CUDA10.0官方文档的翻译与学习之编程接口
目录
背景
用nvcc编译
编译工作流
二进制适配性
ptx适配性
应用适配性
C/C++适配性
64位适配性
cuda c运行时
初始化
设备内存
共享内存
页锁主机内存
可移植内存
写合并内存
映射内存
异步并发执行
主机与设备间的并发执行
并发核执行
数据迁移与核执行重叠
并发数据传输
流
多设备系统
设备枚举:
设备选择
流与事件行为
对等结点内存访问
对等结点内存复制
统一虚地址空间
进程间通信
错误检查
调用栈
纹理内存和表面(surface)内存
纹理对象API
纹理引用API
两字节浮点纹理
分层纹理
立方图纹理
纹理聚集
表面内存
表面引用API
立方图表面
cuda数组
读写一致性
图形交互性
OpenGL交互性
Direct3D交互性
SLI交互
版本和适配性
计算模式
模式切换
针对Windows的Tesla计算集群模式
结语
背景
在文章CUDA10.0官方文档的翻译与学习之编程模型和CUDA10.0官方文档的翻译与学习之介绍中我分别翻译了CUDA10.0官方文档的前两章,这篇文章我将翻译此文档中最重要的部分——编程接口
cuda C为熟悉C编程语言的用户提供了简单的写出可以被设备执行的程序的方法,它由对C语言的简单扩展和一个运行时的库组成。核心的语言扩展已经在编程模型一章中介绍了,它允许程序员把核函数定义成C函数,然后使用新的语法来为每一次函数调用指定网格与线程块的维度,对所有扩展的完整描述请参见官方手册。任何包含这些扩展的源文件都必须用nvcc编译器编译,详情参见本章第一节——用nvcc编译。
运行时库在第一节第一部分编译流程中介绍,它提供了在主机上执行的C函数,用来分配与回收设备内存、在主机内存与设备内存之间迁移数据、管理拥有多个设备的系统等,关于运行时的完整描述请参见cuda参考手册。
运行时库是在底层C API、CUDA驱动API(也可以被应用获取)上构建的,驱动API通过暴露底层概念(比如cuda上下文——类似于主机进程、cuda模块——类似于动态链接库等)来提供另一个层面的控制。大多数应用不使用驱动API,因为他们不需要这种额外的控制,当使用运行时时,上下文、模块管理时隐式的,这样代码会简洁得多,驱动API的介绍和完整的描述请参见参考手册
用nvcc编译
核函数可以通过使用cuda指令集来编写,cuda指令集又称为ptx,它在ptx参考手册中有所描述。当然,使用C这种高级编程语言效率更高,但不管怎样,核函数都要通过nvcc编译成二进制代码以便在设备上执行。nvcc是一个简化编译C或ptx代码的编译驱动:它提供简单且熟悉的命令行选项,然后通过调用实现不同编译阶段的工具集来执行它们。本节给出了nvcc工作流和命令选项的总览,完成的介绍请参见nvcc用户手册。
编译工作流
离线编译:
被nvcc编译的源文件由主机代码(在主机上执行的代码)和设备代码(在设备上执行的代码)组成,nvcc的基本工作流包括从主机代码中分离设备代码,把设备代码编译成汇编形式(ptx代码)或二进制形式(cubin对象),然后通过把核函数调用时的<<<...>>>语法替换成有必要加载的cuda c运行时函数调用来修改主机代码,最后从ptx代码或者cubin对象中启动每个编译好的核函数。修改好的主机代码要么以用来被别的工具编译的C代码的形式输出,要么让nvcc在最后的编译阶段调用主机编译器输出目标代码。而后应用就可以要么链接编译好的主机代码(一般如此),要么忽略所有修改过的主机代码,并使用cuda驱动API来加载ptx代码或者运行cubin文件。
即时编译:
被应用加载的任何ptx代码在运行时被设备驱动进一步编译成二进制代码,这就是即时编译。即时编译增大了应用加载时间,但允许应用从任何新设备驱动对编译器的改进中获益,这也是应用运行在它编译时还不存在的设备上的唯一方法,详情请参见应用适配性一节。当设备驱动的即时编译器为一些应用编译ptx代码时,它会自动缓存一份生成的二进制代码的拷贝,以防止对此应用的在后续调用时重复编译。这个缓存(又称之为计算缓存)在设备驱动更新时会自动失效,所以应用才能在安装到设备驱动中的新即时编译器的改进中获益。官方手册中的cuda环境变量部分有关于可以用来控制即时编译的环境变量的描述。
二进制适配性
二进制代码是架构相关的,cubin对象是通过使用指定目标架构的-code编译选项生成的,例如用-code=sm_35编译选项生成的二进制代码是运行在计算能力为3.5的设备上的。二进制适应性在从小的副版本迁移到大的副版本的过程中被保证,但不会在从大的副版本迁移到小的副版本或者跨主版本的迁移过程中保证,换句话说,为计算能力X.y生成的cubin代码只会执行在计算能力X.z(z >= y)的设备上。
ptx适配性
一些ptx指令只在计算能力更高的的设备上被支持,例如伪线程混洗函数只在计算能力>=3.0的设备上支持。编译选项-arch指定了把C编译成ptx代码时使用的计算能力。因此,包含伪线程混洗的代码必须用参数-arch=compute_30(或者更大)来进行编译。被某个计算能力产生的ptx代码总是可以被编译成相同或者更高计算能力的二进制代码,注意从早期ptx版本编译过来的二进制代码可能不会使用某些硬件特征,例如由计算能力6.0的ptx代码编译成的计算能力7.0二进制代码,就不会使用只能在7.0设备上才能用的功能,比如张量核指令。所以,如果二进制文件是使用最新版本的ptx生成的话,它的性能可能会更好一些。
应用适配性
为了在指定计算能力的设备上执行代码,应用必须加载和这种计算能力适配的二进制或者ptx代码,参见上两小节。特殊地,为了能够在拥有更高计算能力的未来架构上执行代码(对于这种架构还不能生成二进制代码),应用就必须装载可以被这些未来设备即时编译的ptx代码(请参见即时编译部分)。哪种ptx或二进制代码可以被嵌入到cuda c应用中可以由-arch和-code编译选项分别指定,或者用-gencode包装它们。但是,如果有多个arch参数,就只会嵌入值最大的ptx代码,举例如下所示
nvcc x.cu -gencode arch=compute_35,code=sm_35 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_60,code=\"compute_60,sm_60\"这段命令将嵌入适配3.5、5.0和6.0的二进制代码以及适配6.0的ptx代码,没有显式适配3.5和5.0,是因为6.0的ptx已经适配了这两个版本了,另外最后面的code=\"compute_60,sm_60\"表示要生成的是6.0的胖二进制(既可以即时编译,也可以立马执行)。主机代码的生成是为了在运行时自动选择最合适的代码来加载和执行,例如在上面的例子中,要加载运行的代码就是:
1、计算能力为3.5和3.7的设备 ->3.5版本的二进制代码;
2、计算能力为5.0和5.2的设备 ->5.0版本的二进制代码;
3、计算能力为6.0和6.1的设备 ->6.0版本的二进制代码;
4、计算能力≥7.0的设备 -> ptx代码,可以被进一步编译成二进制代码。
x.cu可以使用优化后的代码路径,比如使用只在计算能力>=3.0的设备上才能用的伪线程混洗操作,__CUDA_ARCH__宏可以被用来区别基于不同计算能力的代码路径,但它只在设备代码中才能使用,比如当使用-arch=comput_35编译时,__CUDA_ARCH__就等于350。
使用驱动API的应用必须编译代码以分离文件,然后在运行时明确加载运行最合适的文件。Volta架构引入了能改变线程在GPU上调度的独立线程调度机制,对于以之前架构上的smit调度运行的代码,独立线程调度可能会改变参与的线程集合,从而导致错误的结果。为了使用包含独立线程调度的路径的同时保证正确迁移,Volta开发者可以用编译选项-arch=compute_60 -code=sm_70来编译pascal线程调度模块(参数意思是,生成适配6.0的ptx和直接能运行在7.0上的二进制,如果要运行在6.0设备上,6.0的ptx将会再编译成6.0的二进制,这时就会使用SIMT了)。
nvcc用户手册为-arch、-code和-gencode列出了各种简写,例如-arch=sm_35是arch=compute_35 -code=compute_35,sm_35的缩写(也等于-gencode arch=comput_35, code=\"compute_35, sm_35\"),也就是要生成3.5的胖二进制
C/C++适配性
编译器前端来处理包括C++语法的cuda源文件,在主机代码中支持所有的C++,但在设备代码中只有部分C++的自己才被完全支持,请参见官方手册中的C/C++语言支持部分
64位适配性
64位的nvcc编译器以64位模式编译设备代码,比如指针都是64位的,被64位模式编译的设备代码只能支持同样以64位模式编译主机代码,对于32位的nvcc也是如此。但是,为了兼容性,可以为32位编译器加上-m64、为64位编译器加上-m32来让它们分别以64位和32位模式编译设备代码
cuda c运行时
运行时在cudart库中被实现,这个库通过静态(cudart.lib或libcudart.a)或动态(cudart.dll或libcudart.so)的方式和应用链接,需用使用cudart.dll或者cudart.so做动态链接的应用经常把它们做为自己安装包的一部分,只有在链接到相同的cuda运行时实例的组件之间进行的cuda运行时符号地址传递才是安全的,另外所有cuda运行时函数的前缀都是cuda。
初始化
运行时库里没有明确的初始化函数,当一个运行时函数(准确地说是除了设备管理或版本管理之外的任何运行时函数)被调用时就会初始化,当我们需要为运行时函数计时或者把第一次调用生成的错误码解释到运行时时要记住这一点。初始化时,运行时会为系统中的每个设备创建cuda上下文,这就是设备的主上下文,它被应用的所有主机线程共享。作为主线程创建过程的一部分,设备代码会被加载到设备内存中,必要时会在加载前作即时编译。所有这一切都是隐式进行的,运行时不会把主上下文暴露给应用。
当一个主机线程调用了cudaDeviceReset()函数,当前主机线程所在的设备主上下文就会随之销毁,此设备上任何主机线程进行下一次运行时函数调用会为这个设备创建一个新主上下文。
设备内存
如前文异构编程中所言,cuda编程模型假设系统由主机和设备组成,两者拥有自己独立的内存。核函数并不直接操作内存,所以运行时提供了分配、回收、复制设备内存的函数,以及在主机内存与设备内存之间迁移数据的函数。
设备内存能够以线性内存或者cuda数组的形式被分配。cuda数组是用来做纹理读取的不透明的内存布局,我们会在纹理和表面内存一节中讲述;线性内存存在于设备中的一个40位的地址空间中,所以独立分配的实体可以通过例如二叉树这样的指针相互引用。线性内存通常使用cudaMalloc()函数分配,用cudaFree()函数回收,主机与设备之间的数据迁移一般用cudaMemcpy()函数进行,在向量加法样例中剩余代码里,向量需要从主机内存复制到设备内存中
// vecAdd.cu
#include
#include
#include
__global__ void VecAdd(float* A, float* B, float* C, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
C[x] = A[x] + B[x];
}
}
int main() {
int N = 10;
size_t size = N * sizeof(float);
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
... // 初始化h_A和h_B,赋值
float* d_A;
float* d_B;
float* d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<>>(d_A, d_B. d_C, N);
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
... // 释放主机内存
} 线性内存也可以通过cudaMallocPitch()和cudaMalloc3D()函数分配,当要分配2维或3维数组时我们推荐使用这两个函数,因为这种分配的填充方式可以近似满足设备内存访问一节描述的对齐要求,从而保证了访问低地址或执行二维数组在设备内存其他区域进行复制(使用cudaMemcpy2D()或cudaMemcpy3D()函数)时的最好表现,返回的行宽或者步长必须被用来分配数组,下面的例子展示了为二维浮点数组分配空间以及如何循环遍历:
int width = 64, height = 64;
float* devPtr;
size_t pitch; // 得到的行宽
cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
__global__ void MyKernel(float* devPtr, size_t pitch, int width, int height) {
for (int r = 0; r < height; r++) {
float* row = (float*)((char*)devPtr + r * pitch); // 每一行
for (int c = 0; c < width; c++) {
float element = row[c];
}
}
}下面是分配并循环三维数组的例子:
int width = 64, height = 64, depth = 64;
cudaExtent extent = make_cudaExtent(width * sizeof(float), height, depth); // 三维数组结构体
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
MyKernel<<<100, 512>>>(devPitchedPtr, width, height, depth);
__global__ void MyKernel(cudaPitchedPtr devPitchedPtr, int width, int height, int depth) {
char* devPtr = devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * height;
for (int z = 0; z < depth; ++z) {
char* slice = devPtr + z * slicePitch;
for (int y = 0; y < height; ++y) {
float* row = (float*)(slice + y * pitch);
for (int x = 0; x < width; ++x) {
float element = row[x];
}
}
}
}参考手册列举了各种用来在cudaMalloc()、cudaMallocPith()和cudaMalloc3D()分配的线性空间、cuda数组和为声明在全局或常量内存中的内存之间进行内存复制的函数。下面的例子描述了通过运行时API访问全局内存变量的各种方法:
__constant__ float constData[256]; // 设备中的常量内存变量,必须写到所有函数外面
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data)); // symbol是指全局或设备内存中的变量,因此这个函数是写入内存函数
cudaMemcpyFromSymbol(data, constData, sizeof(data)); // 读取内存函数
__device__ float devData; // 设备中的全局变量,必须写到所有函数外面
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
__device__ float* devPointer;
float* ptr;
cudaMalloc(&ptr, 256 * sizeof(float));
cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr)); // 必须通过复制设备局部变量的方式为全局变量复制,但它们都是存在设备全局内存中的cudaGetSymbolAddress()用来读取指向分配给全局内存空间中变量的内存地址,分配的内存数可以通过cudaGetSymbolSize()得到
共享内存
我们可以通过使用__shared__内存标识符来为一个变量分配共享内存空间,如线程层次一节中所述,共享内存要比全局内存快得多,只要有机会就应该用共享内存访问代替全局内存访问,我们用下面的矩阵相乘例子来讲述。下面的代码是不使用共享内存来实现的矩阵乘法样例:
typedef struct {
int width;
int height;
float* data;
} Matrix;
#define BLOCK_SIZE 2 // 要确保能被A的高与B的宽整除
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
void MatMaul(const Matrix A, const Matrix B, Matrix C) {
Matrix dA;
dA.height = A.height;
dA.width = A.width;
size_t size = dA.width * dA.height * sizeof(float);
cudaMalloc(&dA.data, size);
cudaMemcpy(dA.data, A.data, size, cudaMemcpyHostToDevice);
Matrix dB;
dB.height = B.height;
dB.width = B.width;
size = dB.width * dB.height * sizeof(float);
cudaMalloc(&dB.data, size);
cudaMemcpy(dB.data, B.data, size, cudaMemcpyHostToDevice);
Matrix dC;
dC.height = C.height;
dC.width = C.width;
size = dC.width * dC.height * sizeof(float);
cudaMalloc(&dC.data, size);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<>>(dA, dB, dC);
cudaMemcpy(C.data, dC.data, size, cudaMemcpyDeviceToHost);
cudaFree(dA.data);
cudaFree(dB.data);
cudaFree(dC.data);
}
__global__ void MatMulKernel(const Matrix A, const Matrix B, Matrix C) {
float value = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = 0; i < A.width; i++) {
value += A.data[row * A.width + i] * B.data[i * B.width + col];
}
C.data[row * C.width + col] = value;
} 这里的矩阵乘法图示如下
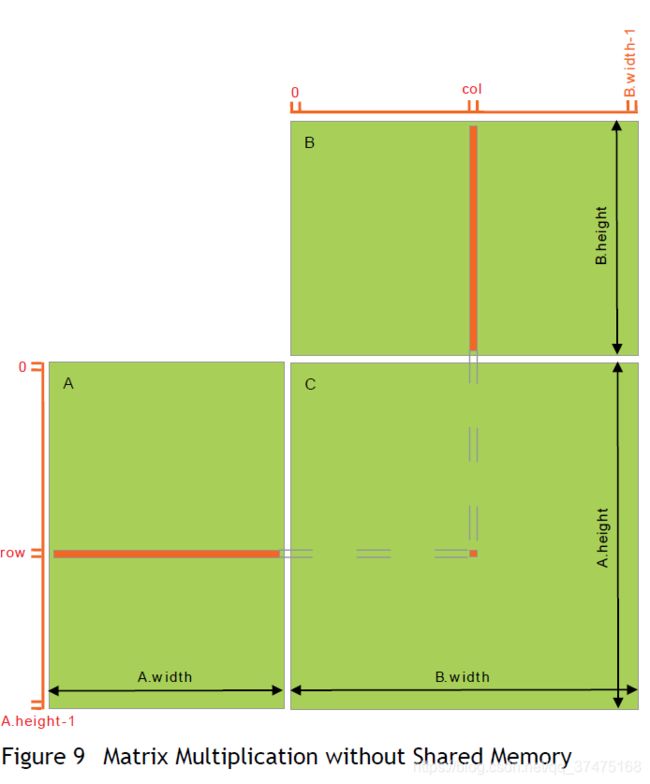
然后我们再写一个使用共享内存的实现,在这个实现中,每一个线程块要计算C中的一个子方阵Csub,如下图所示
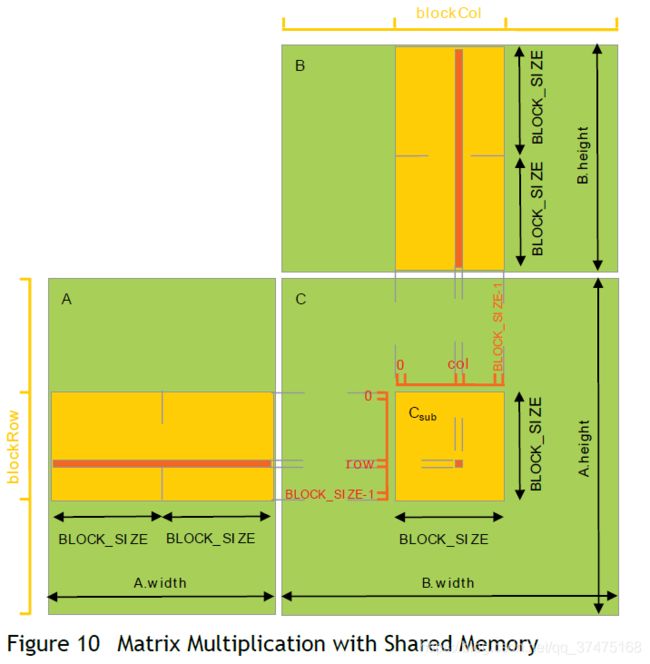
Csub等于A中子矩阵(A.width, block_size)和B中子矩阵(block_size, B.height)的乘积,为了把A和B加载到设备资源中,这两个矩阵被分解成了尽可能多的block_size方阵,因此Csub就是这些方阵的乘积和。每次计算Csub都是先把两个相关的方阵从全局内存中加载到共享内存中,此时每个线程加载每个矩阵的一个元素并计算Csub中的一个元素,然后把结果累加到一个寄存器中,所有的结果计算完成后就把结果写回全局内存里。
typedef struct {
int width;
int height;
int stride; // 遍历步长,其实这里就是行宽
float* data;
} Matrix;
#define BLOCK_SIZE 2 // 子方阵边长,也是线程块边长
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
__device__ float GetElement(const Matrix A, int row, int col) {
return A.data[row * A.stride + col]; // 读元素,注意内存的连续分配
}
__device__ void SetElement(Matrix A, int row, int col, float value) {
A.data[row * A.stride + col] = value; // 写元素
}
__device__ Matrix GetSubMatrix(Matrix A, int row, int col) { // 获取第r行第c列开始的子矩阵,注意这里的r和c都是被子方阵缩放过的
Matrix sub;
sub.width = BLOCK_SIZE;
sub.height = BLOCK_SIZE;
sub.stride = A.stride;
sub.data = &A.data[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col];
return sub;
}
void MatMaul(const Matrix A, const Matrix B, Matrix C) {
Matrix dA;
dA.height = A.height;
dA.width = A.width;
dA.stride = A.width;
size_t size = dA.width * dA.height * sizeof(float);
cudaMalloc(&dA.data, size);
cudaMemcpy(dA.data, A.data, size, cudaMemcpyHostToDevice);
Matrix dB;
dB.height = B.height;
dB.width = B.width;
dB.stride = B.width;
size = dB.width * dB.height * sizeof(float);
cudaMalloc(&dB.data, size);
cudaMemcpy(dB.data, B.data, size, cudaMemcpyHostToDevice);
Matrix dC;
dC.height = C.height;
dC.width = C.width;
dC.stride = C.width;
size = dC.width * dC.height * sizeof(float);
cudaMalloc(&dC.data, size);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<>>(dA, dB, dC);
cudaMemcpy(C.data, dC.data, size, cudaMemcpyDeviceToHost);
cudaFree(dA.data);
cudaFree(dB.data);
cudaFree(dC.data);
}
__global__ void MatMulKernel(const Matrix A, const Matrix B, Matrix C) {
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
float value = 0;
int row = threadIdx.y; // 每个线程处理一个元素,所以线程的块内横纵id就是元素在子矩阵中的位置
int col = threadIdx.x;
for (int i = 0; i < A.width / BLOCK_SIZE; i++) { //遍历A的子矩阵
Matrix Asub = GetSubMatrix(A, blockRow, i);
Matrix Bsub = GetSubMatrix(B, i, blockCol);
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE + 1]; // 子方阵就是一个共享内存
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE + 1];
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
__syncthreads(); // 对多块共享内存IO时要注意同步
for (int j = 0; j < BLOCK_SIZE; j++) {
value += As[row][j] * Bs[j][col];
}
__syncthreads(); // 对多块共享内存IO时要注意同步
}
SetElement(Csub, row, col, value);
} 通过这种块式计算,A只用读取B.width / block_size次全局内存,B只用读取A.height / block_size次,所以大大节省了全局内存的开销
页锁主机内存
运行时提供了使用了页锁主机内存(也称为钉主机)主机内存的函数,这种内存和使用malloc()分配的可分页主存是对立的:
1、cudaHostAlloc()和cudaFreeHost()用来对页锁主机内存进行分配和回收;
2、cudaHostRegister()将指定范围内被malloc()函数分配的内存的分页锁住。
使用页锁内存有以下几个好处:
1、对于一些设备,页锁主机内存和设备内存之间的复制是可以和核函数并发执行的;
2、在一些设备上,页锁主机内存可以被映射到设备上的地址空间中,直接消除了从数据在主机与设备内存之间复制的必要;
3、在有用前端总线的设备上,通过把主机内存分配成页锁内存可以提高主机和设备之间的带宽,如果页锁内存再被分配成写合并,那么带宽会更高。
但是,页锁内存是一种稀缺资源,所以它的分配会比可分页内存的分配失败的更早。另外,减少能够让操作系统分页的内存数量、使用太多的页锁内存会降低系统的整体性能。
可移植内存
一块页锁内存可以和系统中任何设备共存,但是在默认情况下,页锁内存的好处只有和它被分配时所在的设备(以及共享同一块虚拟地址空间的设备,如果有的话)共事时才能体现出上面的优势。为了让所有设备都享有那些好处,需要在分配内存时给cudaHostAlloc()函数传入cudaHostAllocPortable标志,或者调用cudaHostRegister()函数时传入cudaHostRegisterPortable标志
写合并内存
默认情况下被分配的页锁主机内存是可缓存的,它可以通过给cudaHostAlloc()函数传递cudaHostAllocWriteCombined参数被改成写合并内存。写合并内存不会使用主机的L1和L2缓存,从而让应用别的部分有更多的缓存使用。另外,当写合并内存通过PCI传输总线传递数据时,他不会被监视,从而提高了大约40%的传输性能。但是从主机中的写合并内存中读取数据不可避免地缓慢,所以写合并用到只被主机写数据的内存上。
映射内存
一块页锁内存也可以通过给cudaHostAlloc()函数传递标志cudaHostAllocMapped或者给cudaHostRegister()函数传递标志cudaHostRegisterMapped标志被映射到设备内存的内存空间中去,因此这种内存块就有了两个地址:通过cudaHostAlloc()或者malloc()函数返回的主机地址和可以通过cudaHostGetDevicePointer()函数返回的设备地址,故而此内存可以在核函数中被直接访问。只是当主机和设备使用同一块虚拟地址空间时,我们直接使用cudaHostAlloc()返回的地址即可,不必调用cudaHostGetDevicePointer()函数了。
从核函数内直接访问主机内存有以下几个好处:
1、不需要在设备中分配内存然后扎在主机和设备的内存之间来回复制了,此时如果核函数需要数据,会发生隐式地数据传输;
2、将数据传输和核函数执行重叠时不需要使用流了,面向核函数的数据传输会自动和核函数执行重叠。
但是,由于映射页锁内存在主机和设备间是共享的,应用必须使用流或事件同步内存访问,以便避免任何的写后读、读后写、写后写等风险。为了读取任何映射页锁内存的设备地址,页锁内存映射必须在其他任何cuda调用执行前通过调用cudaSetDeviceFlags()并传递cudaDeviceMapHost参数来使能,否则,cudaHostGetDevicePointer()函数会返回一个错误。当然,如果设备压根儿不支持映射页锁内存,cudaHostGetDevicePointer()函数也会返回错误。所以我们要通过查询canMapHostMemory设备属性来检查这项功能是否开启(1表示支持)。
注意,在映射页锁内存上进行的原子函数从主机或设备的角度来说,将不再是原子的。而且,cuda运行时要求对从设备端初始化的内存进行的1字节、2字节、4字节和8字节的自然对齐读写要从主机或设备的角度保留成单向访问,在一些平台上,内存的原子性可能被硬件分解成读操作和写操作,这些操作对自然对齐访问有着同样的保留要求(单向)。例如,cuda运行时就不会支持存在把8字节的自然对齐写分割成主机与设备间的两个4字节写(只能是一个读一个写)的传递桥的PCI传递总线。
异步并发执行
cuda将以下操作暴露为可以和其他任务并发执行的独立任务:
1、主机上的计算;
2、设备上的计算;
3、主机向设备的内存迁移;
4、设备向主机的内存迁移;
5、设备内部的与设备之间的内存迁移。
这些操作能达到并发度将取决于设备的特征集与计算能力
主机与设备间的并发执行
主机并发执行是通过在设备完成指定任务前就把控制权返回给主机线程的异步库函数实现的,使用异步调用时,当合适的设备资源可用是很多的设备操作将被cuda驱动进行排队以待执行。这样就减轻了主机线程很多管理设备的责任,让它能够执行别的任务。对于主机而言,下面的设备操作是异步的:
内核启动、从一个设备内存的数据复制、从主机向设备≤64KB的内存的复制、使用前缀Async的函数进行的复制、内存设置函数的调用
程序员可以通过设置CUDA_LAUNCH_BLOCKING环境变量为1来关闭所有运行在系统上的cuda应用的核函数的异步启动,但这一特征只对调试行为开放,不应该用来让产品软件进行可信赖执行。
除非并发核分析开启,当通过分析器来收集硬件计数器时,核函数将会同步启动。如果内存复制涉及非页锁主机内存的话,也将是异步的
并发核执行
一些计算能力>=2.X的设备可以并发执行多个核函数,应用可以通过检查concurrentKernels属性来看看是否开启了这项功能(1表示开启)。一台设备可以并发执行的最大核启动数量取决于它的计算能力,如下表所示
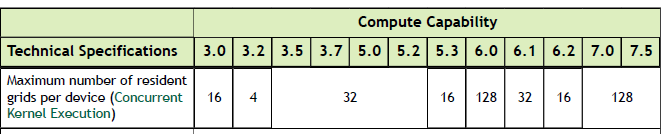
从cuda上下文启动的核不能与另外一个从cuda上下文启动的核并发执行,使用大量纹理或局部内存的核函数也不太可能与其他核函数并发执行。
数据迁移与核执行重叠
一些设备可以将GPU与主机之间的内存复制与核执行并发执行,应用可以通过asyncEngineCount设备属性(>0为支持)来检查此功能是否开启,如果使用这种复制方式涉及的主机内存必须是页锁的。当设备使能concurrentKernels设备属性时可以将设备内复制与核执行并行,如果使能asyncEngineCount时可以将设备内复制与设备外(向设备复制与从设备复制)复制并行,设备内部复制可以通过将标准内存复制函数的源地址与目的地址都设成同一块设备来初始化
并发数据传输
一些计算能力≥2.X的设备可以将设备外复制并行执行,应用可以通过asyncEngineCount设备属性(2为支持)来检查此功能是否开启,如果使用这种复制方式涉及的主机内存必须是页锁的
流
应用通过流来管理上述的并发操作,流是一组有序执行的命令集合(可能由不同的主机线程指定),另一方面,不同的流可能不按彼此间的顺序来执行或者并发执行,这种操作无从保证,因此不能指望它们的正确性(比如,核函数之间的通信是未定义的)
1、创建与销毁:
流通过创建一个流对象并把它指定为核启动与主机-设备间内存复制序列的参数来被定义,以下的代码创建了两个流,并且在页锁内存中分配了一个float数组hostPtr:
cudaStream_t stream[2];
for (int i = 0; i < 2; i++) {
cudaStreamCreate(&stream[i]);
}
float* hostPtr;
int size = 16;
cudaMallocHost(&hostPtr, 2 * size * sizeof(float));下面代码会把每个流创建成从主机向设备的内存复制、核函数启动与从设备向主机的内存复制的工作流:
__global__ void MyKernel(float* dev0Ptr, float* dev1Ptr, int size) {
}
int main() {
.....
float* dev0Ptr;
cudaMalloc(&dev0Ptr, 2 * size * sizeof(float));
float* dev1Ptr;
cudaMalloc(&dev1Ptr, 2 * size * sizeof(float));
for (int i = 0; i < 2; i++) {
cudaMemcpyAsync(&dev0Ptr[i], &hostPtr[i], size * sizeof(float), cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(&dev0Ptr[i], &dev1Ptr[i], size); // <<<>>>内第三个参数为共享内存数
cudaMemcpyAsync(&hostPtr[i], &dev1Ptr[i], size * sizeof(float), cudaMemcpyDeviceToHost, stream[i]);
}
return 0;
}每个流从输入数组hostPtr中将自己的部分粗知道设备内存中的dev0数组中,通过调用MyKernel在设备上处理dev0数组,然后把结果dev1数组复制到hostPtr的对应部分上。重叠行为描述了这个例子中流是怎样根据设备的计算能力进行重叠的,注意这里使用的hostPtr必须指向一块页锁主机内存,以便进行重叠执行。
可以通过调用cudaStreamDestroy()函数销毁流:
cudaStreamDestroy(stream[i]);考虑到当调用cudaStreamDestroy()时设备可能还在做工作,这个函数会立刻返回,当流上的任务全部执行完后,流会自动释放它的资源。
2、默认流:
不指定任何流参数或者设置流参数为0的核启动和主机设备间的内存复制会被分配到默认流上执行,从而会被串行有序执行。对于使用--default-stream per-thread编译选项编译的或者在包含cuda头文件前定义了CUDA_API_PER_THREAD_DEFAULT_STREAM宏的代码,默认流是一个常规流,每个主机线程都会自己的默认流。不指定--default-stream编译参数值时,--default-stream默认为legacy。
- 显式同步:
有几个显式地让流进行彼此间同步的函数:
1)、cudaDeviceSynchronize():等待所有主机线程中所有流的所有前驱命令执行完毕;
2)、cudaStreamSynchronize():需要一个流作为参数,等待其中所有前驱命令完成。此函数可以被用来将主机和指定流进行同步,而允许别的流继续在设备上执行;
3)、3cudaStreamWaitEvent():需要一个流和一个时间作为参数,此函数被调用之后,此后所有被添加到这个流上的命令(调用前添加的不算)会延迟执行,直到指定的事件完成。这个流可以是0号默认流,这时调用cudaStreamWaitEvent()之后添加到所有流上的所有命令都要等待指定的事件完成;
4)、cudaStreamQuery():给应用提供了了解是否指定流上所有的前驱命令都已经完成的方式。
为了避免不必要的降速,所有这些同步函数最好是为了计时或隔离失败的启动或者失败的内存复制来被使用。
- 隐式同步:
当主机线程在不同的流之间执行下列操作中的任何一个,那么来自这些不同的流的两个命令将不能并发执行(也就是如果主机线程在流A上执行命令0,在流B上执行命令1,那么命令0和命令1必须串行执行):
页锁主机内存分配;设备内存分配与设置;同一块内存设备中两个不同地址的内存复制;对NULL流的任何cuda命令;L1和共享内存配置间的切换
对于支持并发核执行并且计算能力<=3.0的设备来说,任何需要进行依赖检查以查看某个使用流的核启动是否完成的操作,只有当cuda上下文中所有前置核启动的所有线程块开始执行之后才能执行,并且阻塞来自任何cuda上下文流的后置核启动,直到被检查的核启动完成。
需要做依赖性检查的操作包含要检查的核启动流上的任何其他命令,以及在那个流上的任何cudaStreamQuery()调用。因此应用需要遵守以下指南来提供他们在并发核执行方面的潜力:
1)、在依赖性操作前,应该执行所有的独立操作;
2)、任何类型的同步应该被尽可能延迟。
3、重叠行为:
两个流之间重叠执行的数量取决于每个流执行的命令的顺序,以及设备是否支持数据迁移与核执行的并发、核并发执行以及并发数据传输。例如,在不支持并发数据传输的设备上,创建与销毁中的样例代码根本不会重叠执行,因为流1发起的从主机向设备的内存复制是在流0发起的从设备向主机的内存复制之后进行的,所以只有流0的从设备向主机的内存复制完成之后,流1的从主机向设备的内存复制才能开始。如果以下面的方式重写代码,并且假设设备支持数据迁移与核执行的重叠的话,那么流1的从主机向设备的内存复制将和流0的核启动重叠执行:
for (int i = 0; i < 2; i++) {
cudaMemcpyAsync(&dev0Ptr[i], &hostPtr[i], size * sizeof(float), cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < 2; i++) {
MyKernel<<<100, 512, 0, stream[i]>>>(&dev0Ptr[i], &dev1Ptr[i], size);
}
for (int i = 0; i < 2; i++) {
cudaMemcpyAsync(&hostPtr[i], &dev1Ptr[i], size * sizeof(float), cudaMemcpyDeviceToHost, stream[i]);
}在支持并发数据传输的设备上,创建与销毁中的样例代码会重叠执行:流1的从主机向设备的内存复制与流0的从设备向主机的内存复制甚至是流0的核启动(假设设备支持数据迁移与核执行的并行)将会重叠执行。但是,对于计算能力<=3.0的设备,核的执行可能并不会重叠,因为流1的核启动是在流0的设备向主机复制内存之后进行的(更是在流0的核启动之后),并且两个核函数都要访问相同的设备内存,所以它会向隐式同步中所描述的一样,等待流0的核启动完成之后再停止自己的阻塞。对于以上的重写代码,假设设备又支持并发的核启动,那么核的执行会重叠,因为流1的核启动是在流0的从设备向主机的内存复制完成之前进行的,但是在这种情况下,流0的设备向主机的内存复制只会和流1核启动的最后一个线程块(占核执行总时间的一小部分)重叠,如隐式同步中所述,这与重写代码前流0和流1核启动不重叠的情况一样,因为流0的设备向主机内存的复制与流1的核启动都访问了设备内存1.
4、回调:
运行时提供了通过cudaStreamAddCallback()函数在任何时间点向一个流中来插入回调的方法,回调是在插入回调前所有被分配到流上的任务执行完之后,才在主机上执行的函数。0号流上的回调会在插入回调前的被分配到所有流上的所有前置任务执行完之后再执行。在下面的例子中,一个回调函数MyCallback被分别插入到了两个流中主机向设备的内存复制、核函数启动和设备向主机内存的复制之后,因此当每个流的设备向主机内存的复制完成之后,这个回调函数就会各执行一次:
void CUDART_CB MyCallback(cudaStream_t stream, cudaError_t status, void *data){
printf("Inside callback %d with status %d\n", (size_t)data, status);
}
....
int main() {
.....
int i;
for (i = 0; i < 2; i++) {
cudaMemcpyAsync(&dev0Ptr[i], &hostPtr[i], size * sizeof(float), cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(&dev0Ptr[i], &dev1Ptr[i], size);
cudaMemcpyAsync(&hostPtr[i], &dev1Ptr[i], size * sizeof(float), cudaMemcpyDeviceToHost, stream[i]);
cudaStreamAddCallback(stream[i], MyCallback, (void*) i, 0);
cudaStreamDestroy(stream[i]);
}
cudaDeviceSynchronize(); // 注册回调后,必须调用另一个cuda函数,否则会阻塞到回调函数里
.....
return 0;
}被分配到一个流上的命令,或者回调被分配到流0上时所有流上的所有命令都不会在回调执行完之前开始执行,cudaStreamAddCallback()函数中的最后一个参数是以备后用的。回调不能直接或间接地调用任何cuda api,因为如果它调用会导致死锁的api时会自行中断阻塞,也就是如果一个函数在等待回调的执行,而这个回调调用了会导致死锁的api,那么等它的这个函数将不会等回调执行完就立刻执行。
5、流优先级:
流的相对优先级可以在创建时通过cudaStreamCreateWithPriority()函数指定,可用的优先级范围可以通过cudaDeviceGetStreamPriorityRange()函数以[最低, 最高]的形式获取,在运行时,高优先级的线程块停止后,第优先级流中的线程才能开始调度。下面代码就是获取优先级返回、指定流优先级的示例
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high); // low为0,high为-2
cudaStream_t st_high, st_low;
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);6、图:
图表达了一种新的cuda任务提交模型,图是由一系列类似核启动这样的操作用依赖相连(依赖的定义要独立于执行),而且允许图的一次定义、重复执行。把图的定义从执行中分离开来可以支持大量的优化:首先,CPU启动图的代价比流要小,因为大部分设置工作已经完成了;第二,向cuda提交整个工作流可以支持流的分段提交工作机制不支持的优化。为了看到这些只可能存在于图中的优化,请考虑流中的这样的场景:当我们把核函数放入流中,主机平台会执行一系列操作以准备在GPU上执行核函数,这些对于设置与启动核函数很有必要的操作就成了提交每个核时必须要付出的代价。对于执行时间较短的GPU核,这种代价可能是整个端到端耗时的主要部分。
使用图的共提交可以被划分为三个主要阶段:定义、实例化、执行。
在定义阶段,程序会在图中创建对操作以及操作间依赖的描述;实例化会取图模板的一个快照,验证之,并且执行启动所需最少的设置与初始化的大部分工作,实例化的结果又称为可执行图;一个可执行图可以被启动到一个流中,就像别的cuda任务一样,可以一次实例化、多次启动。
- 图的结构:
操作对应一个结点,操作间的依赖对应边,这些依赖限制了操作的执行序列。一旦依赖完成,结点对应的操作可以被随时调度,调度就交给cuda系统。
结点类型:进核函数、CPU函数调用、内存复制、memset、空、子图(执行一个独立的嵌套图,如下图中的Y所示)

- 使用图API创建图:
图的创建可以通过两种机制实现:显式API和流捕获,我们以创建并执行下面的图为例:

用图API创建图的代码如下:
cudaGraphCreate(&graph, 0); // 创建空图
cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams); // 创建图结点a、b、c、d
cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);
cudaGraphAddDependencies(graph, &a, &b, 1); // A->B,边的创建也可以在创建结点时进行
cudaGraphAddDependencies(graph, &a, &c, 1); // A->C
cudaGraphAddDependencies(graph, &b, &d, 1); // B->D
cudaGraphAddDependencies(graph, &c, &d, 1); // C->D- 用流捕获创建图:
流捕获提供了一种从现有的基于流的api中创建图的机制,可用cudaStreamBeginCapture()和cudaStreamEndCapture()包裹住将工作放入流中等现有代码,如下所示:
cudaGraph_t graph;
cudaStreamBeginCapture(stream);
kernel_A<<< ..., stream >>>(...);
kernel_B<<< ..., stream >>>(...);
libraryCall(stream);
kernel_C<<< ..., stream >>>(...);
cudaStreamEndCapture(stream, &graph);cudaStreamBeginCapture()的调用将流放入捕获模式下,当流被捕获时,写入流中的工作不会去排队等着执行,而是被追加到一个正在被创建的中间图中,这个图会通过cudaStreamEndCapture()的调用被返回(&graph),同时也会结束流的捕获模式。通过流捕获正在被积极构建的图称之为捕获图。流捕获可以在任何cuda流(cudaStreamLegacy除外,又称为null流)上使用,也可以在cudaStreamPerThread上使用。如果程序正在使用legacy流,它可以把0号流重新定义成per-thread流,同时不改变自己的功能性,请参见默认流部分
1)、跨流的依赖和事件:
流捕获可以处理用cudaEventRecord()和cudaStreamWaitEvent()传递的跨流依赖,只要被等待的事件被记录到了同一张捕获图中。当一个事件被在捕获模式下的流记录的时候,它就成了捕获事件,表示捕获图中的一系列结点。
当一个捕获事件被流所等待,它就会把不处于捕获模式下的等它的流放入捕获模式下,而且流中下一项将会对捕获事件中的结点产生额外的依赖,而后这两条流就都会捕获到一张捕获图中。
当跨流依赖在捕获流中存在时,cudaStreamEndCapture()还是必须被调用cudaStreamStartCature()的流调用,这叫原始流。由于事件依赖的关系,任何其他被捕获到同一张捕获图的流必须加入到原始流的后面。而且,同一张捕获图里的所有捕获流当调用cudaStreamEndCapture()时会退出捕获模式,如果加入原始流失败,整个捕获操作就会随之失败
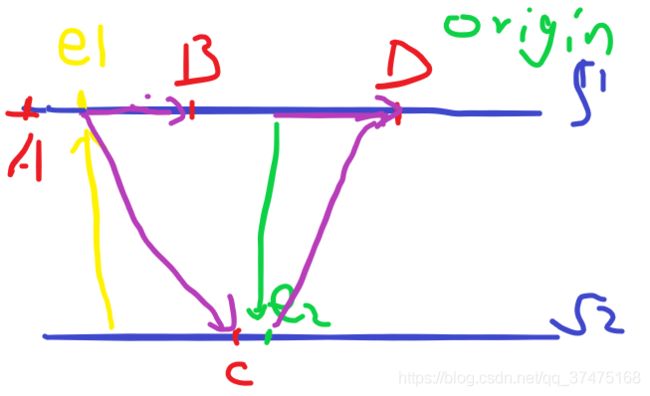
cudaStreamBeginCapture(stream1); // 流1是原始流
kernel_A<<< ..., stream1 >>>(...);
cudaEventRecord(event1, stream1); // 事件1是捕获事件
cudaStreamWaitEvent(stream2, event1); // 流2加入原始流
kernel_B<<< ..., stream1 >>>(...); // 流1执行B
kernel_C<<< ..., stream2 >>>(...); // 流2执行C
cudaEventRecord(event2, stream2); // 流2记录事件2
cudaStreamWaitEvent(stream1, event2); // 流1等待事件2,事件发生后流2并入流1中
kernel_D<<< ..., stream1 >>>(...); // 流1执行D
cudaStreamEndCapture(stream1, &graph); // 流1和流2退出捕获模式得到的图如下所示:
2)、相关的无效操作:
查询正在被捕获的流或事件的执行状态或者对其同步是无效的,因为他们没有展现可以被调度执行的项。对包含任何处于捕获模式下的流的更宽句柄(比如设备、上下文等)进行的同步和状态查询也是无效的。当上下文中存在任何没有使用cudaStreamNoBlocking创建的流正在被捕获时,尝试使用null流也是无效的,这是因为null流总是会包含其他流的引用,加入null流会创建对正在被捕获的流的依赖,对null流的查询或同步也会作用到被捕获的流上。所以在这种情况下使用同步API也是无效的,类似cudaMemcpy()这样的同步API会把任务加入到null流中,并且同步等待api的返回。
如果一个捕获事件来自于一条捕获流,并且这条流与另外一张捕获图相关联,也就是这个捕获事件处一条位于两张捕获图交集的捕获流上,那么通过这个事件来进行两张捕获图的合并,那是无效的。同样无效的还有在捕获流上等待非捕获事件。
把异步操作入队到流中的少量API(例如cudaStreamAttachAsync())目前不支持图,如果被捕获流调用将会返回错误。
3)、失效:
当以上一个失效操作在流捕获期间被尝试执行,相关的任何捕获图就会随之失效。当一个捕获图无效后,对于相关捕获流和捕获事件的后续使用将会无效并且返回一个错误,直到流捕获被cudaStreamEndCapture()中断,这个函数会把相关的流带出捕获模式,但也会返回一个错误和一个NULL图指针。
- 图API的使用:
cudaGraph_t对象不是线程安全的,用户应该保证多个线程不会并发访问一个graph_t对象;cudaGraphExec_t不能和自己并发运行,一个cudaGraphExec_t的启动将在启动同一个可执行图之后进行;和其他异步任务排序时,图的执行将在流中进行,但是这个流只是用来排序的,它不会限制图的内部并行度,也不会影响图结点在哪条流上执行
7、事件:
运行时也提供了近距离监视设备进程和执行准确计时的方法,那就是让应用在程序的任何部分异步记录时间,然后当事件完成后进行查询。当流上的所有前置任务或者命令完成后,事件也就完成了。在0号流上的事件则在所有流上的所有前置任务完成后才会完成
- 创建与销毁:
事件的创建与销毁的代码如下所示:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);- 执行时间:
上面例子中创建的事件可以用下面的方式统计执行时间
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(&dev0Ptr[i * size], &hostPtr[i * size],
size * sizeof(float ), cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<1, 1, 0, stream[i]>>>
(dev0Ptr, dev1Ptr, i * size, size);
cudaMemcpyAsync(&hostPtr[i * size], &dev1Ptr[i * size],
size * sizeof(float ), cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "time: " << elapsedTime << std::endl; // time: 1.1407 单位为毫秒8、同步调用:
当一个同步函数调用时,设备完成指定任务之前是不会把控制权返回给主机线程的。在主机线程执行任何cuda调用前,可以通过调用cudaSetDeviceFlags()并传入具体的参数来开启主机线程在这种情况下是让出控制权(让别的主机线程抢占CPU)、阻塞系统还是自己继续执行。
多设备系统
设备枚举:
一个主机系统可以有多个设备,下面的样例代码展示了如何枚举这些设备、查询他们的属性,并确定支持cuda的设备:
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device);
printf("Device %d has compute capability %d.%d.\n",device, deviceProp.major, deviceProp.minor);
// Device 0 has compute capability 6.1.
}
设备选择
主机线程随时可以通过调用cudaSetDevice()来选择它要操作的设备,设备内存分配和内核启动、流和事件的创建将在当前选择的设备上进行。如果没有调用cudaSetDevice(),那么当前设备就是设备0。
下面的样例代码展示了设置当前设备会怎样影响内存分配与核执行:
size_t size = 1024 * sizeof(float);
cudaSetDevice(0); // 设置设备0为当前设备
float* p0;
cudaMalloc(&p0, size); // 在设备0上分配内存
MyKernel<<<1000, 128>>>(p0); // 在设备0上执行核函数
cudaSetDevice(1); // 设置设备1位当前设备
float* p1;
cudaMalloc(&p1, size); // 在设备1上分配内存
MyKernel<<<1000, 128>>>(p1); // 在设备1上执行核函数流与事件行为
如果核函数被分配到了不属于当前设备上的流时,它就会启动失败,如下所示
cudaSetDevice(0);
cudaStream_t s0;
cudaStreamCreate(&s0); // s0在设备0上
MyKernel<<<100, 64, 0, s0>>>();
cudaSetDevice(1);
cudaStream_t s1;
cudaStreamCreate(&s1); // s1在设备1上
MyKernel<<<100, 64, 0, s1>>>();
MyKernel<<<100, 64, 0, s0>>>(); // 当前设备为设备1,在s0上启动核函数会失败但是,即便把内存分配操作分配到不在当前设备上的流时,它依旧会成功。
如果输入的流和输入事件不在同一台设备上,cudaEventRecord()会失败;如果两个输入的事件不再同一台设备上,cudaEventElapsedTime()会失败;如果输入的事件不属于当前设备,cudaEventSynchronize()和cudaEventQuery()函数依旧成功;如果输入流和输入事件不属于同一台设备,cudaStreamWaitEvent()还是会成功,因此此函数可以被用来多台设备间的同步。
每台设备都有自己的默认流,因此被分配到不同设备上默认流的命令之间会并发执行。
对等结点内存访问
当应用运行在Tesla系列、计算能力>=2.0且为64位的设备上时,它可以对不同设备的内存空间进行取址(例如,在某台设备上运行的核函数可以析构另一台设备上的内存指针)。如果两台设备的cudaDeviceCanAccessPeer()都返回true的话,这种对等结点内存访问特征将在这两台设备上受到支持。
必须通过调用cudaDeviceEnablePeerAccess()函数来在开启与目标设备的对等结点内存访问,如下面代码所示:
cudaSetDevice(0); // 设置设备0为当前设备
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // 在设备0上分配内存
MyKernel<<<1000, 128>>>(p0); // 启动核函数
cudaSetDevice(1); // 设置设备1为当前设备
cudaDeviceEnablePeerAccess(0, 0); // 开启与设备1的对等结点内存访问
MyKernel<<<1000, 128>>>(p0); // 此时可以在设备1上位于设备0内存中的p0了在没有支持NVSwitch的系统上,每个设备可以最大支持8个系统级别的对等连接。如果两台设备上都使用了统一虚地址空间,那么相同的指针就可以被用来指向两台设备上的内存地址。
对等结点内存复制
两台设备间也可以进行内存复制。当两台设备都使用统一地址空间时,对等内存复制可以通过常规内存复制来完成;否则的话,我们就需要使用cudaMemcpyPeer()、cudaMemcpyPeerAsync()、cudaMemcpy3DPeer()或cudaMemcpy3DPeerAsync()来进行了,如下代码所示:
cudaSetDevice(0); // 设置设备0为当前设备
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // 在设备0上分配内存
cudaSetDevice(1); // 设置设备1为当前设备
float* p1;
cudaMalloc(&p1, size); // 在设备1上分配内存
cudaSetDevice(0); // 设置设备0为当前设备
MyKernel<<<1000, 128>>>(p0); // 在设备0上启动核函数
cudaSetDevice(1); // 设置设备1为当前设备
cudaMemcpyPeer(p1, 1, p0, 0, size); // 从p0内存复制到p1
MyKernel<<<1000, 128>>>(p1); // 在设备1上启动核函数默认在null流上进行的不同设备间的内存复制要等到两台设备上所有的前置命令完成之前才会开始,而且两台设备上任何在其之后的命令都要等待内存复制完成之后才能开始。
和流的普通行为一致,两台设备间的内存异步复制可以和其他流上的核函数或复制重叠执行。注意如果两台设备间的对等内存访问通过cudaDeviceEnablePeerAccess()开启了,这两台设备间的内存访问就不需要通过主机进行了,从而更快。
统一虚地址空间
当应用以一个64位进程运行时,主机和所有计算能力>=2.0设备将使用一块地址空间。通过cuda api进行的所有主机内存访问和设备内存访问都会在这个虚地址空间中进行,因此:
1)、通过cuda分配的主机内存位置或使用统一内存空间的设备内存位置都可以通过cudaPointerGetAttributes()函数由指针的值得到;
2)、当和任何使用统一内存空间的设备进行内存复制时,cudaMemcpyXXX()函数的cudaMemcpyKind参数可以设置成cudaMemcpyDefault来通过指针确定位置,即便这个指针时没有使用cuda分配的也没关系,只要要交互的设备使用了统一地址即可;
3)、通过cudaHostAlloc()函数进行的分配是自动可以在所有使用统一内存地址设备间进行移植的,而且此函数返回的指针可以直接在这些设备上的核函数里使用(不需要向在映射内存中记载的那样,通过cudaHostGetDevicePoiner()来获得设备指针了)
应用可以通过检查unifiedAddressing参数(1为使用)来查看某个设备是否使用了统一内存空间,检查方法参见多设备系统中的设备枚举一节
进程间通信
被主机线程创建的任何设备内存指针或事件句柄可以被同一进程中的其他任何线程引用,但是出了这个进程就不行了,也就是不能被别的进程中的线程引用。
为了在进程间共享设备内存指针和事件,应用就必须使用进程间通信的API了,这在参考手册中有详细的介绍。IPC API只支持运行计算能力>=2.0的设备上的64位Linux进程,但是不支持通过cudaMallocManaged()分配的内存。
使用这些IPC API,应用可以使用cudaIpcGetMemHandle()来获取一个给定设备内存指针的IPC句柄,使用标准的IPC机制(共享内存或文件等)来把它传给另一个进程,再使用cudaIpcOpenMemHandle()来从IPC句柄中获取其他进程中有效的指针。事件共享的方法类似。
使用IPC API的一个例子就是当一个主进程生成一批输入数据,可以通过IPC在不进行任何重新生成或者复制的情况下让这些数据对别的子进程可用。
错误检查
所有的运行时函数都会返回一个错误码,但是对于异步函数,这个错误码可能不会报告发生在设备上的错误,因为函数在设备完成任务之前就返回了;错误码只会在任务执行前给主机报告错误,主要是和参数验证相关的错误;如果异步错误发生,它将会通过一些下游不相关的运行时函数调用来进行报告。
在一些异步函数调用之后检查异步错误的唯一方法因此就是同步,通过调用cudaDeviceSynchronize()来进行,或者使用异步并发执行一节中提及的其他同步机制,然后检查cudaDeviceSynchronize()等函数返回的错误码。
运行时为每一个主机线程都分配了一个初始值为cudaSuccess的错误变量,它的值可以在每个错误发生时被修改(要么是异步错误,要么是一个参数验证错误)。cudaPeekAtLastError()函数会返回这个错误,cudaGetLastError()也会返回这个错误,但同时会把错误变量重置为cudaSuccess。
核函数启动不会返回任何错误码,因此cudaPeekAtLastError()或cudaGetLastError()必须在核函数启动后立刻调用来获取任何的预启动错误。为了保证由这两个函数返回的错误不是来源于核函数启动之前的某个操作,我们要确保运行时错误变量在核函数启动前被设置成了cudaSuccess,比如在核函数之前调用cudaGetLastError()。核函数启动是异步的,所以必须在核函数启动和其之后的cudaPeekAtLastError()或cudaGetLastError()调用之间进行同步,以检查这种异步错误。
注意,cudaStreamQuery()和cudaEventQuery()返回的cudaErrorNotReady错误不会被当成一个错误,因此不会被cudaPeekAtLastError()或cudaGetLastError()返回。
调用栈
在计算能力大于等于2.X的设备上,调用栈的大小可以通过cudaDeviceGetLimit()来得到,也可以通过cudaDeviceSetLimit()来设置。当调用栈溢出时,核函数调用就会失败,并且产生一个栈溢出错误(如果使用cuda-gdb、Nsight等cuda调试工具运行应用的话)或者未指定的的启动错误。
纹理内存和表面(surface)内存
cuda支持一种GPU可以用来为图像访问纹理和表面内存的纹理硬件子集,从纹理或表面内存而不是全局内存中读取数据可以有几个性能上的好处,这在设备内存访问中会提到。
两种API可以用来访问纹理和表面内存:所有设备都支持的纹理引用API和只在计算能力为3.x设备上支持的纹理对象API,前者有更多的限制
纹理对象或纹理引用会指定以下属性
| 属性 |
描述 |
| 纹理 |
指定哪块纹理要被获取。纹理对象在运行时创建,而纹理在纹理对象创建时被创建;纹理引用在编译期被创建,但纹理是在纹理引用运行时通过运行时函数被绑定到纹理时被创建的。一些特殊的纹理引用可能被绑定到同一块纹理或者在内存中重叠的纹理上。纹理可以是线性内存中的任何部分或者是一个cuda数组。 |
| 维度 |
维度指明纹理是用一个(两个、三个)纹理坐标表示的一维(二维、三维)数组,数组中的元素称为texels(纹素),是纹理元素texture elements的简称。纹理宽度、高度和深度表示数组在每个维度上的尺寸。 |
| 类型 |
纹理元素的类型受限于基本整型、单精度浮点类型和在char、short、int、long、longlong、float、double中定义的一维、二维和四维向量类型,这些向量定义也来源于整型和单精度浮点类型 |
| 读取模式 |
可取cudaReadModeNormalizedFloat或cudaReadModeElementType。如果是前者,并且元素类型是2字节或单字节整型,被纹理获取返回的值将是浮点数类型,或者全范围整型,但是值域会被映射到[0.0, 1.0]和[-1.0, 1.0]之间,前者针对无符号,后者针对有符号,例如,一个值为0xff的无符号单字节纹理元素会被读成1;如果是后者,就不会有任何转换 |
| 坐标是否被正规化 |
默认情况下,纹理是被定义域为[0, N - 1]的浮点坐标引用的,其中N为与坐标相关的纹理维度最大值。例如,尺寸为64 * 32的纹理的坐标范围就是([0, 63], [0, 31])。正规化的坐标会导致坐标被映射到[0.0, 1.0 - 1 / N]而不是[0, N - 1],所以同一个64 * 32的纹理会被范围为([0.0, 1.0 - 1 / 64], [0.0, 1.0 - 1 / 31])的正规化坐标引用。正规化坐标可以天然适应某些应用的要求,特别是要求纹理坐标独立于纹理大小的情况下 |
| 取址模式 |
当坐标超出定义域时,调用纹理函数依旧是有效的,其结果取决于取址模式。默认的取址模式是把坐标固定到定义域中:非正规化为[0, N),正规化为[0.0, 1.0)。如果边界模式被指定,读取坐标超出定义域的纹理会返回0。对于正规化的坐标,我们还可以使用包裹模式和镜像模式。当使用包裹模式时,每个坐标x会被转换成x * floor(x),floor(x)表示不超过x的最大整数;当使用镜像模式时,坐标x会根据floor(x)的奇偶性进行转换:若为偶数,则为x * floor(x),否则就是 1 - x * floor(x)。取址模式通过一个三维数组表示,每个元素表示每个纹理坐标维度的取址模式,可用的有cudaAddressModeBorder、cudaAddressModeClamp、cudaAddressModeWrap和cudaAddressModeMirror,后两个只支持正规化的纹理坐标 |
| 过滤模式 |
过滤模式指定读取纹理时返回值是怎么基于输入的纹理坐标计算的。线性纹理过滤只适用于配置为返回浮点类型数据的纹理,它在相邻纹理元素间执行低精度的插值。当使用线性纹理过滤时,首先会读取纹理获取坐标附近的纹理元素,然后会纹理获取的返回值会根据落在这些纹理元素之间的坐标进行插值运算得到。 一维纹理会执行线性插值;二维纹理会执行双线性插值;三维纹理会进行三线性插值。纹理获取一节会更进行详细的介绍。 过滤模式可以取cudaFilterModePoint或cudaFilterModeLinear。如果是前者,返回值将是坐标最接近输入纹理坐标的纹理元素;如果是后者,返回值将是一维(二维、三维)纹理的2(4、8)个坐标最接近输入纹理坐标的线性插值结果,但是这种模式只支持浮点类型的返回值。 |
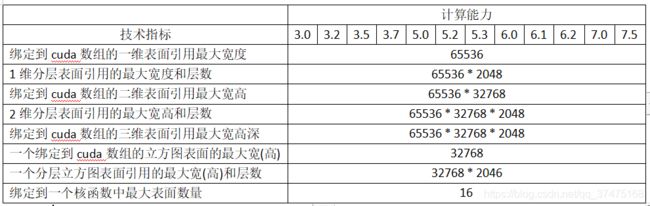
下表列举了不同计算能力的设备支持的最大纹理宽度、高度和深度:
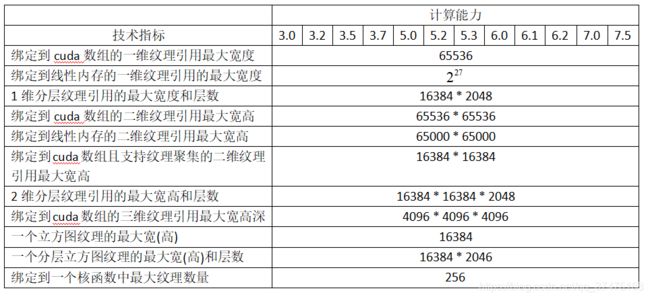
关于char、short、int、long、longlong、float、double中定义的一维、二维和四维向量的的定义如下:来源于整型和浮点类型的向量类型是结构体,其第1、2、3、4个元素可以通过字段x、y、z和w得到。这些向量都通过形如make_
纹理对象API
纹理对象通过cudaResourceDesc类型结构体的资源描述符的cudaCreateTextureObject()方法创建,这种结构体指定了纹理的属性,其内容如下:
struct cudaTextureDesc
{
enum cudaTextureAddressMode addressMode[3]; // 取址模式
enum cudaTextureFilterMode filterMode; // 过滤模式
enum cudaTextureReadMode readMode; // 读取模式
int sRGB;
int normalizedCoords; // 是否正规化坐标
unsigned int maxAnisotropy;
enum cudaTextureFilterMode mipmapFilterMode;
float mipmapLevelBias;
float minMipmapLevelClamp;
float maxMipmapLevelClamp;
}; // sRGB、maxAnisotropy等字段请参考手册下面的代码把简单的转换核函数应用到了纹理上:
#include
#include
__global__ void transformKernel(float *output, cudaTextureObject_t texObj, int width, int height, float theta) {
unsigned int x = blockIdx.x * blockIdx.x + threadIdx.x;
unsigned int y = blockIdx.y * blockIdx.y + threadIdx.y;
float u = x / (float) width - 0.5f;
float v = y / (float) height - 0.5f;
float tu = u * cosf(theta) - v * sinf(theta) + 0.5f; // cuda采样时会偏移5像素,因此要偏移回去
float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
output[y * width + x] = tex2D(texObj, tu, tv);
}
int main() {
cudaChannelFormatDesc desc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat); // 创建cuda数组需要用到管道,这里采用float类型的,向量为(32, 0, 0, 0),也就是只有x方向上有4个字节
cudaArray *cudaArray;
int width = 5, height = 2;
int size = width * height;
float *h_data = (float *) malloc(size * sizeof(float));
for (int i = 0; i < size; i++) { // 初始化数据
h_data[i] = i;
}
printf("data initialized.\n");
cudaMallocArray(&cudaArray, &desc, width, height); // 分配cuda数组
cudaMemcpyToArray(cudaArray, 0, 0, h_data, size, cudaMemcpyHostToDevice); // 从主机复制数组给cuda数组
struct cudaResourceDesc resDesc; // 资源描述符定义
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array.array = cudaArray;
struct cudaTextureDesc texDesc; // 纹理描述符定义
memset(&texDesc, 0, sizeof(texDesc));
texDesc.addressMode[0] = cudaAddressModeWrap;
texDesc.addressMode[1] = cudaAddressModeWrap;
texDesc.filterMode = cudaFilterModeLinear;
texDesc.readMode = cudaReadModeElementType;
texDesc.normalizedCoords = 1;
cudaTextureObject_t texObj = 0; // 纹理对象创建
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
printf("Texture object created.\n");
float* output;
cudaMalloc(&output, size * sizeof(float ));
dim3 dimBlock(16, 16);
dim3 dimGrid((width + dimBlock.x - 1) / dimBlock.x, (height + dimBlock.y - 1) / dimBlock.y);
printf("Ready to call kernel.\n");
transformKernel<<>>(output, texObj, width, height, 0.5f); // 调用核函数
float *h_result = (float *) malloc(size * sizeof(float));
cudaMemcpy(h_result, output, size * sizeof(float), cudaMemcpyDeviceToHost); // 复制结果到主机
printf("Kernel is finished and here`s the result:\n");
for (int i = 0; i < size; i++) {
printf("%f\n", h_result[i]);
}
cudaDestroyTextureObject(texObj); // 释放资源
cudaFreeArray(cudaArray);
cudaFree(output);
return 0;
} 输出如下:
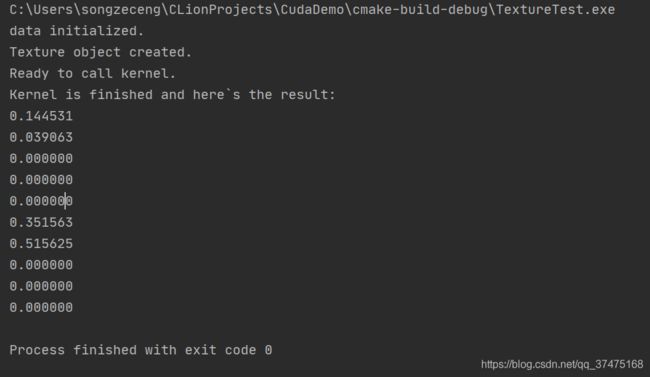
纹理引用API
纹理引用的一些属性是不可改变的,并且必须在编译期确定,因此必须在声明纹理引用时指定。一个此文件可用的纹理引用可以被定义成纹理类型的变量:
texture texRef; 其中,DataType指定纹理元素的类型;Type指定纹理引用的类型(cudaTextureType1D、cudaTextureType2D、cudaTextureType3D、cudaTextureType1DLayered和cudaTextureType2DLayered,分别对应一维、二维、三维、分层一维和分层二维的纹理),默认值为cudaTextureType1D;ReadMode指定了读取模式,默认值为cudaReadModeElementType。纹理引用只能被声明为静态全局变量,不能作为参数传给函数。
纹理引用的其他属性是可改变的,其值可以在主机运行时被修改。根据参考手册中的记载,运行时API有一个低级的C风格接口和一个高级的C++风格接口。而纹理类型是作为一种公有结构体在高级API中被定义,而这种公有结构体来源于低级API中的textureReference类型,其定义如下:
struct __device_builtin__ textureReference
{
int normalized; // 纹理坐标是否正规化,可在主机代码中直接修改
enum cudaTextureFilterMode filterMode; // 过滤模式,可在主机代码中直接修改
enum cudaTextureAddressMode addressMode[3]; // 取址模式,可在主机代码中直接修改
struct cudaChannelFormatDesc channelDesc; // 纹理元素格式,必须和纹理引用声明时的DataType参数匹配。这个字段的类型如下:
/*
struct __device_builtin__ cudaChannelFormatDesc
{
int x; // x、y、z、w对应四维向量类型的每一维的字节数量,请参见上文纹理内存的属性表部分
int y;
int z;
int w;
enum cudaChannelFormatKind f; // cudaChannelFormatKindSigned(纹理元素为有符号整型)、cudaChannelFormatKindUnsigned(纹理元素为无符号整型)、cudaChannelForamtKindFloat(纹理元素为浮点型)
};
*/
int sRGB;
unsigned int maxAnisotropy;
enum cudaTextureFilterMode mipmapFilterMode;
float mipmapLevelBias;
float minMipmapLevelClamp;
float maxMipmapLevelClamp;
int __cudaReserved[15];
};在核函数可以使用纹理引用来从纹理内存中读取数据之前,纹理引用必须通过cudaBindTexture()或cudaBindTexture2D()来绑定一块线性内存,或者使用cudaBindTextureToArray()来绑定一个cuda数组。cudaUnbindTexture()用来为纹理引用解绑,纹理引用解绑后可以安全地绑定到新的数组上,即便使用老的绑定纹理的核函数还没有完成。我们建议使用cudaMallocPitch()在线性空间中分配二维纹理,然后把此函数返回的对象作为参数传递给cudaBindTexture2D()。下面的代码简单地把一个二维纹理引用绑定到了devPtr指向的线性内存中:
- 低级API:
texture texRef;
const textureReference *texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc desc = cudaCreateChannelDesc();
float *devPtr;
size_t pitch;
cudaMallocPitch((void **) &devPtr, &pitch, width * sizeof(float), height);
size_t offset;
cudaBindTexture2D(&offset, texRefPtr, devPtr, &desc, width, height, pitch); - 高级API:
texture texRef;
cudaChannelFormatDesc desc = cudaCreateChannelDesc();
float *devPtr;
size_t pitch;
cudaMallocPitch((void **) &devPtr, &pitch, width * sizeof(float), height);
size_t offset;
cudaBindTexture2D(&offset, texRef, devPtr, desc, width, height, pitch); 下面的例子把一个二维纹理引用绑定到了cuda数组cuArray上:
- 低级API:
texture texRef;
const textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc desc;
cudaArray *cudaArray;
cudaMallocArray(&cudaArray, &desc, width, height);
cudaGetChannelDesc(&desc, cudaArray);
cudaBindTextureToArray(texRef, cudaArray); - 高级API:
cudaChannelFormatDesc desc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat);
cudaArray *cudaArray;
cudaMallocArray(&cudaArray, &desc, width, height);
texture texRef;
cudaBindTextureToArray(texRef, cudaArray); 把纹理绑定到纹理引用时指定的格式必须和纹理引用声明时的DataType参数匹配,否则纹理获取的结果就不得而知。每个核函数可以绑定的纹理数量如下表所示

下面的代码同样是使用核函数对纹理进行简单的转换:
#include "cuda_runtime.h"
#include "texture_fetch_functions.h"
#include
void textureObjTest();
void bindTextureRef();
int width = 5, height = 2;
int size = width * height;
float *h_data = (float *) malloc(size * sizeof(float));
texture texRef;
__global__ void transformKernelRef(float *output, int width, int height, float theta) {
unsigned int x = blockIdx.x * blockIdx.x + threadIdx.x;
unsigned int y = blockIdx.y * blockIdx.y + threadIdx.y;
float u = x / (float) width - 0.5f;
float v = y / (float) height - 0.5f;
float tu = u * cosf(theta) - v * sinf(theta) + 0.5f;
float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
output[y * width + x] = tex2D(texRef, tu, tv);
}
int main() {
bindTextureRef();
return 0;
}
void bindTextureRef() {
cudaChannelFormatDesc desc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat);
for (int i = 0; i < size; i++) {
h_data[i] = i;
}
cudaArray *cudaArray;
cudaMallocArray(&cudaArray, &desc, width, height);
cudaMemcpyToArray(cudaArray, 0, 0, h_data, size, cudaMemcpyHostToDevice);
texRef.addressMode[0] = cudaAddressModeWrap;
texRef.addressMode[1] = cudaAddressModeWrap;
texRef.filterMode = cudaFilterModeLinear;
texRef.normalized = 1;
cudaBindTextureToArray(texRef, cudaArray);
float *output;
cudaMalloc(&output, size * sizeof(float));
dim3 dimBlock(16, 16);
dim3 dimGrid((width + dimBlock.x - 1) / dimBlock.x, (height + dimBlock.y - 1) / dimBlock.y);
printf("Ready to call kernel.\n");
transformKernelRef<<>>(output, width, height, 0.5f);
float *h_result = (float *) malloc(size * sizeof(float));
cudaMemcpy(h_result, output, size * sizeof(float), cudaMemcpyDeviceToHost);
printf("Kernel is finished and here`s the result:\n");
for (int i = 0; i < size; i++) {
printf("%f\n", h_result[i]);
}
cudaFreeArray(cudaArray);
cudaFree(output);
} 输出结果和使用纹理对象的一样
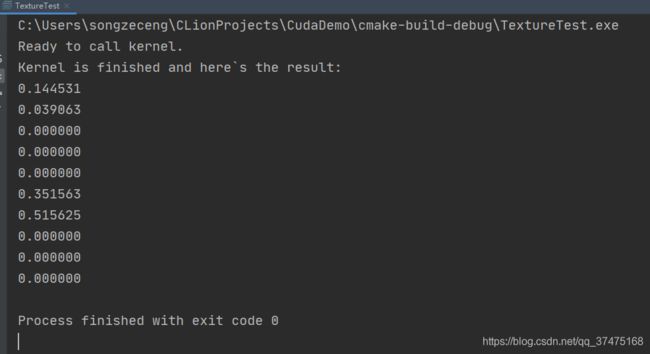
两字节浮点纹理
cuda数组支持的两字节浮点或半(half)格式和IEEE 754-2008的binary2format格式一样。cuda c不支持匹配数据类型,但是提供了指令级函数来通过无符号短整型进行四字节浮点类型的纹理和两字节纹理之间的转换,这些函数有__float2half_rn(float)和__half2float(unsigned short)。这些函数只能在设备代码中使用,主机代码中的等价函数可以在OpenEXR库中找到。
在执行纹理获取的过滤前,两字节浮点元素应该被转换成四字节浮点数。另外,可以通过cudaCreateChannelDescHalfXX()系列函数来创建两字节浮点格式的通道描述符。
分层纹理
一维二维分层纹理(在Direct3D中也称为纹理数组,OpenGL中则是数组纹理)是由一系列层组成的纹理,所有层的纹理都是维度、大小和数据类型一致的常规纹理,只在计算能力>=2.0的设备上支持。一维的分层纹理通过一个整数索引和一维浮点数纹理坐标来取址,前者表示层数,后者表示层内坐标;二维分层纹理通过一个整数索引和二维浮点数坐标取址,前者表示层数,后者表示层内坐标。
分层纹理只能是一个cuda数组,通过给cudaMalloc3DArray()函数传递cudaArrayLayered标志创建,如果是一维分层纹理的话,高度参数为0。在设备函数中获取分层纹理可以参见官方手册中tex1DLayered()和tex2DLayered()函数,纹理过滤(参见官方手册纹理获取)只能在层内进行,而不能跨层进行。
立方图纹理
立方图纹理是一种特殊的二维分层纹理,这种纹理有六层,分别表示立方图的每个面,而层的宽度等于其高度;
立方图使用三个纹理坐标x、y、z来取址,这三个坐标可以被解释为以立方体中心为原点,指向立方体某一面和和那个面对应的层上的某一纹理元素的方向向量。更具体地,面的选择方法为:选择坐标中的最大值m,然后使用坐标(s / m + 1) / 2和(t / m + 1) / 2来对对应的层进行取址,m、s和t的取值以及面的选择如下表所示:

- 立方图分层纹理:
立方图分层纹理(只支持计算能力>=2.0的设备)是一种泛化的立方图纹理,唯一的区别就是立方图分层纹理的层数不固定,但每层还是一个立方体。它可以使用一个整型索引和三个浮点纹理坐标来取址,前者表示层数,后者表示层内的坐标。
这种立方图分层纹理只能是一个cuda数组,通过给cudaMalloc3DArray()函数传递cudaArrayCubemap标志和cudaArrayLayered标志创建,其在设备函数中可通过texCubemapLayered()函数进行获取,纹理过滤(参见官方手册纹理获取部分)只能在层内进行,而不能跨层进行。
纹理聚集
纹理聚集是一种特殊的纹理获取,只能用在二维纹理上,可通过tex2Dgather()函数进行,其参数只比tex2D()函数多了一个com参数(可取0、1、2、3)。这个函数返回四个四字节的数,每一个数对应四个已经在常规纹理获取时用来做双线性过滤的纹理元素之一的由comp参数指定的向量元素。比如,如果这些文理元素的值为(253, 20, 31, 255)、(250, 25, 29, 254)、(249, 16, 37, 253)和(251, 22, 30, 250),当comp = 2时,tex2Dgather()函数会返回(31,29, 37, 30)。
注意纹理坐标只能和精确到小数点后8位的参数正常工作,因此如果tex2D()函数使用1.0作为其参数之一的话(α或β),tex2Dgather()函数可能返回异常值。例如,当纹理坐标x为2.49805,xB = x - 0.5 = 1.99805,但是xB的小数部分是以固定八位的格式存储的,因此0.99805更接近256.f / 256.f,而不是255.f / 256.f,因此xB的值就是2。tex2Dgather在这种情况下会返回x坐标2和3,而非1和2.
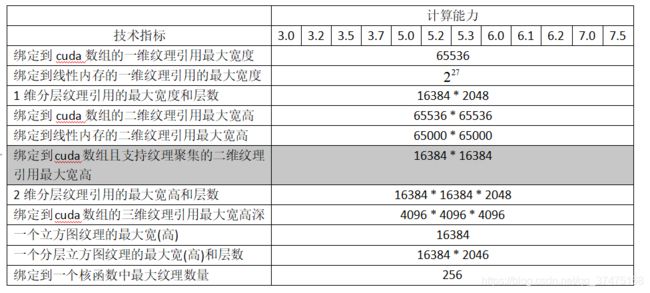
纹理聚集只支持用cudaArrayTextureGather标志创建的cuda数组(以及计算能力>=2.0的设备),并且其宽高最大值要小于下表所示的值,这些值要比常规的纹理获取要小。
表面内存
对计算能力≥2.0的设备来说,用cudaArraySurfaceLoadStore标志创建的cuad数组可以通过表面对象或者表面引用相关的函数进行读写,下表列举了不同计算能力的设备的最大宽高和深度:
- 表面对象API:
使用类型为struct cudaResourceDesc的资源描述符的cudaCreateSurfaceObject()函数创建的是表面对象,下面的代码把简单的转换应用到了纹理中:
#include "texture_fetch_functions.h"
#include "surface_indirect_functions.h"
#include
int width = 5, height = 2;
int size = width * height;
float *h_data = (float *) malloc(size * sizeof(float));
texture texRef;
__global__ void transformKernelSurfaceObj(cudaSurfaceObject_t inputSurObj, cudaSurfaceObject_t outputSurObj, int width, int height) {
unsigned int x = blockIdx.x * blockIdx.x + threadIdx.x;
unsigned int y = blockIdx.y * blockIdx.y + threadIdx.y;
if (x < width && y < height) {
uchar4 data;
surf2Dread(&data, inputSurObj, 4 * x, y); // 把数据从inputSurObj读到data中
// 4 * x是因为每个线程读取的数据data,要按4字节排列到表面内存中(uchar4大小就是四字节)
surf2Dwrite(data, outputSurObj, 4 * x, y); // 把数据从data写到outputObj中
}
}
int main() {
for (int i = 0; i < size; i++) {
h_data[i] = i;
}
// 分配cuda数组
cudaChannelFormatDesc des = cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned);
cudaArray* cuInputArray;
cudaMallocArray(&cuInputArray, &des, width, height, cudaArraySurfaceLoadStore);
cudaArray* cuOutputArray;
cudaMallocArray(&cuOutputArray, &des, width, height, cudaArraySurfaceLoadStore);
cudaMemcpyToArray(cuInputArray, 0, 0, h_data, size * sizeof(float), cudaMemcpyHostToDevice);
// 配置表面内存
struct cudaResourceDesc resourceDesc;
memset(&resourceDesc, 0, sizeof(resourceDesc));
resourceDesc.resType = cudaResourceTypeArray;
resourceDesc.res.array.array = cuInputArray;
cudaSurfaceObject_t cuInputObj = 0, cuOutputObj = 0;
cudaCreateSurfaceObject(&cuInputObj, &resourceDesc);
resourceDesc.res.array.array = cuOutputArray;
cudaCreateSurfaceObject(&cuOutputObj, &resourceDesc);
// 调用核函数
dim3 blockDim(16, 16);
dim3 gridDim((width + blockDim.x - 1) / blockDim.x, (height + blockDim.y - 1) / blockDim.y);
transformKernelSurfaceObj<<>>(cuInputObj, cuOutputObj, width, height);
// 把结果复制到主机中
float *h_result = (float *) malloc(size * sizeof(float));
cudaMemcpyFromArray(h_result, cuOutputArray, 0, 0, size * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < size; i++) {
printf("%f\n", h_result[i]);
}
// 释放资源
cudaDestroySurfaceObject(cuInputObj);
cudaDestroySurfaceObject(cuOutputObj);
cudaFreeArray(cuInputArray);
cudaFreeArray(cuOutputArray);
return 0;
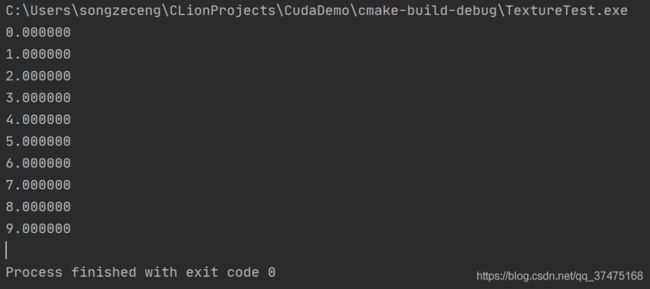
} 运行结果如下

表面引用API
当前文件可用的表面引用可以通过surface类型的变量声明:surface
- 低级API:
const surface surfRef;
const surfaceReference* surRefPtr;
cudaGetSurfaceReference(&surRefPtr, "surRef");
cudaChannelFormatDesc desc;
cudaArray* cuArray;
cudaGetChannelDesc(&desc, cuArray);
cudaBindSurfaceToArray(surfRef, cuArray); - 高级API:
cudaArray* cuArray;
cudaChannelFormatDesc des = cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned);
cudaMallocArray(&cuArray, &des, width, height, cudaArraySurfaceLoadStore);
surface surfRef;
cudaBindSurfaceToArray(surfRef, cuArray); cuda数组必须使用维度和类型匹配的表面函数和维度匹配的表面引用来进行读写,否则读写的结果就会有异常。
不像纹理内存,表面内存使用字节取址,这意味着通过纹理函数访问纹理元素时使用的x坐标需要被元素的字节大小整除(这也是为何我在transformKernelSurfaceObj()函数中使用4 * x来定位数据的原因),以便通过表面函数来访问这个纹理元素。比如,一个一维浮点cuda数组的某个元素的纹理坐标为x,而且此元素和纹理引用texRef、表面引用surfRef进行了绑定,所以应该通过tex1d(texRef, x)和surf1Dread(surfRef, x * 4)分别从texRef和surfRef中读取此数据。类似地,某二维浮点cuda数组中的某个元素纹理坐标为(x, y),而且此元素和纹理引用texRef、表面引用surfRef进行了绑定,所以应该通过tex2d(texRef, x, y)和surf2Dread(surfRef, x * 4, y)分别从texRef和surfRef中读取此数据(y坐标的字节偏移量会通过cuda数组的对应行自动计算)。下面代码也是通过核函数进行简单的复制,但使用的是表面绑定机制:
#include "cuda_runtime.h"
#include "texture_fetch_functions.h"
#include "surface_indirect_functions.h"
#include "surface_functions.h"
#include
int width = 5, height = 2;
int size = width * height;
float *h_data = (float *) malloc(size * sizeof(float));
const surface inputSurf, outputSurf;
__global__ void transformKernelSurfaceRef(int width, int height) {
unsigned int x = blockIdx.x * blockIdx.x + threadIdx.x;
unsigned int y = blockIdx.y * blockIdx.y + threadIdx.y;
if (x < width && y < height) {
uchar4 data;
surf2Dread(&data, inputSurf, 4 * x, y);
surf2Dwrite(data, outputSurf, 4 * x, y);
}
}
int main() {
for (int i = 0; i < size; i++) {
h_data[i] = i;
}
// 分配cuda数组
cudaChannelFormatDesc des = cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned);
cudaArray* cuInputArray;
cudaMallocArray(&cuInputArray, &des, width, height, cudaArraySurfaceLoadStore);
cudaArray* cuOutputArray;
cudaMallocArray(&cuOutputArray, &des, width, height, cudaArraySurfaceLoadStore);
cudaMemcpyToArray(cuInputArray, 0, 0, h_data, size * sizeof(float), cudaMemcpyHostToDevice);
// 绑定表面引用
cudaBindSurfaceToArray(inputSurf, cuInputArray);
cudaBindSurfaceToArray(outputSurf, cuOutputArray);
// 执行核函数
dim3 blockDim(16, 16);
dim3 gridDim((width + blockDim.x - 1) / blockDim.x, (height + blockDim.y - 1) / blockDim.y);
transformKernelSurfaceRef<<>>(width, height);
// 复制结果到主机
float *h_result = (float *) malloc(size * sizeof(float));
cudaMemcpyFromArray(h_result, cuOutputArray, 0, 0, size * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < size; i++) {
printf("%f\n", h_result[i]);
}
// 释放资源
cudaFreeArray(cuInputArray);
cudaFreeArray(cuOutputArray);
return 0;
} 运行结果如下:
立方图表面
使用surfCubemapred()和surfCubemapwrite()函数可以把立方图表面内存作为二维分层表面来访问,也就是说使用整数索引表示面、二维浮点纹理坐标表示和这个面对应的层上纹理元素的坐标,面的排序方法如下表所示(和立方图纹理中的方法一样)

分层立方图表面:
通过surfCubemapLayeredRead()和surfCubemapLayeredWrite()函数可以把分层立方图表面当成二维分层表面来访问,也就是说使用一个整数表示某一立方图的某个面,二维浮点纹理坐标来定位和这个面对应的层上的纹理元素,面的排序方法和立方图表面一样。比如索引(2 * 6) + 3就表示第3个立方图(cubemap 2)的第4张面(face 4)
cuda数组
cuda数组是为纹理获取优化的不透明内存布局,他们可以是一维、二维或三维的,由拥有单字节、双字节或四字节无符号整数(或者是双字节、四字节浮点数)组成的1、2、4维向量的元素组成,一维向量元素对应单字节整数和双字节浮点数,二维向量对应双字节整数和浮点数,三维向量对应四字节整数和浮点数。cuda数组只能通过核函数的纹理获取或表面内存的读写来访问,具体请参见上两小节。
读写一致性
纹理和表面内存是缓存的,在同一个核函数调用中,涉及全局内存写和表面内存写的缓存不会保持一致性,所以在同一核函数调用中对已经通过全局写或表面写的地址进行纹理读和表面读的话,会返回未知值。换言之,只有某内存位置被之前的核函数调用或内存复制更新(而非被同一核函数的任何调用更新)之后,一个线程才可以安全地进行纹理或表面读取。
所以在上面写过的几个纹理或表面内存核函数中,我要么是只对纹理内存或表面内存读,要么是读写不同的内存地址,但是内存地址的纹理坐标都是一致的,故而保证了读写一致性。
图形交互性
一些来自OpenGL、Direct3D这种源的资源可以被映射到cuda的地址空间中,从而支持cuda读取被OpenGL或Direct3D写入的数据或者写入可以被OpenGL或Direct3D消费的数据。
在可以使用和OpenGL或Direct3D交互的函数之前,这种资源必须现在cuda中注册。那些交互函数会返回一个指向cuda图像的struct cudaGraphicsResource类型的指针,而注册资源是代价昂贵的,因此每个资源只能注册一次,另外可以通过cudaGraphicsUnregisterResource()函数来为资源注销。每个要使用资源的cuda上下文都需要对资源单独注册。
一旦一个资源被注册到了cuda中,它就可以多次映射和去映射,通过使用cudaGraphicsMapResources()和cudaGraphicsUnmapResources()函数,cudaGraphicsResourcesSetMapFlags()函数可以指明cuda驱动用来优化资源管理的资源访问权限(只读、只写等)。
映射好的资源可以通过使用设备内存地址在核函数中进行读写,这种设备内存地址可以通过cudaGraphicsResourcesGetMappedPointer()或者cudaGraphicsSubResourcesGetMappedArray()函数返回得到,前者对应缓存的地址,后者对应cuda数组的地址。
通过未注册的cuda上下文或者OpenGL、Direct3D直接访问映射好的资源会产生未知结果。
OpenGL交互性
可以被映射到cuda地址空间的OpenGL资源有OpenGL缓存、纹理和渲染缓存(renderbuffer)对象。缓存对象可以通过cudaGraphicsGLRegisterBuffer()函数注册,在cuda中它表现为设备指针,因此可以通过核函数或者cudaMemcpy()函数进行读写;纹理或者渲染缓存对象通过cudaGraphicsGLRegisterImage()函数注册,在cuda中它们表现为绑定到纹理或表面引用的cuda数组,如果在注册时使用了cudaGraphicsRegisterFlagsSurfaceLoadStore标志的话,它们就可以通过表面写函数来写了。这些数组也可以通过cudaMemcpy2D()函数进行读写。cudaGraphicsGLRegisterImage()函数支持一维、二维或四维向量的纹理和OpenGL的浮点类型(GL_RGBA_FLOAT32等)、正规化整数(GL_RGDA8、GL_INTENSITY16等)和非正规化整数(GL_RGBA8UI),注意因为非正规化整数格式要求OpenGL版本为3.0,那么它们只能通过着色器(shaders)而不是固定函数流程(fixed function pipeline)来进行写。
资源正在被着色的OpenGL上下文必须是当前使用OpenGL交互API的主机线程。注意,当一个OpenGL纹理是无绑定(bindless)创建时(比如通过glGetTextureHandleX/glGetImageHandleX系列API请求纹理或图像句柄时)的,那它不能在cuda中注册,我们需要在请求纹理或图像句柄前为纹理进行交互注册。下面的代码使用核函数动态修改一个存储在结点缓存对象中的尺寸为width * height的二维网格:
GLuint positionsVBO;
struct cudaGraphicsResource* positionsVBO_CUDA;
int main() {
.....
// 为设备0初始化OpenGL和GLUT,并设置OpenGL的上下文为当前上下文
glutDisplayFunc(display);
// 明确使用设备0
cudaSetDevice(0);
// 创建buffer对象,并在cuda中注册
glGenBuffers(1, &positionsVBO);
glBindBuffer(GL_ARRAY_BUFFER, positionsVBO);
unsigned int size = width * height * 4 * sizeof(float);
glBufferData(GL_ARRAY_BUFFER, size, 0, GL_DYNAMIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
cudaGraphicsGLRegisterBuffer(&positionsVBO_CUDA, positionsVBO, cudaGraphicsMapFlagsWriteDiscard);
// 启动渲染循环
glutMainLoop();
...
}
void display() {
// 映射cuda要写入的缓存对象
float4* positions;
cudaGraphicsMapResources(1, &positionsVBO_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions, &num_bytes, positionsVBO_CUDA));
// 执行核函数
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<>>(positions, time, width, height);
// 缓存对象去映射
cudaGraphicsUnmapResources(1, &positionsVBO_CUDA, 0);
// 从缓存对象中渲染
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glBindBuffer(GL_ARRAY_BUFFER, positionsVBO);
glVertexPointer(4, GL_FLOAT, 0, 0);
glEnableClientState(GL_VERTEX_ARRAY);
glDrawArrays(GL_POINTS, 0, width * height);
glDisableClientState(GL_VERTEX_ARRAY);
// 交换缓存
glutSwapBuffers();
glutPostRedisplay();
}
void deleteVBO() {
cudaGraphicsUnregisterResource(positionsVBO_CUDA);
glDeleteBuffers(1, &positionsVBO);
}
__global__ void createVertices(float4* positions, float time, unsigned int width, unsigned int height) {
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 计算uv坐标
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// 计算简单正弦波模板
float freq = 4.0f;
float w = sinf(u * freq + time) * cosf(v * freq + time) * 0.5f;
// 写入数据
positions[y * width + x] = make_float4(u, w, v, 1.0f);
} 在windows和Quadro GPU上,cudaWGLGetDevice()可以被用来读取和wglEnumGpusNV()函数返回的句柄相关的cuda设备。在OpenGL渲染在Quadro GPU上执行、cuda计算在系统中其他GPU上执行的多GPU配置下,Quadro GPU关于提供比GeForce和Tesla GPU更好的OpenGL交互性表现。
Direct3D交互性
Direct3D交互性支持Direct3D 9Ex、Direct3D 10和Direct3D 11。cuda上下文只能和完全满足这些条件的Direct3D设备交互:Direct3D 9Ex设备必须通过把DeviceType设置成D3DDEVTYPE_HAL、BehaviorType设置成D3DCREATE_HARDWARE_VERTEXPROCESSING来创建;Direct3D 10和Direct3D 1设备则需要通过把DriverType设置成D3D_DRIVER_TYPE_HARDWARE来创建。
可以映射到cuda地址空间的Direct3D资源有Direct3D缓存、纹理和表面,这些资源通过cudaGraphicsD3D9RegisterResource()、cudaGraphicsD3D10RegisterResource()和cudaGraphicsD3D11RegisterResource()注册,下面的代码使用核函数动态修改一个存储在结点缓存对象的二维width * height网格:
- Direct3D 9版本:
IDirect3D9 *D3D;
IDirect3DDevice9 *device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
IDirect3DVertexBuffer9 *positionsVB;
struct cudaGraphicsResource *positionsVB_CUDA;
int main() {
int dev;
// 初始化Direct3D
D3D = Direct3DCreate9Ex(D3D_SDK_VERSION);
// 获取支持cuda的适配器
unsigned int adapter = 0;
for (; adapter < g_pD3D->GetAdapterCount(); adapter++) {
D3DADAPTER_IDENTIFIER9 adapterId;
g_pD3D->GetAdapterIdentifier(adapter, 0, &adapterId);
if (cudaD3D9GetDevice(&dev, adapterId.DeviceName) == cudaSuccess)
break;
}
// 创建设备
...
D3D->CreateDeviceEx(adapter, D3DDEVTYPE_HAL, hWnd, D3DCREATE_HARDWARE_VERTEXPROCESSING, ¶ms, NULL, &device);
// 使用设备
cudaSetDevice(dev);
// 创建并注册结点缓存
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
device->CreateVertexBuffer(size, 0, D3DFVF_CUSTOMVERTEX, D3DPOOL_DEFAULT, &positionsVB, 0);
cudaGraphicsD3D9RegisterResource(&positionsVB_CUDA, positionsVB, cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA, cudaGraphicsMapFlagsWriteDiscard);
// 启动渲染循环
while (...) {
...
Render();
...
}
...
}
void Render() {
// 映射结点缓存,以便cuda写
float4 *positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void **) &positions, &num_bytes, positionsVB_CUDA);
// 执行核函数
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<>>(positions, time, width, height);
// 去映射节点缓存
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// 画图并展示
...
}
void releaseVB() {
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4 *positions, float time, unsigned int width, unsigned int height) {
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 计算uv坐标
float u = x / (float) width;
float v = y / (float) height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// 计算简单正弦波模板
float freq = 4.0f;
float w = sinf(u * freq + time) * cosf(v * freq + time) * 0.5f;
// 写入数据
positions[y * width + x] = make_float4(u, w, v, __int_as_float(0xff00ff00));
} - Direct3D 10版本:
ID3D10Device *device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D10Buffer *positionsVB;
struct cudaGraphicsResource *positionsVB_CUDA;
int main() {
int dev;
// 获取支持cuda的适配器
IDXGIFactory *factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void **) &factory);
IDXGIAdapter *adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D10GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// 创建交换链和设备
...
D3D10CreateDeviceAndSwapChain(adapter, D3D10_DRIVER_TYPE_HARDWARE, 0, D3D10_CREATE_DEVICE_DEBUG, D3D10_SDK_VERSION, &swapChainDesc, &swapChain, &device);
adapter->Release();
// 使用设备
cudaSetDevice(dev);
// 创建并注册结点缓存
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D10_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D10_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D10_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D10RegisterResource(&positionsVB_CUDA, positionsVB, cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA, cudaGraphicsMapFlagsWriteDiscard);
// 启动渲染循环
while (...) {
...
Render();
...
}
...
}
void Render() {
// 映射结点缓存,以便cuda写数据
float4 *positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void **) &positions, &num_bytes, positionsVB_CUDA);
// 执行核函数
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<>>(positions, time, width, height);
// 结点缓存去映射
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// 绘画并展示
...
}
void releaseVB() {
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4 *positions, float time, unsigned int width, unsigned int height) {
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 计算uv坐标
float u = x / (float) width;
float v = y / (float) height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// 计算简单的正弦波模板
float freq = 4.0f;
float w = sinf(u * freq + time) * cosf(v * freq + time) * 0.5f;
// 写入数据
positions[y * width + x] = make_float4(u, w, v, __int_as_float(0xff00ff00));
} - Direct3D 11版本:
ID3D11Device *device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D11Buffer *positionsVB;
struct cudaGraphicsResource *positionsVB_CUDA;
int main() {
int dev;
// 得到支持cuda的适配器
IDXGIFactory *factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void **) &factory);
IDXGIAdapter *adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D11GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// 创建交换链和设备
...
sFnPtr_D3D11CreateDeviceAndSwapChain(adapter, D3D11_DRIVER_TYPE_HARDWARE, 0, D3D11_CREATE_DEVICE_DEBUG, featureLevels, 3, D3D11_SDK_VERSION, &swapChainDesc, &swapChain, &device, &featureLevel, &deviceContext);
adapter->Release();
// 使用设备
cudaSetDevice(dev);
// 创建并注册结点缓存
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D11_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D11_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D11RegisterResource(&positionsVB_CUDA, positionsVB, cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA, cudaGraphicsMapFlagsWriteDiscard);
// 启动渲染循环
while (...) {
...
Render();
...
}
...
}
void Render() {
// 映射结点缓存,以便cuda写入
float4 *positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void **) &positions, &num_bytes, positionsVB_CUDA));
// 执行核函数
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<>>(positions, time, width, height);
// 去映射结点缓存
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// 绘图并展示
...
}
void releaseVB() {
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4 *positions, float time, unsigned int width, unsigned int height) {
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 计算uv坐标
float u = x / (float) width;
float v = y / (float) height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// 计算简单正弦波模板
float freq = 4.0f;
float w = sinf(u * freq + time) * cosf(v * freq + time) * 0.5f;
// 写入数据
positions[y * width + x] = make_float4(u, w, v, __int_as_float(0xff00ff00));
} SLI交互
在多核GPU系统中,所有的支持cuda的GPU都可以通过cuda驱动和运行时作为独立设备访问,但是当系统处在SLI模式下时有这么几点特殊的考虑:
首先,一个GPU上的一个cuda设备的内存分配将会消耗Direct3D或OpenGL设备SLI配置中的GPU内存,所以内存分配可能比预期要更早失败。
第二,应用应该为SLI配置中的每个GPU都创建一个cuda上下文。尽管这不是硬性要求,但它避免了设备间不必要的数据迁移。我们可以为Direct3D使用cudaD3d[9|10|11]()、为OpenGL使用cudaGLGetDevices()系列方法来为设备指定渲染当前和下一帧的cuda设备句柄。有了由这些函数返回的设备信息,当deviceList参数被设置成cudaD3D[9|10|11]DeviceListCurrentFrame或cudaGLDeviceListCurrentFrame时,应用可以选择合适的设备并把Diretct3D或OpenGL资源映射到cuda设备上。
注意,cudaGraphicsD3D[9|10|11]RegisterResource()和cudaGraphicsGLRegister[Buffer|Image]()只能用在发生注册的设备上,因此当SLI配置中,不同帧的数据在不同cuda设备上计算时,为每台设备单独注册资源就是有必要的。
关于cuda运行时如何与Direct3D和OpenGL交互的细节,请参见上两小节。
版本和适配性
当开发一个cuda应用时,开发者需要注意两个版本号:描述一般标准和特征的计算能力和描述驱动、运行时API支持的特征的cuda驱动API版本号。驱动API的版本号在驱动头文件中被定义为CUDA_VERSION,允许开发者检查他们的应用是否要求一个比已安装的设备驱动更新的设备驱动,这一点很重要,因为驱动API是向后兼容的,意味着用特定版本的驱动API编译的插件、库(包括C运行时)、应用可以继续在随后发行的设备驱动上工作,如下图所示

但是驱动API不是向前兼容的,意味着用特定版本的驱动API编译的插件、库(包括C运行时)、应用不会在之前版本的设备驱动上工作。再就是需要注意,支持多版本的混合与匹配有一些限制:
1、因为系统中一次只能安装一个版本的cuda驱动,那么被安装的驱动的版本必须>=任何应用、插件或库编译时用的驱动API最大版本;
2、被一个应用使用的所有插件和库必须使用相同版本的cuda运行时,除非它们想要和cuda运行时进行动态链接,在这种情况下,统一进程空间可以存在多个版本的运行时。注意如果nvcc被用来链接应用,cuda运行时库的静态版本将会被默认使用,所有的cuda工具包库将会和cuda运行时静态链接;
3、被一个应用使用的所有插件和库如果在运行时要使用一些库(比如cuFFT、cuBLAS等),那么这些库必须使用相同版本
计算模式
在运行于Windows Server 2008及以后的Windows或者Linux上的Tesla设备上,我们可以使用nvidia-smi给系统中任何设备设置三种模式之一,见下表
| 计算模式 |
描述 |
| 默认 |
多个主机线程可以通过使用运行时API时在设备上调用cudaSetDevice()或者使用驱动API时让和此设备相关的上下文为当前上下文的方法同时共享设备 |
| 进程独占 |
系统中的所有进程只能在设备上创建一个cuda上下文,这个上下文可以是创建这个上下文的进程里多个线程共有的当前上下文。换句话说,一次只能有一个进程占用设备。 |
| 禁止 |
此设备上不允许 cuda上下文 |
也就是说,如果一个使用运行时API的主机线程没有明确调用cudaSetDevice()的话,它可能和一个不是device0的设备关联,如果device0处在禁止模式下或者处于进程独占模式下且正在被别的进程使用时。cudaSetValidDevices()可以被用来从一个设备优先级表中对设备进行设置。
还要注意的是,对于使用先进的Pascal架构的设备(计算能力主版本号>=6)来说,抢占式计算是被支持且默认开启的。这允许任务在指令级别被抢占,而不是在之前的Maxwell和Kepler GPU架构了使用的线程块级别,这给程序带来的好处是:避免了长时间运行的核函数独占系统或运行超市。然而,使用抢占式计算时有着一些切换上下文的性能损耗。正在使用的设备是否支持抢占式计算可以通过cudaDeviceGetAttribute()函数查到的结构体里cudaDevAttrComputePreemptionSupported字段进行判断,希望避免使用不同进程带来的上下文切换性能损耗的用户可以通过选择进程独占模式来确保GPU上一次只有一个活动进程。应用可以通过检查computeMode设备属性来查询设备的计算模式。
模式切换
拥有屏幕输出的GPU会把一些内存专门用在所谓的主表面(primary surface)上,这个主表面用来刷新输出被用户观看的显示器设备。当用户通过改变分别率或者显示位深度(使用英伟达控制面板或者windows上的显示控制面板)来初始化显示器的模式切换(mode switch)时,主表面需要的内存数量也会随之变化。例如如果用户把分辨率从1280 * 1024 * 32位切换到1600 * 1200 * 32位时,主表面需要的内存会从5.24MB增加到7.68MB(使用反锯齿的全屏图像应用的主表面可能需要更多)。在windows上,可能导致显示模式切换的事件还包括启动全屏DirectX应用、使用Alt + Tab从全屏DirectX应用中移除任务或者使用Ctrl + Alt + Del进行锁屏
如果模式切换增加了主表面需要的内存数量,系统可能会调拨一些分配给cuda应用的内存,所以模式切换会导致所有cuda运行时API调用失败并且返回一个无效上下文错误。
针对Windows的Tesla计算集群模式
使用nvidia-smi,windows设备驱动可以为计算能力>=2.0的Tesla和Quadro系列设备进入Tesla计算集群(TCC)模式,这个模式的主要好处如下:
1、它让集群中没有集成英伟达的图像设备使用这些GPU;
2、它让GPU通过远程桌面直接可用,或者可以通过依赖于远程桌面的集群管理系统访问;
3、它让作为windows服务的应用(比如会话0中的应用)可以使用GPU;
但是,TCC模式移除了对任何图像功能的支持。
结语
以上就是第三章编程接口的翻译,内容庞杂,下一章将翻译硬件实现部分。