge0 λi≥0 ?
A:由于L是半正定矩阵,证明:对于任何非零向量 x ∈ R N x\in\mathbb{R}^N x∈RN, x T L x = ∑ ( i , j ) ∈ E W i , j [ x ( i ) − x ( j ) ] 2 ≥ 0 x^TLx=\sum_{(i,j)\in\mathcal{E}}{W_{i,j}[x(i)-x(j)]^2}\ge0 xTLx=∑(i,j)∈EWi,j[x(i)−x(j)]2≥0
Q:为什么 λ 0 = 0 \lambda_0=0 λ0=0 ?
A:由于 L u = λ u Lu=\lambda u Lu=λu,取 u i = 1 ( f o r i ∈ [ 0 , 1 , … , N − 1 ] ) u_i=1(for\ i \in[0,1,\dots,N-1]) ui=1(for i∈[0,1,…,N−1]),此时对应特征值为0
为什么选择拉普拉斯,什么是图的傅立叶变换
-
首先解释什么是拉普拉斯算子,数学上拉普拉斯算子是非混合二阶偏导数的和,举例来说对于 y = f ( x 1 , x 2 , . . . ) y=f(x_1,x_2,...) y=f(x1,x2,...),其拉普拉斯算子定义为
Δ = ∑ i ∂ 2 / ∂ x i 2 \Delta=\sum_i{\partial^2}/\partial x_i^2 Δ=∑i∂2/∂xi2
考虑单变量函数的离散近似, ∂ f / ∂ x ≈ f ( x + 1 ) − f ( x ) \partial f/\partial x \approx f(x+1)-f(x) ∂f/∂x≈f(x+1)−f(x),那么 ∂ 2 f / ∂ x 2 ≈ f ′ ( x ) − f ′ ( x − 1 ) ≈ f ( x + 1 ) + f ( x − 1 ) − 2 f ( x ) \partial ^2f/\partial x^2 \approx f'(x)-f'(x-1)\approx f(x+1)+f(x-1)-2f(x) ∂2f/∂x2≈f′(x)−f′(x−1)≈f(x+1)+f(x−1)−2f(x)
此处获得结论:拉普拉斯算子计算的是在所有自由度进行扰动后获得的增益的和。
一维信号有+1,-1两个扰动方向,而对于N个节点的图,其自由度为N,那么拉普拉斯算子作用于信号f 需要满足
( L f ) ( i ) = ∑ j ∈ N i W i , j [ f ( i ) − f ( j ) ] ⇒ L = D − W (Lf)(i)=\sum_{j\in\mathcal{N_i}}{W_{i,j}[f(i)-f(j)]}\Rightarrow L=D-W (Lf)(i)=j∈Ni∑Wi,j[f(i)−f(j)]⇒L=D−W -
传统傅立叶变换定义为: f ^ ( ω ) = ∫ R f ( t ) e − 2 π i ω t d t \hat{f}(\omega)=\int_\mathbb{R} f(t)e^{-2\pi i \omega t}dt f^(ω)=∫Rf(t)e−2πiωtdt,其中 e − 2 π i ω t e^{-2\pi i \omega t} e−2πiωt是传统傅立叶变换中的基底,同时也可以看成是一维空间中的拉普拉斯算子的特征向量: − Δ ( e 2 π i ω t ) = − ∂ 2 ∂ t 2 e 2 π i ω t = ( 2 π ω ) 2 e 2 π i ω t -\Delta(e^{2\pi i \omega t})=-\frac{\partial^2}{\partial t ^2}e^{2\pi i \omega t}=(2\pi \omega)^2 e^{2\pi i \omega t} −Δ(e2πiωt)=−∂t2∂2e2πiωt=(2πω)2e2πiωt其中我们可以将特征值项看作频率,特征向量项看作基底。那么传统傅立叶变换可以堪称将信号在不同的拉普拉斯特征向量上进行投影。
-
在图上有 L u = λ u Lu=\lambda u Lu=λu我们将特征值 λ \lambda λ看成频率项,特征向量 u u u看成基。仿照信号在不同的图拉普拉斯矩阵的特征向量上进行投影定义图上的傅立叶变换为: f ^ ( λ l ) = ∑ i = 0 N − 1 f ( i ) u l ∗ ( i ) \hat{f}(\lambda_l)=\sum_{i=0}^ {N-1}{f(i)u_l^*(i)} f^(λl)=i=0∑N−1f(i)ul∗(i)定义图上的逆傅立叶变换为: f ( i ) = ∑ l = 0 N − 1 f ^ ( λ l ) u l ( i ) f(i)=\sum_{l=0}^{N-1}{\hat{f}(\lambda_l)u_l(i)} f(i)=l=0∑N−1f^(λl)ul(i)
Q: 为什么我们可以将特征向量 u u u看成图空间的基?
A: 图空间包含N个节点,自由度为N,恰好拉普拉斯是实对称阵,拥有N个正交且互不相关的特征向量,故可作为图空间的基。
图上的频率
在式子 − Δ ( e 2 π i ω t ) = − ∂ 2 ∂ t 2 e 2 π i ω t = ( 2 π ω ) 2 e 2 π i ω t -\Delta(e^{2\pi i \omega t})=-\frac{\partial^2}{\partial t ^2}e^{2\pi i \omega t}=(2\pi \omega)^2 e^{2\pi i \omega t} −Δ(e2πiωt)=−∂t2∂2e2πiωt=(2πω)2e2πiωt中我们将 ( 2 π ω ) 2 (2\pi \omega)^2 (2πω)2看成频率项容易理解,那如何理解我们将特征值 λ \lambda λ看成频率项?
首先对于 λ 0 = 0 \lambda_0=0 λ0=0,当图谱频率为0时,其对应的基,也就是特征向量(经过归一化)为 u 0 = [ 1 N , 1 N , … , 1 N ] T u_0=[\frac{1}{\sqrt{N}},\frac{1}{\sqrt{N}},\dots,\frac{1}{\sqrt{N}}]^T u0=[N1,N1,…,N1]T,如此的基可以看成是在图上所有的节点都拥有同样大小的信号值,可以当作是直流分量,类比传统领域内的 ω = 0 , f ≡ 1 \omega=0,f\equiv1 ω=0,f≡1。
当 λ \lambda λ增大时,随着在节点上的移动信号变化的更加迅速,直觉上可以从式子 L u = λ u , ∣ ∣ u ∣ ∣ = 1 Lu=\lambda u,||u||=1 Lu=λu,∣∣u∣∣=1中观察得出
L是差分算子, L u Lu Lu衡量了不同节点与相邻节点的差异性,那么, u u u上相邻节点差异性越大 ⇒ \Rightarrow ⇒ L u Lu Lu越大 ⇒ λ \Rightarrow\lambda ⇒λ越大
频率(信号随节点变化的程度)也可以通过 过零边 的数量表示,类比过零点。定义过零边的集合为:
Z G ( f ) : = { e = ( i , j ) ∈ E : f ( i ) f ( j ) < 0 } \mathcal{Z}_\mathcal{G}(f):=\{e=(i,j)\in\mathcal{E}:f(i)f(j)<0\} ZG(f):={e=(i,j)∈E:f(i)f(j)<0}
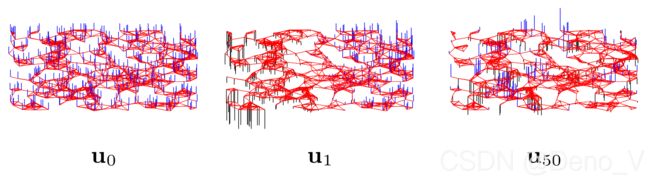
以一张随机生成的网络结构为例,绘制其频率0、1、50对应的特征向量如下图所示:
过零边的数量和特征频率的关系如下图所示:
 (右图为使用经过归一化拉普拉斯矩阵得到的特征值分布)
(右图为使用经过归一化拉普拉斯矩阵得到的特征值分布)
虽然于传统领域中震荡的波形的频律有所差别,但是也足够说明随着图谱上频率的增大,信号随节点的变化更加迅速。
Q:传统和图谱的频率的不同?
A:传统的频率是连续的,无限的。但是图谱的频率是离散的,有限的。
图的两域
图上的傅立叶变换和逆傅立叶变换为我们提供了两个视角观察图,其一是空域(vertex domain),其二是谱域(spectral domain)。对于空域的信号 g g g,记其谱域信号为 g ^ \hat{g} g^,我们也称这类信号为核(kernel)。以一个谱域上长尾的信号为例(heat kernel)其空域和谱域如下图所示。类似这种数据,也可以通过记录头部傅立叶系数进行存储,实现图数据的压缩存储。

图的离散计算-图结构下的信号光滑度
为了数学上定义图的光滑程度,首先定义图信号在节点i的边导数(edge derivative): ∂ f ∂ e ∣ i : = W i , j [ f ( j ) − f ( i ) ] \left.\frac{\partial f}{\partial e}\right |_i:=\sqrt{W_{i,j}}[f(j)-f(i)] ∂e∂f∣∣∣∣i:=Wi,j[f(j)−f(i)]接着定义,在节点i处的图梯度(graph gradient):
▽ i f : = [ { ∂ f ∂ e ∣ i } e ∈ E s . t . e = ( i , j ) f o r s o m e j ∈ V ] \bigtriangledown_if:=\left[\left\{\left.\frac{\partial f}{\partial e}\right |_i\right\}_{e\in\mathcal{E}\ s.t.\ e=(i,j)\ for\ some\ j\in\mathcal{V}}\right] ▽if:=[{∂e∂f∣∣∣∣i}e∈E s.t. e=(i,j) for some j∈V]那么,图信号在i节点的局部方差表示为: ∥ ▽ i f ∥ : = [ ∑ e = ( i , j ) ∈ E ( ∂ f ∂ e ∣ i ) 2 ] 1 2 = [ ∑ j ∈ N i W i , j [ f ( i ) − f ( j ) ] 2 ] 1 2 \|\bigtriangledown_if\|:=\left[ \sum_{e=(i,j)\in\mathcal{E}}{\left(\left.\frac{\partial f}{\partial e}\right |_i\right)^2} \right]^{\frac{1}{2}}=\left[\sum_{j\in\mathcal{N_i}}{W_{i,j}[f(i)-f(j)]^2}\right]^{\frac{1}{2}} ∥▽if∥:=⎣⎡e=(i,j)∈E∑(∂e∂f∣∣∣∣i)2⎦⎤21=⎣⎡j∈Ni∑Wi,j[f(i)−f(j)]2⎦⎤21图信号的局部方差描述了信号在该节点周围的光滑程度。图的全局光滑程度定义为: S p ( f ) : = 1 / p ∑ i ∈ V ∥ ▽ i f ∥ 2 p S_p(f):=1/p\sum_{i\in\mathcal{V}}\|\triangledown_if\|_2^p Sp(f):=1/pi∈V∑∥▽if∥2p当取p=2时, S 2 ( f ) S_2(f) S2(f)就是图拉普拉斯二次型(graph Laplacian quadratic form) S 2 ( f ) = ∑ ( i , j ) ∈ E W i , j [ f ( i ) − f ( j ) ] 2 = f T L f S_2(f)=\sum_{(i,j)\in\mathcal{E}}{W_{i,j}[f(i)-f(j)]}^2=f^TLf S2(f)=(i,j)∈E∑Wi,j[f(i)−f(j)]2=fTLf
谈论图结构数据的信号光滑程度是需要同时考虑图的拓扑信息的。相同的信号在节点相同但是拓扑结构不同的图上,其信号光滑度是不一致的。下图展现了节点相同,信号相同,拓扑结构不同的条件下图与其相应的图谱,其中 f T L 1 f = 0.14 , f T L 2 f = 1.31 , f T L 3 f = 1.81 f^TL_1f=0.14,f^TL_2f=1.31,f^TL_3f=1.81 fTL1f=0.14,fTL2f=1.31,fTL3f=1.81。

通过Courant-Fischer定理可以得到:
λ 0 = m i n { f T L f } ( ∥ f ∥ 2 = 1 ) \lambda_0=min\{f^TLf\}\ \ \ \ \ \ \ (\|f\|_2=1) λ0=min{fTLf} (∥f∥2=1) λ l = m i n { f T L f } ( ∥ f ∥ 2 = 1 , f ⊥ s p a n { u 0 , . . . , u l − 1 } ) \lambda_l=min\{f^TLf\}\ \ \ (\|f\|_2=1,f\perp span\{u_0,...,u_{l-1}\}) λl=min{fTLf} (∥f∥2=1,f⊥span{u0,...,ul−1})
由于 u l ⊥ s p a n { u 0 , . . . , u l − 1 } u_l\perp span\{u_0,...,u_{l-1}\} ul⊥span{u0,...,ul−1},故而 λ l = m i n { u l T L u l } ( ∥ u l ∥ 2 = 1 ) \lambda_l=min\{u_l^TLu_l\}\ \ \ (\|u_l\|_2=1) λl=min{ulTLul} (∥ul∥2=1)
由上式也能看出通过引入光滑程度可以为什么低频特征值对应的特征向量在图上会更加光滑。
证明:
f T L f = f T U Λ U T f = z T Λ z f^TLf=f^TU\Lambda U^Tf=z^T\Lambda z fTLf=fTUΛUTf=zTΛz其中 z = U T f z=U^Tf z=UTf由于U是正交变换且 ∥ f ∥ 2 = 1 \|f\|_2=1 ∥f∥2=1,故 ∥ z ∥ 2 = 1 \|z\|_2=1 ∥z∥2=1
若 f ⊥ s p a n { u 0 , . . . , u l − 1 } f\perp span\{u_0,...,u_{l-1}\} f⊥span{u0,...,ul−1}则 z = [ 0 , . . . , 0 , u l T f , u l + 1 T f , . . . , u N T f ] T : = [ 0 , . . . , 0 , z l , z l + 1 , . . , z N ] T z=[0,...,0,u_l^Tf,u_{l+1}^Tf,...,u_N^Tf]^T:=[0,...,0,z_l,z_l+1,..,z_N]^T z=[0,...,0,ulTf,ul+1Tf,...,uNTf]T:=[0,...,0,zl,zl+1,..,zN]T f T L f = z T Λ z = z l 2 λ l + z l + 1 2 λ l + 1 + ⋯ + z N 2 λ N ≥ λ l ∑ i = l N z i 2 = λ l f^TLf=z^T\Lambda z=z_{l}^2\lambda_{l}+z_{l+1}^2\lambda_{l+1}+\dots+z_{N}^2\lambda_{N}\ge\lambda_l\sum_{i=l}^Nz_i^2=\lambda_l fTLf=zTΛz=zl2λl+zl+12λl+1+⋯+zN2λN≥λli=l∑Nzi2=λl
其他的图矩阵
除了拉普拉斯矩阵外,归一化的拉普拉斯矩阵 L n o r m L_{norm} Lnorm也是常用的算子,使用归一化的拉普拉斯算子有一个好处,归一化的拉普拉斯矩阵特征值满足: 0 = λ ^ 0 ≤ λ ^ 1 ≤ λ ^ 2 ≤ ⋯ ≤ λ ^ N − 1 ≤ 2 0=\hat\lambda_0\le\hat\lambda_1\le\hat\lambda_2\le\dots\le\hat\lambda_{N-1}\le2 0=λ^0≤λ^1≤λ^2≤⋯≤λ^N−1≤2
证明
L n o r m = D − 1 / 2 L D − 1 / 2 , L u 0 = λ 0 u 0 = 0 ⇒ D 1 / 2 L n o r m ( D 1 / 2 u 0 ) = 0 L_{norm}=D^{-1/2}LD^{-1/2}\ ,\ Lu_0=\lambda_0u_0=\bold{0}\Rightarrow D^{1/2}L_{norm}(D^{1/2}u_0)=\bold 0 Lnorm=D−1/2LD−1/2 , Lu0=λ0u0=0⇒D1/2Lnorm(D1/2u0)=0故 D 1 / 2 u 0 D^{1/2}u_0 D1/2u0对应的特征值为0。注意此时0特征值对应的特征向量不具有常值特性!!
对于实对阵阵A(特征值为 λ \lambda λ),其瑞利熵 λ m i n ≤ R = x T A x x T x ≤ λ m a x \lambda_{min}\le R=\frac{x^TAx}{x^Tx}\le\lambda_{max} λmin≤R=xTxxTAx≤λmax,利用该性质证明归一化的拉普拉斯矩阵最大特征值不超过2.
归一化的拉普拉斯矩阵的瑞利熵为: R = f T D − 1 / 2 L D − 1 / 2 f T f = z T L z z T D z = ∑ ( i , j ) ∈ E W u , v ( z u − z v ) 2 ∑ v z v 2 d v ≤ 2 ∑ ( i , j ) ∈ E W u , v ( z u 2 + z v 2 ) ∑ v z v 2 d v = 2 R=\frac{f^TD^{-1/2}LD^{-1/2}}{f^Tf}=\frac{z^TLz}{z^TDz}=\frac{\sum_{(i,j)\in\mathcal{E}}W_{u,v}(z_u-z_v)^2}{\sum_v z_v^2d_v}\le2\frac{\sum_{(i,j)\in\mathcal{E}}W_{u,v}(z_u^2+z_v^2)}{\sum_v z_v^2d_v}=2 R=fTffTD−1/2LD−1/2=zTDzzTLz=∑vzv2dv∑(i,j)∈EWu,v(zu−zv)2≤2∑vzv2dv∑(i,j)∈EWu,v(zu2+zv2)=2取等号,当且仅当图为二部图
除上述两种之外,还有基于随机游走的半归一化拉普拉斯矩阵 L s e m i − n o r m = I N − D − 1 / 2 W L_{semi-norm}=I_N-D^{-1/2}W Lsemi−norm=IN−D−1/2W
目前,没有明确的在什么条件下选择哪一种算子更加有利,归一化的拉普拉斯算子其特征值有被限制在[0,2]的优势,而拉普拉斯算子有特征值为0时对应的特征向量为常值的优势(有利于设计有关DC信号的滤波器)。
图上滤波
谱域滤波
传统滤波器即在信号的频谱上进行操作,例如放大某些频段的信号或者抑制某些频道的信号,这个在频域上表现为乘积,在时域上则表现为卷积,不过多赘述了。
在图上,也延续相同的做法,即对输入信号 f i n f_{in} fin进行傅立叶变换得到其谱表示 f i n ^ = U T f i n \hat{f_{in}}=U^Tf_{in} fin^=UTfin,滤波器 h h h在其频谱上进行放大或抑制得到 f ^ o u t = h ( f ^ i n ) \hat f_{out}=h(\hat f_{in}) f^out=h(f^in),最后通过逆傅立叶变换得到最后的输出 f o u t = U f ^ o u t f_{out}=U\hat f_{out} fout=Uf^out,矩阵表示如下: f o u t = h ^ ( L ) f i n f_{out}=\hat h(L)f_{in} fout=h^(L)fin h ^ ( L ) : = U d i a g ( [ h ^ ( λ 0 ) , … , h ^ ( λ N − 1 ) ] ) U T \hat h(L):=Udiag([\hat h(\lambda_0),\dots,\hat h(\lambda_{N-1})])U^T h^(L):=Udiag([h^(λ0),…,h^(λN−1)])UT
如设计(低通)滤波器 h ^ ( λ ) : = 1 1 + γ λ \hat h(\lambda):=\frac{1}{1+\gamma\lambda} h^(λ):=1+γλ1,并且针对含有噪声的图片建图,建图方法为每个像素点构成一个节点,每个节点和他上下左右和对角线一共八个节点形成边的关联,边的权重选用前文所述的高斯距离核计算(通过像素值之间的距离计算,而不是图片上的空间距离)。将设计的低通滤波器应用在所建图上,效果如下所示(最右):
可以看出图滤波明显减少了边缘模糊的副作用。
空域滤波
图上的空域滤波可以被一下公式所概括:
f o u t ( i ) = b i , i f i n ( i ) + ∑ j ∈ N ( i , K ) b i , j f i n ( j ) f_{out}(i)=b_{i,i}f_{in}(i)+\sum_{j\in\mathcal{N}(i,K)}b_{i,j}f_{in}(j) fout(i)=bi,ifin(i)+j∈N(i,K)∑bi,jfin(j)其中 N ( i , K ) \mathcal{N}(i,K) N(i,K)表示K-hop邻居集合, b i , j b_{i,j} bi,j为一些参数。
空域滤波和频域滤波
空域滤波和频域滤波是可以相互转换的,假设存在一个频域的滤波器满足 h ^ ( λ l ) = ∑ k = 0 K a k λ l k \hat h(\lambda_l)=\sum_{k=0}^K a_k\lambda_l^k h^(λl)=k=0∑Kakλlk我们可以将其转化到空域中表示 f o u t ( i ) = ∑ l = 0 N − 1 f ^ i n ( λ l ) h ^ ( λ l ) u l ( i ) = ∑ j = 1 N f i n ( j ) ∑ k = 0 K a k ∑ l = 0 N − 1 λ k u l ∗ ( j ) u l ( i ) = ∑ j = 1 N f i n ( j ) ∑ k = 0 K a k ( L k ) i , j \begin{aligned} f_{out}(i)&=\sum_{l=0}^{N-1}\hat f_{in}(\lambda_l)\hat h(\lambda_l)u_l(i)\\ &=\sum_{j=1}^N f_{in}(j)\sum_{k=0}^K a_k\sum_{l=0}^{N-1}\lambda^ku_l^*(j)u_l(i)\\&=\sum_{j=1}^N f_{in}(j)\sum_{k=0}^K a_k(L^k)_{i,j}\end{aligned} fout(i)=l=0∑N−1f^in(λl)h^(λl)ul(i)=j=1∑Nfin(j)k=0∑Kakl=0∑N−1λkul∗(j)ul(i)=j=1∑Nfin(j)k=0∑Kak(Lk)i,j故,空域中我们只需要满足: b i , j : = ∑ k = d G ( i , j ) K a k ( L k ) i , j b_{i,j}:=\sum_{k=d_\mathcal G(i,j)}^K a_k(L^k)_{i,j} bi,j:=k=dG(i,j)∑Kak(Lk)i,j
图上卷积
传统领域的卷积被定义为: f o u t ( t ) = ∫ f i n ( τ ) h ( t − τ ) d τ f_{out}(t)=\int f_{in}(\tau)h(t-\tau)d\tau fout(t)=∫fin(τ)h(t−τ)dτ,而图上很难有 t − τ t-\tau t−τ的概念。所以不能直接扩展概念。
但是由于时域上的卷积在频域上是乘积,那么图上,我们也将卷积操作通过谱域解决:
( f ∗ h ) ( i ) : = ∑ l = 0 N − 1 f ^ ( λ l ) h ^ ( λ l ) u l ( i ) (f\ast h)(i):=\sum_{l=0}^{N-1}\hat f(\lambda_l)\hat h(\lambda_l)u_l(i) (f∗h)(i):=l=0∑N−1f^(λl)h^(λl)ul(i)
图上平移
图上很难有 t − τ t-\tau t−τ的概念。所以不能直接扩展概念。但是在传统方案中也可以通过卷积操作完成信号的平移。狄利克雷函数(冲激函数 δ \delta δ)可以辅助实现平移:
f ( t ) ∗ δ ( t − τ ) = f ( t − τ ) f(t)\ast\delta(t-\tau)=f(t-\tau) f(t)∗δ(t−τ)=f(t−τ)
所以我们定义一个平移算子 T n T_n Tn:
( T n g ) ( i ) : = N ( g ∗ δ n ) ( i ) = N ∑ l = 0 N − 1 g ^ ( λ l ) u l ∗ ( n ) u l ( i ) (T_ng)(i):=\sqrt N(g\ast \delta_n)(i)=\sqrt N \sum_{l=0}^{N-1}\hat g(\lambda_l)u^*_l(n)u_l(i) (Tng)(i):=N(g∗δn)(i)=Nl=0∑N−1g^(λl)ul∗(n)ul(i)其中 δ n ( i ) = 1 i f i = n e l s e 0 \delta_n(i)=1\ if\ i=n\ else\ 0 δn(i)=1 if i=n else 0

图信号调制与膨胀
在传统领域,时域上给信号乘上一个频率的基(类比载波调制),等价于在频谱上进行平移:
( M ω f ) ( t ) : = e 2 π i ω t f ( t ) (M_\omega f)(t):=e^{2\pi i \omega t}f(t) (Mωf)(t):=e2πiωtf(t) M ω f ^ ( ξ ) : = f ^ ( ξ − ω ) \hat{M_\omega f}(\xi):=\hat f(\xi-\omega) Mωf^(ξ):=f^(ξ−ω)在图上,我们也等价的定义类似的操作,用基与信号在空域相乘: ( M k g ) ( i ) : = N u k ( i ) g ( i ) (M_k g)(i):=\sqrt{N}u_k(i)g(i) (Mkg)(i):=Nuk(i)g(i)
但是在图上并没有严格的类似于传统中频谱平移的性质,只有当 g ^ \hat g g^集中在0附近的时候(低频为主), M k g ^ \hat{M_kg} Mkg^在集中在频率 λ k \lambda_k λk。
传统上的膨胀表示为: ( D s f ) ( t ) : = 1 s f ( t s ) (D_sf)(t):=\frac{1}{s}f(\frac{t}{s}) (Dsf)(t):=s1f(st) ( D s f ^ ) ( ξ ) : = f ^ ( s ξ ) (\hat{D_sf})(\xi):=\hat f(s\xi) (Dsf^)(ξ):=f^(sξ)我们同样不能从空域定义膨胀,只能从谱域定义 ( D s g ^ ) ( λ ) : = g ^ ( s λ ) (\hat{D_sg})(\lambda):=\hat g(s\lambda) (Dsg^)(λ):=g^(sλ)
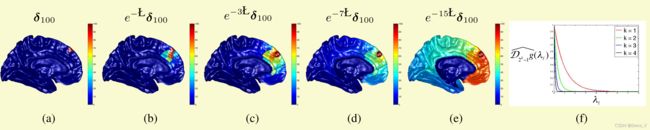
举例来说,定义一个热传播算子(heat diffusion operator) R = e − L R = e^{-L} R=e−L,该算子作用于图信号 f f f上时,表示将信号沿边进行传播,我们可以加入温度系数 τ \tau τ控制信号的传播速率。
R τ f = ( e − τ L ) f = U Λ U T f = U ( d i a g ( D τ g ^ ) ) U T f = f ∗ ( D τ g ) \begin{aligned} R^\tau f=(e^{-\tau L})f & =U\Lambda U^Tf\\ &=U (diag(\hat{D_\tau g})) U^Tf\\ &=f \ast (D_\tau g) \end{aligned} Rτf=(e−τL)f=UΛUTf=U(diag(Dτg^))UTf=f∗(Dτg)其中g仅通过频谱来定义 g ^ ( λ l ) = e − λ l \hat g (\lambda_l)=e^{-\lambda_l} g^(λl)=e−λl