mmdetection训练自己的模型【数据集转变,数据集划分,数据集gt可视化,mmdetection配置文件生成及修改,开始训练,gradio部署】
同步更新,观看体验更佳:【https://www.cnblogs.com/gy77/p/15721305.html】
针对有一点mmdetction基础的,然后想根据自己的数据集,熟练训练自己的模型。需要改成自己配置的地方,我会在代码中做好标记,方便修改。
我们先了解一下mmdetection的基本流程,你想训练一个模型,你只需要准备的是:数据集,mmdetection的配置文件。
下面我分为两部分,分别处理这两个东西。然后你就可以用官方实现的训练工具愉快的进行训练了。
1. 数据集的处理
先把数据集复制到mmdetection的data目录下,方便管理,data目录下一个文件夹就是一个数据集。dataset1/data/目录下是你的.xml文件和.jpg文件,如果你的数据集本身就是voc数据集,那可以跳过步骤1.1。
- xml2voc2007.py:用于将.xml文件转换成voc2007数据集。
- voc2coco.py:用于将voc数据集转换成coco数据集。
- box_visiual.py:利用coco数据集可视化数据集的ground truth。查看数据集中是否有脏数据,根据具体情况除掉。
如果需要用到其他的格式转换,或者数据集处理的一些操作,参考:数据集拆分,互转,可视化,查错 - 一届书生 - 博客园 (cnblogs.com)
1.1 数据集转变: .xml --> voc数据集
首先是数据集的处理,我是比较习惯用coco数据集,虽然mmdetection也可以训练voc数据集。因为我拿到手的是一个.jpg和.xml文件的数据集,因为我们要先将.xml文件数据集转换成voc数据集,然后再将voc数据集转换成coco数据集。
mmdetection/data/dataset1/xml2voc2007.py
# 命令行执行: python xml2voc2007.py --input_dir data --output_dir VOCdevkit
import argparse
import glob
import os
import os.path as osp
import random
import shutil
import sys
percent_train = 0.9 # 改成你想设置的训练集比例。
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="data",
help="input annotated directory") # 将保存你.jpg和.xml文件的文件夹名改为data,下边就不用动了
parser.add_argument("--output_dir", default="VOCdevkit", help="output dataset directory") # 输出的voc数据集目录,不用动
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
print("| Creating dataset dir:", osp.join(args.output_dir, "VOC2007"))
# 创建保存的文件夹
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "Annotations")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "Annotations"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "JPEGImages")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "JPEGImages"))
# 获取目录下所有的.jpg文件列表
total_img = glob.glob(osp.join(args.input_dir, "*.jpg"))
print('| Image number: ', len(total_img))
# 获取目录下所有的joson文件列表
total_xml = glob.glob(osp.join(args.input_dir, "*.xml"))
print('| Xml number: ', len(total_xml))
num_total = len(total_xml)
data_list = range(num_total)
num_tr = int(num_total * percent_train)
num_train = random.sample(data_list, num_tr)
print('| Train number: ', num_tr)
print('| Val number: ', num_total - num_tr)
file_train = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "train.txt"), 'w')
file_val = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "val.txt"), 'w')
for i in data_list:
name = total_xml[i][:-4] + '\n' # 去掉后缀'.jpg'
if i in num_train:
file_train.write(name[5:]) # 因为这里的name是带着目录的,也就是name本来是:'data/1.jpg' ,去掉'data/' ,就是文件名了。
else:
file_val.write(name[5:])
file_train.close()
file_val.close()
if os.path.exists(args.input_dir):
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list, 内容是该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(args.input_dir):
for file in files:
src_file = osp.join(root, file)
if src_file.endswith(".jpg"):
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "JPEGImages"))
else:
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "Annotations"))
print('| Done!')
if __name__ == "__main__":
print("—" * 50)
main()
print("—" * 50)
1.2 数据集转变: voc数据集 --> coco数据集
写的有点繁琐了,代码比较冗长,暂时没有时间去优化一下。 但是很好用!!!
mmdetection/data/dataset1/voc2coco.py
# -*- coding: utf-8 -*-
import json
import os
import shutil
root_path = os.getcwd()
def voc2coco():
import datetime
from PIL import Image
# 处理coco数据集中category字段。
# 创建一个 {类名 : id} 的字典,并保存到 总标签data 字典中。
class_name_to_id = {'point': 1, }
# 创建coco的文件夹
if not os.path.exists(os.path.join(root_path, "coco2017")):
os.makedirs(os.path.join(root_path, "coco2017"))
os.makedirs(os.path.join(root_path, "coco2017", "annotations"))
os.makedirs(os.path.join(root_path, "coco2017", "train2017"))
os.makedirs(os.path.join(root_path, "coco2017", "val2017"))
# 创建 总标签data
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, file_name,url, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
for name, id in class_name_to_id.items():
data["categories"].append(
dict(supercategory=None, id=id, name=name, )
)
# 处理coco数据集train中images字段。
images_dir = os.path.join(root_path, 'VOCdevkit', 'VOC2007', 'JPEGImages')
images = os.listdir(images_dir)
# 生成每个图片对应的image_id
images_id = {}
for idx, image_name in enumerate(images):
images_id.update({image_name[:-4]: idx})
# 获取训练图片
train_img = []
fp = open(os.path.join(root_path, 'VOCdevkit', 'VOC2007', 'ImageSets', 'Main', 'train.txt'))
for i in fp.readlines():
train_img.append(i[:-1] + ".jpg")
# 获取训练图片的数据
for image in train_img:
img = Image.open(os.path.join(images_dir, image))
data["images"].append(
dict(
license=0,
url=None,
file_name=image, # 图片的文件名带后缀
height=img.height,
width=img.width,
date_captured=None,
# id=image[:-4],
id=images_id[image[:-4]],
)
)
# 获取coco数据集train中annotations字段。
train_xml = [i[:-4] + '.xml' for i in train_img]
bbox_id = 0
for xml in train_xml:
category = []
xmin = []
ymin = []
xmax = []
ymax = []
import xml.etree.ElementTree as ET
tree = ET.parse(os.path.join(root_path, 'VOCdevkit', 'VOC2007', 'Annotations', xml))
root = tree.getroot()
object = root.findall('object')
for i in object:
category.append(class_name_to_id[i.findall('name')[0].text])
bndbox = i.findall('bndbox')
for j in bndbox:
xmin.append(float(j.findall('xmin')[0].text))
ymin.append(float(j.findall('ymin')[0].text))
xmax.append(float(j.findall('xmax')[0].text))
ymax.append(float(j.findall('ymax')[0].text))
for i in range(len(category)):
data["annotations"].append(
dict(
id=bbox_id,
image_id=images_id[xml[:-4]],
category_id=category[i],
area=(xmax[i] - xmin[i]) * (ymax[i] - ymin[i]),
bbox=[xmin[i], ymin[i], xmax[i] - xmin[i], ymax[i] - ymin[i]],
iscrowd=0,
)
)
bbox_id += 1
# 生成训练集的json
json.dump(data, open(os.path.join(root_path, 'coco2017', 'annotations', 'instances_train2017.json'), 'w'))
# 获取验证图片
val_img = []
fp = open(os.path.join(root_path, 'VOCdevkit', 'VOC2007', 'ImageSets', 'Main', 'val.txt'))
for i in fp.readlines():
val_img.append(i[:-1] + ".jpg")
# 将训练的images和annotations清空,
del data['images']
data['images'] = []
del data['annotations']
data['annotations'] = []
# 获取验证集图片的数据
for image in val_img:
img = Image.open(os.path.join(images_dir, image))
data["images"].append(
dict(
license=0,
url=None,
file_name=image, # 图片的文件名带后缀
height=img.height,
width=img.width,
date_captured=None,
id=images_id[image[:-4]],
)
)
# 处理coco数据集验证集中annotations字段。
val_xml = [i[:-4] + '.xml' for i in val_img]
for xml in val_xml:
category = []
xmin = []
ymin = []
xmax = []
ymax = []
import xml.etree.ElementTree as ET
tree = ET.parse(os.path.join(root_path, 'VOCdevkit', 'VOC2007', 'Annotations', xml))
root = tree.getroot()
object = root.findall('object')
for i in object:
category.append(class_name_to_id[i.findall('name')[0].text])
bndbox = i.findall('bndbox')
for j in bndbox:
xmin.append(float(j.findall('xmin')[0].text))
ymin.append(float(j.findall('ymin')[0].text))
xmax.append(float(j.findall('xmax')[0].text))
ymax.append(float(j.findall('ymax')[0].text))
for i in range(len(category)):
data["annotations"].append(
dict(
id=bbox_id,
image_id=images_id[xml[:-4]],
category_id=category[i],
area=(xmax[i] - xmin[i]) * (ymax[i] - ymin[i]),
bbox=[xmin[i], ymin[i], xmax[i] - xmin[i], ymax[i] - ymin[i]],
iscrowd=0,
)
)
bbox_id += 1
# 生成验证集的json
json.dump(data, open(os.path.join(root_path, 'coco2017', 'annotations', 'instances_val2017.json'), 'w'))
print('| VOC -> COCO annotations transform finish.')
print('Start copy images...')
for img_name in train_img:
shutil.copy(os.path.join(root_path, "VOCdevkit", "VOC2007", "JPEGImages", img_name),
os.path.join(root_path, "coco2017", 'train2017', img_name))
print('| Train images copy finish.')
for img_name in val_img:
shutil.copy(os.path.join(root_path, "VOCdevkit", "VOC2007", "JPEGImages", img_name),
os.path.join(root_path, "coco2017", 'val2017', img_name))
print('| Val images copy finish.')
if __name__ == '__main__':
print("—" * 50)
voc2coco() # voc数据集转换成coco数据集
print("—" * 50)
1.3 数据集真实值可视化
利用coco数据集可视化数据集的ground truth。查看数据集中是否有脏数据,根据具体情况除掉。
mmdetection/data/dataset1/box_visiual.py
import json
import os
import random
import cv2
root_path = os.getcwd()
SAMPLE_NUMBER = 30 # 随机挑选多少个图片检查,
id_category = {1: 'point'} # 改成自己的类别
def visiual():
# 获取bboxes
json_file = os.path.join(root_path, 'coco2017', 'annotations', 'instances_train2017.json') # 如果想查看验证集,就改这里
data = json.load(open(json_file, 'r'))
images = data['images'] # json中的image列表,
# 读取图片
for i in random.sample(images, SAMPLE_NUMBER): # 随机挑选SAMPLE_NUMBER个检测
# for i in images: # 整个数据集检查
img = cv2.imread(os.path.join(root_path, 'coco2017', 'train2017',
i['file_name'])) # 改成验证集的话,这里的图片目录也需要改,train2017 -> val2017
bboxes = [] # 获取每个图片的bboxes
category_ids = []
annotations = data['annotations']
for j in annotations:
if j['image_id'] == i['id']:
bboxes.append(j["bbox"])
category_ids.append(j['category_id'])
# 生成锚框
for idx, bbox in enumerate(bboxes):
left_top = (int(bbox[0]), int(bbox[1])) # 这里数据集中bbox的含义是,左上角坐标和右下角坐标。
right_bottom = (int(bbox[0] + bbox[2]), int(bbox[1] + bbox[3])) # 根据不同数据集中bbox的含义,进行修改。
cv2.rectangle(img, left_top, right_bottom, (0, 255, 0), 1) # 图像,左上角,右下坐标,颜色,粗细
cv2.putText(img, id_category[category_ids[idx]], left_top, cv2.FONT_HERSHEY_SCRIPT_SIMPLEX, 0.4,
(255, 255, 255), 1)
# 画出每个bbox的类别,参数分别是:图片,类别名(str),坐标,字体,大小,颜色,粗细
# cv2.imshow('image', img) # 展示图片,
# cv2.waitKey(1000)
cv2.imwrite(os.path.join('visiual', i['file_name']), img) # 或者是保存图片
# cv2.destroyAllWindows()
if __name__ == '__main__':
print('—' * 50)
os.mkdir('visiual')
visiual()
print('| visiual completed.')
print('| saved as ', os.path.join(os.getcwd(), 'visiual'))
print('—' * 50)
到这里我们的数据集就准备好了,第一大步完成,开始第二步。
2. 配置文件的处理
配置文件的处理,我们主要在work_dirs目录下,如果在你 mmdetection/ 目录下没有 work_dirs 目录的话,新建一个文件夹,然后我们在 work_dirs/ 目录下新建一个自己的项目文件夹,例如图中 dataset1。然后我们在 dataset1/ 目录下见一个python文件,用于生成配置文件。

2.1 生成配置文件
先生成一个我们的配置文件,然后我们再在配置文件中做详细修改。
mmdetection/work_dirs/dataset1/create_config.py
import os
import random
import numpy as np
import torch
from mmcv import Config
from mmdet.apis import set_random_seed
# from mmcv.ops import get_compiling_cuda_version, get_compiler_version
# print(torch.__version__, torch.cuda.is_available())
# print(get_compiling_cuda_version())
# print(get_compiler_version())
"""
设置随机种子
"""
seed = 7777
"""Sets the random seeds."""
set_random_seed(seed, deterministic=False)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ['PYTHONHASHSEED'] = str(seed)
job_num = '1' # 根据我的经验,设置一个job编号方便管理。
model_name = f'cascade_rcnn_r50_fpn_1x_job{job_num}' # 改成自己要使用的模型名字
work_dir = os.path.join(os.getcwd(), model_name) # 训练过程中,保存文件的路径,不用动。
baseline_cfg_path = "../../configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py" # 改成自己要使用的模型的路径
cfg_path = os.path.join(work_dir, model_name + '.py') # 生成的配置文件保存的路径
train_data_images = os.getcwd() + '/../../data/mchar/mchar_train' # 改成自己训练集图片的目录。
val_data_images = os.getcwd() + '/../../data/mchar/mchar_val' # 改成自己验证集图片的目录。
test_data_images = os.getcwd() + '/../../data/mchar/mchar_test' # 改成自己测试集图片的目录。
# File config
num_classes = 1 # 改成自己的类别数。
classes = ("point",) # 改成自己的类别
# 去找个网址里找你对应的模型的网址: https://github.com/open-mmlab/mmdetection/blob/master/README_zh-CN.md
load_from = 'https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco/cascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth'
train_ann_file = os.getcwd() + '/../../data/mchar/instances_train2017.json' # 修改为自己的数据集的训练集json
val_ann_file = os.getcwd() + '/../../data/mchar/instances_val2017.json' # 修改为自己的数据集的验证集json
# Train config # 根据自己的需求对下面进行配置
gpu_ids = [1] # 没啥用,后边用官方的工具进行训练,这里无所谓。
total_epochs = 30 # 改成自己想训练的总epoch数
batch_size = 2 ** 2 # 根据自己的显存,改成合适数值,建议是2的倍数。
num_worker = 2 # 比batch_size小,就行
log_interval = 100 # 日志打印的间隔
checkpoint_interval = 8 # 权重文件保存的间隔
evaluation_interval = 1 # 验证的间隔,这个一般不用动
lr = 0.01 / 2 # 学习率
"""
制作mmdetection的cascade配置文件
"""
def create_mm_config():
cfg = Config.fromfile(baseline_cfg_path)
cfg.work_dir = work_dir
# Set seed thus the results are more reproducible
cfg.seed = seed
# You should change this if you use different model
cfg.load_from = load_from
if not os.path.exists(work_dir):
os.makedirs(work_dir)
print("| work dir:", work_dir)
# Set the number of classes
for head in cfg.model.roi_head.bbox_head:
head.num_classes = num_classes
cfg.gpu_ids = gpu_ids
cfg.runner.max_epochs = total_epochs # Epochs for the runner that runs the workflow
cfg.total_epochs = total_epochs
# Learning rate of optimizers. The LR is divided by 8 since the config file is originally for 8 GPUs
cfg.optimizer.lr = lr
## Learning rate scheduler config used to register LrUpdater hook
cfg.lr_config = dict(
policy='CosineAnnealing',
# The policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9.
by_epoch=False,
warmup='linear', # The warmup policy, also support `exp` and `constant`.
warmup_iters=500, # The number of iterations for warmup
warmup_ratio=0.001, # The ratio of the starting learning rate used for warmup
min_lr=1e-07)
# config to register logger hook
cfg.log_config.interval = log_interval # Interval to print the log
# Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation.
cfg.checkpoint_config.interval = checkpoint_interval # The save interval is 1
cfg.dataset_type = 'CocoDataset' # Dataset type, this will be used to define the dataset
cfg.classes = classes
cfg.data.train.img_prefix = train_data_images
cfg.data.train.classes = cfg.classes
cfg.data.train.ann_file = train_ann_file
cfg.data.train.type = 'CocoDataset'
cfg.data.val.img_prefix = val_data_images
cfg.data.val.classes = cfg.classes
cfg.data.val.ann_file = val_ann_file
cfg.data.val.type = 'CocoDataset'
cfg.data.test.img_prefix = val_data_images
cfg.data.test.classes = cfg.classes
cfg.data.test.ann_file = val_ann_file
cfg.data.test.type = 'CocoDataset'
cfg.data.samples_per_gpu = batch_size # Batch size of a single GPU used in testing
cfg.data.workers_per_gpu = num_worker # Worker to pre-fetch data for each single GPU
# The config to build the evaluation hook, refer to https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/evaluation/eval_hooks.py#L7 for more details.
cfg.evaluation.metric = 'bbox' # Metrics used during evaluation
# Set the epoch intervel to perform evaluation
cfg.evaluation.interval = evaluation_interval
cfg.evaluation.save_best = 'bbox_mAP'
cfg.log_config.hooks = [dict(type='TextLoggerHook')]
print("| config path:", cfg_path)
# Save config file for inference later
cfg.dump(cfg_path)
# print(f'CONFIG:\n{cfg.pretty_text}')
if __name__ == '__main__':
print("—" * 50)
create_mm_config()
print("—" * 50)
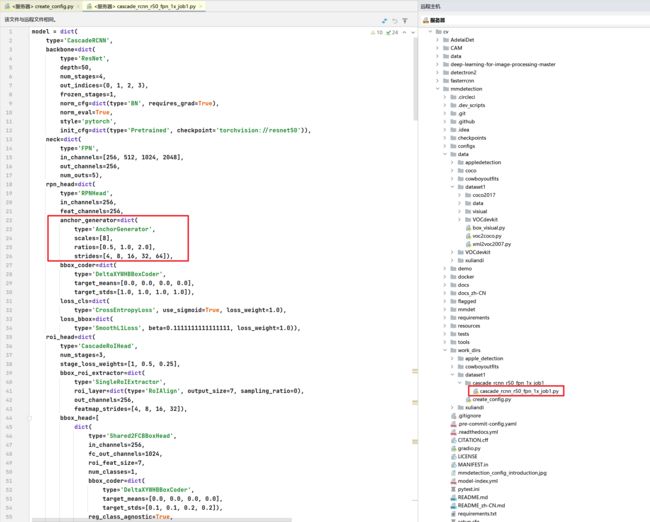
2.2 修改配置文件
一些没有在生成配置文件中设置的,我们直接打开配置文件,进行修改,例如下边的anchor_generator的一些参数。
mmdetection/work_dirs/dataset1/cascade_rcnn_r50_fpn_1x_job1/cascade_rcnn_r50_fpn_1x_job1.py
3. 开始训练
在mmdetection根目录下,也就是 mmdetection/ 目录用命令行运行,可以等程序运行起来后,看显存占用,然后调节batch_size。
单GPU训练
模板
python tools/train.py ${配置文件} --gpu-ids ${gpu id}
样例:我想利用第二张显卡训练,就将 –gpu-ids 设置为1
python tools/train.py work_dirs/dataset1/cascade_rcnn_r50_fpn_1x_job1/cascade_rcnn_r50_fpn_1x_job1.py --gpu-ids 1
多GPU训练
模板
bash tools/dist_train.sh ${配置文件} ${gpu 数量}
样例:我用两张显卡一起训练
bash tools/dist_train.sh work_dirs/dataset1/cascade_rcnn_r50_fpn_1x_job1/cascade_rcnn_r50_fpn_1x_job1.py 2
如果你想在一台机器上启动多个任务,比如8GPU机器,启动两个训练任务。你需要在执行tools/dist_train.sh脚本的时候,指定不同的端口(默认端口为29500)来避免冲突。
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501
4. 可视化模型的输出
训练完后可以看一下自己模型推理的结果,看一下效果。在我们的工作目录下创建一个 visiual.py 文件。
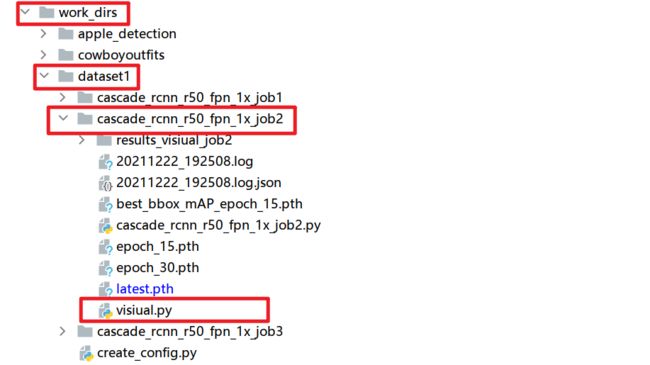
mmdetection/work_dirs/dataset1/cascade_rcnn_r50_fpn_1x_job2/visiual.py
import glob
import os
import shutil
import cv2
import cv2.cv2
import numpy as np
from mmdet.apis import inference_detector, init_detector
root_path = os.getcwd()
job_num = '2' # 根据job数,进行修改
model_name = f'cascade_rcnn_r50_fpn_1x_job{job_num}.py' # 改为自己的模型名
test_images_path = os.path.join(root_path, '../../../data/dataset1/coco2017/train2017/') # 改为自己想要推理的图片
save_dir = 'results_visiual_job' + job_num # 可视化结果保存的路径
classes = ("point",) # 改成自己的类别
image_id = (1,) # 类别对应id
SCORE_THRESH = 0.1 # 置信度阈值,只显示置信度>=阈值的bbox
DEVICE = 'cuda:0' # 显卡
def inference_res(model, images_filename):
results = []
for img_name in images_filename:
img = test_images_path + img_name
result = inference_detector(model, img)
for i in range(len(result)):
for j in result[i]:
j = np.array(j).tolist()
if j[-1] >= SCORE_THRESH:
# 这里注意原来是xmin, ymin, xmax, ymax.
# 根据需求进行保存,这里我就保存xmin, ymin, xmax, ymax.
pred = {'image_id': img_name,
'category_id': 1, # 因为我只有一个类,推理出来的result只有置信度和bbox,
# 没有类别信息,这里根据自己的需求改
'bbox': [j[0], j[1], j[2], j[3]],
'score': j[-1]}
results.append(pred)
return results
def visiual(results):
img_names = os.listdir(test_images_path)
# lst = []
for i in img_names:
img = cv2.imread(os.path.join(test_images_path, i))
for j in results:
if j['image_id'] == i:
if j['score'] >= SCORE_THRESH:
xmin = int(j['bbox'][0])
ymin = int(j['bbox'][1])
xmax = int(j['bbox'][2])
ymax = int(j['bbox'][3])
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2)
# cv2.cv2.putText(img,str(round(j['score'], 3)),(xmin,ymin ),cv2.cv2.FONT_HERSHEY_COMPLEX, 0.7, (255, 255, 255), 3)
cv2.imwrite(save_dir + '/' + i, img) # 将结果保存到文件夹
# lst.append(img)
# lst = cycle(lst)
# key = 0
# while key & 0xFF !=27:
# cv2.imshow("image",next(lst))
# key = cv2.waitKey(3000)
# cv2.cv2.destroyAllWindows() # esc结束可视化
if __name__ == '__main__':
print("—" * 50)
if os.path.exists(save_dir):
shutil.rmtree(save_dir)
os.makedirs(save_dir)
best_epoch_filepath = glob.glob('best' + '*')[0] # best_bbox_mAP_epoch_9.pth
config = os.path.join(root_path, model_name)
checkpoint = os.path.join(root_path, best_epoch_filepath)
print('| config: ', config)
print('| checkpoint: ', checkpoint)
model = init_detector(config, checkpoint, device=DEVICE)
images_filename = os.listdir(test_images_path)
results = inference_res(model, images_filename)
visiual(results) # 可视化测试数据集
print('| image save dir:', save_dir)
print('| Visiual complete.')
print("—" * 50)
5. gradio做到网页
我相信面前的你肯定也是个愿意折腾的小伙伴,那就让我们把它做到网页上,过程很简单。
更多的配置,参考gradio官网文档 【Gradio Getting Started】 【Gradio Docs】
5.1 安装gradio
pip install gradio
5.2 编写实例
我是在 mmdetection/ 目录下新建了一个 gradio.py 文件。运行后就可以看到控制台输出了一个网址,点进去,就可以上传图片,然后可以推理了。
mmdetection/gradio.py
import os
import gradio as gr
import numpy as np
from cv2 import cv2
from mmdet.apis import inference_detector, init_detector
root_path = os.getcwd()
classes = ("apple",) # 改为自己的类别名
image_id = (1,) # 类别名对应的id
SCORE_THRESH = 0.2 # 置信度阈值
DEVICE = 'cuda:0' # 用那个显卡推理
config_path = "./work_dirs/xuliandi/cascade_rcnn_r50_fpn_1x/cascade_rcnn_r50_fpn_1x.py" # 配置文件,改为自己的
checkpoint_path = "./work_dirs/xuliandi/cascade_rcnn_r50_fpn_1x/best_bbox_mAP_epoch_9.pth" # 权重文件,改为自己的
config = config_path
checkpoint = checkpoint_path
model = init_detector(config, checkpoint, device=DEVICE)
def inference_res(model, image_input):
results = []
result = inference_detector(model, image_input)
for i in range(len(result)):
for j in result[i]:
j = np.array(j).tolist()
if j[-1] >= SCORE_THRESH:
pred = {'bbox': [j[0], j[1], j[2], j[3]],
'score': j[-1]}
results.append(pred)
return results
def detect_image(image_input):
results = inference_res(model, image_input)
for i in results:
xmin = int(i['bbox'][0])
ymin = int(i['bbox'][1])
xmax = int(i['bbox'][2])
ymax = int(i['bbox'][3])
cv2.rectangle(image_input, (xmin, ymin), (xmax, ymax), (255, 0, 0), 2) # 画bbox
return image_input
if __name__ == '__main__':
gr.Interface(fn=detect_image, inputs="image", outputs="image", capture_session=True).launch()
⭐️ 完结撒花