OCR识别图片表格
目录:
一、PP-Structure简介
二、安装PP-Structure
三、使用Jupyter Notebook编写代码
一、PP-Structure简介
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,主要特性如下:
- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
二、安装PP-Structure
可根据官网操作(PaddleOCR/README_ch.md at release/2.3 · PaddlePaddle/PaddleOCR · GitHub)
1、打开命令提示符(Win+R),输入cmd
2、安装PaddlePaddle,输入pip install paddlepaddle
3、安装Layout-Parser,输入pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
4、安装paddleocr,输入pip install paddleocr
(按步骤安装,安装时间有点慢)
三、使用Jupyter Notebook编写代码
1、导入需要用的包
from paddleocr import PaddleOCR,draw_ocr,draw_structure_result,save_structure_res,PPStructure
import os
import cv2
import pandas as pd2、
table =PPStructure(show_log=True,use_gpu=True)出现
[2022/05/03 16:11:39] ppocr DEBUG: Namespace(help='==SUPPRESS==', use_gpu=False, ir_optim=True, use_tensorrt=False, min_subgraph_size=15, precision='fp32', gpu_mem=500, image_dir=None, det_algorithm='DB', det_model_dir='C:\\Users\\yi/.paddleocr/whl\\det\\ch\\ch_PP-OCRv2_det_infer', det_limit_side_len=960, det_limit_type='max', det_db_thresh=0.3, det_db_box_thresh=0.6, det_db_unclip_ratio=1.5, max_batch_size=10, use_dilation=False, det_db_score_mode='fast', det_east_score_thresh=0.8, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_sast_score_thresh=0.5, det_sast_nms_thresh=0.2, det_sast_polygon=False, det_pse_thresh=0, det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_box_type='quad', det_pse_scale=1, scales=[8, 16, 32], alpha=1.0, beta=1.0, fourier_degree=5, det_fce_box_type='poly', rec_algorithm='CRNN', rec_model_dir='C:\\Users\\yi/.paddleocr/whl\\rec\\ch\\ch_PP-OCRv2_rec_infer', rec_image_shape='3, 32, 320', rec_batch_num=6, max_text_length=25, rec_char_dict_path='D:\\Anaconda\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', use_space_char=True, vis_font_path='./doc/fonts/simfang.ttf', drop_score=0.5, e2e_algorithm='PGNet', e2e_model_dir=None, e2e_limit_side_len=768, e2e_limit_type='max', e2e_pgnet_score_thresh=0.5, e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_pgnet_valid_set='totaltext', e2e_pgnet_mode='fast', use_angle_cls=False, cls_model_dir=None, cls_image_shape='3, 48, 192', label_list=['0', '180'], cls_batch_num=6, cls_thresh=0.9, enable_mkldnn=False, cpu_threads=10, use_pdserving=False, warmup=False, draw_img_save_dir='./inference_results', save_crop_res=False, crop_res_save_dir='./output', use_mp=False, total_process_num=1, process_id=0, benchmark=False, save_log_path='./log_output/', show_log=True, use_onnx=False, output='./output', table_max_len=488, table_model_dir='C:\\Users\\yi/.paddleocr/whl\\table\\en_ppocr_mobile_v2.0_table_structure_infer', table_char_dict_path='D:\\Anaconda\\lib\\site-packages\\paddleocr\\ppocr\\utils\\dict\\table_structure_dict.txt', layout_path_model='lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config', layout_label_map=None, mode='structure', layout=True, table=True, ocr=True, lang='ch', det=True, rec=True, type='ocr', ocr_version='PP-OCRv2', structure_version='STRUCTURE')
3、写入自己的图片地址(我的图片直接放入的C盘),用cv2包把图片读进来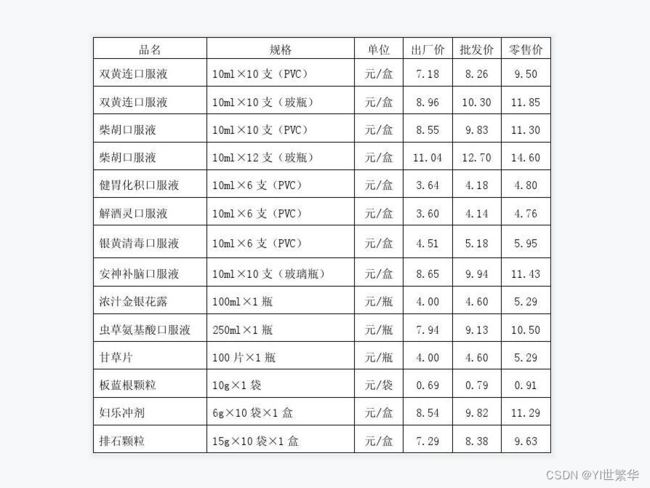
img_path="C:\yy.bmp"
img=cv2.imread(img_path)
result=table(img)结果
[2022/05/03 16:19:05] ppocr DEBUG: dt_boxes num : 90, elapse : 0.449573278427124 [2022/05/03 16:19:08] ppocr DEBUG: rec_res num : 90, elapse : 2.99617600440979 表示成功读取图片数据(读取图片大概需要几秒时间)
4、
result[{'type': 'Table', 'bbox': [0, 8, 631, 570], 'img': array([[[253, 253, 253], [ 0, 0, 0], [254, 254, 254], ..., [255, 255, 255], [253, 253, 253], [ 0, 0, 0]], [[253, 253, 253], [ 0, 0, 0], [254, 254, 254], ..., [255, 255, 255], [253, 253, 253], [ 0, 0, 0]], [[253, 253, 253], [ 0, 0, 0], [254, 254, 254], ..., [255, 255, 255], [253, 253, 253], [ 0, 0, 0]], ..., [[253, 253, 253], [ 0, 0, 0], [254, 254, 254], ..., [255, 255, 255], [253, 253, 253], [ 0, 0, 0]], [[237, 237, 237], [ 12, 12, 12], [243, 243, 243], ..., [251, 251, 251], [243, 243, 243], [ 17, 17, 17]], [[255, 255, 255], [ 3, 3, 3], [255, 255, 255], ..., [244, 244, 244], [255, 255, 255], [ 1, 1, 1]]], dtype=uint8), 'res': {'html': ''}}]
品名 规格 单位 出厂价 批发价 零售价 双黄连口服液 10mlX10支(PVC) 元/盒 7.18 2 9.50 双黄连口服液 10mlX10支(玻瓶) 元/盒 8.96 10.30 11.85 柴胡口服液 10mlX10支(PVC) 元/盒 8.55 9.83 11.30 柴胡口服液 10ml×12支(玻瓶) 元/盒 11.04 12.70 14.60 健胃化积口服液 10mlX6支(PVC) 元/盒 3.64 4.18 4.80 解酒灵口服液 10ml×6支(PVC) 元/盒 3.60 4.14 4.76 银黄清毒口服液 10mlX6支(PVC) 元/盒 4.51 5.18 5.95 安神补脑口服液 10ml×10支(玻璃瓶) 元/盒 8.65 9.94 11. 43 浓汁金银花露 100mlx1瓶 元/瓶 4.00 4.60 5.29 虫草氨基酸口服液 250ml×1瓶 元/瓶 7.94 9.13 10.50 甘草片 100片×1瓶 元/瓶 4.00 4.60 5.29 板蓝根颗粒 10g×1袋 元/袋 0.69 0.79 0.91 妇乐冲剂 6g×10袋×1盒 元/盒 8.54 9.82 11.29 排石颗粒 15g×10袋×1盒 元/盒 7.29 8.38 9.63
将result改为result[0] ,出现结果同上,再改为result[0]['res'],出现
{'html': ''}
品名 规格 单位 出厂价 批发价 零售价 双黄连口服液 10mlX10支(PVC) 元/盒 7.18 2 9.50 双黄连口服液 10mlX10支(玻瓶) 元/盒 8.96 10.30 11.85 柴胡口服液 10mlX10支(PVC) 元/盒 8.55 9.83 11.30 柴胡口服液 10ml×12支(玻瓶) 元/盒 11.04 12.70 14.60 健胃化积口服液 10mlX6支(PVC) 元/盒 3.64 4.18 4.80 解酒灵口服液 10ml×6支(PVC) 元/盒 3.60 4.14 4.76 银黄清毒口服液 10mlX6支(PVC) 元/盒 4.51 5.18 5.95 安神补脑口服液 10ml×10支(玻璃瓶) 元/盒 8.65 9.94 11. 43 浓汁金银花露 100mlx1瓶 元/瓶 4.00 4.60 5.29 虫草氨基酸口服液 250ml×1瓶 元/瓶 7.94 9.13 10.50 甘草片 100片×1瓶 元/瓶 4.00 4.60 5.29 板蓝根颗粒 10g×1袋 元/袋 0.69 0.79 0.91 妇乐冲剂 6g×10袋×1盒 元/盒 8.54 9.82 11.29 排石颗粒 15g×10袋×1盒 元/盒 7.29 8.38 9.63
5、保存表格(我直接保存到了C盘)
save_folder = 'C:/'
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])C盘出现图片相同名字的文件夹,打开(有些表格可能有小小的错误,需要自己核对),完成
