NNI自动化机器学习工具包
NNI 是 Neural Network Intelligence 的缩写,可以译作:智能神经网络。名字听起来陌生,但 NNI 实际上就是一个自动化机器学习工具包。它通过多种调优的算法来搜索最好的神经网络结构和超参数,并支持单机、本地多机、云等不同的运行环境。刚好接触到,记录一下方便以后查阅。
1 安装
pip install nni测试安装是否成功,输入:
nnictl -h出现下图模样即安装成功!
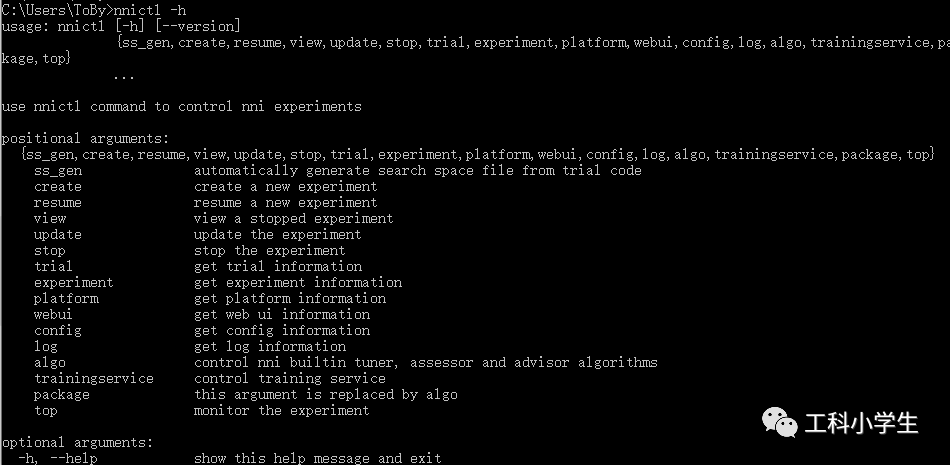
2 使用
安装完成后,想要使用NNI来完成一次实验,一般会有以下几个步骤:
-
定义模型训练和测试代码。
-
定义 NNI 搜索空间参数。
-
基于 NNI 接口改动模型代码。
-
定义 NNI Experiment 配置。
-
使用 NNICTL 工具完成训练。
示例:
本次示例使用的是手写字符数据集,并使用支持向量机来完成分类。首先定义模型。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_digits
from sklearn.svm import SVC
def load_data():
'''加载数据函数'''
digits = load_digits() # DIGITS 数据集
# 切分数据,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target, random_state=99, test_size=0.2)
# 标准化数据
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
return X_train, X_test, y_train, y_test
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_data()
model = SVC()
model.fit(X_train, y_train) # 训练模型
score = model.score(X_test, y_test)
print(score)代码非常简单,加载 DIGITS 数据集并完成归一化,使用默认参数定义 SVM 模型,然后训练并获得准确度。这其实是一个非常标准的训练过程。
定义搜索空间参数,并命名为search_space.json
{
"C": { "_type": "uniform", "_value": [0.1, 1] },
"keral": {
"_type": "choice",
"_value": ["linear", "rbf", "poly", "sigmoid"]
},
"degree": { "_type": "choice", "_value": [1, 2, 3, 4] },
"gamma": { "_type": "uniform", "_value": [0.01, 0.1] },
"coef0 ": { "_type": "uniform", "_value": [0.01, 0.1] }
}_type 实际上就是定义以何种方式从 _value 后续参数中取值。你可以阅读 官方文档 详细了解,这里就不再罗列了。
基于NNI接口改动模型代码
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import nni
def load_data():
'''加载数据函数'''
digits = load_digits() # DIGITS 数据集
# 切分数据,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target, random_state=99, test_size=0.2)
# 标准化数据
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
return X_train, X_test, y_train, y_test
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_data()
# 默认超参数
PARAMS = {'C': 1.0, 'kernel': 'linear', 'degree': 3, 'gamma': 0.01, 'coef0': 0.01}
# 从 Tuner 接收搜索空间生成的超参数
RECEIVED_PARAMS = nni.get_next_parameter()
PARAMS.update(RECEIVED_PARAMS) # 更新超参数
# 传入超参数
model = SVC(C=PARAMS.get('C'), kernel=PARAMS.get('kernel'),
degree=PARAMS.get('degree'), gamma=PARAMS.get('gamma'),
coef0=PARAMS.get('coef0'))
model.fit(X_train, y_train) # 训练模型
score = model.score(X_test, y_test) # 准确度
# 最后将 score 发送给可视化看板
nni.report_final_result(score)首先使用 import nni 导入 NNI 库,然后定义默认参数字典 PARAMS。接下来,使用 nni.get_next_parameter() 接收到新的参数,并更新默认参数后传入模型。最后,使用 nni.report_final_result 将需要可视化的指标发送给可视化看板,一般会选择分类准确度。
定义 NNI Experiment 配置,保存为文件config.yml。
authorName: gkxxs
experimentName: example_sklearn-classification
trialConcurrency: 3
maxExecDuration: 1h
maxTrialNum: 100
#choice: local, remote
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python svc.py
codeDir: .
gpuNum: 0配置文件中比较关键的字段有:
-
trialConcurrency:并发尝试任务的最大数量,根据机器配置而定。 -
maxExecDuration:Experiment 最大运行时长。 -
maxTrialNum:Experiment 最大运行 Trial 数量。 -
trainingServicePlatform:local表示本地,可选择remote,pai,kubeflow等平台。 -
searchSpacePath:搜索空间参数文件。 -
builtinTunerName:指定优化算法,例如:TPE, Random, Anneal, Evolution, BatchTuner, GridSearch 等。 -
optimize_mode:根据优化算法设置,TPE 默认为 maximize。 -
command:运行 Trial 进程的命令行。 -
codeDir:指定了 Trial 代码文件的目录
此时文件夹下应该有config.yml,search_space.json 和 svm.py 三个文件,之后打开cmd,通过cd命令切换到此文件夹,输入以下命令:
nnictl create --config config.yml -p 8957p后面是自定义端口,成功运行后会出现下图,选择其中一个URL在浏览器中打开。

然后就能动态地看到参数优化的过程
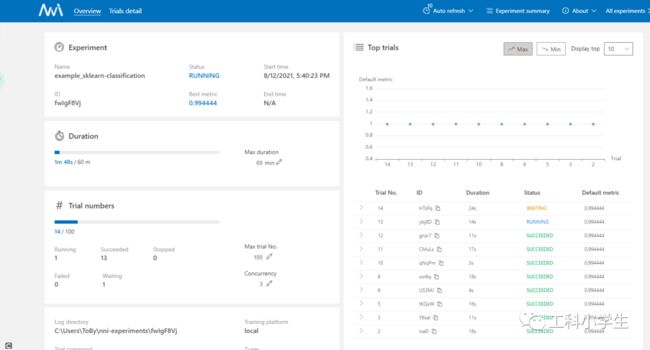
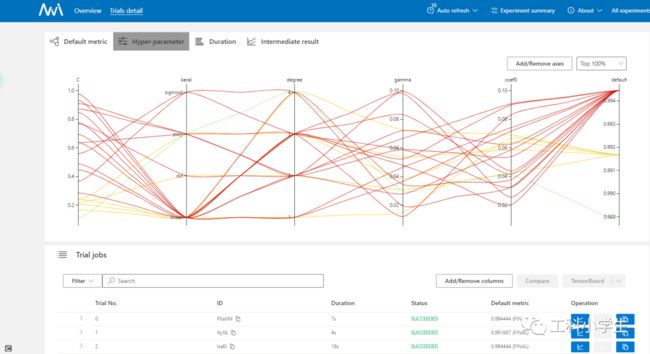
避坑:
如果一直fail,可以查看文件路径是否有中文,不要有中文;先使用默认参数运行一下模型代码,如能正确运行再进行自动化调参!