深度学习——物体识别和数据集(笔记)
1.图片分类与目标检测的区别:
图片分类:把图片中的主体找出来
目标检测:识别图片中所有感兴趣的物体,并且把每个物体的位置找出来。
2.目标检测的应用
无人驾驶,无人售货
3.边缘框:表示物体的位置

一个边缘框可以由4个数字定义(x右为正,y下为正)
①左上x,左上y
右下x,右下y
②左上x,左上y
宽,高
4.目标检测数据集
①数据集用文本存储:
每行表示一个物体,由图片文件名(可重复,因为一个图片多个物体),物体类别(标号),边缘框(位置)组成。1+1+4
②COCO数据集:80物体,330K图片,1.5M物体

【总结】
①物体检测识别图片里的多个物体的类别和位置
②位置通常使用边缘框表示
【代码 实现边缘框】
1.加载图片
import torch
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')2.边界框 两种转换函数
①从左上右下转换到 中间,宽度,高度
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes②从中间转换到左上,右下
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes3.x轴为右是正,y轴向下是正
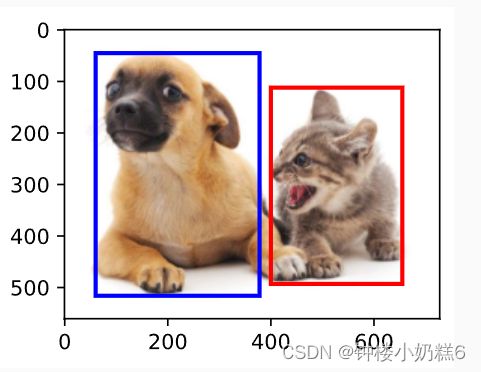
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]4.bbox_to_rect函数将边界框表示成matplotlib的边界框格式
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)5.物体在两个框内
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))