scrapy中start_time或者finish_time中时区问题处理
当我们运行一个scrapy爬虫时,最终统计结果中的“start_time”和“finish_time”时间的时区和日志中其他时间的时区是不同的,如下图:
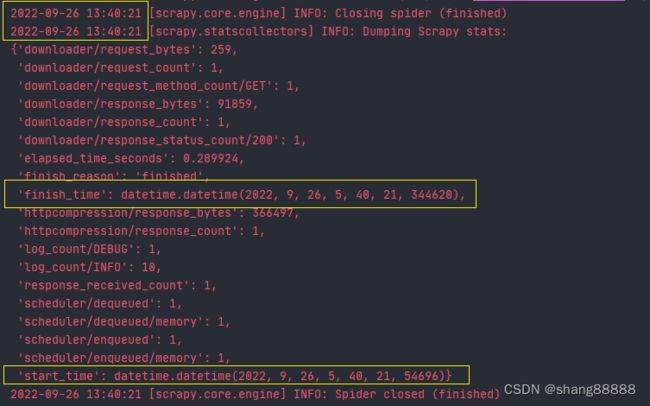
显然,“start_time”和“finish_time”使用的是utc时间,而其他的log日志使用的是本机时间或者说是本地时间,即东八区时间。
那如何处理这个问题呢?首先看下出现这个问题的原因,根据scrapy中扩展(extensions)文件源码中的“CoreStats”类(scrapy.extensions.corestats.CoreStats)可知:
"""
Extension for collecting core stats like items scraped and start/finish times
"""
from datetime import datetime
from scrapy import signals
class CoreStats:
def __init__(self, stats):
self.stats = stats
self.start_time = None
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.stats)
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(o.spider_closed, signal=signals.spider_closed)
crawler.signals.connect(o.item_scraped, signal=signals.item_scraped)
crawler.signals.connect(o.item_dropped, signal=signals.item_dropped)
crawler.signals.connect(o.response_received, signal=signals.response_received)
return o
def spider_opened(self, spider):
self.start_time = datetime.utcnow()
self.stats.set_value('start_time', self.start_time, spider=spider)
def spider_closed(self, spider, reason):
finish_time = datetime.utcnow()
elapsed_time = finish_time - self.start_time
elapsed_time_seconds = elapsed_time.total_seconds()
self.stats.set_value('elapsed_time_seconds', elapsed_time_seconds, spider=spider)
self.stats.set_value('finish_time', finish_time, spider=spider)
self.stats.set_value('finish_reason', reason, spider=spider)
def item_scraped(self, item, spider):
self.stats.inc_value('item_scraped_count', spider=spider)
def response_received(self, spider):
self.stats.inc_value('response_received_count', spider=spider)
def item_dropped(self, item, spider, exception):
reason = exception.__class__.__name__
self.stats.inc_value('item_dropped_count', spider=spider)
self.stats.inc_value(f'item_dropped_reasons_count/{reason}', spider=spider)
第26行的“self.start_time = datetime.utcnow()”和第30行的“finish_time = datetime.utcnow()”就是出现以上问题的原因,这两处的时间均用的是utc时间。
既然知道了原因,那我们就看解决方法吧,解决方法的思路就是禁用“CoreStats”扩展类,同时自己添加新的扩展类并启用。下面就是具体的解决方法。
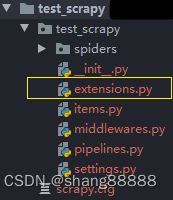
1. 首先在scrapy项目路径下新建一个“extensions.py”文件,和“pipelines.py”文件在相同文件夹下,如下图:
2. 在“extensions.py”文件中添加以下代码,其中“TestCoreStats”类继承于“CoreStats”类,然后我们重写(覆盖)了父类的“spider_opened”和“spider_closed”方法,然后修改了里面的时间。因为此处的使用了很多个时间变量,请根据自己的情况删除无用时间的变量或者更改输出名。
from scrapy.extensions.corestats import CoreStats
from datetime import datetime, timedelta
import pytz
class TestCoreStats(CoreStats):
"""
此扩展类的作用是修改日期为本地时区日期,特别注意,这些时间均依赖于当前系统时间,即需要当前系统时间准确。
日志中显示的时间也是依赖于当前系统时间。
"""
def spider_opened(self, spider):
self.start_time = datetime.utcnow() # utc时间
self.start_time_now = datetime.now() # 当前系统时间
self.start_time_zone = datetime.now(tz=pytz.timezone('Asia/Shanghai')) # 选择指定时区时间
self.start_time_delta = self.start_time + timedelta(hours=8) # 根据时区对utc对时间计算,比如北京时间是东八区,即为utc时间加8小时
self.stats.set_value('start_time', self.start_time, spider=spider)
self.stats.set_value('start_time_now', self.start_time_now, spider=spider)
self.stats.set_value('start_time_zone', self.start_time_zone, spider=spider)
self.stats.set_value('start_time_delta', self.start_time_delta, spider=spider)
def spider_closed(self, spider, reason):
finish_time = datetime.utcnow() # utc时间
finish_time_now = datetime.now() # 当前系统时间
finish_time_zone = datetime.now(tz=pytz.timezone('Asia/Shanghai')) # 选择指定时区时间
finish_time_delta = finish_time + timedelta(hours=8) # 根据时区对utc对时间计算,比如北京时间是东八区,即为utc时间加8小时
elapsed_time = finish_time - self.start_time
elapsed_time_seconds = elapsed_time.total_seconds()
self.stats.set_value('elapsed_time_seconds', elapsed_time_seconds, spider=spider)
self.stats.set_value('finish_time', finish_time, spider=spider)
self.stats.set_value('finish_time_now', finish_time_now, spider=spider)
self.stats.set_value('finish_time_zone', finish_time_zone, spider=spider)
self.stats.set_value('finish_time_delta', finish_time_delta, spider=spider)
self.stats.set_value('finish_reason', reason, spider=spider)
3. 在“settings.py”文件里启用“TestCoreStats”扩展类,并禁用“CoreStats”扩展类,如下:
EXTENSIONS = {
'scrapy.extensions.corestats.CoreStats': None,
'test_scrapy.extensions.TestCoreStats': 0
}
最终,我们来看看效果。
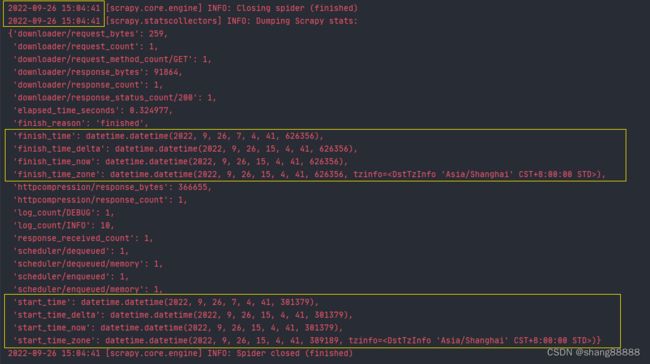
此时就可以看到,我们新增的几个时间“_delta” 、“_now”、“_zone”的时间都是和图上日志时间是相同时区的了,所以根据具体情况将“start_time”和“finish_time”变量的值进行更改吧。