ICCV 2021 Oral | CoaT: Co-Scale Conv-Attentional Image Transformers
ICCV 2021 Oral | CoaT: Co-Scale Conv-Attentional Image Transformers

- 论文:https://arxiv.org/abs/2104.06399
- 参考:https://zhuanlan.zhihu.com/p/536517021
主要工作
- 设计了一种简化的线性注意力形式,factorized attention。
- 设计了一种基于深度分离卷积的卷积相对位置编码。
- 搭建了一种多尺度交叉形式的架构。
注意力的改进

线性注意力
A = 1 d Q [ softmax ( K ⊤ ) V ] + E V A = \frac{1}{\sqrt{d}} Q [\text{softmax}(K^{\top})V] + EV A=d1Q[softmax(K⊤)V]+EV
在设计思路上延续了 Linear Attention的形式,几种不同的Attention可以参考我之前的文章:Vision Transformer之LambdaNetworks。
线性注意力:Softmax 应用于 KV 之间要被消去的维度,即序列索引的维度。这里的运算形式可以看做是 KV 就是对 Q 进行 global data-dependent linear transformation 的权重(空间共享的通道变换)。这种设计在没有位置编码的情况下,考虑到 Transformer 仅由线性层和自注意力组成,一个 token 的输出依赖于相应的输入,而没有考虑到其局部附近特征的任何差异,该属性不利语义分割等任务(例如,天空和具有相同外观属性的蓝色斑块可能被划分为同一类别),所以有必要引入位置信息。
卷积相对位置编码
模型整体使用了卷积位置编码和卷积相对位置编码。其中卷积位置编码与原始的CPE一致。但是卷积相对位置编码就是作者们自己的设计了。
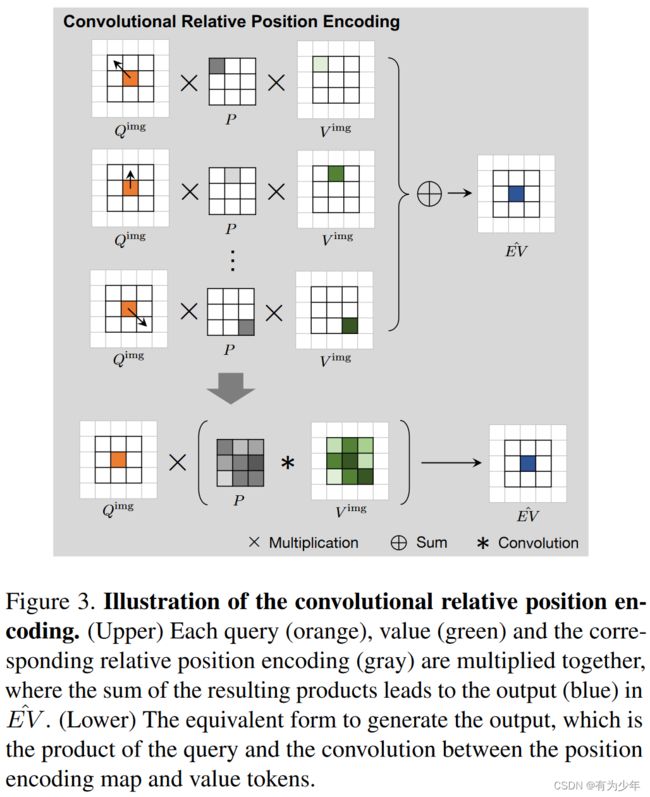
这里的核心是相对位置嵌入 E V ∈ R N × C EV \in \mathbb{R}^{N \times C} EV∈RN×C。独立计算的时候,时空复杂度均为序列长度的平方级别。
- E ∈ R N × N E \in \mathbb{R}^{N \times N} E∈RN×N 中每个元素表示 Q 中元素与 V 中元素的关系,且 E i , j = 1 ( i , j ) q i ⋅ p j − i , 0 ≤ i , j ≤ N E_{i,j}=\mathbb{1}(i,j)q_i \cdot p_{j-i}, 0 \le i,j \le N Ei,j=1(i,j)qi⋅pj−i,0≤i,j≤N。
- 大小为 M M M 的相对位置编码 P = { p i ∈ R C , i = − M − 1 2 , … , M − 1 2 } P = \{p_i \in \mathbb{R}^{C}, i=-\frac{M-1}{2}, \dots, \frac{M-1}{2}\} P={pi∈RC,i=−2M−1,…,2M−1}。
对于图像而言有:
E V i , j , c v = ∑ ∣ k − i ∣ < M 2 , ∣ l − j ∣ < M 2 ∑ c q ( Q i , j , c q P k , l , c q ) V k , l , c v = ∑ c q Q i , j , c q ∑ ∣ k − i ∣ < M 2 , ∣ l − j ∣ < M 2 ( P k , l , c q V k , l , c v ) EV_{i,j,c_v} = \sum_{|k-i| < \frac{M}{2}, |l-j| < \frac{M}{2}} \sum_{c_q} (Q_{i,j,c_q} P_{k,l,c_q}) V_{k,l,c_v} \\ = \sum_{c_q} Q_{i,j,c_q} \sum_{|k-i| < \frac{M}{2}, |l-j| < \frac{M}{2}} (P_{k,l,c_q} V_{k,l,c_v}) EVi,j,cv=∣k−i∣<2M,∣l−j∣<2M∑cq∑(Qi,j,cqPk,l,cq)Vk,l,cv=cq∑Qi,j,cq∣k−i∣<2M,∣l−j∣<2M∑(Pk,l,cqVk,l,cv)
所以为了降低计算复杂度,这里将 Q、P 和 V 的每个通道独立作为一个 head 进行处理,即这里的处理就没有了通道维度的索引,变为:
E V i , j c = ∑ ∣ k − i ∣ < M 2 , ∣ l − j ∣ < M 2 ( Q i , j c P k , l c ) V k , l c = Q i , j c ∑ ∣ k − i ∣ < M 2 , ∣ l − j ∣ < M 2 ( P k , l c V k , l c ) EV^c_{i,j} = \sum_{|k-i| < \frac{M}{2}, |l-j| < \frac{M}{2}} (Q^c_{i,j} P^c_{k,l}) V^c_{k,l}\\ = Q^c_{i,j} \sum_{|k-i| < \frac{M}{2}, |l-j| < \frac{M}{2}} (P^c_{k,l} V^c_{k,l}) EVi,jc=∣k−i∣<2M,∣l−j∣<2M∑(Qi,jcPk,lc)Vk,lc=Qi,jc∣k−i∣<2M,∣l−j∣<2M∑(Pk,lcVk,lc)
而后面这个形式可以通过深度分离卷积来实现,窗口的相对位置编码即为卷积的权重,V 即为被卷积的特征。输出结果与 Q 直接相乘即可。
基于以上推导,深度卷积可以看做是相对位置编码的一种特殊情况。
多尺度架构
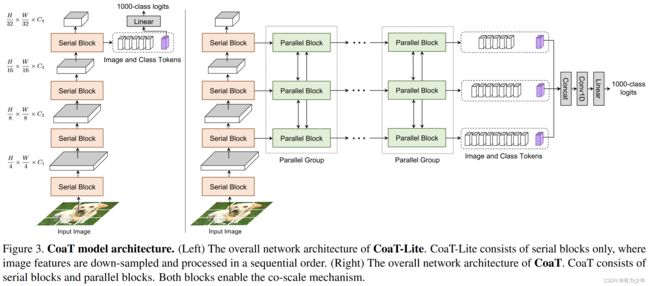
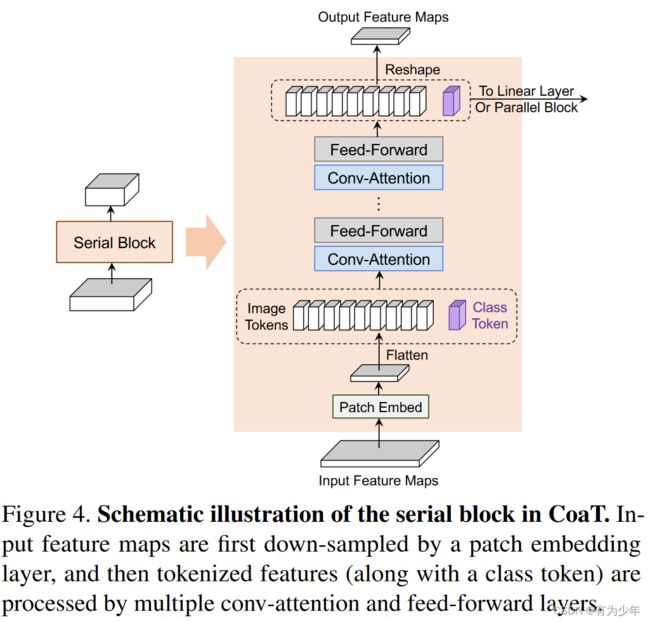
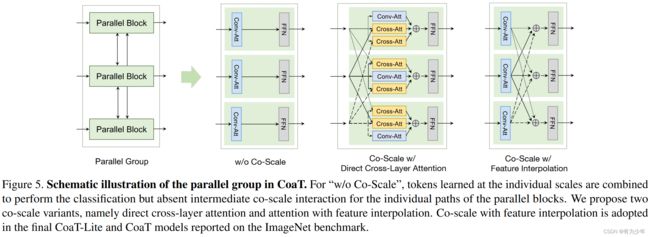
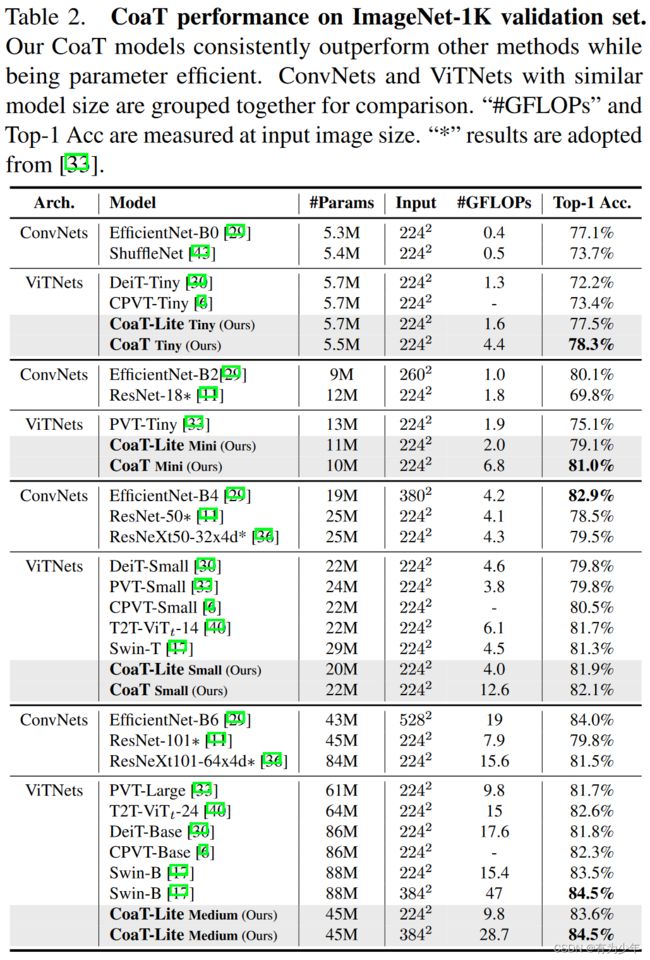
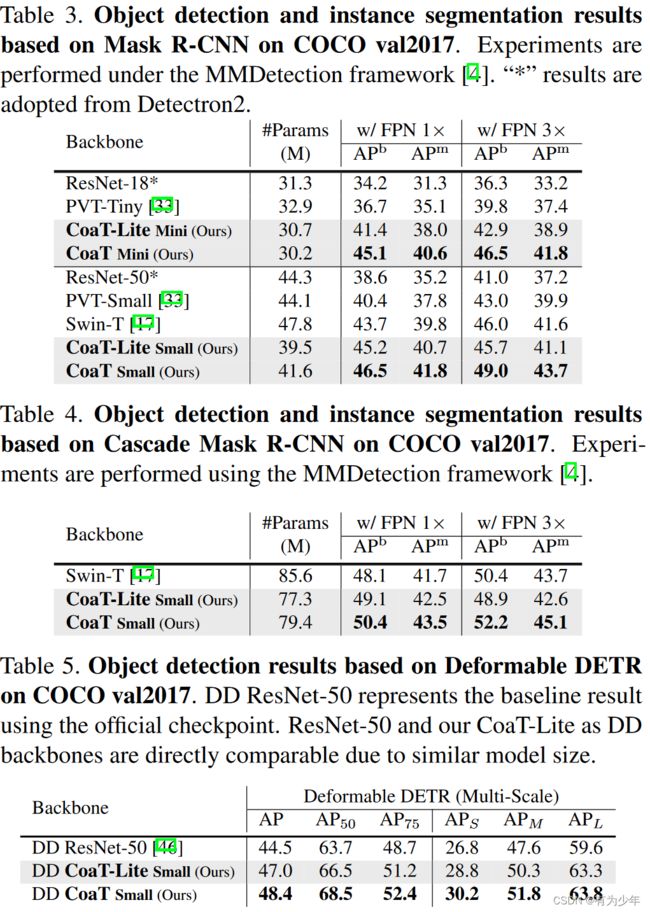
实验结果
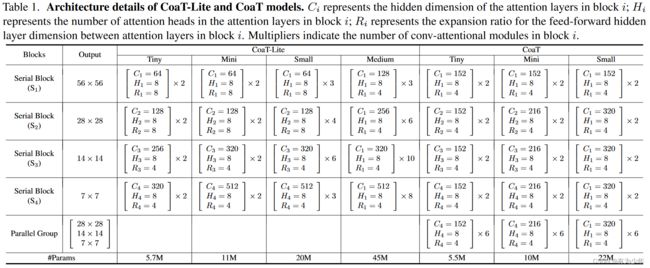
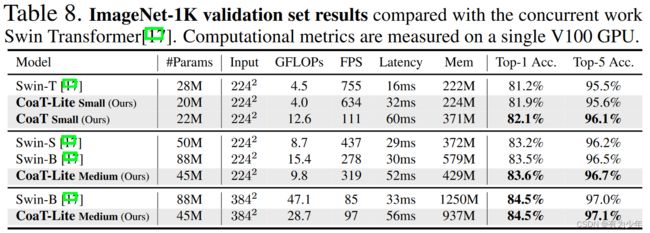
对比实验
| 分类 | 密集预测 |
|---|---|
 |
 |
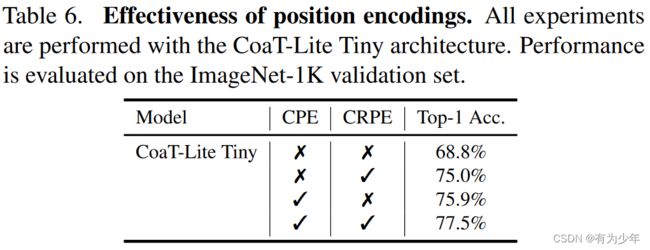
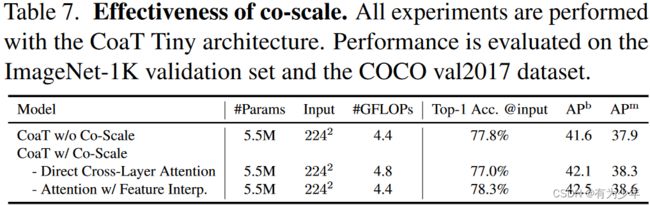
消融实验