【目标检测】一些数据集处理常用代码
一些数据处理常用代码
在训练目标检测模型时,不同的数据集标签格式不一,不同模型要求的数据格式不一,最近一直在各种格式转换,用到的代码(大多数是找的别人的经试验能用的,部分是根据自己需求写的)在这儿总结一下。
文章目录
- 一些数据处理常用代码
-
-
- 1.标签数据格式转换
-
- (1).txt转xml【DOTA->VOC】
- (2).标签转为json格式【NWPU/DIOR->COCO】
- 2. 影像及标签裁剪
-
- (1).NWPU VHR
- (2).DOTA
- 3. 影像拼接
-
1.标签数据格式转换
(1).txt转xml【DOTA->VOC】
DOTA数据集的标签文件为txt格式,内容为:
四个角点坐标(顺时针排列)
类别名
difficult:0,1 表示实例是否难以识别,0表示不难1表示困难
x1 y1 x2 y2 x3 y3 x4 y4 category difficult
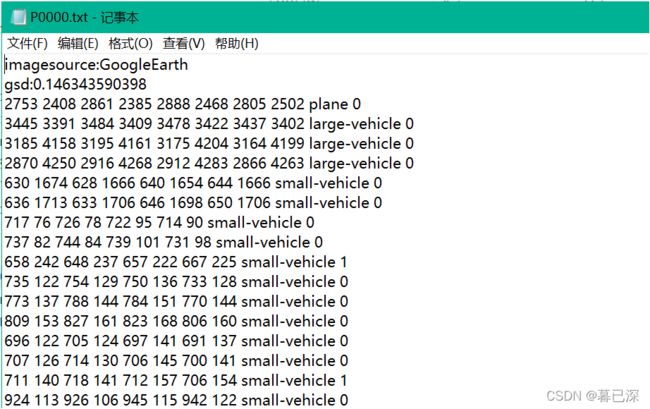
DOTA标签转换为xml格式代码:
'''
DOTA数据集中标签为txt,将其转换为xml
类别数目:15
类别名称:plane, ship, storage tank, baseball diamond, tennis court, basketball court,
ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout,
soccer ball field , swimming pool
'''
import os
import cv2
from xml.dom.minidom import Document
# import importlib,sys
# stdi, stdo, stde = sys.stdin, sys.stdout, sys.stderr
# importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
# sys.stdin, sys.stdout, sys.stderr = stdi, stdo, stde
category_set = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship', 'tennis-court',
'basketball-court', 'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor', 'swimming-pool', 'helicopter']
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def limit_value(a, b):
if a < 1:
a = 1
if a >= b:
a = b - 1
return a
def readlabeltxt(txtpath, height, width, hbb=True):
print(txtpath)
with open(txtpath, 'r') as f_in: # 打开txt文件
lines = f_in.readlines()
splitlines = [x.strip().split(' ') for x in lines] # 根据空格分割
boxes = []
for i, splitline in enumerate(splitlines):
if i in [0, 1]: # DOTA数据集前两行对于我们来说是无用的
continue
#
# if len(splitline)<10:
# print(txtpath+lines)
label = splitline[8]
kunnan = splitline[9]
if label not in category_set: # 只书写制定的类别
print(label)
continue
x1 = int(float(splitline[0]))
y1 = int(float(splitline[1]))
x2 = int(float(splitline[2]))
y2 = int(float(splitline[3]))
x3 = int(float(splitline[4]))
y3 = int(float(splitline[5]))
x4 = int(float(splitline[6]))
y4 = int(float(splitline[7]))
# 如果是hbb
if hbb:
xx1 = min(x1, x2, x3, x4)
xx2 = max(x1, x2, x3, x4)
yy1 = min(y1, y2, y3, y4)
yy2 = max(y1, y2, y3, y4)
xx1 = limit_value(xx1, width)
xx2 = limit_value(xx2, width)
yy1 = limit_value(yy1, height)
yy2 = limit_value(yy2, height)
box = [xx1, yy1, xx2, yy2, label, kunnan]
boxes.append(box)
else: # 否则是obb
x1 = limit_value(x1, width)
y1 = limit_value(y1, height)
x2 = limit_value(x2, width)
y2 = limit_value(y2, height)
x3 = limit_value(x3, width)
y3 = limit_value(y3, height)
x4 = limit_value(x4, width)
y4 = limit_value(y4, height)
box = [x1, y1, x2, y2, x3, y3, x4, y4, label, kunnan]
boxes.append(box)
return boxes
def writeXml(tmp, imgname, w, h, d, bboxes, hbb=True):
doc = Document()
# owner
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
# owner
folder = doc.createElement('folder')
annotation.appendChild(folder)
folder_txt = doc.createTextNode("VOC2007")
folder.appendChild(folder_txt)
filename = doc.createElement('filename')
annotation.appendChild(filename)
filename_txt = doc.createTextNode(imgname)
filename.appendChild(filename_txt)
# ones#
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
source.appendChild(database)
database_txt = doc.createTextNode("My Database")
database.appendChild(database_txt)
annotation_new = doc.createElement('annotation')
source.appendChild(annotation_new)
annotation_new_txt = doc.createTextNode("VOC2007")
annotation_new.appendChild(annotation_new_txt)
image = doc.createElement('image')
source.appendChild(image)
image_txt = doc.createTextNode("flickr")
image.appendChild(image_txt)
# owner
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid = doc.createElement('flickrid')
owner.appendChild(flickrid)
flickrid_txt = doc.createTextNode("NULL")
flickrid.appendChild(flickrid_txt)
ow_name = doc.createElement('name')
owner.appendChild(ow_name)
ow_name_txt = doc.createTextNode("idannel")
ow_name.appendChild(ow_name_txt)
# onee#
# twos#
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
size.appendChild(width)
width_txt = doc.createTextNode(str(w))
width.appendChild(width_txt)
height = doc.createElement('height')
size.appendChild(height)
height_txt = doc.createTextNode(str(h))
height.appendChild(height_txt)
depth = doc.createElement('depth')
size.appendChild(depth)
depth_txt = doc.createTextNode(str(d))
depth.appendChild(depth_txt)
# twoe#
segmented = doc.createElement('segmented')
annotation.appendChild(segmented)
segmented_txt = doc.createTextNode("0")
segmented.appendChild(segmented_txt)
for bbox in bboxes:
# threes#
object_new = doc.createElement("object")
annotation.appendChild(object_new)
name = doc.createElement('name')
object_new.appendChild(name)
name_txt = doc.createTextNode(str(bbox[-2]))
name.appendChild(name_txt)
pose = doc.createElement('pose')
object_new.appendChild(pose)
pose_txt = doc.createTextNode("Unspecified")
pose.appendChild(pose_txt)
truncated = doc.createElement('truncated')
object_new.appendChild(truncated)
truncated_txt = doc.createTextNode("0")
truncated.appendChild(truncated_txt)
difficult = doc.createElement('difficult')
object_new.appendChild(difficult)
difficult_txt = doc.createTextNode(bbox[-1])
difficult.appendChild(difficult_txt)
# threes-1#
bndbox = doc.createElement('bndbox')
object_new.appendChild(bndbox)
if hbb:
xmin = doc.createElement('xmin')
bndbox.appendChild(xmin)
xmin_txt = doc.createTextNode(str(bbox[0]))
xmin.appendChild(xmin_txt)
ymin = doc.createElement('ymin')
bndbox.appendChild(ymin)
ymin_txt = doc.createTextNode(str(bbox[1]))
ymin.appendChild(ymin_txt)
xmax = doc.createElement('xmax')
bndbox.appendChild(xmax)
xmax_txt = doc.createTextNode(str(bbox[2]))
xmax.appendChild(xmax_txt)
ymax = doc.createElement('ymax')
bndbox.appendChild(ymax)
ymax_txt = doc.createTextNode(str(bbox[3]))
ymax.appendChild(ymax_txt)
else:
x0 = doc.createElement('x0')
bndbox.appendChild(x0)
x0_txt = doc.createTextNode(str(bbox[0]))
x0.appendChild(x0_txt)
y0 = doc.createElement('y0')
bndbox.appendChild(y0)
y0_txt = doc.createTextNode(str(bbox[1]))
y0.appendChild(y0_txt)
x1 = doc.createElement('x1')
bndbox.appendChild(x1)
x1_txt = doc.createTextNode(str(bbox[2]))
x1.appendChild(x1_txt)
y1 = doc.createElement('y1')
bndbox.appendChild(y1)
y1_txt = doc.createTextNode(str(bbox[3]))
y1.appendChild(y1_txt)
x2 = doc.createElement('x2')
bndbox.appendChild(x2)
x2_txt = doc.createTextNode(str(bbox[4]))
x2.appendChild(x2_txt)
y2 = doc.createElement('y2')
bndbox.appendChild(y2)
y2_txt = doc.createTextNode(str(bbox[5]))
y2.appendChild(y2_txt)
x3 = doc.createElement('x3')
bndbox.appendChild(x3)
x3_txt = doc.createTextNode(str(bbox[6]))
x3.appendChild(x3_txt)
y3 = doc.createElement('y3')
bndbox.appendChild(y3)
y3_txt = doc.createTextNode(str(bbox[7]))
y3.appendChild(y3_txt)
xmlname = os.path.splitext(imgname)[0]
tempfile = os.path.join(tmp, xmlname + '.xml')
with open(tempfile, 'wb') as f:
f.write(doc.toprettyxml(indent='\t', encoding='utf-8'))
return
if __name__ == '__main__':
data_path = '/home/DOTA/train2017' #
images_path = os.path.join(data_path) # 样本图片路径
labeltxt_path = os.path.join('/home/DOTA/labeltxt/') #
anno_new_path = os.path.join('/home/DOTA/Annotations_xml/') # 新的voc格式存储位置(hbb形式)
ext = '.png' # 样本图片的后缀
filenames = os.listdir(labeltxt_path) # 获取每一个txt的名称
for filename in filenames:
filepath = labeltxt_path + '/' + filename # 每一个DOTA标签的具体路径
picname = os.path.splitext(filename)[0] + ext
pic_path = os.path.join(images_path, picname)
im = cv2.imread(pic_path) # 读取相应的图片
(H, W, D) = im.shape # 返回样本的大小
boxes = readlabeltxt(filepath, H, W, hbb=True) # 默认是矩形(hbb)得到gt
if len(boxes) == 0:
print('文件为空', filepath)
# 读取对应的样本图片,得到H,W,D用于书写xml
# 书写xml
writeXml(anno_new_path, picname, W, H, D, boxes, hbb=True)
print('正在处理%s' % filename)
(2).标签转为json格式【NWPU/DIOR->COCO】
一些数据集转COCO格式的代码NWPU,DIOR数据集标签转为COCO格式的json代码,
import os
import cv2
import json
import argparse
from tqdm import tqdm
import xml.etree.ElementTree as ET
COCO_DICT=['images','annotations','categories']
IMAGES_DICT=['file_name','height','width','id']
ANNOTATIONS_DICT=['image_id','iscrowd','area','bbox','category_id','id']
CATEGORIES_DICT=['id','name']
## {'supercategory': 'person', 'id': 1, 'name': 'person'}
## {'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'}
YOLO_CATEGORIES=['person']
RSOD_CATEGORIES=['aircraft','playground','overpass','oiltank']
NWPU_CATEGORIES=['airplane','ship','storage tank','baseball diamond','tennis court',\
'basketball court','ground track field','harbor','bridge','vehicle']
VOC_CATEGORIES=['aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow',\ 'diningtable','dog','horse','motorbike','person','pottedplant','sheep','sofa','train','tvmonitor']
DIOR_CATEGORIES=['golffield','Expressway-toll-station','vehicle','trainstation','chimney','storagetank',\
'ship','harbor','airplane','groundtrackfield','tenniscourt','dam','basketballcourt',\
'Expressway-Service-area','stadium','airport','baseballfield','bridge','windmill','overpass']
parser=argparse.ArgumentParser(description='2COCO')
#parser.add_argument('--image_path',type=str,default=r'T:/shujuji/DIOR/JPEGImages-trainval/',help='config file')
parser.add_argument('--image_path',type=str,default=r'G:/postgraduate1-1/EfficientdetPaper/paper/xiu/NWPU VHR-10 dataset/positive image set/',help='config file')
#parser.add_argument('--annotation_path',type=str,default=r'T:/shujuji/DIOR/Annotations/',help='config file')
parser.add_argument('--annotation_path',type=str,default=r'G:/postgraduate1-1/EfficientdetPaper/paper/xiu/NWPU VHR-10 dataset/ground truth/',help='config file')
parser.add_argument('--dataset',type=str,default='NWPU',help='config file')
parser.add_argument('--save',type=str,default='G:/postgraduate1-1/EfficientdetPaper/paper/xiu/NWPU VHR-10 dataset/train.json',help='config file')
args=parser.parse_args()
def load_json(path):
with open(path,'r') as f:
json_dict=json.load(f)
for i in json_dict:
print(i)
print(json_dict['annotations'])
def save_json(dict,path):
print('SAVE_JSON...')
with open(path,'w') as f:
json.dump(dict,f)
print('SUCCESSFUL_SAVE_JSON:',path)
def load_image(path):
img=cv2.imread(path)
#print(path)
return img.shape[0],img.shape[1]
def generate_categories_dict(category): #ANNOTATIONS_DICT=['image_id','iscrowd','area','bbox','category_id','id']
print('GENERATE_CATEGORIES_DICT...')
return [{CATEGORIES_DICT[0]:category.index(x)+1,CATEGORIES_DICT[1]:x} for x in category] #CATEGORIES_DICT=['id','name']
def generate_images_dict(imagelist,image_path,start_image_id=11725): #IMAGES_DICT=['file_name','height','width','id']
print('GENERATE_IMAGES_DICT...')
images_dict=[]
with tqdm(total=len(imagelist)) as load_bar:
for x in imagelist: #x就是图片的名称
#print(start_image_id)
dict={IMAGES_DICT[0]:x,IMAGES_DICT[1]:load_image(image_path+x)[0],\
IMAGES_DICT[2]:load_image(image_path+x)[1],IMAGES_DICT[3]:imagelist.index(x)+start_image_id}
load_bar.update(1)
images_dict.append(dict)
return images_dict
# return [{IMAGES_DICT[0]:x,IMAGES_DICT[1]:load_image(image_path+x)[0],\
# IMAGES_DICT[2]:load_image(image_path+x)[1],IMAGES_DICT[3]:imagelist.index(x)+start_image_id} for x in imagelist]
def DIOR_Dataset(image_path,annotation_path,start_image_id=11725,start_id=0):
categories_dict=generate_categories_dict(DIOR_CATEGORIES) #CATEGORIES_DICT=['id':,1'name':golffield......] id从1开始
imgname=os.listdir(image_path)
images_dict=generate_images_dict(imgname,image_path,start_image_id) #IMAGES_DICT=['file_name','height','width','id'] id从0开始的
print('GENERATE_ANNOTATIONS_DICT...') #生成cooc的注记 ANNOTATIONS_DICT=['image_id','iscrowd','area','bbox','category_id','id']
annotations_dict=[]
id=start_id
for i in images_dict:
image_id=i['id']
print(image_id)
image_name=i['file_name']
annotation_xml=annotation_path+image_name.split('.')[0]+'.xml'
tree=ET.parse(annotation_xml)
root=tree.getroot()
for j in root.findall('object'):
category=j.find('name').text
category_id=DIOR_CATEGORIES.index(category) #字典的索引,是从1开始的
x_min=float(j.find('bndbox').find('xmin').text)
y_min=float(j.find('bndbox').find('ymin').text)
w=float(j.find('bndbox').find('xmax').text)-x_min
h=float(j.find('bndbox').find('ymax').text)-y_min
bbox=[x_min,y_min,w,h]
dict={'image_id':image_id,'iscrowd':0,'bbox':bbox,'category_id':category_id,'id':id}
annotations_dict.append(dict)
id=id+1
print('SUCCESSFUL_GENERATE_DIOR_JSON')
return {COCO_DICT[0]:images_dict,COCO_DICT[1]:annotations_dict,COCO_DICT[2]:categories_dict}
def NWPU_Dataset(image_path,annotation_path,start_image_id=0,start_id=0):
categories_dict=generate_categories_dict(NWPU_CATEGORIES)
imgname=os.listdir(image_path)
images_dict=generate_images_dict(imgname,image_path,start_image_id)
print('GENERATE_ANNOTATIONS_DICT...')
annotations_dict=[]
id=start_id
for i in images_dict:
image_id=i['id']
image_name=i['file_name']
annotation_txt=annotation_path+image_name.split('.')[0]+'.txt'
txt=open(annotation_txt,'r')
lines=txt.readlines()
for j in lines:
if j=='\n':
continue
category_id=int(j.split(',')[4])
category=NWPU_CATEGORIES[category_id-1]
print(category_id,' ',category)
x_min=float(j.split(',')[0].split('(')[1])
y_min=float(j.split(',')[1].split(')')[0])
w=float(j.split(',')[2].split('(')[1])-x_min
h=float(j.split(',')[3].split(')')[0])-y_min
area=w*h
bbox=[x_min,y_min,w,h]
dict = {'image_id': image_id, 'iscrowd': 0, 'area': area, 'bbox': bbox, 'category_id': category_id,
'id': id}
id=id+1
annotations_dict.append(dict)
print('SUCCESSFUL_GENERATE_NWPU_JSON')
return {COCO_DICT[0]:images_dict,COCO_DICT[1]:annotations_dict,COCO_DICT[2]:categories_dict}
def YOLO_Dataset(image_path,annotation_path,start_image_id=0,start_id=0):
categories_dict=generate_categories_dict(YOLO_CATEGORIES)
imgname=os.listdir(image_path)
images_dict=generate_images_dict(imgname,image_path)
print('GENERATE_ANNOTATIONS_DICT...')
annotations_dict=[]
id=start_id
for i in images_dict:
image_id=i['id']
image_name=i['file_name']
W,H=i['width'],i['height']
annotation_txt=annotation_path+image_name.split('.')[0]+'.txt'
txt=open(annotation_txt,'r')
lines=txt.readlines()
for j in lines:
category_id=int(j.split(' ')[0])+1
category=YOLO_CATEGORIES
x=float(j.split(' ')[1])
y=float(j.split(' ')[2])
w=float(j.split(' ')[3])
h=float(j.split(' ')[4])
x_min=(x-w/2)*W
y_min=(y-h/2)*H
w=w*W
h=h*H
area=w*h
bbox=[x_min,y_min,w,h]
dict={'image_id':image_id,'iscrowd':0,'area':area,'bbox':bbox,'category_id':category_id,'id':id}
annotations_dict.append(dict)
id=id+1
print('SUCCESSFUL_GENERATE_YOLO_JSON')
return {COCO_DICT[0]:images_dict,COCO_DICT[1]:annotations_dict,COCO_DICT[2]:categories_dict}
def RSOD_Dataset(image_path,annotation_path,start_image_id=0,start_id=0):
categories_dict=generate_categories_dict(RSOD_CATEGORIES)
imgname=os.listdir(image_path)
images_dict=generate_images_dict(imgname,image_path,start_image_id)
print('GENERATE_ANNOTATIONS_DICT...')
annotations_dict=[]
id=start_id
for i in images_dict:
image_id=i['id']
image_name=i['file_name']
annotation_txt=annotation_path+image_name.split('.')[0]+'.txt'
txt=open(annotation_txt,'r')
lines=txt.readlines()
for j in lines:
category=j.split('\t')[1]
category_id=RSOD_CATEGORIES.index(category)+1
x_min=float(j.split('\t')[2])
y_min=float(j.split('\t')[3])
w=float(j.split('\t')[4])-x_min
h=float(j.split('\t')[5])-y_min
bbox=[x_min,y_min,w,h]
dict={'image_id':image_id,'iscrowd':0,'bbox':bbox,'category_id':category_id,'id':id}
annotations_dict.append(dict)
id=id+1
print('SUCCESSFUL_GENERATE_RSOD_JSON')
return {COCO_DICT[0]:images_dict,COCO_DICT[1]:annotations_dict,COCO_DICT[2]:categories_dict}
if __name__=='__main__':
dataset=args.dataset #数据集名字
save=args.save #json的保存路径
image_path=args.image_path #对于coco是图片的路径
annotation_path=args.annotation_path #coco的annotation路径
if dataset=='RSOD':
json_dict=RSOD_Dataset(image_path,annotation_path,0)
if dataset=='NWPU':
json_dict=NWPU_Dataset(image_path,annotation_path,0)
if dataset=='DIOR':
json_dict=DIOR_Dataset(image_path,annotation_path,11725)
if dataset=='YOLO':
json_dict=YOLO_Dataset(image_path,annotation_path,0)
save_json(json_dict,save)
2. 影像及标签裁剪
(1).NWPU VHR
将NWPU VHR数据集影像及其标签裁剪为指定大小
import cv2
import os
# 图像宽不足裁剪宽度,填充至裁剪宽度
def fill_right(img, size_w):
size = img.shape
# 填充值为数据集均值
img_fill_right = cv2.copyMakeBorder(img, 0, 0, 0, size_w - size[1],
cv2.BORDER_CONSTANT, value=(107, 113, 115))
return img_fill_right
# 图像高不足裁剪高度,填充至裁剪高度
def fill_bottom(img, size_h):
size = img.shape
img_fill_bottom = cv2.copyMakeBorder(img, 0, size_h - size[0], 0, 0,
cv2.BORDER_CONSTANT, value=(107, 113, 115))
return img_fill_bottom
# 图像宽高不足裁剪宽高度,填充至裁剪宽高度
def fill_right_bottom(img, size_w, size_h):
size = img.shape
img_fill_right_bottom = cv2.copyMakeBorder(img, 0, size_h - size[0], 0, size_w - size[1],
cv2.BORDER_CONSTANT, value=(107, 113, 115))
return img_fill_right_bottom
# 图像切割
# img_floder 图像文件夹
# out_img_floder 图像切割输出文件夹
# size_w 切割图像宽
# size_h 切割图像高
# step 切割步长
def image_split(img_floder, out_img_floder, size_w, size_h, step):
print("进行图像的裁剪--------------------------------")
img_list = os.listdir(img_floder)
count = 0
for img_name in img_list:
number = 0
# 去除.png后缀
name = img_name[:-4]
img = cv2.imread(img_floder + "" + img_name)
size = img.shape
# 若图像宽高大于切割宽高
if size[0] >= size_h and size[1] >= size_w:
count = count + 1
for h in range(0, size[0] - 1, step):
start_h = h
for w in range(0, size[1] - 1, step):
start_w = w
end_h = start_h + size_h
if end_h > size[0]:
start_h = size[0] - size_h
end_h = start_h + size_h
end_w = start_w + size_w
if end_w > size[1]:
start_w = size[1] - size_w
end_w = start_w + size_w
cropped = img[start_h: end_h, start_w: end_w]
# 用起始坐标来命名切割得到的图像,为的是方便后续标签数据抓取
name_img = name + '_' + str(start_h) + '_' + str(start_w)
cv2.imwrite('{}/{}.jpg'.format(out_img_floder, name_img), cropped)
number = number + 1
# 若图像高大于切割高,但宽小于切割宽
elif size[0] >= size_h and size[1] < size_w:
print('图片{}需要在右面补齐'.format(name))
count = count + 1
img0 = fill_right(img, size_w)
for h in range(0, size[0] - 1, step):
start_h = h
start_w = 0
end_h = start_h + size_h
if end_h > size[0]:
start_h = size[0] - size_h
end_h = start_h + size_h
end_w = start_w + size_w
cropped = img0[start_h: end_h, start_w: end_w]
name_img = name + '_' + str(start_h) + '_' + str(start_w)
cv2.imwrite('{}/{}.jpg'.format(out_img_floder, name_img), cropped)
number = number + 1
# 若图像宽大于切割宽,但高小于切割高
elif size[0] < size_h and size[1] >= size_w:
count = count + 1
print('图片{}需要在下面补齐'.format(name))
img0 = fill_bottom(img, size_h)
for w in range(0, size[1] - 1, step):
start_h = 0
start_w = w
end_w = start_w + size_w
if end_w > size[1]:
start_w = size[1] - size_w
end_w = start_w + size_w
end_h = start_h + size_h
cropped = img0[start_h: end_h, start_w: end_w]
name_img = name + '_' + str(start_h) + '_' + str(start_w)
cv2.imwrite('{}/{}.jpg'.format(out_img_floder, name_img), cropped)
number = number + 1
# 若图像宽高小于切割宽高
elif size[0] < size_h and size[1] < size_w:
count = count + 1
print('图片{}需要在下面和右面补齐'.format(name))
img0 = fill_right_bottom(img, size_w, size_h)
cropped = img0[0: size_h, 0: size_w]
name_img = name + '_' + '0' + '_' + '0'
cv2.imwrite('{}/{}.jpg'.format(out_img_floder, name_img), cropped)
number = number + 1
print('{}.jpg切割成{}张.'.format(name, number))
print('共完成{}张图片'.format(count))
# txt切割
# out_img_floder 图像切割输出文件夹
# txt_floder txt文件夹
# out_txt_floder txt切割输出文件夹
# size_w 切割图像宽
# size_h 切割图像高
def txt_split(out_img_floder, txt_floder, out_txt_floder, size_h, size_w):
print("进行标签文件的裁剪----------------------------")
img_list = os.listdir(out_img_floder)
for img_name in img_list:
# 去除.png后缀
name = img_name[:-4]
# 得到原图像(也即txt)索引 + 切割高 + 切割宽
name_list = name.split('_')
txt_name = name_list[0]
h = int(name_list[1])
w = int(name_list[2])
txtpath = txt_floder + "" + txt_name + '.txt'
out_txt_path = out_txt_floder + "" + name + '.txt'
f = open(out_txt_path, 'a')
# 打开txt文件
with open(txtpath, 'r') as f_in:
lines = f_in.readlines()
# 逐行读取
for line in lines:
splitline = line.split(',')
# print("---",splitline[0].split('(')[1])
# print("---", splitline[1].split(')')[0])
# print("---", splitline[2].split('(')[1])
# print("---", splitline[3].split(')')[0])
label = splitline[4]
x1 = int(splitline[0].split('(')[1])
y1 = int(splitline[1].split(')')[0])
x2 = int(splitline[2].split('(')[1])
y2 = int(splitline[3].split(')')[0])
if w <= x1 <= w + size_w and w <= x2 <= w + size_w and h <= y1 <= h + size_h and h <= y2 <= h + size_h:
f.write('({},{}),({},{}),{}'.format(int(x1 - w),
int(y1 - h), int(x2 - w), int(y2 - h),
label))
print('{}.txt切割完成.'.format(name))
f.close()
# 图像数据集文件夹
img_floder = r'G:/NWPU VHR-10 dataset/img/'
# 切割得到的图像数据集存放文件夹
out_img_floder = r'G:/NWPU VHR-10 dataset/cut/img/'
# txt数据集文件夹
txt_floder = r'G:/NWPU VHR-10 dataset/ground truth/'
# 切割后数据集的标签文件存放文件夹
out_txt_floder = r'G:/NWPU VHR-10 dataset/cut/label/'
# 切割图像宽
size_w = 500
# 切割图像高
size_h = 500
# 切割步长,重叠度为size_w - step
step = 400
image_split(img_floder, out_img_floder, size_w, size_h, step)
txt_split(out_img_floder, txt_floder, out_txt_floder, size_h, size_w)
(2).DOTA
DOTA影像裁剪的代码是一样的,标签裁剪的代码为:
# -*- coding: utf-8 -*-
'''
对裁剪后的影像中的标签实现自动抓取
'''
import cv2
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
def tqtxt(path,path_txt,path_out,size_h,size_w):
ims_list=os.listdir(path)
for im_list in ims_list:
name_list = []
name = im_list[:-4]
name_list = name.split('_')
if len(name_list)<2:
continue
h = int(name_list[1])
w = int(name_list[2])
txtpath = path_txt + name_list[0] + '.txt'
txt_outpath = path_out + name + '.txt'
f = open(txt_outpath,'a')
with open(txtpath, 'r') as f_in: #打开txt文件
i = 0
lines = f_in.readlines()
for line in lines:
if i in [0,1]:
f.write(line) #txt前两行直接复制过去
i = i+1
continue
splitline = line.split(' ')
label = splitline[8]
kunnan = splitline[9]
x1 = int(float(splitline[0]))
y1 = int(float(splitline[1]))
x2 = int(float(splitline[2]))
y2 = int(float(splitline[3]))
x3 = int(float(splitline[4]))
y3 = int(float(splitline[5]))
x4 = int(float(splitline[6]))
y4 = int(float(splitline[7]))
if w<=x1<=w+size_w and w<=x2<=w+size_w and w<=x3<=w+size_w and w<=x4<=w+size_w and h<=y1<=h+size_h and h<=y2<=h+size_h and h<=y3<=h+size_h and h<=y4<=h+size_h:
f.write('{} {} {} {} {} {} {} {} {} {}'.format(float(x1-w),float(y1-h),float(x2-w),float(y2-h),float(x3-w),float(y3-h),float(x4-w),float(y4-h),label,kunnan))
f.close()
if __name__ == '__main__':
ims_path='/home/DOTA/img/'# 图像数据集的路径
txt_path = '/home/DOTA/labeltxt/'#原数据集标签文件
path = '/home/DOTA/selected_txt/'#切割后数据集的标签文件存放路径
tqtxt(ims_path,txt_path,path,size_h=500,size_w=500)
3. 影像拼接
几张图拼接为一张图的代码
newgroup_selected.txt中为随机选择分好组的影像名称,每一行为一组,格式如下,拼接按照这个txt文件中的分组进行
[‘030’, ‘428’, ‘528’, ‘037’]
import os
from PIL import Image
IMAGES_PATH=r'G:/NWPU VHR-10 dataset/cut/img/'
IMAGES_FORMAT = ['.jpg', '.tif'] # 图片格式
IMAGE_SIZE = 500 # 每张小图片的大小
IMAGE_ROW = 2 # 图片间隔,也就是合并成一张图后,一共有几行
IMAGE_COLUMN = 2 # 图片间隔,也就是合并成一张图后,一共有几列
# 图片转换后的地址
txt_path=r'G:/NWPU VHR-10 dataset/newgroup_selected.txt' #生成的txt文档
open_txt=open(txt_path) #打开txt文档
for ii in range(651, 701): #拼接多少张影像,新的影像名为序号.jpg
IMAGE_SAVE_PATH = r'G:/NWPU VHR-10 dataset/cut/stitcherImg/{}.jpg'.format(ii)
aa=[]
line=open_txt.readline()
a=line.split("'")
b,c,d,e=a[1],a[3],a[5],a[7]
aa.append(b)
aa.append(c)
aa.append(d)
aa.append(e)
to_image = Image.new('RGB', (IMAGE_COLUMN * IMAGE_SIZE, IMAGE_ROW * IMAGE_SIZE)) #创建一个新图
for y in range(1, IMAGE_ROW + 1):
for x in range(1, IMAGE_COLUMN + 1):
from_image = Image.open(IMAGES_PATH + aa[IMAGE_COLUMN * (y - 1) + x - 1]+'.jpg').resize(
(IMAGE_SIZE, IMAGE_SIZE),Image.ANTIALIAS)
to_image.paste(from_image, ((x - 1) * IMAGE_SIZE, (y - 1) * IMAGE_SIZE))
to_image.save(IMAGE_SAVE_PATH) # 保存新图
xml拼接
# 生成拼接图像的xml文件
import os
import xml.etree.ElementTree as ET
def indent(elem, level=0):
i = "\n" + level * " "
if len(elem):
if not elem.text or not elem.text.strip():
elem.text = i + " "
if not elem.tail or not elem.tail.strip():
elem.tail = i
for elem in elem:
indent(elem, level + 1)
if not elem.tail or not elem.tail.strip():
elem.tail = i
else:
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
src_path = r'/home/DOTA/xml/'
txt_path = r'/home/DOTA/newgroup_selected.txt'
open_txt = open(txt_path)
# read_txt=open_txt.readline()
for ii in range(3000, 3120):
print("处理标签{}".format(ii))
num = 0
aa = []
line = open_txt.readline() # 一组拼接图像的xml文件进行合成
# print(line)
annotation = ET.Element("annotation")
filename = ET.SubElement(annotation, "filename")
filename.text = "P{}.png".format(ii)
source = ET.SubElement(annotation, "source")
databse = ET.SubElement(source, "databse")
databse.text = "DOTA"
size = ET.SubElement(annotation, "size") # SubElement 子节点
width = ET.SubElement(size, "width") # SubElement 子节点
width.text = "2000"
height = ET.SubElement(size, "height") # SubElement 子节点
height.text = "2000"
depth = ET.SubElement(size, "depth") # SubElement 子节点
depth.text = "3"
segmented = ET.SubElement(annotation, "segmented") # SubElement 子节点
segmented.text = "0"
a = line.split("'")
b, c, d, e = a[1], a[3], a[5], a[7]
aa.append(b)
aa.append(c)
aa.append(d)
aa.append(e)
for i in aa:
if num == 0:
target_dom = ET.parse(os.path.join(src_path, i) + ".xml")
target_root = target_dom.getroot() # 数据内存地址
for i in target_root.iter('object'):
object = ET.SubElement(annotation, "object")
for j in i:
if j.tag == 'name':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'pose':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'bndbox':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
for m in j:
if m.tag == 'xmin':
m_tag = ET.SubElement(j_tag, m.tag) # SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'ymin':
m_tag = ET.SubElement(j_tag, m.tag) # SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'xmax':
m_tag = ET.SubElement(j_tag, m.tag) # SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'ymax':
m_tag = ET.SubElement(j_tag, m.tag) # SubElement 子节点
m_tag.text = str(int(m.text) // 2)
num += 1
elif num == 1:
target_dom = ET.parse(os.path.join(src_path, i) + ".xml")
target_root = target_dom.getroot() # 数据内存地址
for i in target_root.iter('object'):
object = ET.SubElement(annotation, "object")
for j in i:
if j.tag == 'name':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'pose':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'bndbox':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
for m in j:
if m.tag == 'xmin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str((int(m.text) // 2) + 1000)
if m.tag == 'ymin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'xmax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str((int(m.text) // 2) + 1000)
if m.tag == 'ymax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2)
num += 1
elif num == 2:
target_dom = ET.parse(os.path.join(src_path, i) + ".xml")
target_root = target_dom.getroot() # 数据内存地址
for i in target_root.iter('object'):
object = ET.SubElement(annotation, "object")
for j in i:
if j.tag == 'name':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'pose':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'bndbox':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
for m in j:
if m.tag == 'xmin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'ymin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
if m.tag == 'xmax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2)
if m.tag == 'ymax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
num += 1
elif num == 3:
target_dom = ET.parse(os.path.join(src_path, i) + ".xml")
target_root = target_dom.getroot() # 数据内存地址
for i in target_root.iter('object'):
object = ET.SubElement(annotation, "object")
for j in i:
if j.tag == 'name':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'pose':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
j_tag.text = j.text
if j.tag == 'bndbox':
j_tag = ET.SubElement(object, j.tag) # SubElement 子节点
for m in j:
if m.tag == 'xmin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
if m.tag == 'ymin':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
if m.tag == 'xmax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
if m.tag == 'ymax':
m_tag = ET.SubElement(j_tag, m.tag) # 构建SubElement 子节点
m_tag.text = str(int(m.text) // 2 + 1000)
indent(annotation)
et = ET.ElementTree(annotation)
et.write(r"/home/DOTA/cut/selected_stitched_xml/P{}.xml".format(ii), encoding="utf-8",
xml_declaration=True)