2021李宏毅机器学习笔记--17 transformer
2021李宏毅机器学习笔记--17 transformer
- 摘要
- 一、transformer
- 二、Self-Attention
- 三、Muliti-head self-attention
- 四、Position Encoding
- 五、seq2seq with attention
- 总结
摘要
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建。采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算。Transformer使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量,它不是类似RNN的顺序结构,因此具有更好的并行性。
一、transformer
Transformer的知名应用——BERT——无监督的训练的Transformer。
Transformer是BERT的核心模块
 Transformer是一个seq2seq模型,并且大量用到了"Self-attention",接下来就要讲解一下"Self-attention"用到了什么东西
Transformer是一个seq2seq模型,并且大量用到了"Self-attention",接下来就要讲解一下"Self-attention"用到了什么东西
 Sequence就会想到RNN,单方向或者双向的RNN。
Sequence就会想到RNN,单方向或者双向的RNN。
RNN输入是一串sequence,输出是另外一串sequence。
RNN常被用于输出是一个序列的情况,但是有一个问题——不容易被平行化(并行)。
单向RNN的时候,想要算出b4,必须先把a1,a2,a3都看过才可以算出a4。双向则得全部看完才会有输出。
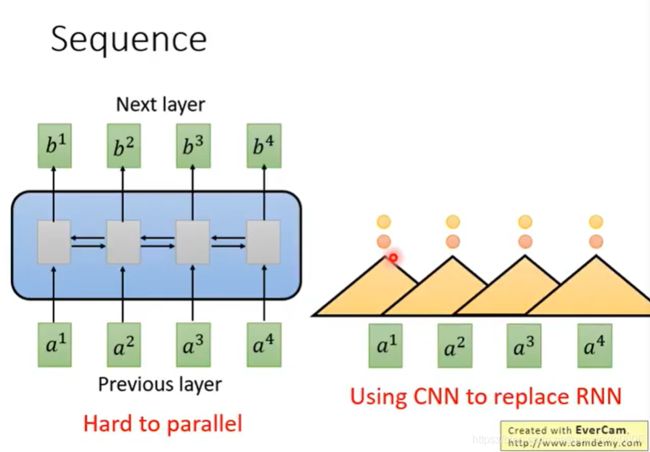
于是有人提出用CNN取代RNN
一个三角形是一个filter,输入为sequence中的一段,此刻是将三个vector作为一个输入,输出一个数值。
将三个vector的内容与filter内部的参数做内积,得到一个数值,将filter扫过sequence,产生一排不同的数值。
有多个filter,产生另外一排不同的数值
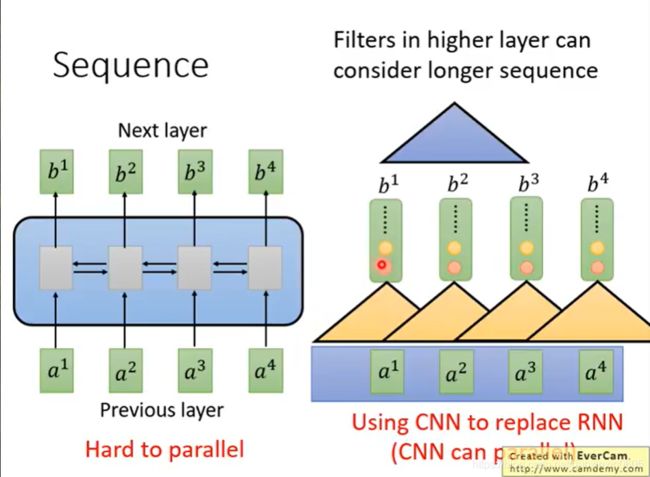
我们可以看到,用CNN也可以做到和RNN类似的效果:输入一个sequence,输出一个sequence。
表面上CNN和RNN都可以有同样的输入输出。
但是每个CNN只能考虑很有限的内容(三个vector),而RNN是考虑了整个句子再决定输出。
CNN也可以考虑更长的信息,只要叠加多层CNN,上层的filter就可以考虑更加多的信息。
eg:先叠了第一层CNN后,叠加第二层CNN。第二层的filter会把第一层的output当作输入,相当于看了更多的内容。
CNN的好处在于可以并行化。
CNN的缺点在于必须叠加多层,才可以看到长时间的信息,如果要在第一层filter就要看到长时间的信息,那是无法做到的。所以有Self-Attention。
二、Self-Attention
Self-Attention做的事情就是取代RNN原本要做的事情。
关键: 有一种新的layer—— Self-Attention,输入输出与RNN一样,都是sequence。
特别的地方在于,和双向RNN有同样的能力,每一个输出都是看过整个input sequence,只不过b1 b2 b3 b4是可以同时算出来的,可以并行计算!
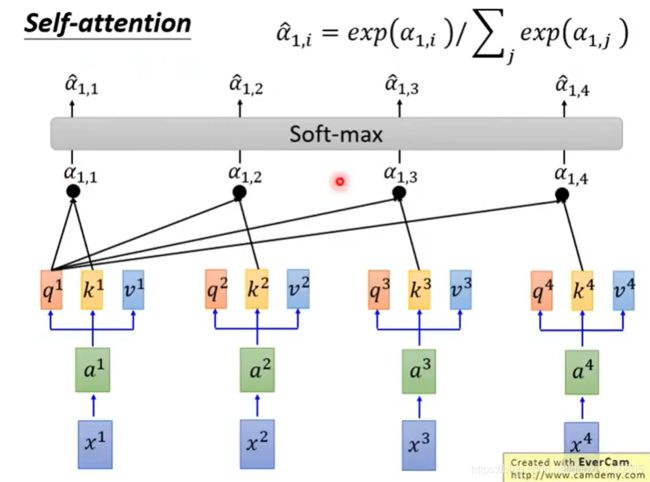
 输入sequence x1~x4,通过乘上一个W matrix来得到embedding a1~a4,丢入Self-attention,每一个输入都分别乘上三个不同的transformation matrix,产生三个不同的vector q,k,v。
输入sequence x1~x4,通过乘上一个W matrix来得到embedding a1~a4,丢入Self-attention,每一个输入都分别乘上三个不同的transformation matrix,产生三个不同的vector q,k,v。
q代表query,用来match其他人
k代表key,用来被匹配的
v代表要被抽取出来的信息
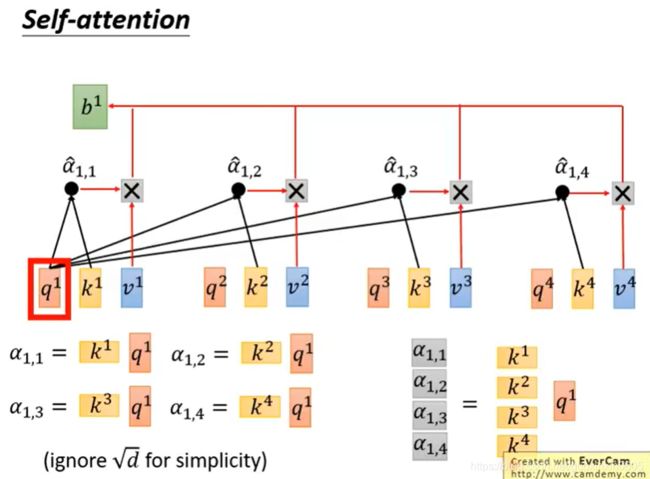
 拿每个query q去对每个key k做attention,我们这里用到的计算attention的方法是scaled dot-product。
拿每个query q去对每个key k做attention,我们这里用到的计算attention的方法是scaled dot-product。
attention本质就是输入两个向量,输出一个分数。
除以 √d的一个原因是:d是q和k的维度,q和k做inner product,所以q和k的维度是一样的为d。
除以 √d的直观解释为q和k做内积/点积的数值会随着维度增大 他的variance越大,所以除以来 √d平衡。
不除以d会梯度爆炸,不收敛,推一推梯度就能的到结果
 通过一个softmax函数
通过一个softmax函数
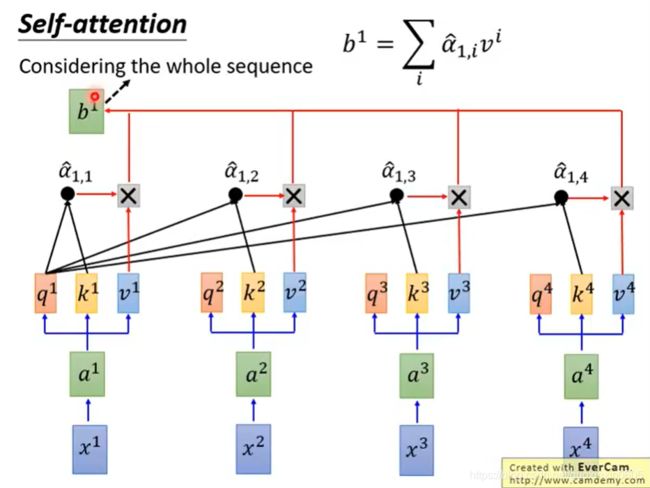 上图,产生b1的时候已经考虑了全部句子的信息
上图,产生b1的时候已经考虑了全部句子的信息
如果现在只想考虑局部的信息,而不是全局的,也是可以做到的,即只需要让右边那些α产生出来的值变成0,就只考虑局部了。
如果要考虑全局的信息,就要考虑离他最远的input的vector值的话,只要让那个attention ( α)有值即可。
刚刚只是计算了b1,同时也可以计算其他的b
 我们来看一下最终完整的流程图:
我们来看一下最终完整的流程图:
self-attention做的和RNN的事情是一样的,只不过是平行计算出来的。
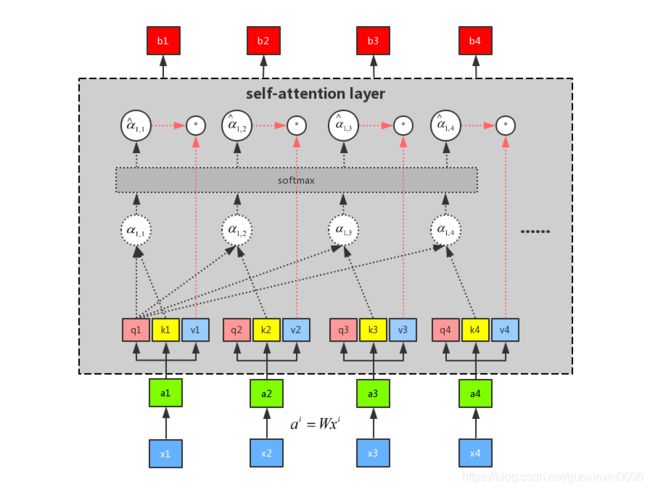

self-attention中所有的运算都可以利用矩阵来进行运算,因此我们就可以使用gpu来进行加速,极大的加快了我们的运算速度。
 矩阵运算就是将a1~a4拼起来作为一个matrix I,用 I 再乘以 Wq,一次得到matrix Q,里面的每一列代表一个q。同理,将matrix I乘以Wk和Wv可以得到相应的matrix K和marix V。
矩阵运算就是将a1~a4拼起来作为一个matrix I,用 I 再乘以 Wq,一次得到matrix Q,里面的每一列代表一个q。同理,将matrix I乘以Wk和Wv可以得到相应的matrix K和marix V。
接下来,拿query q去对每个key k做attention。并对每一列做softmax。
 接下来就是根据我们通过softmax得到的结果,考虑每个信息,从而得到我们的一个输出。
接下来就是根据我们通过softmax得到的结果,考虑每个信息,从而得到我们的一个输出。
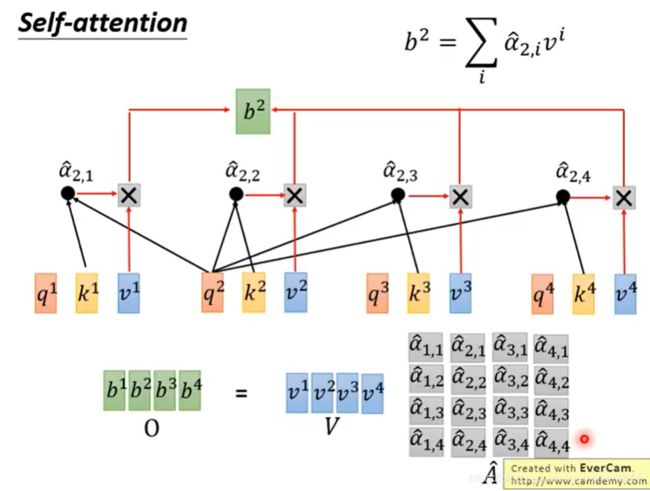 最后,我们将所有矩阵运算整合起来,来回顾一下整个流程。
最后,我们将所有矩阵运算整合起来,来回顾一下整个流程。

三、Muliti-head self-attention
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1、它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2、它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
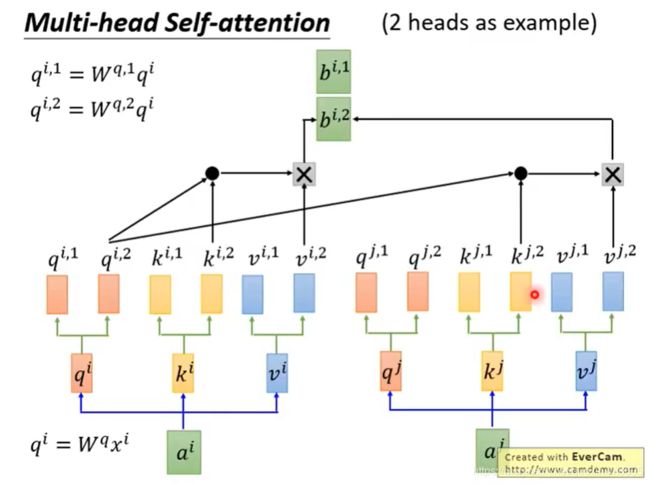 注意一点的是,每个头只能和对应的头进行运算。比如: q i , 2 q^{i,2} qi,2只能和对应的 k i , 2 k^{i,2} ki,2以及 k j , 2 k^{j,2} kj,2进行运算,而不能和 k i , 1 k^{i,1} ki,1以及 k j , 1 k^{j,1} kj,1进行运算。
注意一点的是,每个头只能和对应的头进行运算。比如: q i , 2 q^{i,2} qi,2只能和对应的 k i , 2 k^{i,2} ki,2以及 k j , 2 k^{j,2} kj,2进行运算,而不能和 k i , 1 k^{i,1} ki,1以及 k j , 1 k^{j,1} kj,1进行运算。
算出了 b i , 1 b^{i,1} bi,1和 b i , 2 b^{i,2} bi,2后,给我们带来了一点挑战。前馈层不需要两个矩阵,它只需要一个矩阵!所以我们需要一种方法把这两个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵 W 0 W^0 W0与它们相乘。

四、Position Encoding
到目前为止,我们对模型的描述缺少了一种理解输入单词顺序的方法。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
在原始paper中 e i e^i ei是人手设置的,不是学习出来的。 e i e^i ei代表了位置信息,每个位置 e i e^i ei不同。
paper中将 e i e^i ei加上得到一个 a i a^i ai新的vector,之后和Self-attention操作一样。
Q:那么为什么是 e i e^i ei和 a i a^i ai相加呢?而不是拼接起来呢?
A:把再 x i x^i xiappend一个one-hot向量 p i p^i pi,由下图可知,结果是一样的。
 为了让模型理解单词的顺序,我们添加了位置编码向量,这些向量的值遵循特定的模式。
为了让模型理解单词的顺序,我们添加了位置编码向量,这些向量的值遵循特定的模式。
如果我们假设词嵌入的维数为4,则实际的位置编码如下:
 尺寸为4的迷你词嵌入位置编码实例
尺寸为4的迷你词嵌入位置编码实例
这个模式会是什么样子?
在下图中,每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。
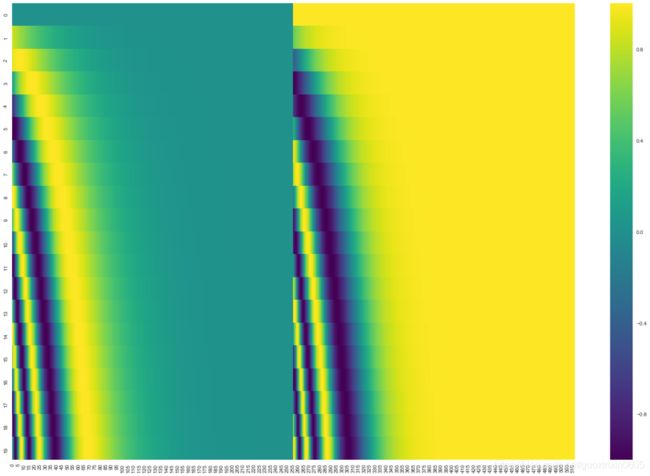 20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
五、seq2seq with attention
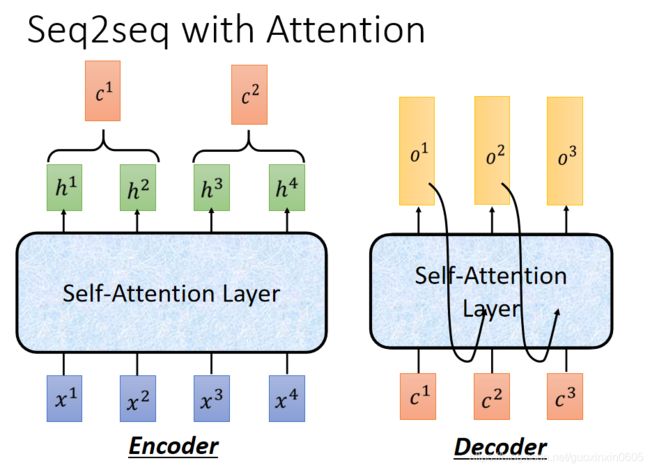 光看上面这张图我们可能并不能直观的看出整个过程,索性谷歌做了一张动图来描述整个过程,让我们一起来看一下吧。
光看上面这张图我们可能并不能直观的看出整个过程,索性谷歌做了一张动图来描述整个过程,让我们一起来看一下吧。
这个图的encoding 过程, 主要是self attention, 有三层。 接下来是decoding过程, 也是有三层, 第一个预测结果 符号, 是完全通过encoding 里的attention vector 做出的决策。 而第二个预测结果Je, 是基于encoding attention vector & attention vector 做出的决策。按照这个逻辑,新翻译的单词不仅仅依赖 encoding attention vector, 也依赖过去翻译好的单词的attention vector。 随着翻译出来的句子越来越多,翻译下一个单词的运算量也就会相应增加。 如果详细分析,复杂度是 n 2 d n^{2d} n2d, 其中n是翻译句子的长度,d是word vector 的维度。
总结
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution
Transformer 是第一个完全依赖自注意力来计算其输入和输出表示而不使用序列对齐的 RNN 或卷积的转换模型.