MongoDB入门与实战-第六章-MongoDB分片
目录
- 参考
- 一、MongoDB 分片概念
-
- 1、为什么使用分片
- 2、垂直扩容(Scale Up) VS 水平扩容(Scale Out):
- 3、不分片的客户端连接
- 4、分片的客户端连接
- 二、分片三种角色
- 三、分片集群架构图
- 四、如何确定shard,mongos的数量
- 五、如何选择片键(Shard Key)?
-
- MongoDB分片集群支持的分片策略
-
- Hashed Sharding
- Ranged Sharding
- 六、关于jumbo chunk及chunk size
-
- 范围分片和哈希分片无法解决的问题
- 好的Shard Key拥有的特性
- 七、分片示例
-
- 场景一:
-
- (推荐)方案一:组合设备ID和时间戳作为Shard Key,进行范围分片。
- 方案二: 时间戳作为Shard Key,进行范围分片。
- 方案三: 时间戳作为Shard Key,进行哈希分片。
- 方案四:设备ID作为Shard Key,进行哈希分片。
- 场景二:
-
- 插入5w条数据
- 启动分片
- 针对info集合创建索引
- 使用sh.shardCollection("school.info",{"id":1})命令对集合info进行分片
- 查看分片信息
- sh.addShardTag()添加标签
、
参考
mongodb分片
猿创征文|MongoDB数据库 分片集群搭建部署实战
MongoDB 分片集群介绍
一、MongoDB 分片概念
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据也足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
应用程序不必知道哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,进程名mongos,这个路由器知道所有数据的存放位置,所以应用可以连接它来正常发送请求.对应用来说,它仅知道连接了一个普通的mongod。路由器知道和片的对应关系,能够转发请求到正确的片上.如果请求有了回应,路由器将其收集起来回送给应用.
1、为什么使用分片
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
2、垂直扩容(Scale Up) VS 水平扩容(Scale Out):
-
垂直扩容 : 用更好的服务器,提高 CPU 处理核数、内存数、带宽等
-
水平扩容 : 将任务分配到多台计算机上
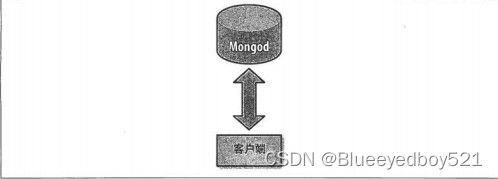
3、不分片的客户端连接
4、分片的客户端连接
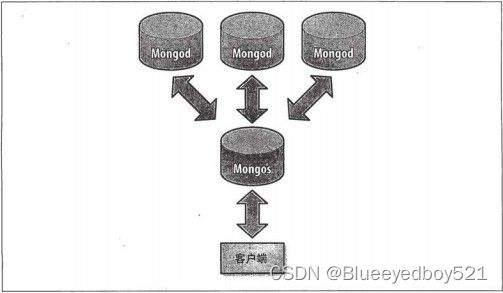
二、分片三种角色
mongodb分片有三种角色:
-
mongos:是整个分片架构的核心。数据库集群的入口,所有的请求都通过mongos进行协调,通常有多个mongos作为请求的入口,保证高可用。对客户端而言 不知道是否有分片,只需要把数据交给mongos。mongos本身没有任何数据,他也不知道该怎么处理这数据,去找config server。
-
config server:配置服务器,存储集群所有节点、分片数据路的信息。默认需要配置3个Config Server节点,保证高可用。mongos本身并没有物理存储分片服务器和数据路由信息,只是缓存再内存里。第一次启动或者重启就会从config server加载配置信息。
-
shard:真正的数据存储位置,可以看成是一个个副本集。
大致的工作流程:客户端提交数据,传给mongos进程,mongos查看配置服务器config server,知道了它包含的shard有哪些,由此把数据均衡分配给各个shard。
三、分片集群架构图
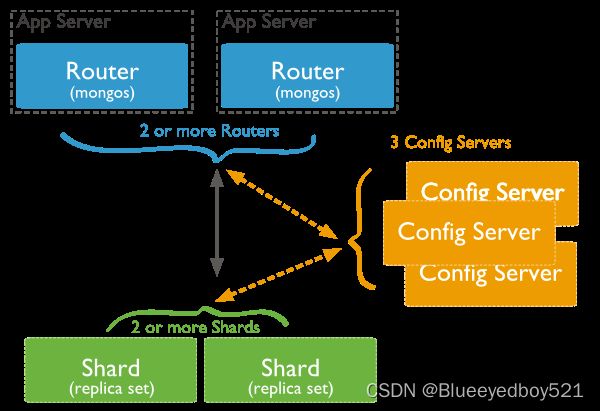
MongoDB 分片集群(Sharded Cluster)是对数据进行水平扩展的一种方式。MongoDB 使用 分片集群来支持大数据集和高吞吐量的业务场景。在分片模式下,存储不同的切片数据的节点被称为分片节点,一个分片集群内包含了多个分片节点。当然,除了分片节点,集群中还需要一些配置节点、路由节点,以保证分片机制的正常运作。
四、如何确定shard,mongos的数量
您可以根据以下方法确定shard和mongos的使用数量:
- 分片集群仅用于解决海量数据的存储问题,且访问量不多。例如一个shard能存储M, 需要的存储总量是N,那么您的业务需要的shard和mongos数量按照以下公式计算:
- numberOfShards = N/M/0.75 (假设容量水位线为75%)
- numberOfMongos = 2+(对访问要求不高,至少部署2个mongos做高可用)
- 分片集群用于解决高并发写入(或读取)数据的问题,但总的数据量很小。即shard和mongos需要满足读写性能需求,例如一个shard的最大QPS为M,一个mongos的最大QPS为Ms,业务需要的总QPS为Q,那么您的业务需要的shard和mongos数量按照以下公式计算:
- numberOfShards = Q/M/0.75 (假设负载水位线为75%)
- numberOfMongos = Q/Ms/0.75
说明
如果分片集群同时解决上述两个问题,则按照需求更高的指标进行预估。
上述计算方法是基于分片集群中数据和请求都均为分布的理想情况下进行预估,实际情况下,分布可能并不均匀,为了让系统的负载尽量均匀,您需要选择合理的Shard
Key。 mongos和mongod的服务能力,需要用户根据访问特性来实测得出。
五、如何选择片键(Shard Key)?
MongoDB分片集群支持的分片策略
范围分片,支持基于Shard Key的范围查询。
哈希分片,能够将写入均衡分布到各个shard。
Tag aware sharding,您可以自定义一些chunk的分布规则。
说明
- 原理 sh.addShardTag()给shard设置标签A。
sh.addTagRange()给集合的某个chunk范围设置标签A,最终MongoDB会保证设置标签A的chunk范围(或该范围的超集)分布设置了标签A的shard上。- 应用场景
将部署在不同机房的shard设置机房标签,将不同chunk范围的数据分布到指定的机房。
将服务能力不同的shard设置服务等级标签,将更多的chunk分散到服务能力更强的shard上去。- 注意事项
chunk分配到对应标签的shard上无法立即完成,而是在不断insert、update后触发split、moveChunk后逐步完成的并且需要保证balancer是开启的。在设置了tag
range一段时间后,写入仍然没有分布到tag相同的shard上去。
Hashed Sharding
散列分片涉及计算分片键字段值的hash散列。 然后根据散列的分片键值为每个块分配一个范围。
基于散列值的数据分布有利于更均匀的数据分布,尤其是在分片键单调变化的数据集中。然而,散列分布意味着对分片键的基于范围的查询不太可能针对单个分片,从而导致更多的集群范围的广播操作
优势:由于hash键可以分布多个chunk,所以会极大提高写入性能
劣势:不方便范围查询
Ranged Sharding
范围分片涉及根据分片键值将数据划分为范围。 然后根据分片键值为每个块分配一个范围。
值“接近”的一系列分片键更有可能驻留在同一块上。 这允许有针对性的操作,因为 mongos 可以将操作路由到仅包含所需数据的分片。
优势:方便范围查询;若果分片键不是单调递增,也可以提升写入性能
劣势:如果分片键是单调递增,则无法提升写入性能
六、关于jumbo chunk及chunk size
MongoDB默认的chunk size为64 MB,如果chunk超过64 MB且不能分裂(假如所有文档的Shard Key都相同),则会被标记为jumbo chunk,balancer不会迁移这样的chunk,从而可能导致负载不均衡,应尽量避免。
当出现jumbo chunk时,如果对负载均衡要求不高,并不会影响到数据的读写访问。如果您需要处理,可以使用如下方法:
-
对jumbo chunk进行split,split成功后mongos会自动清除jumbo标记。
-
对于不可再分的chunk,如果该chunk已不是jumbo chunk,可以尝试手动清除chunk的jumbo标记。
说明 清除前,您需要先备份config数据库,避免误操作导致config库损坏。
-
调大chunk size,当chunk大小不超过chunk size时,jumbo标记最终会被清理。但是随着数据的写入仍然会再出现jumbo chunk,根本的解决办法还是合理的规划Shard Key。
需要调整chunk size(取值范围为1~1024 MB)的场景:
- 迁移时I/O负载太大,可以尝试设置更小的chunk size。
- 测试时,为了方便验证效果,设置较小的chunk size。
- 初始chunk size设置不合理,导致出现大量jumbo chunk影响负载均衡,此时可以尝试调大chunk size。
- 将未分片的集合转换为分片集合,如果集合容量太大,需要(数据量达到T级别才有可能遇到)调大chunk size才能转换成功。具体方法请参见Sharding Existing Collection Data Size。
范围分片和哈希分片无法解决的问题
- Shard Key的取值范围太小,例如将数据中心作为Shard Key,由于数据中心通常不多,则分片效果不好。
- Shard Key中某个值的文档特别多,会导致单个chunk特别大(即 jumbo chunk),会影响chunk迁移及负载均衡。
- 根据非Shard Key进行查询、更新操作都会变成scatter-gather查询,影响效率。
好的Shard Key拥有的特性
- key分布足够离散(sufficient cardinality)
- 写请求均匀分布(evenly distributed write)
- 尽量避免scatter-gather查询(targeted read)
七、分片示例
场景一:
某物联网应用使用MongoDB分片集群存储海量设备的工作日志。如果设备数量在百万级别,设备每10秒向MongoDB汇报一次日志数据,日志包含设备ID(deviceId)和时间戳(timestamp)信息。应用最常见的查询请求是查询某个设备某个时间内的日志信息。查询请求:查询某个设备某个时间内的日志信息。
(推荐)方案一:组合设备ID和时间戳作为Shard Key,进行范围分片。
写入能均分到多个shard。
同一个设备ID的数据能根据时间戳进一步分散到多个chunk。
根据设备ID查询时间范围的数据,能直接利用(deviceId,时间戳)复合索引来完成。
方案二: 时间戳作为Shard Key,进行范围分片。
新的写入为连续的时间戳,都会请求到同一个分片,写分布不均。
根据设备ID的查询会分散到所有shard上查询,效率低。
方案三: 时间戳作为Shard Key,进行哈希分片。
写入能均分到多个shard上。
根据设备ID的查询会分散到所有shard上查询,效率低。
方案四:设备ID作为Shard Key,进行哈希分片。
说明 如果设备ID没有明显的规则,可以进行范围分片。
写入能均分到多个shard上。
同一个设备ID对应的数据无法进一步细分,只能分散到同一个chunk,会造成jumbo chunk,根据设备ID的查询只请求到单个shard,请求路由到单个shard后,根据时间戳的范围查询需要全表扫描并排序。
场景二:
插入5w条数据
mongos> use school #进入并创建数据库school
switched to db school
mongos> for (var i=1;i<=5000000;i++)db.info.insert({"id":i,"name":"tom"+i}) #创建集合info,并使用循环插入50000条数据
WriteResult({ "nInserted" : 1 }) #此时50000条数据都在primary(47017)服务器上
启动分片
使用sh.enableSharding(“school”)命令启动school数据库分片
mongos> sh.enableSharding("school")
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1635298856, 6),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1635298856, 6)
}
针对info集合创建索引
mongos> db.info.createIndex({"id":1})
{
"raw" : {
"192.168.30.55:47017" : {
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
},
"ok" : 1
}
使用sh.shardCollection(“school.info”,{“id”:1})命令对集合info进行分片
mongos> sh.shardCollection("school.info",{"id":1})
{
"collectionsharded" : "school.info",
"collectionUUID" : UUID("64af5a8d-ae31-4916-b0fc-2859ebb0a65d"),
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1635301130, 10),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1635301130, 10)
}
查看分片信息
mongos > sh . status ()
--- Sharding Status ---
sharding version : {
"_id" : 1 ,
"minCompatibleVersion" : 5 ,
"currentVersion" : 6 ,
"clusterId" : ObjectId ( "62cf9dfd0915271ec0959b9b" )
}
shards :
{ "_id" : "shard0000" , "host" : "192.168.11.74:47017" , "state" : 1 }
{ "_id" : "shard0001" , "host" : "192.168.11.74:47018" , "state" : 1 }
active mongoses :
"3.6.3" : 1
autosplit :
Currently enabled : yes
balancer :
Currently enabled : yes
Currently running : no
Failed balancer rounds in last 5 attempts : 0
Migration Results for the last 24 hours :
8 : Success
databases :
{ "_id" : "config" , "primary" : "config" , "partitioned" : true }
config .system .sessions
shard key : { "_id" : 1 }
unique : false
balancing : true
chunks :
shard0000 1
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : { "$maxKey" : 1 } } on : shard0000 Timestamp ( 1 , 0 )
{ "_id" : "school" , "primary" : "shard0000" , "partitioned" : true } # 数据库 school 的分片信息
school .info
shard key : { "id" : 1 } # 分片键
unique : false
balancing : true
chunks : # 可以看到 chunks 均匀分布到两个分片上
shard0000 9 # 9+8=17
shard0001 8
{ "id" : { "$minKey" : 1 } } -->> { "id" : 299594 } on : shard0001 Timestamp ( 2 , 0 )
{ "id" : 299594 } -->> { "id" : 599188 } on : shard0001 Timestamp ( 3 , 0 )
{ "id" : 599188 } -->> { "id" : 898782 } on : shard0001 Timestamp ( 4 , 0 )
{ "id" : 898782 } -->> { "id" : 1198376 } on : shard0001 Timestamp ( 5 , 0 )
{ "id" : 1198376 } -->> { "id" : 1497970 } on : shard0001 Timestamp ( 6 , 0 )
{ "id" : 1497970 } -->> { "id" : 1797564 } on : shard0001 Timestamp ( 7 , 0 )
{ "id" : 1797564 } -->> { "id" : 2097158 } on : shard0001 Timestamp ( 8 , 0 )
{ "id" : 2097158 } -->> { "id" : 2396752 } on : shard0001 Timestamp ( 9 , 0 )
{ "id" : 2396752 } -->> { "id" : 2696346 } on : shard0000 Timestamp ( 9 , 1 )
{ "id" : 2696346 } -->> { "id" : 2995940 } on : shard0000 Timestamp ( 1 , 9 )
{ "id" : 2995940 } -->> { "id" : 3295534 } on : shard0000 Timestamp ( 1 , 10 )
{ "id" : 3295534 } -->> { "id" : 3595128 } on : shard0000 Timestamp ( 1 , 11 )
{ "id" : 3595128 } -->> { "id" : 3894722 } on : shard0000 Timestamp ( 1 , 12 )
{ "id" : 3894722 } -->> { "id" : 4194316 } on : shard0000 Timestamp ( 1 , 13 )
{ "id" : 4194316 } -->> { "id" : 4493910 } on : shard0000 Timestamp ( 1 , 14 )
{ "id" : 4493910 } -->> { "id" : 4793504 } on : shard0000 Timestamp ( 1 , 15 )
{ "id" : 4793504 } -->> { "id" : { "$maxKey" : 1 } } on : shard0000 Timestamp ( 1 , 16 )
sh.addShardTag()添加标签
mongos> sh.addShardTag("shard0000","abc01")
mongos> sh.addShardTag("shard0001","abc02")
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("62cf9dfd0915271ec0959b9b ")
}
shards:
{ "_id" : "shard0000", "host" : "192.168.30.55:47017", "tags" : [ "abc01" ] }
{ "_id" : "shard0001", "host" : "192.168.30.55:47018", "tags" : [ "abc02" ] }